背景需求:
花了十周,终于把周计划+教案的文字都写满、加粗、节日替换了。为了便于打印,我把19周的周计划教案全部合并在一起PDF。制作打印用PDF
思路
1、周计划是单独打印一张,因此要在第2页插入空白页,
2、教案有3页,需要双面打印,因此要最后一个表格(第三个教案表格)后面插入空白页。

3、将“节日“文件夹内的docx复制到"docx合并PDF”文件夹中的”零食文件“内,每个docx在第一个表格后面插入空白,在最后一个表格后插入空白页。
docx转PDF

4、零食文件夹中的PDF合并一个打印用PDF,并删除零食文件夹


结果:每一周的周计划教案从1+3变成了2+4页,一份是正反3张
代码展示:

'''周计划+教案 所有页合并打印(学期末周计划打印)
时间:2024年4月26日
'''
# 19个docx合并成一个PDF,便于打印
import os
from docx2pdf import convert
from PyPDF2 import PdfMerger
from docx import Document
# from docx.enum.text import WD_BREAK
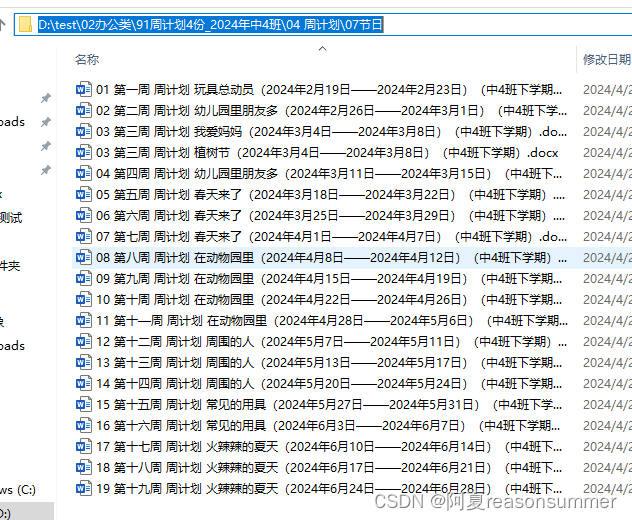
path=r'D:\test\02办公类\91周计划4份_2024年中4班\04 周计划'
old=path+r'\07节日'
new=path+r'\08docx合并pdf'
new_ls=new+r'\零时文件夹'
# 检查文件夹是否存在
if not os.path.exists(new_ls):
# 如果文件夹不存在,则新建文件夹
os.makedirs(new_ls)
# 获取docx文件列表
docx_files = os.listdir(old)
docx_files = [f for f in docx_files if f.lower().endswith('.docx')]
docx_files = docx_files[:] # 只处理前10个docx文件
# 处理.docx文件
import time
from docx import Document
from docx.shared import Pt
from docx.enum.section import WD_ORIENT
from docx.shared import Cm
from docx.enum.section import WD_SECTION
from docx.oxml import OxmlElement
from docx.oxml.ns import nsdecls
from docx.oxml import parse_xml
from docx.enum.section import WD_SECTION
print('--------1、遍历把周计划docx删掉反思内容,另存到jpg上传文件夹---------')
folder_path = old
for file_name in os.listdir(folder_path):
print(file_name)
if file_name.endswith('.docx'):
file_path = os.path.join(folder_path, file_name)
doc = Document(file_path)
# 找到第一个分节符(分页符)后的位置
start_index = 3 # 第1、2行 第3行内容保留(都是第一页上的段落文字
for i, paragraph in enumerate(doc.paragraphs):
if paragraph.runs:
if paragraph.runs[0].text == '\x0c': # 分页符的Unicode码为'\x0c'
start_index = i + 1
break
# 在找到第三个段落文字(说明部分)位置插入一个回车符(在备注哪一行已经有分节符了,备注加2个回车,就自动到下一页,生成一个横版的空页面
if start_index < len(doc.paragraphs):
paragraph = doc.paragraphs[start_index]
for _ in range(2): # 插入两次回车
paragraph.add_run().add_break()
# # 设置页边距(横版和竖版的页边距不同,所以这里不设置
# sections = doc.sections
# for section in sections:
# section.page_width = Cm(21) # 设置页面宽度为21厘米
# section.page_height = Cm(29.7) # 设置页面高度为29.7厘米
# section.left_margin = Cm(3) # 设置左页边距为3厘米
# section.right_margin = Cm(3) # 设置右页边距为3厘米
# section.top_margin = Cm(2) # 设置上页边距为2厘米
# section.bottom_margin = Cm(2) # 设置下页边距为2厘米
# 获取最后一个节
# 获取文档中的所有节
sections = doc.sections
last_section = sections[-1]
# 在最后一个节后面插入一个新的节
new_section = doc.add_section(WD_SECTION.NEW_PAGE)
doc.save(new_ls+r'\{}'.format(file_name))
time.sleep(1)
# # 将零时文件夹docx文件转换为PDF
pdf_files = []
for ls_name in os.listdir(new_ls):
print(ls_name)
if ls_name.endswith('.docx'):#
docx_path = os.path.join(new_ls, ls_name)
pdf_file = ls_name[:-5] + '.pdf'
pdf_path = os.path.join(new_ls, pdf_file)
convert(docx_path, pdf_path)
time.sleep(1)
pdf_files.append(pdf_path)
# 合并PDF文件
merger = PdfMerger()
for pdf_file in pdf_files:
merger.append(pdf_file)
# 保存合并后的PDF文件
output_file = os.path.join(new, '(打印)2024年6月周计划教案合并版(双面打印专用).pdf')
merger.write(output_file)
merger.close()
print('合并完毕,结果保存在{}'.format(output_file))
import shutil
# 删除临时文件夹
shutil.rmtree(new_ls)
打印测试
1、前期我把Word里面表格不留边距(上下左右边距0),生成PDF再打印,会自动保留0.7CM的边,所以我一直认为docx转PDF后会缩小边距。Word打印的内容更大,PDF打印的内容会缩小一点点。
2、生成打印用的周计划教案PDF后,我先打印一周6面pdf,看看打印的表格是不是还是缩小了
打印软件——ADOBE ACROBAT

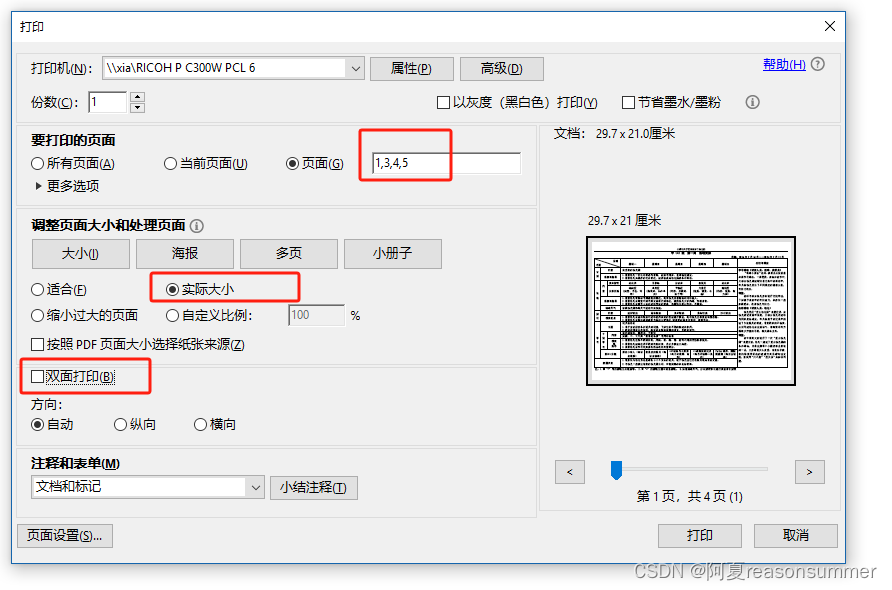
我用废纸打印的,就没有选双面打印。实际上交的纸质周计划教案是双面打印。
关于PDF打印的结论是:
一、doc转PDF显示加粗
1.PDf预览时,宋体显示不加粗,
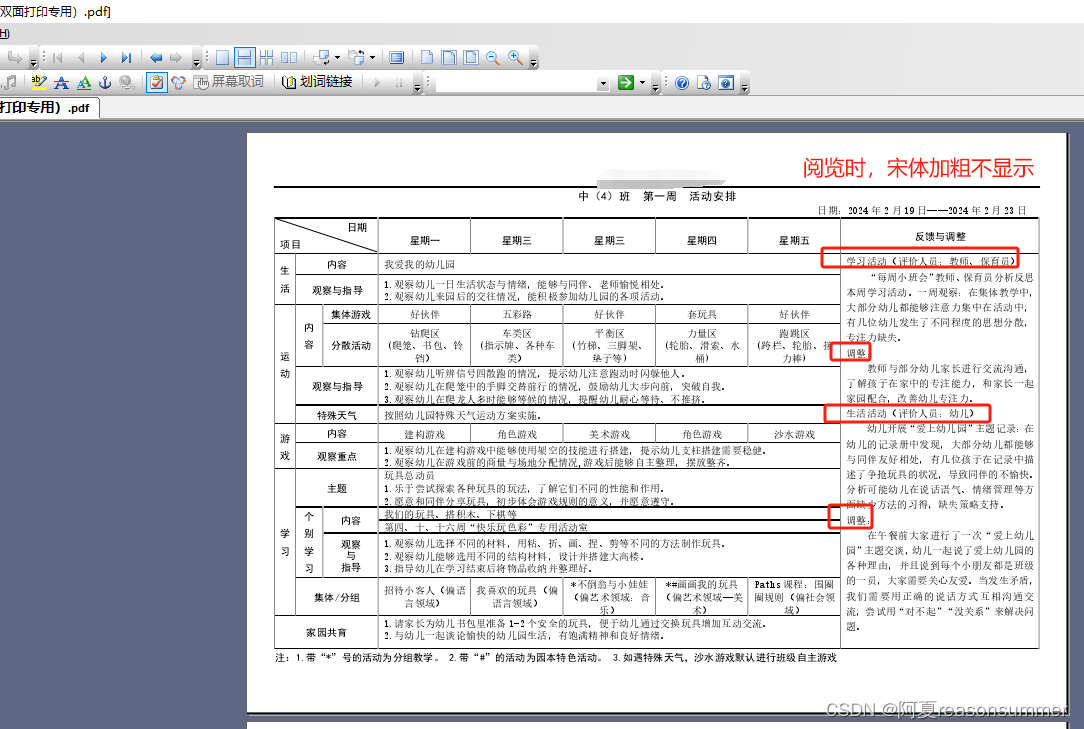
2.但文件夹阅览可以看到宋体加粗
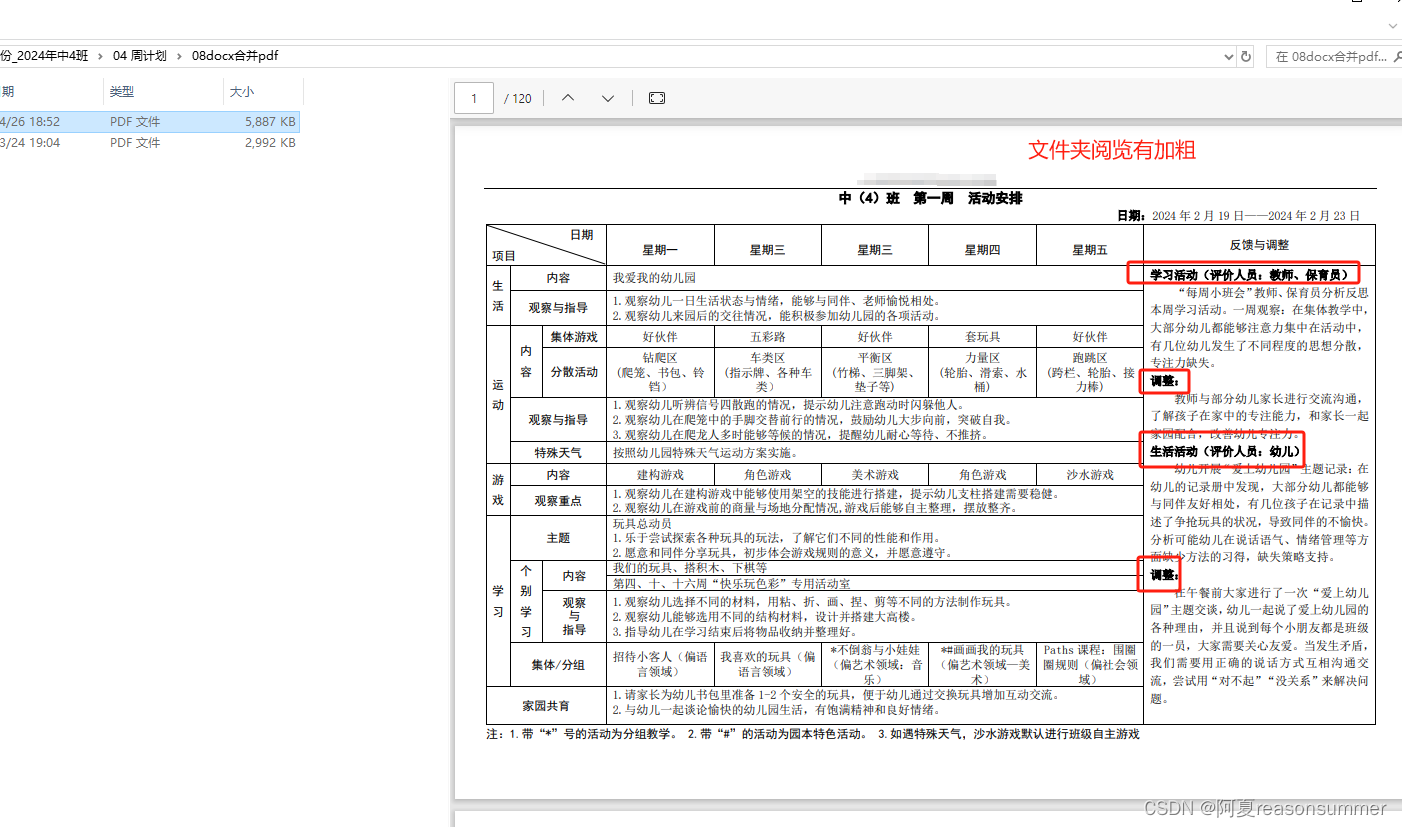
3.PDF打印后有加粗

二、Word需要预留边距
第1-2页:周计划页面的边距测算
1、WORD模板上的边距
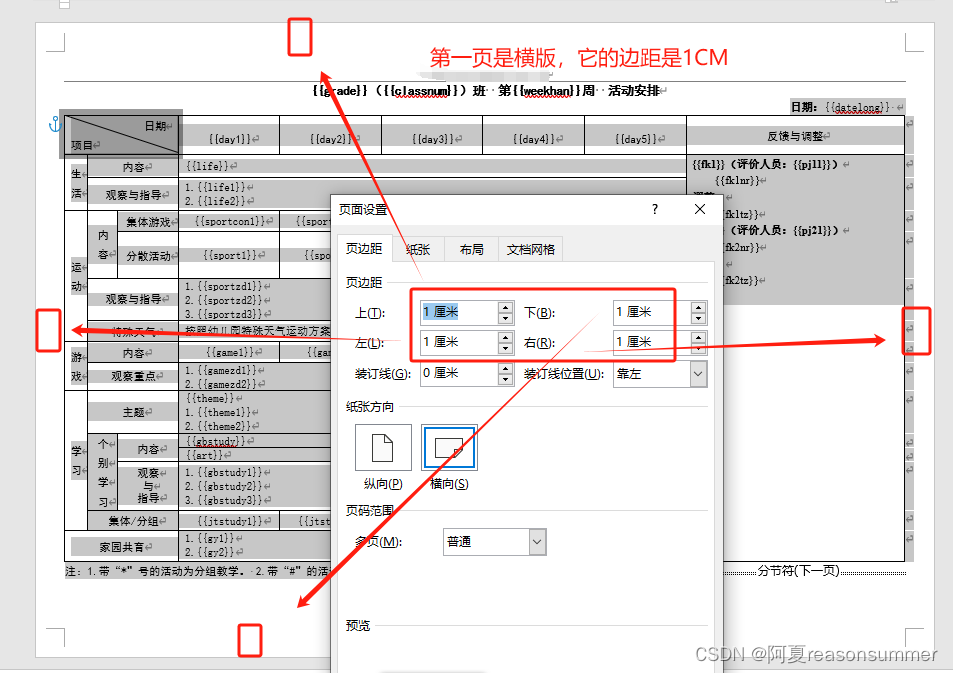
2、实际打印的边距
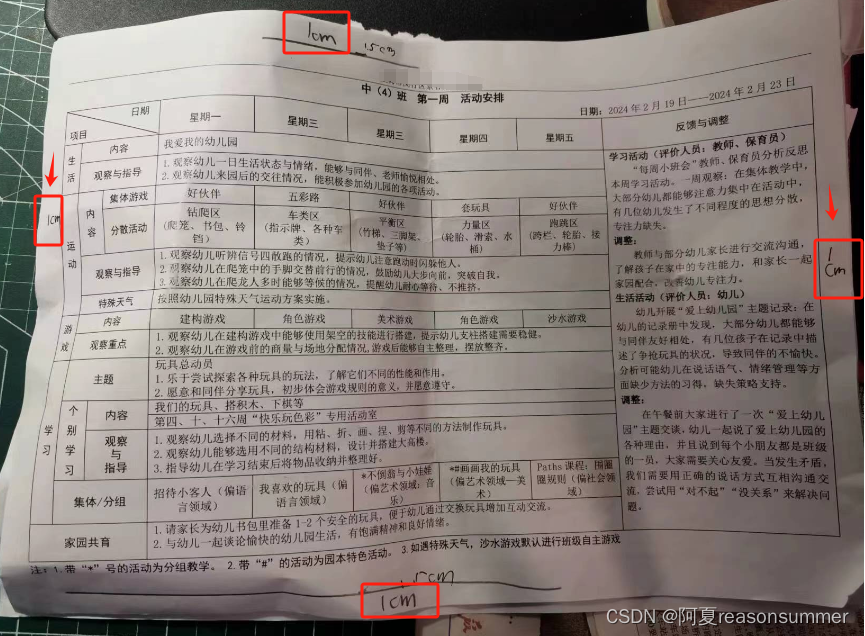
分析:打印纸的左右两侧的边距是1CM,上下的边距是1.5CM(考虑有页眉、分页符,可能页边距实际也是1CM)
第3-6页:教案页面的边距测算
1、WORD模板上的边距
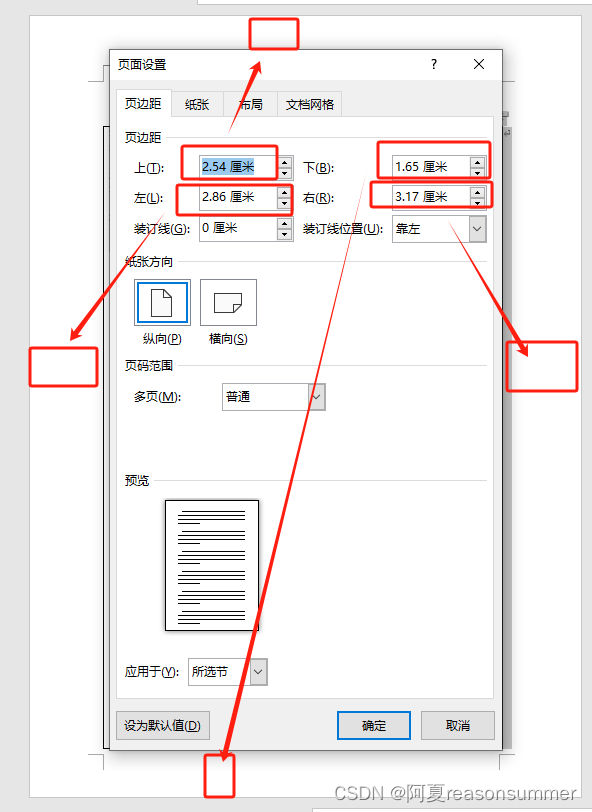
2、实际打印的边距

分析:
打印纸的左右两侧的边距分别是2.86和3.17CM,上边横线是页眉1.5,上边到“教学计划”大约是2.54,但实际“教学计划”打印在2.5位置处,下边距考虑分页符,表格没有撑满等因素,基本符合1.65CM的边距。。
结论:
只要Word里面预先保留0.7CM以上的上下左右边距,在生成PDF后,用WPS和Acobat打开PDF。选择“实际大小”打印,就会打印出与和docx打印一样大小的文字、表格框。
感悟:
终于终于,把周计划系列的资料全部厘清了,再遇到每学期一次的教案备课、贴墙、网页上传、期末打印或者随机出现的教案文字微调,就可以用这一系列的代码来实现了!!!




![正点原子[第二期]Linux之ARM(MX6U)裸机篇学习笔记-6.3](https://img-blog.csdnimg.cn/direct/1b9df6ecbfb946ea99d3ea4248c0e962.png)