正如我们在摸鱼有一手:NLP step by step -- 了解Transformer中看到的那样,Transformers模型通常非常大。对于数以百万计到数千万计数十亿的参数,训练和部署这些模型是一项复杂的任务。此外,由于几乎每天都在发布新模型,而且每种模型都有自己的实现,因此尝试它们绝非易事。
而🤗Hugging Face为我们创建了Transformer库,这个库的目标是提供一个API,通过它可以加载、训练和保存任何Transformer模型。这个库的主要特点是:
-
易于使用:下载、加载和使用最先进的NLP模型进行推理只需两行代码即可完成。
-
灵活:所有型号的核心都是简单的PyTorch nn.Module 或者 TensorFlow tf.kears.Model,可以像它们各自的机器学习(ML)框架中的任何其他模型一样进行处理。
-
简单:当前位置整个库几乎没有任何摘要。“都在一个文件中”是一个核心概念:模型的正向传递完全定义在一个文件中,因此代码本身是可以理解的,并且是可以破解的。
最后一个特性使🤗 Transformers与其他ML库截然不同。这些模型不是基于通过文件共享的模块构建的;相反,每一个模型都有自己的菜单。除了使模型更加容易接受和更容易理解,这还允许你轻松地在一个模型上实验,而且不影响其他模型。
本章将从一个端到端的示例开始,在该示例中,我们一起使用模型和tokenizer分词器来复制摸鱼有一手:NLP step by step -- 了解Transformer中引入的函数pipeline(). 接下来,我们将讨论模型API:我们将深入研究模型和配置类,并展示如何加载模型以及如何将数值输入处理为输出预测。
然后我们来看看标记器API,它是pipeline()函数的另一个主要组件。它是作用分词器负责第一个和最后一个处理步骤,处理从文本到神经网络数字输入的转换,以及在需要时转换回文本。最后,我们展示如何处理在一个准备好的批处理中通过一个模型发送多个句子的问题,然后详细介绍pipeline()函数。
Pipeline中有什么?
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
classifier( [ "I've been waiting for a HuggingFace course my whole life.", "I hate this so much!", ] )
##
[{'label': 'POSITIVE', 'score': 0.9598047137260437},
{'label': 'NEGATIVE', 'score': 0.9994558095932007}]此管道将三个步骤组合在一起:预处理、通过模型传递输入和后处理

图片来源于Hugging Face
使用分词器进行预处理
与其他神经网络一样,Transformer模型无法直接处理原始文本, 因此我们管道的第一步是将文本输入转换为模型能够理解的数字。 为此,我们使用tokenizer(标记器),负责:
-
将输入拆分为单词、子单词或符号(如标点符号),称为标记(token)
-
将每个标记(token)映射到一个整数
-
添加可能对模型有用的其他输入
所有这些预处理都需要以与模型预训练时完全相同的方式完成,因此我们首先需要从Model Hub中下载这些信息。为此,我们使用AutoTokenizer类及其from_pretrained()方法。使用我们模型的检查点名称,它将自动获取与模型的标记器相关联的数据,并对其进行缓存(因此只有在您第一次运行下面的代码时才会下载)。
因为sentiment-analysis(情绪分析)管道的默认检查点是distilbert-base-uncased-finetuned-sst-2-english(你可以看到它的模型卡here),我们运行以下程序:
from transformers import AutoTokenizer
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)一旦我们有了标记器,我们就可以直接将我们的句子传递给它,然后我们就会得到一本字典,它可以提供给我们的模型!剩下要做的唯一一件事就是将输入ID列表转换为张量。
我们在使用🤗 Transformers库的时候,不必担心哪个ML框架被用作后端;它可能是PyTorch或TensorFlow,或Flax。但是,Transformers型号只接受张量作为输入。如果这是你第一次听说张量,你可以把它们想象成NumPy数组。NumPy数组可以是标量(0D)、向量(1D)、矩阵(2D)或具有更多维度。它实际上是张量;其他ML框架的张量行为类似,通常与NumPy数组一样易于实例化。
要指定要返回的张量类型(PyTorch、TensorFlow或plain NumPy),我们使用return_tensors参数:
raw_inputs = [ "I've been waiting for a HuggingFace course my whole life.", "I hate this so much!", ]
inputs = tokenizer(raw_inputs, padding=True, truncation=True, return_tensors="pt") print(inputs)现在不要担心填充和截断;我们稍后会解释这些。这里要记住的主要事情是,你可以传递一个句子或一组句子,还可以指定要返回的张量类型(如果没有传递类型,您将得到一组列表)。
以下是PyTorch张量的结果:
{ 'input_ids': tensor([ [ 101, 1045, 1005, 2310, 2042, 3403, 2005, 1037, 17662, 12172, 2607, 2026, 2878, 2166, 1012, 102], [ 101, 1045, 5223, 2023, 2061, 2172, 999, 102, 0, 0, 0, 0, 0, 0, 0, 0] ]), 'attention_mask': tensor([ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0] ]) }输出本身是一个包含两个键的字典,input_ids和attention_mask。input_ids包含两行整数(每个句子一行),它们是每个句子中标记的唯一标记(token)。我们将在本章后面解释什么是attention_mask。
高维向量
Transformers模块的矢量输出通常较大。它通常有三个维度:
-
Batch size: 一次处理的序列数(在我们的示例中为2)。
-
Sequence length: 序列的数值表示的长度(在我们的示例中为16)。
-
Hidden size: 每个模型输入的向量维度。
由于最后一个值,它被称为“高维”。隐藏的大小可能非常大(768通常用于较小的型号,而在较大的型号中,这可能达到3072或更大)。
如果我们将预处理的输入输入到模型中,我们可以看到这一点:
outputs = model(**inputs)
print(outputs.last_hidden_state.shape)
##
torch.Size([2, 16, 768])注意🤗 Transformers模型的输出与namedtuple或词典相似。您可以通过属性(就像我们所做的那样)或键(输出["last_hidden_state"])访问元素,甚至可以通过索引访问元素,前提是您确切知道要查找的内容在哪里(outputs[0])。
不同的模型头
模型头将隐藏状态的高维向量作为输入,并将其投影到不同的维度。它们通常由一个或几个线性层组成:
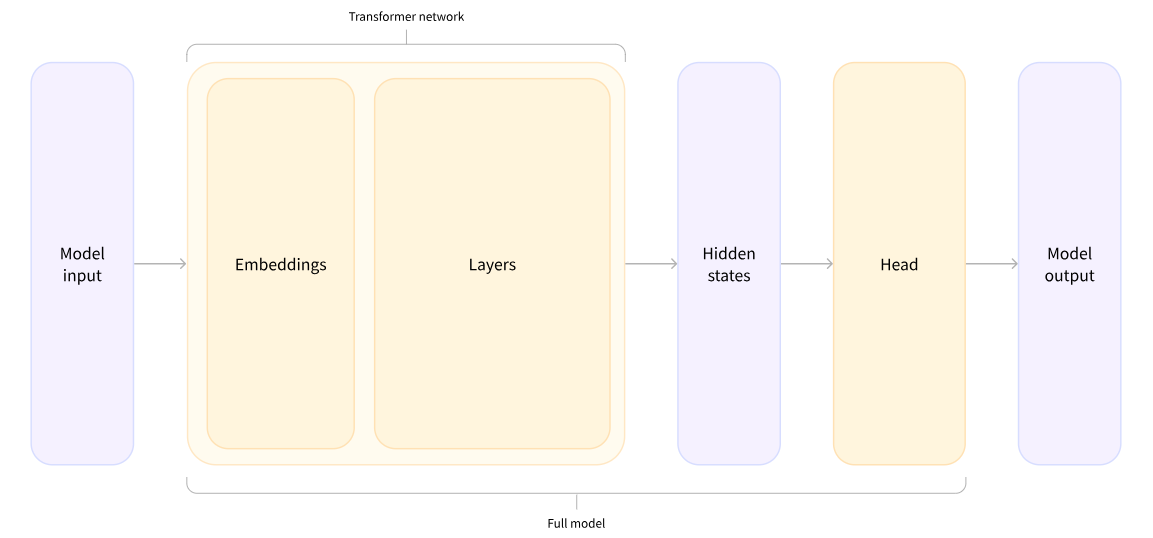
Transformers模型的输出直接发送到模型头进行处理。
在此图中,模型由其嵌入层和后续层表示。嵌入层将标记化输入中的每个输入ID转换为表示关联标记(token)的向量。后续层使用注意机制操纵这些向量,以生成句子的最终表示。
🤗 Transformers中有许多不同的体系结构,每种体系结构都是围绕处理特定任务而设计的。以下是一个非详尽的列表:
-
*Model (retrieve the hidden states)
-
*ForCausalLM
-
*ForMaskedLM
-
*ForMultipleChoice
-
*ForQuestionAnswering
-
*ForSequenceClassification
-
*ForTokenClassification
-
以及其他 🤗
对于我们的示例,我们需要一个带有序列分类头的模型(能够将句子分类为肯定或否定)。因此,我们实际上不会使用AutoModel类,而是使用AutoModelForSequenceClassification:
from transformers import AutoModelForSequenceClassification
checkpoint = "distilbert-base-uncased-finetuned-sst-2-english"
model = AutoModelForSequenceClassification.from_pretrained(checkpoint)
outputs = model(**inputs)
print(outputs.logits.shape)
##
torch.Size([2, 2])因为我们只有两个句子和两个标签,所以我们从模型中得到的结果是2 x 2的形状。
对输出进行后处理
我们从模型中得到的输出值本身并不一定有意义。我们来看看,
print(outputs.logits)
##
tensor([[-1.5607, 1.6123], [ 4.1692, -3.3464]],
grad_fn=<AddmmBackward>)我们的模型预测第一句为[-1.5607, 1.6123],第二句为[ 4.1692, -3.3464]。这些不是概率,而是logits,即模型最后一层输出的原始非标准化分数。要转换为概率,它们需要经过SoftMax层(所有🤗Transformers模型输出logits,因为用于训练的损耗函数通常会将最后的激活函数(如SoftMax)与实际损耗函数(如交叉熵)融合):
import torch
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
print(predictions)
##
tensor([[4.0195e-02, 9.5980e-01], [9.9946e-01, 5.4418e-04]],
grad_fn=<SoftmaxBackward>)现在我们可以看到,模型预测第一句为[0.0402, 0.9598],第二句为[0.9995, 0.0005]。这些是可识别的概率分数。
为了获得每个位置对应的标签,我们可以检查模型配置的id2label属性(下一节将对此进行详细介绍):
model.config.id2label ## {0: 'NEGATIVE', 1: 'POSITIVE'}现在我们可以得出结论,该模型预测了以下几点:
-
第一句:否定:0.0402,肯定:0.9598
-
第二句:否定:0.9995,肯定:0.0005
我们已经成功地复制了管道的三个步骤:使用标记化器进行预处理、通过模型传递输入以及后处理!现在,让我们花一些时间深入了解这些步骤中的每一步。
原文链接:管道的内部 - Hugging Face NLP Course