目录
- 简介
- 准备工作
- 安装步骤
- (一)、下载hive包并解压到指定目录下
- (二)、设置环境变量
- (三)、下载MySQL驱动包到hive的lib目录下
- (四)、将hadoop的guava包拷贝到hive
- (五)、在mysql中创建metastore数据库
- (五)、修改配置
- (六)、初始化元数据
- (七)、启动hive
- 总结
简介
Hive是一个建立在Hadoop上的数据仓库工具,它提供了一个类似于SQL的查询语言来分析大规模数据。
Hive具有以下几个主要特点:
1. 处理大规模数据高效
能够处理TB至PB级数据,并优化MapReduce任务以提高效率。
2.高可扩展性和容错性
利用Hadoop生态系统实现高效扩展,支持大规模并行计算。
3.数据管理与存储
提供表、分区等抽象,方便数据组织和管理。
4.灵活性和集成性
支持自定义数据类型、函数和脚本,实现复杂查询和数据转换。
5.类SQL查询语言
使用与SQL相似的HiveQL,使数据分析变得简单。
准备工作
在安装Hive之前,通常需要安装和配置以下几个组件:
Java开发工具包(JDK):Hive是基于Hadoop的,而Hadoop需要Java环境来运行,因此必须安装JDK。
Hadoop:Hive是一个基于Hadoop的数据仓库,所以必须先安装Hadoop集群,并确保其健康可用。特别是在启动Hive之前,需要确保Hadoop集群已经启动,并且HDFS的安全模式已经关闭。
MySQL:Hive为了操作HDFS上的数据集,需要知道数据的切分格式、行列分隔符、存储类型、是否压缩以及数据的存储地址等信息。这些信息会被存储到一张表中(元数据),而这张表通常会被存储到MySQL中。
除了上述组件外,还需要确保服务器的基础环境配置正确,包括集群时间同步、防火墙关闭、主机Host映射、免密登录等。
安装步骤
搭建Hive环境并不复杂,下面是一个保姆级的教程来帮助你搭建Hive环境。
(一)、下载hive包并解压到指定目录下
解压命令:tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/src/
重命名:mv apache-hive-3.1.2-bin hive
(二)、设置环境变量
vim /root/.bash_profile --> 环境变量只对root用户生效
在文件的最后,添加如下两句:
export HIVE_HOME=/usr/local/src/hive -->根据自己的目录进行更改
export PATH=$HIVE_HOME/bin:$PATH
然后执行:
source /root/.bash_profile --> 使环境变量立即生效
(三)、下载MySQL驱动包到hive的lib目录下
mysql-connector-java-8.0.23.jar
(四)、将hadoop的guava包拷贝到hive
删除hive自带的guava包:rm -rf guava-19.0.jar
拷贝:cp guava-27.0-jre.jar /usr/local/src/hive/lib -->去到hadoop的common/lib下再拷贝
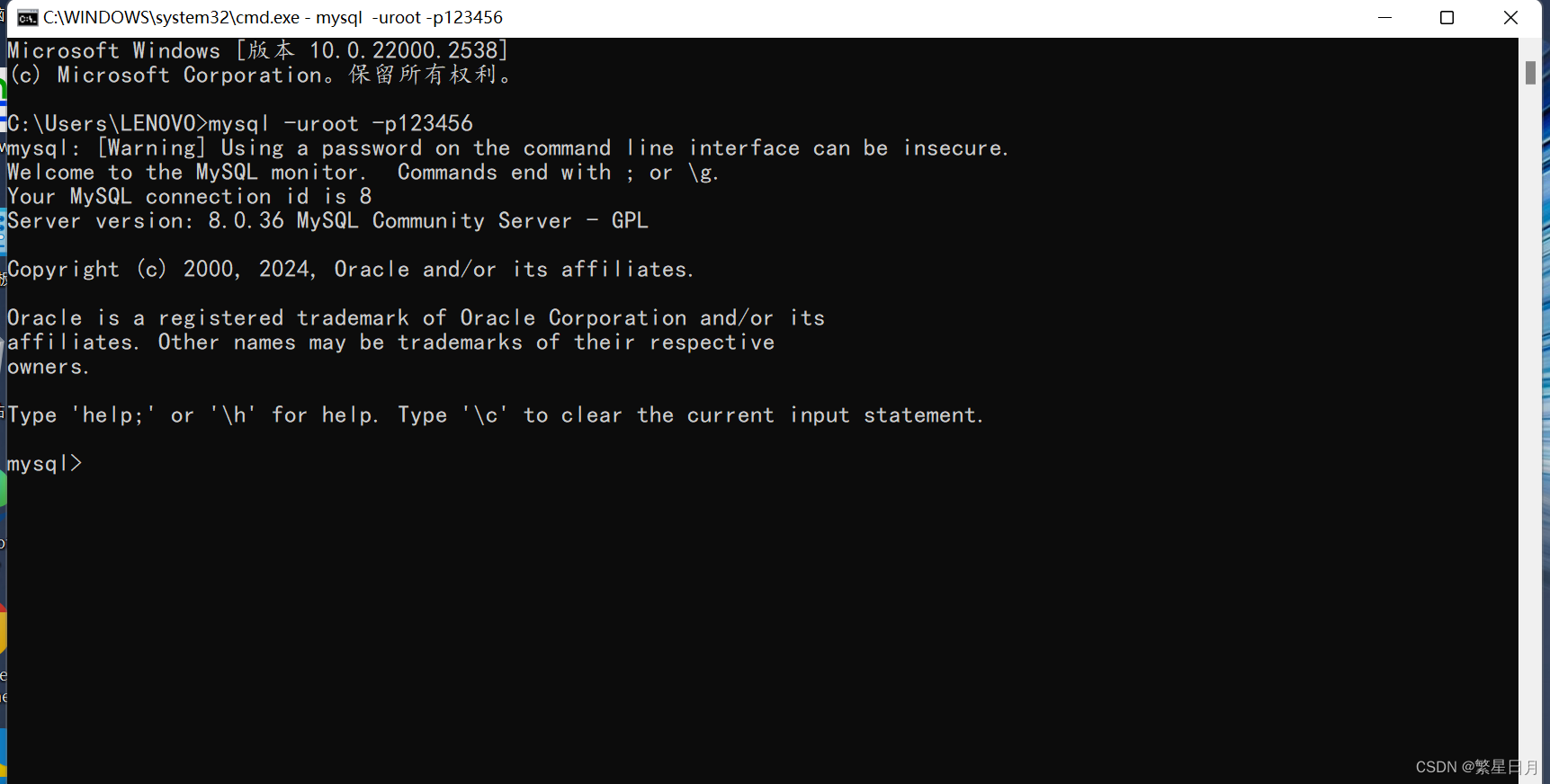
(五)、在mysql中创建metastore数据库
登录:mysql -p123456 --->我的密码是123456
创建库:CREATE DATABASE IF NOT EXISTS metastore;
查看库:show databases;
(五)、修改配置
位置:/hive/conf
创建 hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://ip地址:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/usr/local/src/hive/warehouse</value>
</property>
<!-- 显示表头 -->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 显示当前库 -->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 配置元数据远程连接地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
</configuration>
注意:把配置文件中的ip地址修改为自己的ip地址
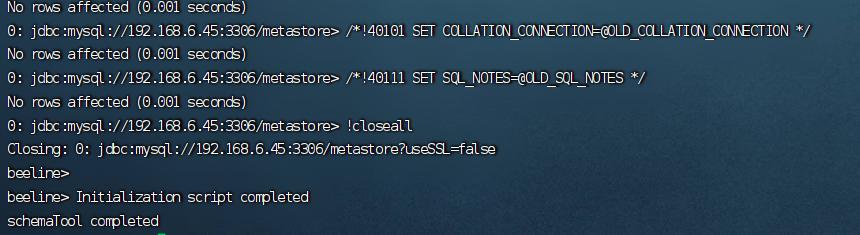
(六)、初始化元数据
初始化 Hive 元数据库(要先启动Hadoop)
./bin/schematool -initSchema -dbType mysql -verbose
(七)、启动hive
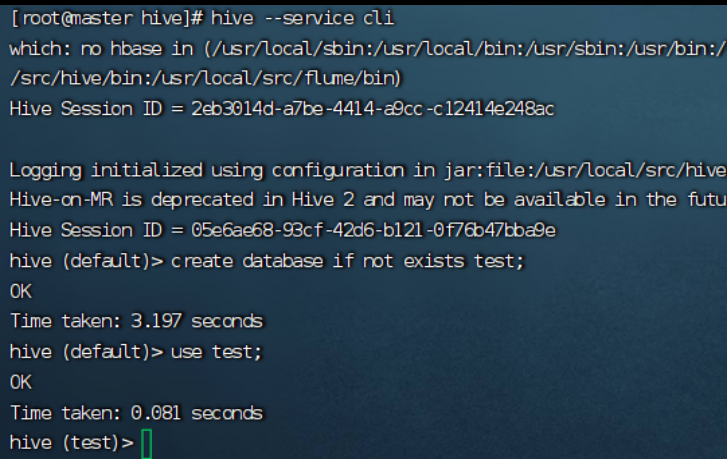
前台启动 Hive 元数据服务 :hive --service metastore
进入 Hive: hive --service cli
创建任意库,检测是否正常: create database if not exists test;

总结
通过本次教学,希望读者能够掌握Hive的搭建方法,利用Hive来处理和分析大规模数据,为企业带来更大的价值。以上就是搭建Hive环境的基本步骤。当然,在实际搭建过程中还有很多细节需要注意,例如配置Hadoop和Hive的版本兼容性、调整Hive的配置参数以优化性能等。希望这篇文章能帮助你搭建Hive环境。