文章目录
- 使用 Spring Kafka 动态管理 Kafka 连接和主题监听
- 1. 前言
- 2. 简单的消费程序配置
- 3. Spring Kafka 主要的相关类的说明
- 4. `@KafkaListener` 注解的加载执行流程解析
- 5. 动态监听消费订阅的设计与实现
使用 Spring Kafka 动态管理 Kafka 连接和主题监听
文章内容较长,如果想看样例代码直接跳到 动态监听消费订阅的设计与实现
1. 前言
SpringBoot 项目中我们在使用 Spring Kafka 来消费 Kafka 的消息时通常是在 application.properties(或application.yml) 文件中先定义 Kafka 的集群地址(如 spring.kafka.bootstrap-servers) ,随后,我们通过编写一个组件并在一个方法上添加@KafkaListener注解来实现消息消费。
对于需要监听多个Kafka集群的场景,单纯通过配置文件来设定是不足够的。在这种情况下,我们需要为每个集群分别创建连接,并为每一个设定专门的ConcurrentKafkaListenerContainerFactory。以下是一个示例配置,其中包括了为两个不同的Kafka集群创建各自的消费工厂和监听容器的过程:
// 在 Spring Boot 应用中,你需要创建两个配置类来分别配置这两个集群
@Configuration
public class KafkaConfig {
@Bean
public ConsumerFactory<String, String> consumerFactory1() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-cluster1:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group1");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 添加其他配置项
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory1() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory1());
return factory;
}
@Bean
public ConsumerFactory<String, String> consumerFactory2() {
Map<String, Object> props = new HashMap<>();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-cluster2:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "group2");
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 添加其他配置项
return new DefaultKafkaConsumerFactory<>(props);
}
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory2() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory2());
return factory;
}
}
// ----
// 创建 Kafka 监听器来消费来自不同集群的消息
@Service
public class KafkaConsumers {
@KafkaListener(topics = "topic1", containerFactory = "kafkaListenerContainerFactory1")
public void listenCluster1(String message) {
System.out.println("Received from cluster 1: " + message);
}
@KafkaListener(topics = "topic2", containerFactory = "kafkaListenerContainerFactory2")
public void listenCluster2(String message) {
System.out.println("Received from cluster 2: " + message);
}
}
对于更复杂的场景,例如需要连接多个Kafka集群或者动态地控制消息监听程序的启动与停止,这种硬编码方式将不再适用。
在处理这个需求时,我思考了一种方法,即通过在数据库中维护一个表来定义Kafka集群的地址、需要监听的topic以及监听者的配置。通过API接口,我们可以动态地添加或移除监听程序,并控制它们的启动和停止。如果能实现这样的功能,就可以避免重新发布服务,同时还可以通过一个后台管理页面来控制程序监听消费哪个Kafka集群的哪个Topic,并可以动态指定监听消费程序的启动和停止。
为了实现这样的功能,我们首先需要对Spring Kafka的运行机制以及其中一些主要的类的概念有一定的了解。
2. 简单的消费程序配置
如果你不是第一次接触 Spring Kafka 的使用,这段内容可以跳过
关于 SpringBoot 对 Apache Kafka 的支持,可以参阅官方文档
下面是大体的流程:
- 在
application.yml进行 kafka 相关的配置,如下所示:spring: kafka: consumer: # 消费者组ID group-id: demo1 # 开启自动提交offset enable-auto-commit: true # 单次调用poll()操作时能拉取的最大消息数量 max-poll-records: 100 # 自动提交offset的时间间隔,单位毫秒 auto-commit-interval: 5000 # 键的反序列化方式 key-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 值的反序列化方式 value-deserializer: org.apache.kafka.common.serialization.StringDeserializer # 消费者如何对待Kafka中不存在的offset或null的offset auto-offset-reset: earliest listener: # 消费者并发数,即并发消费线程的数量 concurrency: 1 # poll()调用时的超时时间,单位毫秒 poll-timeout: 1500 # Kafka集群的地址 bootstrap-servers: localhost:9092Note:
spring.kafka.listener.concurrency参数的设置与 Kafka topic 的 partition 数量的关系非常重要,它决定了并发消费消息的能力。这里解释三种情况:并发数大于 partition 数、等于 partition 数、以及小于 partition 数的效果- 并发数大于 Partition 数:
当spring.kafka.listener.concurrency设置的值大于 topic 的 partition 数量时,由于 Kafka 的每个 partition 只能由一个消费者线程来处理。这意味着实际并发线程的数量仍然受限于 partition 的数量。 - 并发数等于 Partition 数:
这是最理想的配置,每个消费者线程恰好对应一个 partition。这样可以最大化利用所有的 partition,每个 partition 都有一个消费者线程在并发地处理,从而实现最高效的消息处理速度。在这种配置下,消费者的资源被完全利用,没有闲置的消费者线程。 - 并发数小于 Partition 数:
当spring.kafka.listener.concurrency的值小于 topic 的 partition 数量时,每个消费者线程可能需要处理多个 partition 的消息。这种情况下,消费者线程的负载会增加,因为它们需要从多个 partition 中拉取并处理消息。这可能会导致处理速度降低,尤其是当消息量较大时,单个消费者线程可能会成为瓶颈。
总结而言,设置
spring.kafka.listener.concurrency时,最佳实践是将其值设置为等于或略高于 partition 的数量,以避免有消费者线程空闲而浪费资源,同时又能保证所有 partition 都有足够的线程进行处理。调整并发度和 partition 数量的比例是优化 Kafka 消费性能的关键步骤。 - 并发数大于 Partition 数:
- 编写组件并在消费程序上添加
@KafkaListener组件,如下所示:@Slf4j @Component public class SimpleConsumer { @KafkaListener(topics = "test", groupId = "consumer01", batch = "true") public void consume01(String message) { log.info("consumer01: {}", message); } @KafkaListener(topics = "test", groupId = "consumer02", batch = "true") public void consume02(List<String> messages) { log.info("consumer02, count: {}, message: {}", messages.size(), messages); } @KafkaListener(topics = "test", groupId = "consumer03", batch = "true") public void consume03(List<ConsumerRecord<String, String>> records) { log.info("consumer03, count: {}, message:{}", records.size(), records); } }
在上面的例子中,我们分别有 3 个消费组 consumer01、consumer02、consumer03 来监听消费 “test” 这个 topic,启动项目后,我们向 "test’ topic 里发送 10 条数据,内容如下:
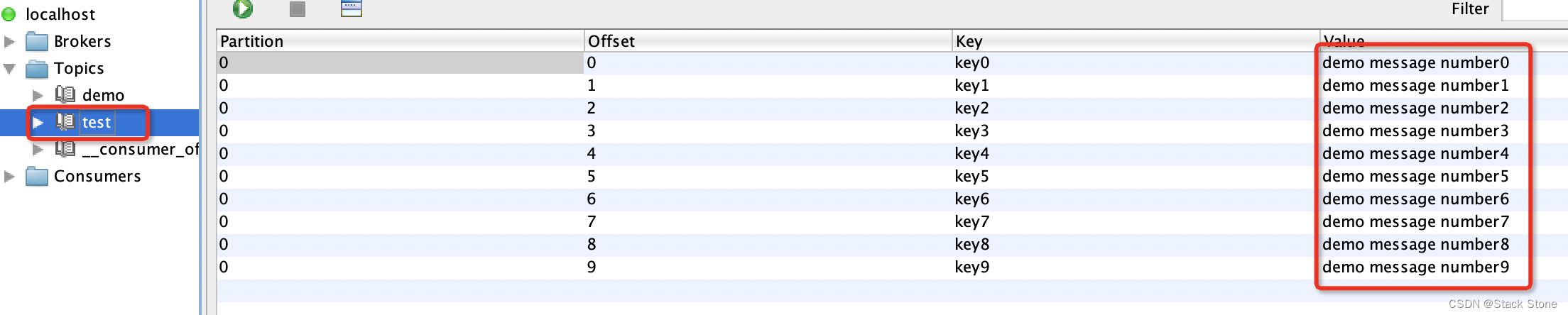
观察程序输出如下所示:

可以看到:
- consumer01: 接收批量数据的时候将数据按 “,” 号进行了分割
- consumer02: 接收到了消息的集合数据,但无法获取消息的 offset 等信息
- consumer03: 接收到了消息的集合数据,并可以获取到消息的 offset 等信息
从上面的结果来看,如果是批量数据消费的话,建议使用第 3 种方法进行接收数据,这样不仅可以获取到消息还可以获取该条消息的 offset 等信息。
样例代码: https://github.com/lt5227/example_code/tree/main/spring_kafka_example
3. Spring Kafka 主要的相关类的说明
-
KafkaTemplate
作用:KafkaTemplate是 Spring Kafka 中用于生产消息的主要类,类似于 Spring JMS 的 JmsTemplate。它封装了 Kafka 的生产者客户端,使得发送消息到 Kafka 变得简单。 -
KafkaListener
作用:@KafkaListener注解用于标记方法以便作为 Kafka 消息的消费者。这使得监听 Kafka topics 变得非常简单。可以在单个方法上配置多个 topics 或使用 pattern 匹配多个 topics。 -
KafkaListenerEndpointRegistry
作用:KafkaListenerEndpointRegistry是一个管理 Kafka 监听容器的注册中心。它可以用来动态地添加、查询和删除监听容器。此外,它还支持启动和停止所有或单个监听容器。 -
MessageListenerContainer
作用:MessageListenerContainer是一个用于封装 Kafka 消费者行为的接口,它的实现类(如ConcurrentMessageListenerContainer和KafkaMessageListenerContainer)提供了具体的消费者配置和消息处理。通过
KafkaListenerEndpointRegistry获取特定的MessageListenerContainer。
调用start(),stop(), 或pause()方法来控制消息消费的行为。 -
AbstractKafkaListenerEndpoint
作用:AbstractKafkaListenerEndpoint包括SimpleKafkaListenerEndpoint和MethodKafkaListenerEndpoint是定义 Kafka 消息监听器细节(如 topic, partition, filter等)的基础类。使用这些类在运行时创建和配置新的监听器端点。将端点注册到
KafkaListenerEndpointRegistry。 -
KafkaListenerContainerFactory
作用:KafkaListenerContainerFactory用于创建MessageListenerContainer。它定义了容器的配置,如并发数、轮询超时和自动启动等。配置具体的工厂来创建具有特定特性的消费者容器。
通常与@KafkaListener注解结合使用,也可以用于编程创建监听器。
4. @KafkaListener 注解的加载执行流程解析
@KafkaListener 注解是 Spring Kafka 提供的核心功能,用于将方法标记为 Kafka 消息的监听器。当 Spring 应用启动时,KafkaListenerAnnotationBeanPostProcessor 会扫描并解析带有 @KafkaListener 的方法,并创建相应的 KafkaListenerEndpoint 实例。这些端点包含了监听所需的所有配置信息,如主题、分区和过滤器等。接着,KafkaListenerEndpointRegistrar 根据这些端点信息,结合 KafkaListenerContainerFactory 创建并管理 MessageListenerContainer,这些容器负责实际与 Kafka 交互,进行消息的接收和处理。
下面是整个过程的详细的流程:
-
注解解析
当 Spring 应用启动时,Spring 的扫描机制会识别包含 @KafkaListener 注解的方法。这一过程主要由KafkaListenerAnnotationBeanPostProcessor类处理,它是一个 Spring Bean 后处理器,专门用来处理 Kafka 监听器注解。
当我们的项目中添加了spring-kafka依赖后,启动项目后KafkaListenerAnnotationBeanPostProcessor这个类 spring 会自动的注册,原因可以参考:KafkaListenerEndpointRegistry 隐式注册分析 一文。 -
端点注册
一旦@KafkaListener注解被识别,KafkaListenerAnnotationBeanPostProcessor将为每个注解创建一个对应的监听器端点(KafkaListenerEndpoint实例)。这个端点包括所有必要的信息,如主题(topics)、分区(partitions)和过滤器(filter),这些信息都是从注解的属性中提取的。详细的代码如下所示:/* * 代码节选自:spring-kafka:3.1.4 KafkaListenerAnnotationBeanPostProcessor:366 */ @Override public Object postProcessAfterInitialization(final Object bean, final String beanName) throws BeansException { // 检查当前bean是否已经被确定为没有Kafka监听器注解 if (!this.nonAnnotatedClasses.contains(bean.getClass())) { // 获取目标类,考虑可能的AOP代理 Class<?> targetClass = AopUtils.getTargetClass(bean); // 在类级别查找@KafkaListener注解 Collection<KafkaListener> classLevelListeners = findListenerAnnotations(targetClass); // 确定是否存在类级别的监听器 final boolean hasClassLevelListeners = !classLevelListeners.isEmpty(); // 存储可能需要处理的多个方法 final List<Method> multiMethods = new ArrayList<>(); // 选择带有@KafkaListener注解的方法 Map<Method, Set<KafkaListener>> annotatedMethods = MethodIntrospector.selectMethods(targetClass, (MethodIntrospector.MetadataLookup<Set<KafkaListener>>) method -> { // 查找方法上的@KafkaListener注解 Set<KafkaListener> listenerMethods = findListenerAnnotations(method); // 如果找到注解,则返回注解,否则返回null return (!listenerMethods.isEmpty() ? listenerMethods : null); }); // 如果存在类级监听器,找出所有带@KafkaHandler注解的方法 if (hasClassLevelListeners) { Set<Method> methodsWithHandler = MethodIntrospector.selectMethods(targetClass, (ReflectionUtils.MethodFilter) method -> AnnotationUtils.findAnnotation(method, KafkaHandler.class) != null); // 将找到的方法添加到multiMethods列表 multiMethods.addAll(methodsWithHandler); } // 如果没有找到任何注解方法,并且没有类级监听器 if (annotatedMethods.isEmpty() && !hasClassLevelListeners) { // 将当前类标记为非注解类,避免未来重复检查 this.nonAnnotatedClasses.add(bean.getClass()); // 记录没有找到@KafkaListener的跟踪信息 this.logger.trace(() -> "No @KafkaListener annotations found on bean type: " + bean.getClass()); } else { // 存在注解方法,遍历这些方法 for (Map.Entry<Method, Set<KafkaListener>> entry : annotatedMethods.entrySet()) { Method method = entry.getKey(); for (KafkaListener listener : entry.getValue()) { // 处理每一个@KafkaListener注解 processKafkaListener(listener, method, bean, beanName); } } // 调试日志,记录处理的@KafkaListener方法数量 this.logger.debug(() -> annotatedMethods.size() + " @KafkaListener methods processed on bean '" + beanName + "': " + annotatedMethods); } // 如果存在类级监听器,处理多方法监听器 if (hasClassLevelListeners) { processMultiMethodListeners(classLevelListeners, multiMethods, bean, beanName); } } // 返回处理后的bean return bean; }方法上如果有
@KafkaListener这个注解在上面的代码中可以看到其会执行如下的方法:// 代码节选自:spring-kafka:3.1.4 KafkaListenerAnnotationBeanPostProcessor:473 protected synchronized void processKafkaListener(KafkaListener kafkaListener, Method method, Object bean, String beanName) { // 检查提供的方法是否为代理方法,如果是,获取原始方法 Method methodToUse = checkProxy(method, bean); // 创建一个方法级别的 Kafka 监听器端点 MethodKafkaListenerEndpoint<K, V> endpoint = new MethodKafkaListenerEndpoint<>(); // 设置监听器端点的方法为检查后的方法 endpoint.setMethod(methodToUse); // 从注解中获取 bean 引用,通常用于多实例bean的场景 String beanRef = kafkaListener.beanRef(); // 将当前 bean 添加到监听作用域中 this.listenerScope.addListener(beanRef, bean); // 为端点设置唯一标识符 endpoint.setId(getEndpointId(kafkaListener)); // 解析注解中配置的主题 String[] topics = resolveTopics(kafkaListener); // 解析注解中配置的主题分区 TopicPartitionOffset[] tps = resolveTopicPartitions(kafkaListener); /* * 处理主监听器和重试监听器,如果处理成功,则不继续后面的流程 * 方法是判断方法上是否有 @RetryableTopic 注解,有则返回 true 并注册到 KafkaListenerEndpointRegistry */ if (!processMainAndRetryListeners(kafkaListener, bean, beanName, methodToUse, endpoint, topics, tps)) { // 处理普通监听器,设置端点的其他属性并注册 (注册到KafkaListenerEndpointRegistry) processListener(endpoint, kafkaListener, bean, beanName, topics, tps); } // 移除之前添加到监听作用域中的 bean this.listenerScope.removeListener(beanRef); } // 代码节选自:spring-kafka:3.1.4 KafkaListenerAnnotationBeanPostProcessor:612 protected void processListener(MethodKafkaListenerEndpoint<?, ?> endpoint, KafkaListener kafkaListener, Object bean, String beanName, String[] topics, TopicPartitionOffset[] tps) { // 将 @KafkaListener 注解的配置应用到 Kafka 监听端点 processKafkaListenerAnnotation(endpoint, kafkaListener, bean, topics, tps); // 从 @KafkaListener 注解中解析出指定的容器工厂名称 String containerFactory = resolve(kafkaListener.containerFactory()); // 根据解析出的容器工厂名称获取实际的 KafkaListenerContainerFactory 实例 KafkaListenerContainerFactory<?> listenerContainerFactory = resolveContainerFactory(kafkaListener, containerFactory, beanName); // 注册端点到 KafkaListenerEndpointRegistrar,以便创建对应的消息监听容器 this.registrar.registerEndpoint(endpoint, listenerContainerFactory); } -
监听器容器的创建
在上面的代码最后可以看到,端点注册使用的是KafkaListenerEndpointRegistrar#registerEndpoint(KafkaListenerEndpoint endpoint, @Nullable KafkaListenerContainerFactory<?> factory)这个方法,其会根据KafkaListenerContainerFactory来创建一个MessageListenerContainer。这个容器负责在运行时与 Kafka 服务器交互,包括连接管理、消息拉取等任务。
代码流程如下:// 代码节选自:spring-kafka:3.1.4 KafkaListenerEndpointRegistrar:231 public void registerEndpoint(KafkaListenerEndpoint endpoint, @Nullable KafkaListenerContainerFactory<?> factory) { // 确保提供的 endpoint 不为空 Assert.notNull(endpoint, "Endpoint must be set"); // 确保 endpoint 有一个非空的 ID Assert.hasText(endpoint.getId(), "Endpoint id must be set"); // 创建一个新的 KafkaListenerEndpointDescriptor 实例,包含 endpoint 和可能为 null 的 factory // factory 可能为空,在创建容器之前,会进行解析 KafkaListenerEndpointDescriptor descriptor = new KafkaListenerEndpointDescriptor(endpoint, factory); // 对 endpointDescriptors 列表进行同步操作,保证线程安全 synchronized (this.endpointDescriptors) { // 如果 startImmediately 标志为 true,则注册并立即启动监听器容器(初始化程序此处为 false) if (this.startImmediately) { this.endpointRegistry.registerListenerContainer(descriptor.endpoint, resolveContainerFactory(descriptor), true); } // 如果 startImmediately 标志为 false,则将描述符添加到列表中,稍后启动 else { this.endpointDescriptors.add(descriptor); } } }KafkaListenerEndpointRegistrar是 Spring Kafka 框架中的一个核心类,用于注册和管理 Kafka 消费者监听器。它是@EnableKafka注解处理过程中使用的关键组件,负责将配置的 Kafka 监听器绑定到相应的消费者实例上。该类提供了一种机制,通过程序注册监听器端点,而不仅限于通过注解定义。
该对象为KafkaListenerAnnotationBeanPostProcessor中的属性,如下所示:

这里源码是直接 new 了一个 KafkaListenerEndpointRegistrar,在上面的代码块中,程序启动的过程中其this.startImmediately一定为false:

所以上面的代码只是将KafkaListenerEndpointDescriptor(保存 KafkaListenerEndpoint 和 KafkaListenerContainerFactory 对象的类) 对象保存了起来,直到当KafkaListenerAnnotationBeanPostProcessor执行afterSingletonsInstantiated()方法时,其类中的KafkaListenerEndpointRegistrar被注入了KafkaListenerEndpointRegistry对象,并代码详情如下:// 代码节选自:spring-kafka:3.1.4 KafkaListenerAnnotationBeanPostProcessor:298 @Override public void afterSingletonsInstantiated() { // 设置注册器的 BeanFactory this.registrar.setBeanFactory(this.beanFactory); // 如果 BeanFactory 是 ListableBeanFactory,检索所有 KafkaListenerConfigurer 实例 if (this.beanFactory instanceof ListableBeanFactory lbf) { // 获取所有 KafkaListenerConfigurer 实例 Map<String, KafkaListenerConfigurer> instances = lbf.getBeansOfType(KafkaListenerConfigurer.class); // 遍历所有配置器,并让它们配置 Kafka 监听器 for (KafkaListenerConfigurer configurer : instances.values()) { configurer.configureKafkaListeners(this.registrar); } } // 检查注册器是否已经有一个 endpoint registry,如果没有,则进行设置 if (this.registrar.getEndpointRegistry() == null) { if (this.endpointRegistry == null) { // 确保 BeanFactory 不为空,以便能通过它获取 endpoint registry Assert.state(this.beanFactory != null, "BeanFactory must be set to find endpoint registry by bean name"); // 通过 Bean 名称从 BeanFactory 获取 KafkaListenerEndpointRegistry 实例 this.endpointRegistry = this.beanFactory.getBean( KafkaListenerConfigUtils.KAFKA_LISTENER_ENDPOINT_REGISTRY_BEAN_NAME, KafkaListenerEndpointRegistry.class); } // 设置注册器的 endpoint registry /* * 此处将 KafkaListenerEndpointRegistry 对象注入到了 KafkaListenerEndpointRegistrar 中 */ this.registrar.setEndpointRegistry(this.endpointRegistry); } // 如果指定了默认的 container factory bean 名称,则设置它 if (this.defaultContainerFactoryBeanName != null) { this.registrar.setContainerFactoryBeanName(this.defaultContainerFactoryBeanName); } // 获取并设置消息处理方法工厂 MessageHandlerMethodFactory handlerMethodFactory = this.registrar.getMessageHandlerMethodFactory(); if (handlerMethodFactory != null) { this.messageHandlerMethodFactory.setHandlerMethodFactory(handlerMethodFactory); } else { // 如果没有指定方法工厂,使用默认的格式化和转换服务 addFormatters(this.messageHandlerMethodFactory.defaultFormattingConversionService); } /* * 初始化注册器,注册所有监听器 */ this.registrar.afterPropertiesSet(); // 获取所有 ContainerGroupSequencer 实例,并初始化它们 Map<String, ContainerGroupSequencer> sequencers = this.applicationContext.getBeansOfType(ContainerGroupSequencer.class, false, false); sequencers.values().forEach(ContainerGroupSequencer::initialize); }afterPropertiesSet方法是InitializingBean接口的一部分,该接口由 Spring 框架提供。它用于在一个 bean 的所有属性被 Spring 容器设置之后,但在 bean 被使用之前,执行必要的初始化工作。
调用时机- 属性设置之后: 在 Spring 的 bean 生命周期中,当一个 bean 被实例化后,Spring 容器将通过 setter 注入方法或通过构造函数注入方法注入依赖。一旦所有必要的属性都被设置(包括注入所有必需的依赖),afterPropertiesSet 方法就会被调用。
- 自定义初始化逻辑之前: 这个方法允许开发者在 Spring 执行任何自定义初始化(比如通过 XML 配置或注解配置的 init-method)之前,加入自己的初始化逻辑。
用途
- 资源初始化: 用于开启资源,如数据库连接、网络连接、文件系统等。
- 状态检查: 验证所有必要的属性是否被正确设置,以确保 bean 能正常工作。
- 配置验证: 在 bean 开始执行其核心功能之前,验证配置的正确性。
之后我们再看
KafkaListenerEndpointRegistrar的afterPropertiesSet()方法:// 代码节选自:spring-kafka:3.1.4 KafkaListenerEndpointRegistrar:184 @Override public void afterPropertiesSet() { // 调用注册所有端点的方法 registerAllEndpoints(); } protected void registerAllEndpoints() { // 锁定 endpointDescriptors 对象,保证线程安全 synchronized (this.endpointDescriptors) { // 遍历所有预先配置的端点描述符 for (KafkaListenerEndpointDescriptor descriptor : this.endpointDescriptors) { // 检查是否是 MultiMethodKafkaListenerEndpoint 类型的端点,并且如果设置了 validator,则应用它 if (descriptor.endpoint instanceof MultiMethodKafkaListenerEndpoint<?, ?> mmkle && this.validator != null) { mmkle.setValidator(this.validator); } // 注册监听容器,使用解析后的容器工厂 this.endpointRegistry.registerListenerContainer( descriptor.endpoint, resolveContainerFactory(descriptor)); } // 设置 startImmediately 标志为 true this.startImmediately = true; } }程序在上面通过
registerListenerContainer方法注册监听容器:// 代码节选自:spring-kafka:3.1.4 KafkaListenerEndpointRegistry:211 public void registerListenerContainer(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory, boolean startImmediately) { // 检查 endpoint 和 factory 是否为空 Assert.notNull(endpoint, "Endpoint must not be null"); Assert.notNull(factory, "Factory must not be null"); // 获取 endpoint 的 ID 并确保它不为空 String id = endpoint.getId(); Assert.hasText(id, "Endpoint id must not be empty"); // 锁定容器,以确保注册操作的线程安全 this.containersLock.lock(); try { // 检查是否已经存在具有相同 id 的监听器容器 Assert.state(!this.listenerContainers.containsKey(id), "Another endpoint is already registered with id '" + id + "'"); // **创建监听器容器** // MessageListenerContainer container = createListenerContainer(endpoint, factory); // 将新创建的容器添加到管理容器的映射中 this.listenerContainers.put(id, container); // 获取 Spring 应用上下文 ConfigurableApplicationContext appContext = this.applicationContext; // 获取 endpoint 的组名 String groupName = endpoint.getGroup(); // 如果组名存在并且应用上下文也存在 if (StringUtils.hasText(groupName) && appContext != null) { List<MessageListenerContainer> containerGroup; ContainerGroup group; // 检查是否已存在这个组名的 bean if (appContext.containsBean(groupName)) { // 如果存在,获取这个组的容器列表和组信息 containerGroup = appContext.getBean(groupName, List.class); group = appContext.getBean(groupName + ".group", ContainerGroup.class); } else { // 如果不存在,创建新的容器组和组信息 containerGroup = new ArrayList<MessageListenerContainer>(); appContext.getBeanFactory().registerSingleton(groupName, containerGroup); group = new ContainerGroup(groupName); appContext.getBeanFactory().registerSingleton(groupName + ".group", group); } // 将新创建的容器添加到组中 containerGroup.add(container); group.addContainers(container); } // 如果需要立即启动,则启动容器 if (startImmediately) { startIfNecessary(container); } } finally { // 释放锁 this.containersLock.unlock(); } } // 代码节选自:spring-kafka:3.1.4 KafkaListenerEndpointRegistry:274 protected MessageListenerContainer createListenerContainer(KafkaListenerEndpoint endpoint, KafkaListenerContainerFactory<?> factory) { // 检查 endpoint 是否为 MethodKafkaListenerEndpoint 类型 if (endpoint instanceof MethodKafkaListenerEndpoint) { // 强制转换为 MethodKafkaListenerEndpoint 类型 MethodKafkaListenerEndpoint<?, ?> mkle = (MethodKafkaListenerEndpoint<?, ?>) endpoint; // 获取 endpoint 关联的 bean 对象 Object bean = mkle.getBean(); // 如果 bean 是 EndpointHandlerMethod 类型 if (bean instanceof EndpointHandlerMethod) { // 强制转换为 EndpointHandlerMethod 类型 EndpointHandlerMethod ehm = (EndpointHandlerMethod) bean; // 更新 bean 对象为从应用上下文解析出的实际 bean ehm = new EndpointHandlerMethod(ehm.resolveBean(this.applicationContext), ehm.getMethodName()); // 更新 MethodKafkaListenerEndpoint 的 bean 和 method mkle.setBean(ehm.resolveBean(this.applicationContext)); mkle.setMethod(ehm.getMethod()); } } // **使用工厂创建一个新的 MessageListenerContainer** // MessageListenerContainer listenerContainer = factory.createListenerContainer(endpoint); // 检查新创建的 listenerContainer 是否实现了 InitializingBean 接口 if (listenerContainer instanceof InitializingBean) { try { // 初始化 listenerContainer ((InitializingBean) listenerContainer).afterPropertiesSet(); } catch (Exception ex) { // 在初始化失败时抛出异常 throw new BeanInitializationException("Failed to initialize message listener container", ex); } } // 获取容器的启动阶段 int containerPhase = listenerContainer.getPhase(); // 如果容器需要自动启动并且设置了自定义的启动阶段 if (listenerContainer.isAutoStartup() && containerPhase != AbstractMessageListenerContainer.DEFAULT_PHASE) { // a custom phase value // 检查是否存在启动阶段的冲突 if (this.phase != AbstractMessageListenerContainer.DEFAULT_PHASE && this.phase != containerPhase) { throw new IllegalStateException("Encountered phase mismatch between container " + "factory definitions: " + this.phase + " vs " + containerPhase); } // 更新 this.phase 为当前容器的启动阶段 this.phase = listenerContainer.getPhase(); } // 返回创建的 MessageListenerContainer return listenerContainer; } -
消息监听器的设置
在MessageListenerContainer创建过程中,会设置一个消息监听器来接收消息。这个监听器是实际调用@KafkaListener标注的方法的回调对象。上面的代码中MessageListenerContainer listenerContainer = factory.createListenerContainer(endpoint);方法内容如下:// 代码节选自:spring-kafka:3.1.4 AbstractKafkaListenerContainerFactory:353 @Override public C createListenerContainer(KafkaListenerEndpoint endpoint) { // 创建 Kafka 监听容器的实例 C instance = createContainerInstance(endpoint); // JavaUtils.INSTANCE 是一个实用工具,这里使用它来链式调用设置方法,如果值非空则设置 JavaUtils.INSTANCE .acceptIfNotNull(endpoint.getId(), instance::setBeanName) .acceptIfNotNull(endpoint.getMainListenerId(), instance::setMainListenerId); // 检查 endpoint 是否为 AbstractKafkaListenerEndpoint 类型 if (endpoint instanceof AbstractKafkaListenerEndpoint) { // 如果是,对该 endpoint 进行额外的配置 configureEndpoint((AbstractKafkaListenerEndpoint<K, V>) endpoint); } // 根据 endpoint 是否配置为批量监听器来决定使用哪种消息转换器 if (Boolean.TRUE.equals(endpoint.getBatchListener())) { // 如果是批量监听器,使用 batchMessageConverter 进行设置 endpoint.setupListenerContainer(instance, this.batchMessageConverter); } else { // 如果不是批量监听器,使用 recordMessageConverter 进行设置 endpoint.setupListenerContainer(instance, this.recordMessageConverter); } // 初始化监听容器 initializeContainer(instance, endpoint); // 对监听容器进行自定义配置 customizeContainer(instance, endpoint); // 返回配置好的监听容器实例 return instance; } -
容器的初始化和启动
一旦MessageListenerContainer配置完成,它将被初始化并启动。这个过程中,容器会根据配置连接到 Kafka 服务器,订阅相应的主题,并开始监听消息。
启动的位置如下所示:// 代码节选自:spring-kafka:3.1.4 KafkaListenerEndpointRegistry:333 public void start() { for (MessageListenerContainer listenerContainer : getListenerContainers()) { startIfNecessary(listenerContainer); } this.running = true; } // 代码节选自:spring-kafka:3.1.4 KafkaListenerEndpointRegistry:388 /** * Start the specified {@link MessageListenerContainer} if it should be started * on startup. * @param listenerContainer the listener container to start. * @see MessageListenerContainer#isAutoStartup() */ private void startIfNecessary(MessageListenerContainer listenerContainer) { if ((this.contextRefreshed && this.alwaysStartAfterRefresh) || listenerContainer.isAutoStartup()) { listenerContainer.start(); } }由于
KafkaListenerEndpointRegistry实现了SmartLifecycle接口的start()方法,对于实现SmartLifecycle的组件,Spring 容器会在刷新应用上下文(即初始化所有单例 bean 之后)时根据isAutoStartup()方法的返回值决定是否自动调用start()方法(如果@KafkaListener配置了 autoStartup = “false” 则 isAutoStartup() 方法返回 false)。// 代码节选自:spring-kafka:3.1.4 AbstractMessageListenerContainer:503 @Override public final void start() { checkGroupId(); this.lifecycleLock.lock(); try { if (!isRunning()) { Assert.state(this.containerProperties.getMessageListener() instanceof GenericMessageListener, () -> "A " + GenericMessageListener.class.getName() + " implementation must be provided"); doStart(); } } finally { this.lifecycleLock.unlock(); } } // 代码节选自:spring-kafka:3.1.4 ConcurrentMessageListenerContainer:235 @Override protected void doStart() { // 检查容器是否已经在运行,只在未运行时启动 if (!isRunning()) { // 检查是否已配置监听的主题 checkTopics(); // 获取容器配置属性 ContainerProperties containerProperties = getContainerProperties(); // 获取配置的主题分区 TopicPartitionOffset[] topicPartitions = containerProperties.getTopicPartitions(); // 检查并发级别是否超过了提供的分区数,如果超过,则警告并调整并发级别 if (topicPartitions != null && this.concurrency > topicPartitions.length) { this.logger.warn(() -> "When specific partitions are provided, the concurrency must be less than or " + "equal to the number of partitions; reduced from " + this.concurrency + " to " + topicPartitions.length); // 注意这里,强制将并发数改成最大分数,在设置消费并发时,不用担心分区数量并发超过 this.concurrency = topicPartitions.length; } // 设置容器为运行状态 setRunning(true); // 根据配置的并发级别创建并启动子容器 for (int i = 0; i < this.concurrency; i++) { // 构造每个子容器 KafkaMessageListenerContainer<K, V> container = constructContainer(containerProperties, topicPartitions, i); // 配置子容器 configureChildContainer(i, container); // 如果主容器处于暂停状态,则暂停子容器 if (isPaused()) { container.pause(); } // 启动子容器 container.start(); // 将子容器添加到容器列表中 this.containers.add(container); } } }上面的代码可以看出如果我们将
spring.kafka.listener.concurrency配置的值设置的大于 topicPartitions 的值程序会打印一个警告并将 concurrency 强制设置成 topicPartitions 的数量。KafkaMessageListenerContainer和ConcurrentMessageListenerContainer都继承AbstractMessageListenerContainer这个类,所以它的start()方法实际也是调用的KafkaMessageListenerContainer重写的doStart()方法,如下所示:// 代码节选自:spring-kafka:3.1.4 KafkaMessageListenerContainer:364 @Override protected void doStart() { // 检查容器是否已经在运行,如果是,直接返回 if (isRunning()) { return; } // 如果 clientIdSuffix 为空,意味着这是一个独立容器,检查配置的主题 if (this.clientIdSuffix == null) { checkTopics(); } // 获取容器的属性 ContainerProperties containerProperties = getContainerProperties(); // 检查确认模式是否合法 checkAckMode(containerProperties); // 获取消息监听器对象 Object messageListener = containerProperties.getMessageListener(); // 获取或创建用于消息消费者的任务执行器 AsyncTaskExecutor consumerExecutor = containerProperties.getListenerTaskExecutor(); if (consumerExecutor == null) { consumerExecutor = new SimpleAsyncTaskExecutor( (getBeanName() == null ? "" : getBeanName()) + "-C-"); containerProperties.setListenerTaskExecutor(consumerExecutor); } // 转换消息监听器为 GenericMessageListener 类型 GenericMessageListener<?> listener = (GenericMessageListener<?>) messageListener; // 确定监听器的类型(比如是否是批量监听器) ListenerType listenerType = determineListenerType(listener); // 初始化观测注册表,默认为 NOOP(不操作) ObservationRegistry observationRegistry = ObservationRegistry.NOOP; ApplicationContext applicationContext = getApplicationContext(); // 如果应用上下文非空且容器属性中启用了观测功能 if (applicationContext != null && containerProperties.isObservationEnabled()) { ObjectProvider<ObservationRegistry> registry = applicationContext.getBeanProvider(ObservationRegistry.class); ObservationRegistry reg = registry.getIfUnique(); if (reg != null) { observationRegistry = reg; } } // 创建监听消费者 this.listenerConsumer = new ListenerConsumer(listener, listenerType, observationRegistry); // 设置容器为运行状态 setRunning(true); // 初始化启动倒计时锁 this.startLatch = new CountDownLatch(1); // 提交监听消费者到任务执行器,并获取将来的结果 this.listenerConsumerFuture = consumerExecutor.submitCompletable(this.listenerConsumer); try { // 等待消费者启动,超时时间从容器属性中获取 if (!this.startLatch.await(containerProperties.getConsumerStartTimeout().toMillis(), TimeUnit.MILLISECONDS)) { // 如果消费者线程启动失败,记录错误日志 this.logger.error("Consumer thread failed to start - does the configured task executor " + "have enough threads to support all containers and concurrency?"); // 发布启动失败的事件 publishConsumerFailedToStart(); } } catch (@SuppressWarnings("unused") InterruptedException e) { // 如果在等待过程中被中断,重新设置中断状态 Thread.currentThread().interrupt(); } }上面代码中的
ListenerConsumer,这个类实现了Runnable接口(SchedulingAwareRunnable继承了Runnable)并重写了run方法,如下图所示:
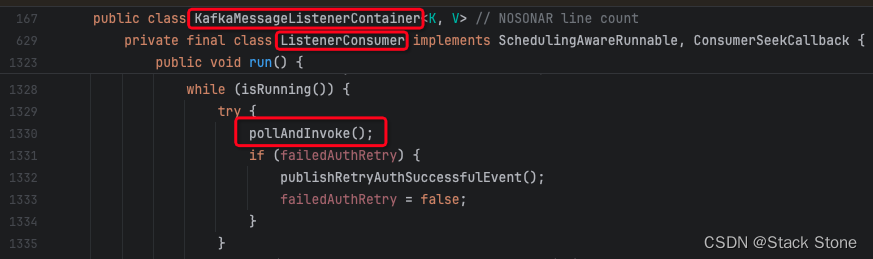
ListenerConsumer是 Spring Kafka 中的核心类,负责封装 Kafka 消费者的关键操作,包括从 Kafka 队列拉取消息、将消息派发到相应的监听器(如通过 @KafkaListener 注解定义的方法)、管理消息的偏移量提交(支持自动和手动模式),以及处理消息消费过程中的错误。这里对于消息的处理流程就比较繁琐了,这里就不做过多的赘述,感兴趣的可以自己 Debug 调试看看。对于上面的流程我这里附上我看源码的主要的断点:
5. 动态监听消费订阅的设计与实现
在详细的了解了上面的关于 @KafkaListener 的执行原理后,我们就可以初步进行设计。
完整的项目 Demo 已上传至 Github 地址:https://github.com/lt5227/example_code/tree/main/spring_kafka_example
可以自行下载下来后进行查看
该样例项目集成了 Knife4J 和 Liquibase,数据库使用 MySQL
SpingBoot:3.2.5
JDK:21
启动项目只需要在application.yml修改数据库的连接信息,并创建一个空的数据库,项目启动后会自动创建表结构和插入 Demo 数据,样例代码实现了动态注册和接口控制启停消费程序的样例,大家可以进行参考结合到自己的项目中。
访问接口文档地址:http://localhost:9898/doc.html
首先我们先在 mysql 中建一张表,用来维护我们动态的配置信息,表如下所示:
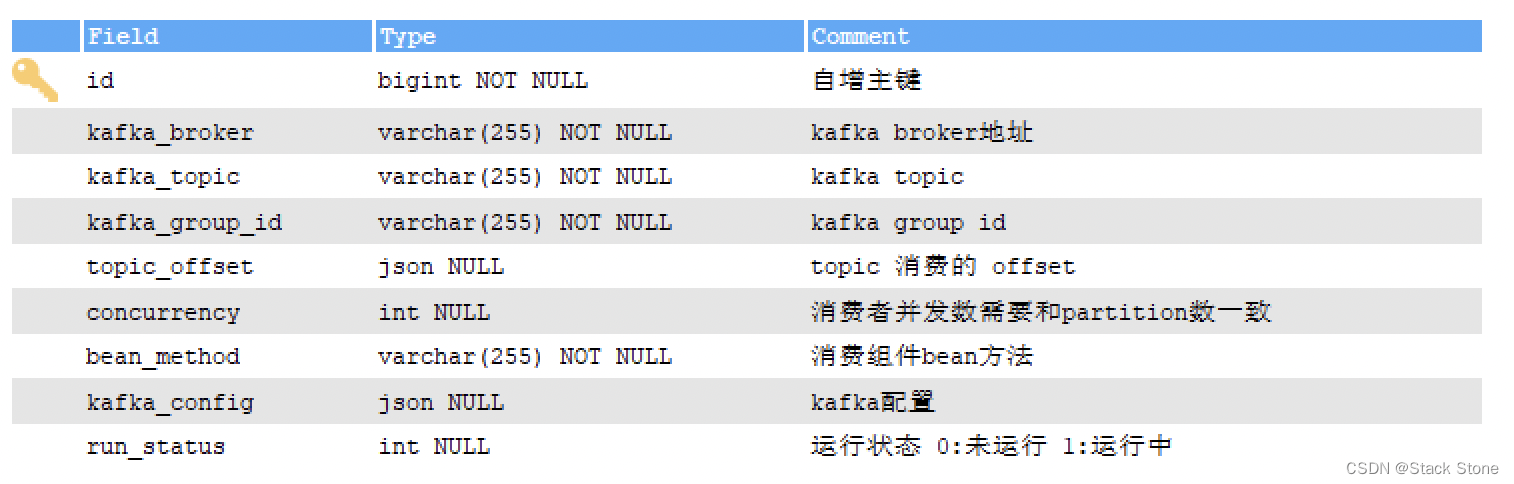
之后我们可以在项目中定义一个组件,当服务启动后该组件读取数据库中的配置初始化消费程序,大致代码如下:
@Component
public class KafkaConfig {
// 注入 Kafka 消费者配置服务
private final KafkaConsumerConfigService kafkaConsumerConfigService;
// 注入 Kafka 监听器端点注册表
private final KafkaListenerEndpointRegistry registry;
// 注入 Kafka 监听器注解处理器
private final KafkaListenerAnnotationBeanPostProcessor<String, String> postProcessor;
// 存储 Kafka 消费者工厂的映射,使用并发哈希映射保证线程安全
@Getter
private Map<String, DefaultKafkaConsumerFactory<String, String>> consumerFactoryMap = new ConcurrentHashMap<>();
/**
* 构造函数注入所需的组件
* @param registry Kafka 监听器端点注册表
* @param postProcessor Kafka 监听器注解处理器
* @param kafkaConsumerConfigService Kafka 消费者配置服务
*/
public KafkaConfig(KafkaListenerEndpointRegistry registry,
KafkaListenerAnnotationBeanPostProcessor postProcessor,
KafkaConsumerConfigService kafkaConsumerConfigService) {
this.registry = registry;
this.postProcessor = postProcessor;
this.kafkaConsumerConfigService = kafkaConsumerConfigService;
}
/**
* 使用 @PostConstruct 注解确保此方法在依赖注入完成后自动执行
*/
@PostConstruct
@SneakyThrows
public void init() {
// 查询所有 Kafka 消费者配置
List<KafkaConsumerConfig> kafkaConsumerConfigs = kafkaConsumerConfigService.findAll();
// 获取消息处理方法工厂
MessageHandlerMethodFactory methodFactory = postProcessor.getMessageHandlerMethodFactory();
for (KafkaConsumerConfig kafkaConsumerConfig : kafkaConsumerConfigs) {
// 获取 Kafka broker 地址
String kafkaBroker = kafkaConsumerConfig.getKafkaBroker();
// 如果工厂映射中尚未有此 broker 的工厂,创建一个
if (!consumerFactoryMap.containsKey(kafkaBroker)) {
// 获取 Kafka 配置,如果为空则使用一个新的 JSONObject
JSONObject props = Optional.ofNullable(kafkaConsumerConfig.getKafkaConfig()).orElse(new JSONObject());
// 设置 Kafka 的基本连接配置
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, kafkaBroker);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 创建并存储 Kafka 消费者工厂
DefaultKafkaConsumerFactory<String, String> consumerFactory = new DefaultKafkaConsumerFactory<>(props);
consumerFactoryMap.put(kafkaBroker, consumerFactory);
}
// 从映射中获取 Kafka 消费者工厂
DefaultKafkaConsumerFactory<String, String> consumerFactory = consumerFactoryMap.get(kafkaBroker);
// 创建 Kafka 监听器容器工厂
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory);
// 设置并发量
factory.setConcurrency(kafkaConsumerConfig.getConcurrency());
// 创建方法级 Kafka 监听器端点
MethodKafkaListenerEndpoint<String, String> endpoint = new MethodKafkaListenerEndpoint<>();
// 解析方法字符串为类和方法的引用
ClassMethodArgs classMethodArgs = ClassMethodArgs.parseMethod(kafkaConsumerConfig.getBeanMethod());
Class<? extends DynamicConsumer> clazz = (Class<? extends DynamicConsumer>) Class.forName(classMethodArgs.getClassName());
// 创建类实例
Constructor<?> constructor = clazz.getDeclaredConstructor(long.class);
endpoint.setBean(constructor.newInstance(kafkaConsumerConfig.getId()));
// 设置方法
Method method = ReflectionUtils.findMethod(clazz, classMethodArgs.getMethod(), classMethodArgs.getArgsClasses());
endpoint.setMethod(method);
// 设置消息处理方法工厂
endpoint.setMessageHandlerMethodFactory(methodFactory);
// 设置端点 ID 和组 ID
endpoint.setId("DynamicConsumer-" + kafkaConsumerConfig.getId());
endpoint.setGroupId(kafkaConsumerConfig.getKafkaGroupId());
// 设置监听的主题
endpoint.setTopics(kafkaConsumerConfig.getKafkaTopic());
// 设置端点的并发量
endpoint.setConcurrency(kafkaConsumerConfig.getConcurrency());
// 设置为批处理监听器
endpoint.setBatchListener(true);
// 注册监听器容器
registry.registerListenerContainer(endpoint, factory, false);
}
// 启动所有注册的监听器容器
registry.start();
}
}
数据库中有如下数据:
[
{
"id": 1,
"kafka_broker": "127.0.0.1:9092",
"kafka_topic": "dynamic_topic",
"kafka_group_id": "dynamic_group1",
"topic_offset": null,
"concurrency": 1,
"bean_method": "com.stackstone.example.spring.kafka.consumer.DemoDynamicConsumer#consumeMessage01(java.util.List)",
"kafka_config": {
"max.poll.records": 10,
"auto.offset.reset": "earliest",
"auto.commit.interval.ms": 5000
},
"run_status": 0
}
]
项目启动后,程序读取查询到上面的数据后动态注册了监听器,其中 kafka_config 可以根据自己的需求进行配置的调整,项目启动后监听器自动消费每次消费完成后会自动的更新数据库中 topic 的消费 offset(这里可以根据自己的需求调整)

消费程序如下所示:
@Slf4j
public class DemoDynamicConsumer extends DynamicConsumer {
public DemoDynamicConsumer(long kafkaConsumerConfigId) {
super(kafkaConsumerConfigId);
}
public void consumeMessage01(@Payload List<ConsumerRecord<String, String>> consumerRecords) {
log.info("consumer01 received message count:{}", consumerRecords.size());
processMessage(consumerRecords);
}
private void processMessage(List<ConsumerRecord<String, String>> consumerRecords) {
Map<TopicPartition, Long> seekConfiguration = new HashMap<>();
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
log.info("message content: {}", consumerRecord);
updateTopicPartitionOffset(consumerRecord, seekConfiguration);
}
KafkaConsumerConfigService kafkaConsumerConfigService = SpringUtil.getBean(KafkaConsumerConfigService.class);
seekConfiguration.forEach((topicPartition, offset) -> {
kafkaConsumerConfigService.recordKafkaOffset(kafkaConsumerConfigId, topicPartition.partition(), offset);
});
}
private void updateTopicPartitionOffset(ConsumerRecord<String, String> consumerRecord, Map<TopicPartition, Long> seekConfiguration) {
String topic = consumerRecord.topic();
int partition = consumerRecord.partition();
TopicPartition topicPartition = new TopicPartition(topic, partition);
Long offset = seekConfiguration.get(topicPartition);
if (offset == null) {
seekConfiguration.put(topicPartition, consumerRecord.offset());
} else {
seekConfiguration.put(topicPartition, Math.max(offset, consumerRecord.offset()));
}
}
}
由于 demo 样例中每次消费完数据都会更新 offset 到数据库中,此处需要将数据库中数据的主键 id 传递到这个类中,并且在每次启动的时候需要读取数据库中的 offset 进行 seek 操作,所以中间定义了一个 DynamicConsumer 这个类,它实现了 ConsumerSeekAware 接口。这个接口用于当 Kafka 消费者的分区被分配后,允许消费者在指定的偏移量(offset)处开始消费消息。:
public class DynamicConsumer implements ConsumerSeekAware {
// 成员变量,存储 Kafka 消费者配置的 ID
protected long kafkaConsumerConfigId;
// 构造函数,初始化 kafkaConsumerConfigId
public DynamicConsumer(long kafkaConsumerConfigId) {
this.kafkaConsumerConfigId = kafkaConsumerConfigId;
}
// 当分区被分配给这个消费者时,此方法被调用
@Override
public void onPartitionsAssigned(Map<TopicPartition, Long> assignments, ConsumerSeekCallback callback) {
// 从 Spring 容器中获取 KafkaConsumerConfigService 实例
KafkaConsumerConfigService kafkaConsumerConfigService = SpringUtil.getBean(KafkaConsumerConfigService.class);
// 通过服务获取 Kafka 消费者的偏移量配置
JSONObject kafkaOffsetJson = kafkaConsumerConfigService.getKafkaOffset(kafkaConsumerConfigId);
// 遍历分配给消费者的所有分区
assignments.keySet().forEach(partition -> {
// 从 JSON 对象中获取对应分区的偏移量
Long offset = kafkaOffsetJson.getLong(partition.topic() + "$" + partition.partition());
// 如果没有获取到偏移量,则默认从 0 开始消费
if (offset == null) {
offset = 0L;
}
// 使用回调设置消费的起始偏移量
callback.seek(partition.topic(), partition.partition(), offset);
});
}
}
关于启停消费程序,我们编写控制层代码如下:
// 控制层部分代码
@GetMapping("/stopTest")
@Operation(summary = "停止消费程序",description = "停止消费程序")
public String testStop(Long id) {
kafkaConsumerConfigService.stopConsumer(id);
return "success";
}
@GetMapping("/startTest")
@Operation(summary = "开启消费程序", description = "开启消费程序")
public String testStart(Long id) {
kafkaConsumerConfigService.startConsumer(id);
return "success";
}
业务层代码如下:
// 业务层代码
@Service
public class KafkaConsumerConfigService {
// 注入Kafka监听器端点注册表,用于管理Kafka消费者容器
private final KafkaListenerEndpointRegistry registry;
// 构造函数注入Kafka配置存储库和Kafka监听器端点注册表
public KafkaConsumerConfigServiceImpl(KafkaConfigRepository kafkaConfigRepository,
KafkaListenerEndpointRegistry registry) {
this.registry = registry;
}
// 停止特定ID的Kafka消费者
public void stopConsumer(Long id) {
// 通过ID查找Kafka消费者配置,如果找不到则抛出异常
KafkaConsumerConfig kafkaConsumerConfig = kafkaConfigRepository.findById(id).orElseThrow();
// 构造消费者容器的ID
String containerId = "DynamicConsumer-" + kafkaConsumerConfig.getId();
// 从注册表中获取对应的消费者容器
MessageListenerContainer container = registry.getListenerContainer(containerId);
// 如果容器存在,则停止容器
if (container != null) {
container.stop();
}
}
// 启动特定ID的Kafka消费者
public void startConsumer(Long id) {
// 通过ID查找Kafka消费者配置,如果找不到则抛出异常
KafkaConsumerConfig kafkaConsumerConfig = kafkaConfigRepository.findById(id).orElseThrow();
// 构造消费者容器的ID
String containerId = "DynamicConsumer-" + kafkaConsumerConfig.getId();
// 从注册表中获取对应的消费者容器
MessageListenerContainer container = registry.getListenerContainer(containerId);
// 如果容器存在,则启动容器
if (container != null) {
container.start();
}
}
}
之后我们请求接口:
-
停止监听消费:
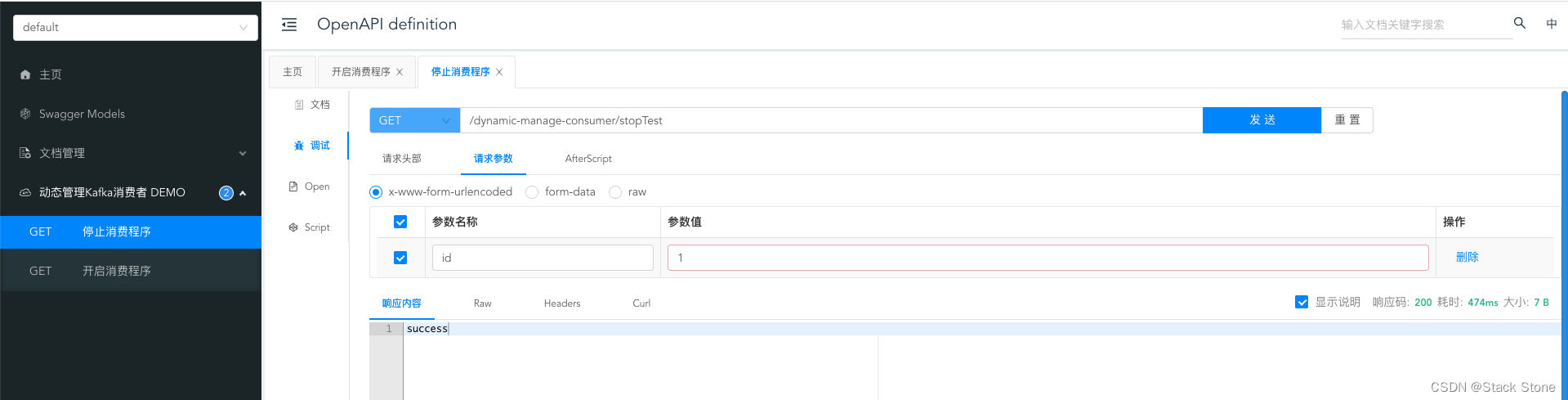
请求成功控制台打印:

-
启动监听消费:
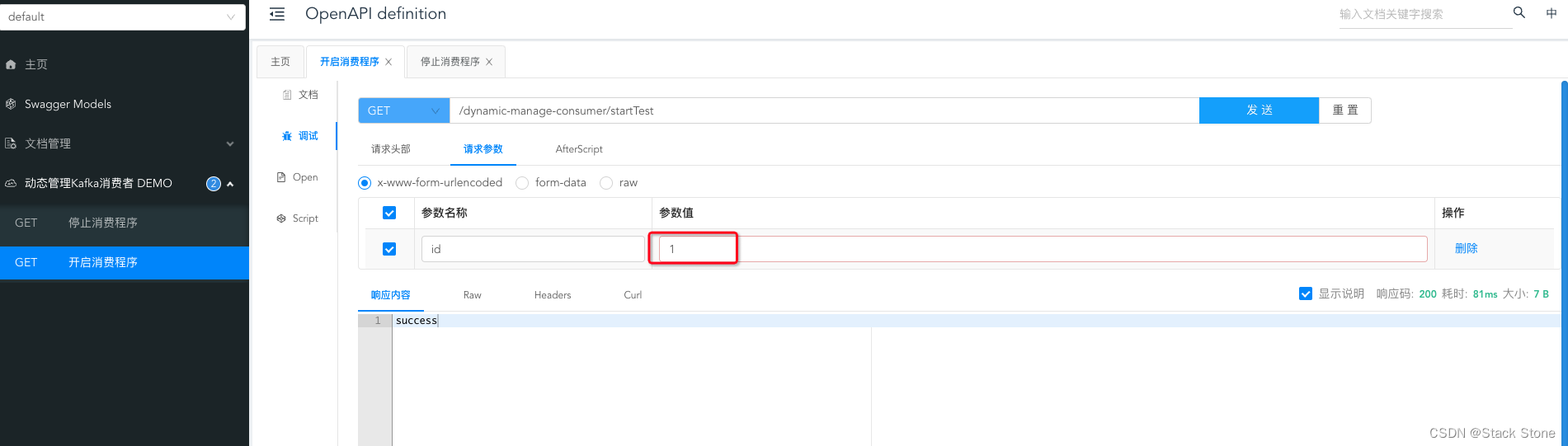
请求成果控制台打印:

并且启动的 Consumer 会读取数据库的 offset 后 seek 后进行消费。