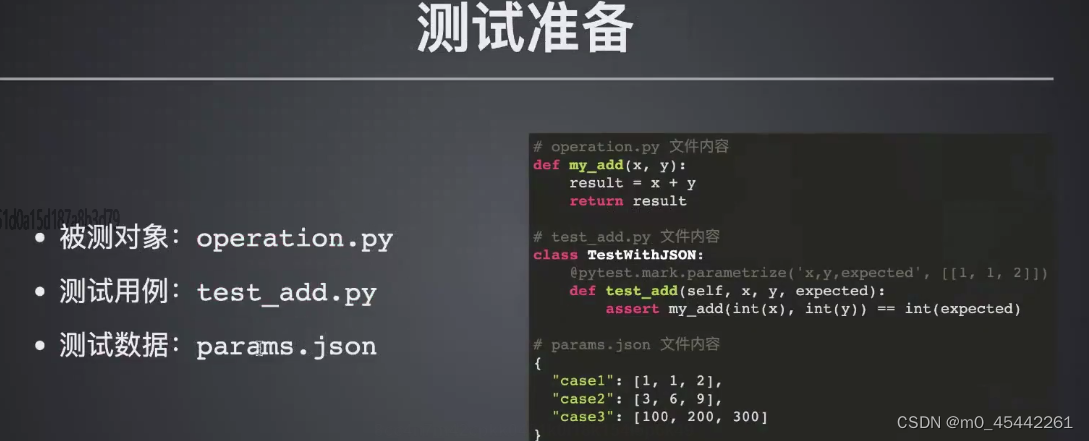
划分数据集
1.创建训练集文件夹和测试集文件夹
# 创建 train 文件夹
os.mkdir(os.path.join(dataset_path, 'train'))
# 创建 test 文件夹
os.mkdir(os.path.join(dataset_path, 'val'))
# 在 train 和 test 文件夹中创建各类别子文件夹
for Retinopathy in classes:
os.mkdir(os.path.join(dataset_path, 'train', Retinopathy))
os.mkdir(os.path.join(dataset_path, 'val', Retinopathy))2.划分训练集、测试集,移动文件
test_frac = 0.2 # 测试集比例
random.seed(123) # 随机数种子,用来打乱数据集
df = pd.DataFrame()
print('{:^18} {:^18} {:^18}'.format('类别', '训练集数据个数', '测试集数据个数'))
for Retinopathy in classes: # 遍历每个类别
# 读取该类别的所有图像文件名
old_dir = os.path.join(dataset_path, Retinopathy)
images_filename = os.listdir(old_dir)
random.shuffle(images_filename) # 随机打乱
# 划分训练集和测试集
testset_numer = int(len(images_filename) * test_frac) # 测试集图像个数
testset_images = images_filename[:testset_numer] # 获取拟移动至 test 目录的测试集图像文件名
trainset_images = images_filename[testset_numer:] # 获取拟移动至 train 目录的训练集图像文件名
# 移动图像至 test 目录
for image in testset_images:
old_img_path = os.path.join(dataset_path, Retinopathy, image) # 获取原始文件路径
new_test_path = os.path.join(dataset_path, 'val', Retinopathy, image) # 获取 test 目录的新文件路径
shutil.move(old_img_path, new_test_path) # 移动文件
# 移动图像至 train 目录
for image in trainset_images:
old_img_path = os.path.join(dataset_path, Retinopathy, image) # 获取原始文件路径
new_train_path = os.path.join(dataset_path, 'train', Retinopathy, image) # 获取 train 目录的新文件路径
shutil.move(old_img_path, new_train_path) # 移动文件
# 删除旧文件夹
assert len(os.listdir(old_dir)) == 0 # 确保旧文件夹中的所有图像都被移动走
shutil.rmtree(old_dir) # 删除文件夹
# 工整地输出每一类别的数据个数
print('{:^18} {:^18} {:^18}'.format(Retinopathy, len(trainset_images), len(testset_images)))
# 保存到表格中
df = df.append({'class':Retinopathy, 'trainset':len(trainset_images), 'testset':len(testset_images)}, ignore_index=True)
# 重命名数据集文件夹
shutil.move(dataset_path, dataset_name+'_split')
# 数据集各类别数量统计表格,导出为 csv 文件
df['total'] = df['trainset'] + df['testset']
df.to_csv('数据量统计.csv', index=False)结果如下:

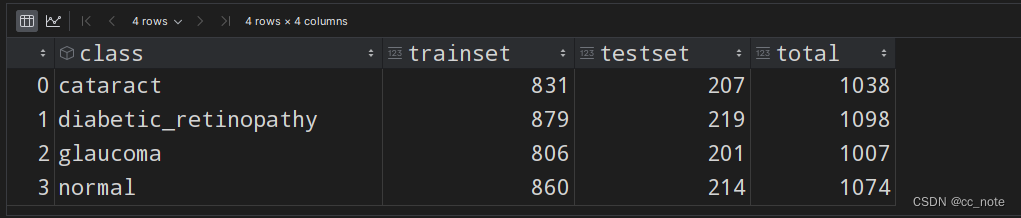
统计各类别数据个数柱状图
1.导入工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline2.设置matplotlib的中文字体,因为它默认无法写中文字体
plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False # 用来正常显示负号3.指定可视化的特征
feature = 'total'
# feature = 'trainset'
# feature = 'testset'
df = df.sort_values(by=feature, ascending=False)4.通过柱状图展示出来
plt.figure(figsize=(22, 7))
x = df['class']
y = df[feature]
plt.bar(x, y, facecolor='#1f77b4', edgecolor='k')
plt.xticks(rotation=90)
plt.tick_params(labelsize=15)
plt.xlabel('类别', fontsize=20)
plt.ylabel('图像数量', fontsize=20)
# plt.savefig('各类别图片数量.pdf', dpi=120, bbox_inches='tight')
plt.show()结果如下:
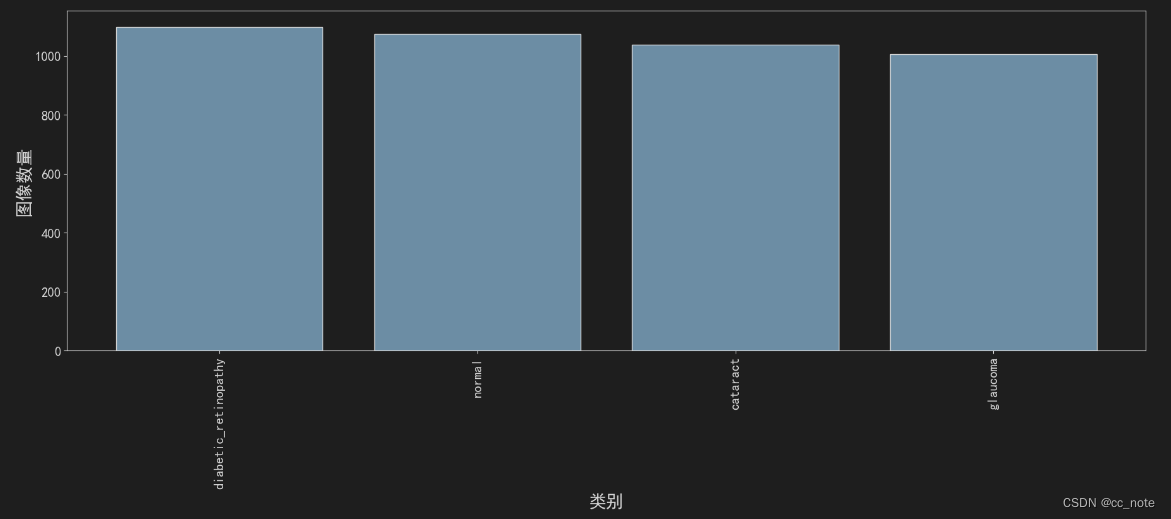
由此可见,数据集是比较均衡的。
5.将训练集与测试集的比例展示出来
plt.figure(figsize=(22, 7))
x = df['class']
y1 = df['testset']
y2 = df['trainset']
width = 0.55 # 柱状图宽度
plt.xticks(rotation=90) # 横轴文字旋转
plt.bar(x, y1, width, label='测试集')
plt.bar(x, y2, width, label='训练集', bottom=y1)
plt.xlabel('类别', fontsize=20)
plt.ylabel('图像数量', fontsize=20)
plt.tick_params(labelsize=13) # 设置坐标文字大小
plt.legend(fontsize=16) # 图例
# 保存为高清的 pdf 文件
plt.savefig('各类别图像数量.pdf', dpi=120, bbox_inches='tight')
plt.show()结果如下:
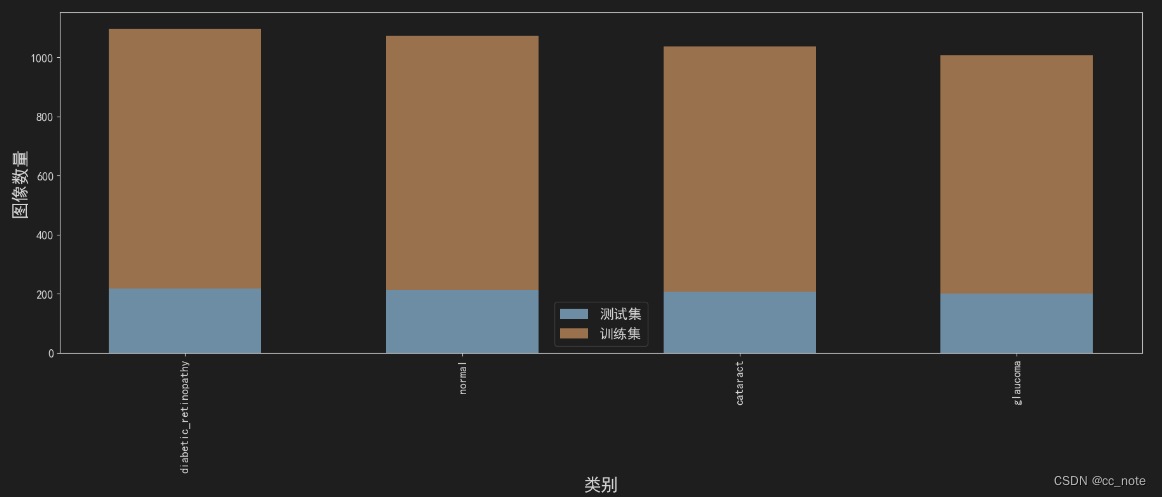
处理完数据集后,就可以开始通过迁移学习训练病变分类模型。
安装配置环境
1.numpy、pandas、matplotlib、seaborn、plotly、requests、tqdm、opencv-python、pillow、wandb和pytorch均已安装完成
2.创建三个文件夹
import os
# 存放结果文件
os.mkdir('output')
# 存放训练得到的模型权重
os.mkdir('checkpoint')
# 存放生成的图表
os.mkdir('图表')迁移学习训练过程与前处理
1.导入包
import time
import os
import numpy as np
from tqdm import tqdm
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")2.获取计算机的硬件,使用CPU还是GPU
# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)3.图像预处理
from torchvision import transforms
# 训练集图像预处理:缩放裁剪、图像增强、转 Tensor、归一化
train_transform = transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 测试集图像预处理:缩放、裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])对训练集和测试集分别进行预处理。
训练集的预处理中,RandomResizedCrop(224)表示随机选择一个面积比例,并在该比例下随机裁剪图像,然后将裁剪后的图像缩放到指定的尺寸,参数 224 指定了裁剪并缩放后的图像尺寸应该是 224x224 像素。RandomHorizontalFlip()是进行随机的水平翻转,目的是图像增强。最后转成pytorch的tensor格式进行归一化。归一化的6个参数约定俗成。
4.载入图像分类数据集
from torchvision import datasets
# 数据集文件夹路径
dataset_dir = 'E:\科研实验\Train_Custom_Dataset-main\图像分类\dataset_split'
train_path = os.path.join(dataset_dir, 'train')
test_path = os.path.join(dataset_dir, 'val')
# 载入训练集
train_dataset = datasets.ImageFolder(train_path, train_transform)
# 载入测试集
test_dataset = datasets.ImageFolder(test_path, test_transform)结果如下:


5.类别和索引号一一对应,方便后续的查询
# 映射关系:索引号 到 类别
idx_to_labels = {y:x for x,y in train_dataset.class_to_idx.items()}
# 保存为本地的 npy 文件
np.save('idx_to_labels.npy', idx_to_labels)
np.save('labels_to_idx.npy', train_dataset.class_to_idx)6.定义数据加载器DataLoader
from torch.utils.data import DataLoader
BATCH_SIZE = 32
# 训练集的数据加载器
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4
)
# 测试集的数据加载器
test_loader = DataLoader(test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=4
)7.可视化一个batch的图像和标注
# 将数据集中的Tensor张量转为numpy的array数据类型
images = images.numpy()举个例子,images[5].shape展示的是一个批次中第五张图片的信息,结果如下:
![]()
images[5]的像素分布如下所示:
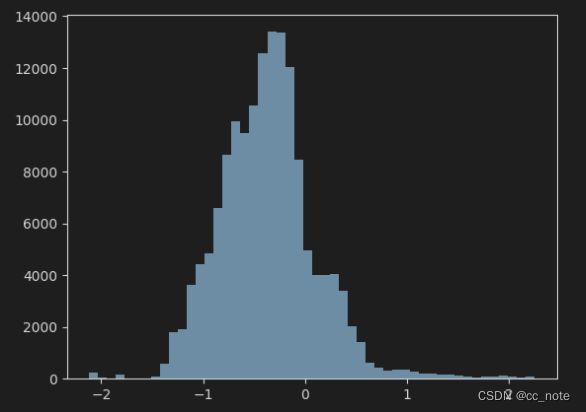
显示上图所用代码为:
plt.hist(images[5].flatten(), bins=50)
plt.show()之前通过预处理归一化,已经将每一个像素都减去它所在通道的均值,再除以它所在通道的标准差了,所以现在的像素不再分布在0~255的整数范围内,而是一个以0为均值的,有正有负的分布。这样的分布更容易被神经网络处理,正如上图所示。
归一化后的图像如下所示:
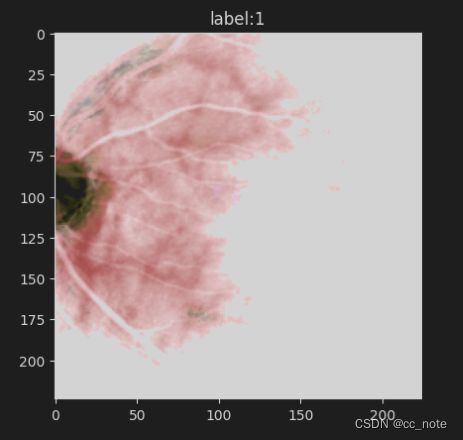
显示上图所用代码为:
# batch 中经过预处理的图像
idx = 5
plt.imshow(images[idx].transpose((1,2,0))) # 转为(224, 224, 3)
plt.title('label:'+str(labels[idx].item()))此图的原图像为:
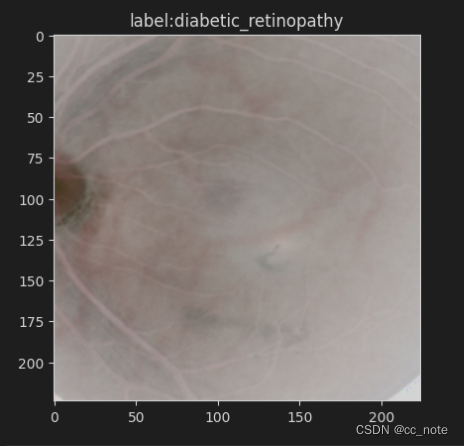
显示上图所用代码为:
# 原始图像
idx = 5
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
plt.imshow(np.clip(images[idx].transpose((1,2,0)) * std + mean, 0, 1))
plt.title('label:'+ pred_classname)
plt.show()8.选择迁移学习训练的方式
视网膜图像和ImageNet的分布不是很一致,所以这里采用“微调训练所有层”的方式
①调整训练所有层
model = model.to(device)
# 交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 训练轮次 Epoch
EPOCHS = 30
# 学习率降低策略
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5)②函数:在训练集上训练
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import roc_auc_score
def train_one_batch(images, labels):
'''
运行一个 batch 的训练,返回当前 batch 的训练日志
'''
# 获得一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
loss = criterion(outputs, labels) # 计算当前 batch 中,每个样本的平均交叉熵损失函数值
# 优化更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 获取当前 batch 的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
log_train = {}
log_train['epoch'] = epoch
log_train['batch'] = batch_idx
# 计算分类评估指标
log_train['train_loss'] = loss
log_train['train_accuracy'] = accuracy_score(labels, preds)
# log_train['train_precision'] = precision_score(labels, preds, average='macro')
# log_train['train_recall'] = recall_score(labels, preds, average='macro')
# log_train['train_f1-score'] = f1_score(labels, preds, average='macro')
return log_train返回的log_train是训练日志
③函数:在整个测试集上评估
def evaluate_testset():
'''
在整个测试集上评估,返回分类评估指标日志
'''
loss_list = []
labels_list = []
preds_list = []
with torch.no_grad():
for images, labels in test_loader: # 生成一个 batch 的数据和标注
images = images.to(device)
labels = labels.to(device)
outputs = model(images) # 输入模型,执行前向预测
# 获取整个测试集的标签类别和预测类别
_, preds = torch.max(outputs, 1) # 获得当前 batch 所有图像的预测类别
preds = preds.cpu().numpy()
loss = criterion(outputs, labels) # 由 logit,计算当前 batch 中,每个样本的平均交叉熵损失函数值
loss = loss.detach().cpu().numpy()
outputs = outputs.detach().cpu().numpy()
labels = labels.detach().cpu().numpy()
loss_list.append(loss)
labels_list.extend(labels)
preds_list.extend(preds)
log_test = {}
log_test['epoch'] = epoch
# 计算分类评估指标
log_test['test_loss'] = np.mean(loss_list)
log_test['test_accuracy'] = accuracy_score(labels_list, preds_list)
log_test['test_precision'] = precision_score(labels_list, preds_list, average='macro')
log_test['test_recall'] = recall_score(labels_list, preds_list, average='macro')
log_test['test_f1-score'] = f1_score(labels_list, preds_list, average='macro')
return log_test返回的log_test是测试日志
④登录wandb(可在网页、手机、iPad上实时监控日志)
安装 wandb:pip install wandb
登录 wandb:在命令行中运行wandb login
按提示复制粘贴API Key至命令行中
⑤创建wandb可视化项目
import wandb
wandb.init(project='视网膜病变', name=time.strftime('%m%d%H%M%S'))⑥运行训练
for epoch in range(1, EPOCHS+1):
print(f'Epoch {epoch}/{EPOCHS}')
## 训练阶段
model.train()
for images, labels in tqdm(train_loader): # 获得一个 batch 的数据和标注
batch_idx += 1
log_train = train_one_batch(images, labels)
df_train_log = df_train_log.append(log_train, ignore_index=True)
wandb.log(log_train)
lr_scheduler.step()
## 测试阶段
model.eval()
log_test = evaluate_testset()
df_test_log = df_test_log.append(log_test, ignore_index=True)
wandb.log(log_test)
# 保存最新的最佳模型文件
if log_test['test_accuracy'] > best_test_accuracy:
# 删除旧的最佳模型文件(如有)
old_best_checkpoint_path = 'checkpoint/best-{:.3f}.pth'.format(best_test_accuracy)
if os.path.exists(old_best_checkpoint_path):
os.remove(old_best_checkpoint_path)
# 保存新的最佳模型文件
best_test_accuracy = log_test['test_accuracy']
new_best_checkpoint_path = 'checkpoint/best-{:.3f}.pth'.format(log_test['test_accuracy'])
torch.save(model, new_best_checkpoint_path)
print('保存新的最佳模型', 'checkpoint/best-{:.3f}.pth'.format(best_test_accuracy))
# best_test_accuracy = log_test['test_accuracy']
df_train_log.to_csv('训练日志-训练集.csv', index=False)
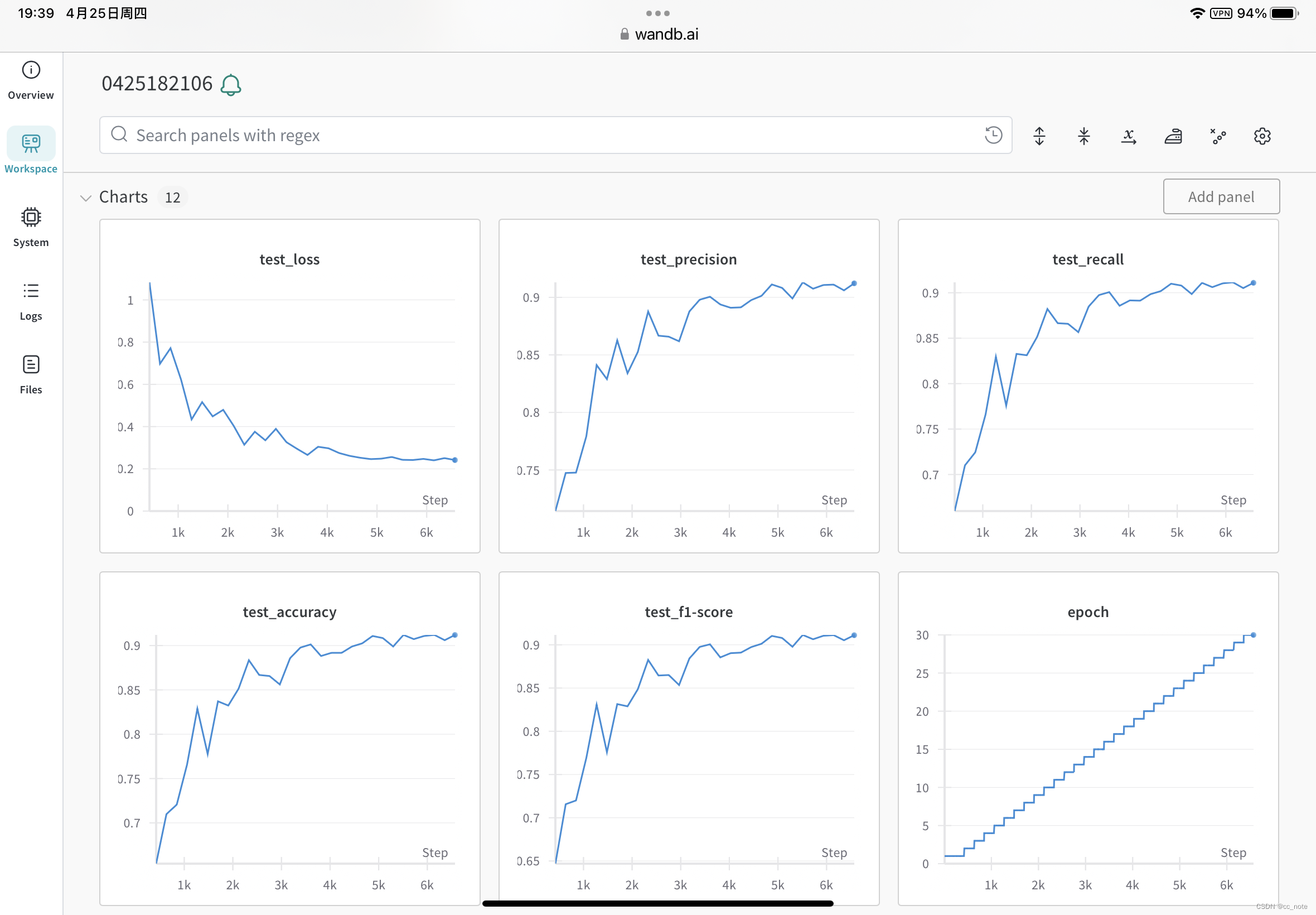
df_test_log.to_csv('训练日志-测试集.csv', index=False)wandb的监控结果如下所示:

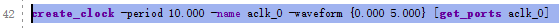
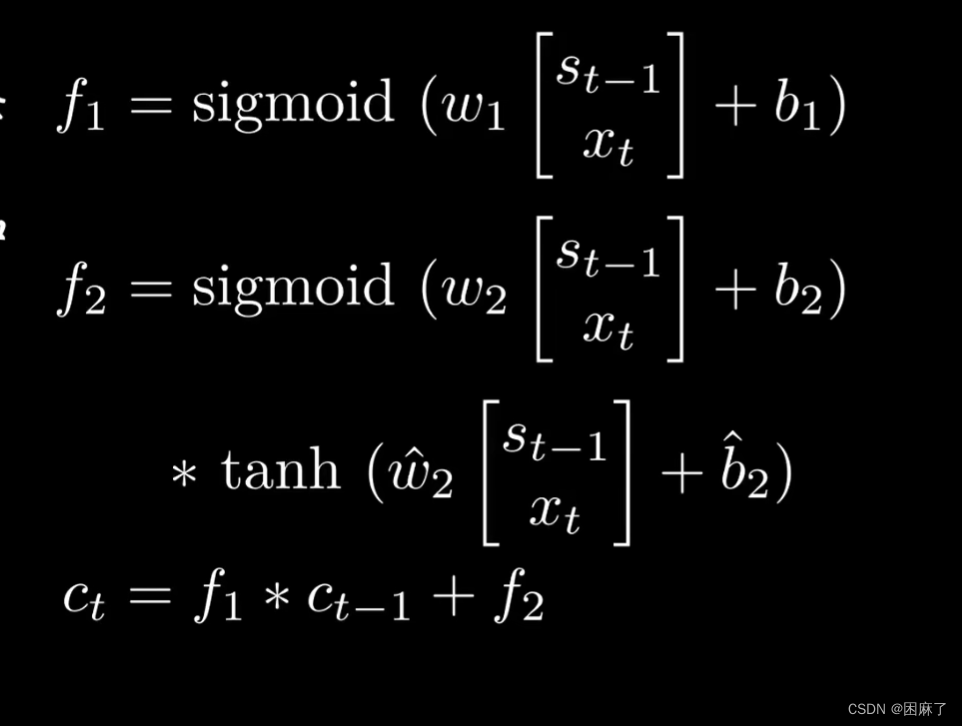







![[iOS]CocoaPods安装和使用](https://img-blog.csdnimg.cn/direct/cc42417e4af84707b6741df16c17fe91.png)