**
![]()
爬虫概述
Python网络爬虫是利用Python编程语言编写的程序,通过互联网爬取特定网站的信息,并将其保存到本地计算机或数据库中。
"""
批量爬取各城市房价走势涨幅top10和跌幅top10
"""
from lxml import etree
import requests
HEADERS = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
INDEX = "https://bj.fangjia.com/zoushi"
def process_index(url):
"""
首页处理
@param url: url
@return: 返回首页源代码
"""
res = requests.request("GET", url=url, headers=HEADERS)
res.encoding = "utf-8"
return res.text
def process_city(html):
"""
各城市首页url获取
@param html: 源代码
@return: 返回各城市名和url
"""
parse = etree.HTML(html)
text = parse.xpath('//div[@class="tab_content"]/div')
city_name = []
city_url = []
for i in text:
city_name.extend(i.xpath("./a/text()"))
city_url.extend(i.xpath("./a/@href"))
city_info = dict(zip(city_name,city_url))
return city_info
def process_trend(html):
"""
各城市小区涨跌top处理
@param html: 网页源码
@return: 各城市小区名,房价基本信息
"""
parse = etree.HTML(html)
area = parse.xpath('//div[@class="trend trend03"]/div/div//tbody/tr')
plot_name = []
info = []
for tr in area:
plot_name.extend(tr.xpath("./td/a/text()"))
plot_info = tr.xpath("./td/text()")
base_info = ','.join(plot_info)
info.append(base_info)
plot_intend = dict(zip(plot_name,info))
return plot_intend
if __name__ == '__main__':
index_html = process_index(INDEX)
city_dict = process_city(index_html)
# 记录到文件中
f = open('全国各城市房价小区涨跌top10_by_xpath.txt',"w", encoding="utf-8")
# 批量获取各城市房价涨跌幅top10
for city_name, city_url in city_dict.items():
# 城市首页处理
city_html = process_index(city_url)
# 房价涨跌top10
plot_intend = process_trend(city_html)
if bool(plot_intend):
for k,value in plot_intend.items():
f.write(f"城市{city_name}----小区名--{k}---房价基本信息{value}\n")
print(f"城市{city_name}----小区名{k}下载完毕....")
else:
f.write(f"城市{city_name}无涨幅小区top10\n")
f.write(f"-------------------城市{city_name}分隔线--------------------------\n")
f.close()
发起请求
一般来说,对于不是接口返回的数据,爬虫首先要做的就是获取网页源代码,网页源代码中有我们需要的数据。

def process_index(url):
"""
首页处理
@param url: url
@return: 返回首页源代码
"""
res = requests.request("GET", url=url, headers=HEADERS)
res.encoding = "utf-8"
return res.text以上片段代码就是获取首页源代码。
提取信息
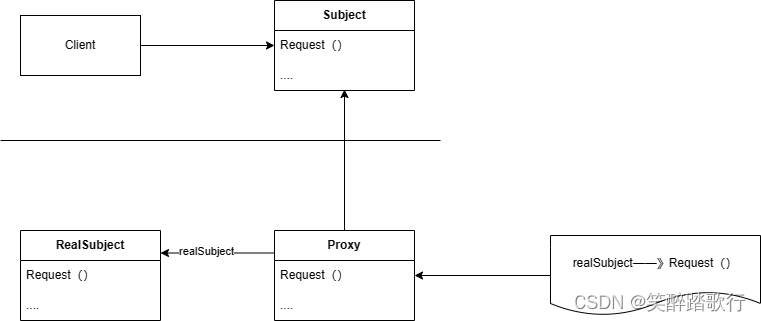
获取网页源代码后,接下来就是分析网页源代码,从中提取我们想要的数据。 首先,最通用的方法便是采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。
def process_city(html):
"""
各城市首页url获取
@param html: 源代码
@return: 返回各城市名和url
"""
parse = etree.HTML(html)
text = parse.xpath('//div[@class="tab_content"]/div')
city_name = []
city_url = []
for i in text:
city_name.extend(i.xpath("./a/text()"))
city_url.extend(i.xpath("./a/@href"))
city_info = dict(zip(city_name,city_url))
return city_info
def process_trend(html):
"""
各城市小区涨跌top处理
@param html: 网页源码
@return: 各城市小区名,房价基本信息
"""
parse = etree.HTML(html)
area = parse.xpath('//div[@class="trend trend03"]/div/div//tbody/tr')
plot_name = []
info = []
for tr in area:
plot_name.extend(tr.xpath("./td/a/text()"))
plot_info = tr.xpath("./td/text()")
base_info = ','.join(plot_info)
info.append(base_info)
plot_intend = dict(zip(plot_name,info))
return plot_intend
以上代码就是通过Xpath方式获取我们想要的数据。
保存数据
提取信息后,我们一般会将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等。
if __name__ == '__main__':
index_html = process_index(INDEX)
city_dict = process_city(index_html)
# 记录到文件中
f = open('全国各城市房价小区涨跌top10_by_xpath.txt',"w", encoding="utf-8")
# 批量获取各城市房价涨跌幅top10
for city_name, city_url in city_dict.items():
# 城市首页处理
city_html = process_index(city_url)
# 房价涨跌top10
plot_intend = process_trend(city_html)
if bool(plot_intend):
for k,value in plot_intend.items():
f.write(f"城市{city_name}----小区名--{k}---房价基本信息{value}\n")
print(f"城市{city_name}----小区名{k}下载完毕....")
else:
f.write(f"城市{city_name}无涨幅小区top10\n")
f.write(f"-------------------城市{city_name}分隔线--------------------------\n")
f.close()
以上代码把获取的数据写入本地的.txt文件中。

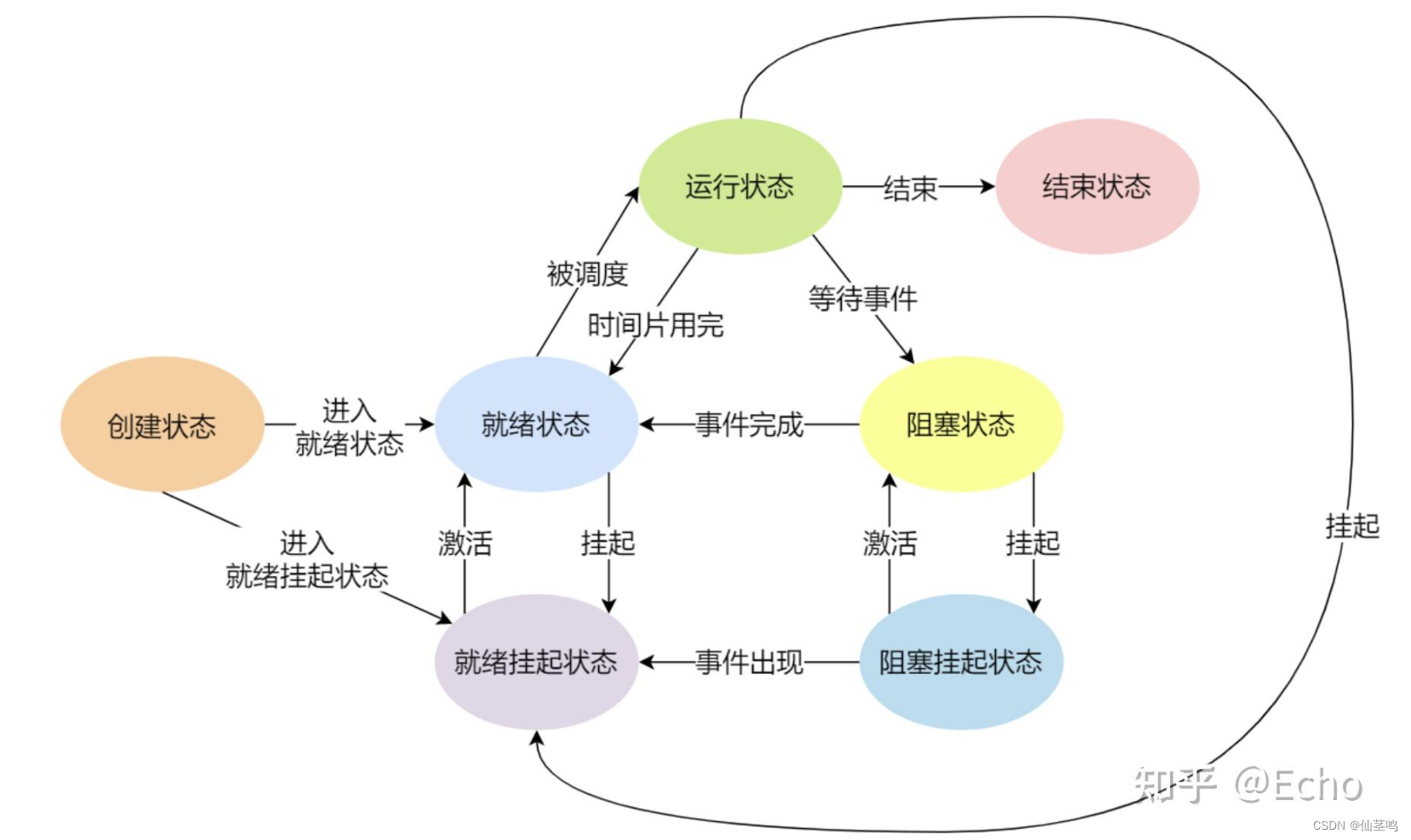
Python网络爬虫的原理包括以下几个步骤:
-
发送HTTP请求:通过Python的requests库向目标网站发送HTTP请求,获取网页内容。
-
解析网页内容:使用Python的HTML解析库(如BeautifulSoup、lxml等)对网页内容进行解析,获取需要爬取的信息。
-
数据存储:将爬取到的数据存储到本地文件或数据库中,以备后续分析或应用。
-
遍历链接:使用Python的正则表达式或其他库解析网页中的链接,进一步遍历目标网站的其他页面,从而实现自动化爬取。
需要注意的是,在进行Python网络爬虫时,需要遵守网站的爬虫规则,以免侵犯网站的合法权益。此外,为了避免被反爬虫机制识别,还需要使用一些反反爬虫技术,如使用代理IP、设置请求头、限制爬虫频率等。