JS设计模式-透过现象看本质
- 设计模式
- SOLID设计原则
- 创建型
- 构造器模式
- 工厂模式 - 简单工厂
- 工厂模式 - 抽象工厂(开发封闭原则)
- 构造器和简单、抽象工厂的区别
- 单例模式
- 原型模式
- 结构型
- 装饰器模式
- 适配器模式
- 代理模式
- 事件代理 - 事件冒泡
- 虚拟代理 - 通过Image加载图片
- 缓存代理 - 缓存计算结果
- 保护代理 - getter,setter保护核心数据
- 其他代理
- 行为型
- 策略模式
- 状态模式
- 策略和状态模式区别
- 观察者模式
- 观察者模式/发布订阅模式
- 迭代器模式
- 内部迭代器
- 外部迭代器
设计模式
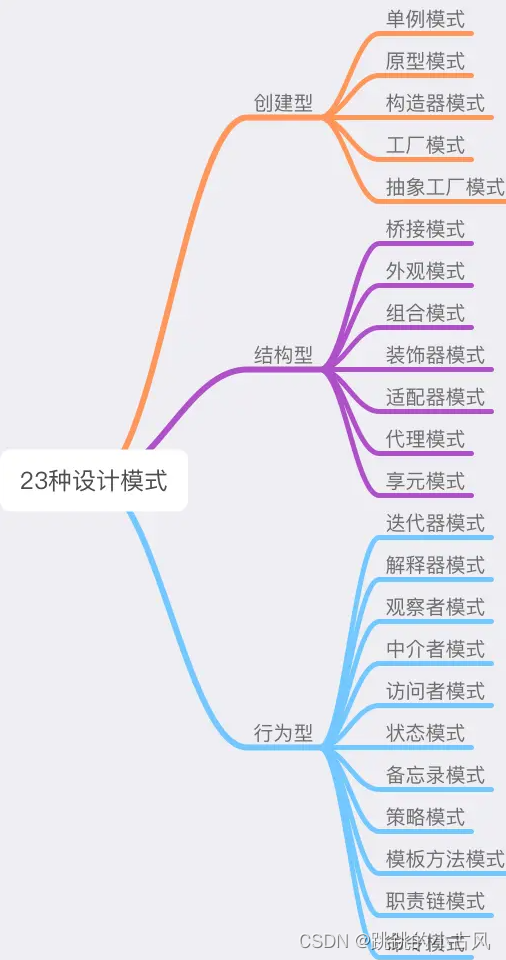
- 作用:在进行开发时,通过各种设计模式,快速在脑海中映射出它对应的解决方法
SOLID设计原则
- 单一功能原则
- 开放封闭原则
对拓展开放,对修改封闭;软件实体(类、模块、函数)可以扩展,但是不可修改;
- 里式替换原则
- 接口隔离原则
- 依赖反转原则
创建型
构造器模式
- 概念:将创建属性的过程单独封装。
- 应用场景:有大量同样属性的对象时候。
- 举例
//学校给小明老师安排了录入学生的任务
//录入第一个学生信息
const liLei = {
name: '李雷',
age: 25,
career:'music',
}
//录入第二个学生信息
const hanMeiMei = {
name: '韩梅梅',
age: 24,
career:'sports',
}
//后面发现还有500+学生,而每个学生的信息都是name,age,于是小明写出了自动创建学生的 User 函数
function User(name , age ,career) {
this.name = name
this.age = age
this.career= career
}
//进行一个简单的调用,让程序自动地去读取数据库里面一行行的员工信息,然后把拿到的姓名、年龄塞进User函数里,
const user = new User(name, age,career)
工厂模式 - 简单工厂
- 概念:将创建对象的过程单独封装。
- 应用场景:有构造函数的地方,在写了大量构造函数、调用了大量的 new的时候。
- 目的:实现无脑传参
//学校又给小明老师多加了要求,要写清楚指定学生的职责,语文课代表要会背古诗,音乐课代表要会唱歌等
//小明思考,那就再加个构造器
function SportsUser(name , age) {
this.name = name
this.age = age
this.career = 'sports'
this.work = ['跑步','跳远', '打羽毛球']
}
function musicUser(name, age) {
this.name = name
this.age = age
this.career = 'music'
this.work = ['高音', '低音', '中音']
}
//写到后面小明又想,那么多课代表,难道要写10多个,还要人为去判断该用哪个吗,于是乎,他又想到了工厂模式!
//学生信息函数
function User(name , age) {
this.name = name
this.age = age
this.career = career
this.work = work
}
function Factory(name, age, career) {
let work
switch(career) {
case 'sports':
work = ['跑步','跳远', '打羽毛球']
break
case 'music':
work = ['高音', '低音', '中音']
break
case 'xxx':
// 其它课代表的职责分配
...
return new User(name, age, career, work)
}
//进行一个简单的调用,让程序自动地去读取数据库里面一行行的员工信息,然后把拿到的姓名、年龄塞进User函数里,
const Factory= new Factory(name, age, career)
工厂模式 - 抽象工厂(开发封闭原则)
简单工厂的弊端,以上节代码为例
- 数据管理混乱,普通学生和职能学生都在一起,且每个可能又不一样的权限,安全委员拥有钥匙权限,而其他没有的,且后期会有其他,转学生,交换生等,新增一个就要去重写函数,会过于庞大及混乱,不易维护
- 不易迭代测试,所有逻辑都在一个函数体,改变一个需要全部回归测试
| 定义 | |
|---|---|
| 抽象工厂(抽象类,它不能被用于生成具体实例) | 用于声明最终目标产品的共性。在一个系统里,抽象工厂可以有多个(大家可以想象我 们的手机厂后来被一个更大的厂收购了,这个厂里除了手机抽象类,还有平板、游戏机抽象类等等),每一个抽象工厂对应的这一类的产品,被称为“产品族”。 |
| 具体工厂(用于生成产品族里的一个具体的产品) | 继承自抽象工厂、实现了抽象工厂里声明的那些方法,用于创建具体的产品的类。 |
| 抽象产品(抽象类,它不能被用于生成具体实例) | 上面我们看到,具体工厂里实现的接口,会依赖一些类,这些类对应到各种各样的具体的细粒度产品(比如操作系统、硬件等),这些具体产品类的共性各自抽离,便对应到了各自的抽象产品类。 |
| 具体产品(用于生成产品族里的一个具体的产品所依赖的更细粒度的产品) | 比如我们上文中具体的一种操作系统、或具体的一种硬件等。 |
- 实例:假如现在我要开一个店,类型和人员都不确定,我只知道店必须有这两部分组成,所以我先来一个抽象类来约定住这台店的基本组成。
// 抽象工厂类【抽象类】
class BaseFactory {
// 提供店铺类型的接口
createStore() {
throw new Error("抽象方法【createStore】不允许直接调用,需要重写");
}
// 提供服务人员的接口
createServicePeople() {
throw new Error("抽象方法【createServicePeople】不允许直接调用,需要重写");
}
}
// 商店类【抽象类】
class Store {
getAddress() {
throw new Error("抽象方法不允许直接调用,需要重写");
}
}
// 员工类【抽象类】
class Staff {
getStaff() {
throw new Error("抽象方法不允许直接调用,需要重写");
}
}
// 定义完抽象类后,开始创建具体工厂
//我的第一家产业 /火锅店,万达一楼77号,服务员李四
// 具体工厂实现类
class AchieveBaseFactory extends BaseFactory {
createStore() {
// 返回店铺类型
return new HotPotStore();
}
createServicePeople() {
// 返回服务人员信息
return new WaiterStaff();
}
}
// 创建服务员【实现类】
class WaiterStaff extends Staff {
getStaff() {
return "服务员, 李四";
}
}
// 创建火锅商店【实现类】
class HotPotStore extends Store {
getAddress() {
return "火锅店,万达一楼77号";
}
}
let myIndustry = new AchieveBaseFactory();
//我现在又有钱了,我再开一家 咖啡店,万象城二楼99号 厨师,张三
// 具体工厂实现类
class NewAchieveBaseFactory extends BaseFactory {
createStore() {
return new CafeStore();
}
createServicePeople() {
return new ChefStaff();
}
}
// 创建咖啡商店【实现类】
class CafeStore extends Store {
getAddress() {
return "咖啡店,万象城二楼99号";
}
}
// 创建厨师【实现类】
class ChefStaff extends Staff {
getStaff() {
return "厨师,张三";
}
}
let newMyIndustry = new NewAchieveBaseFactory();
构造器和简单、抽象工厂的区别
| 定义 | |
|---|---|
| 构造函数模式 | 必须通过new去创建对象,解决的是多个对象实例的问题 |
| 工厂模式 | 内部封装了创建对象的行为,主要用于无脑传参,解决的是多个类的问题-不符合开闭 |
| 抽象工厂 | 抽象类的作用是用于定义范围和规则,通过继承重写的方式去具体实现功能-符合开闭 |
单例模式
- 单例模式:不管创建多少次永远返回第一次创建的唯一实例
- 实现单例方式:闭包、
- 市场上哪些lib使用了单例:redux、vuex,保证全局只有一个store
保证一个类只有一个实例,实现方法一般是先判断实例存在与否,如果存在直接返回,如果不存在就创建了再返回,这就确保了一个类只有一个实例对象
const Singleton = function(name) {
this.name = name;
}
// 引入代理类
const ProxySingleton = (function(){
let instance;
return function(name){
if(!instance){
instance = new Singleton(name);
}
return instance
}
})();
// 使用 & 验证
const a = new ProxySingleton('instance1');
const b = new ProxySingleton('instance2');
console.log(a === b); // true
原型模式
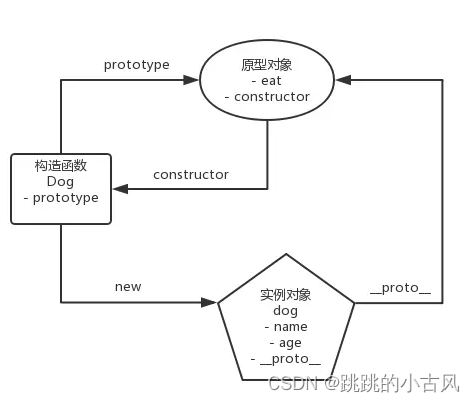
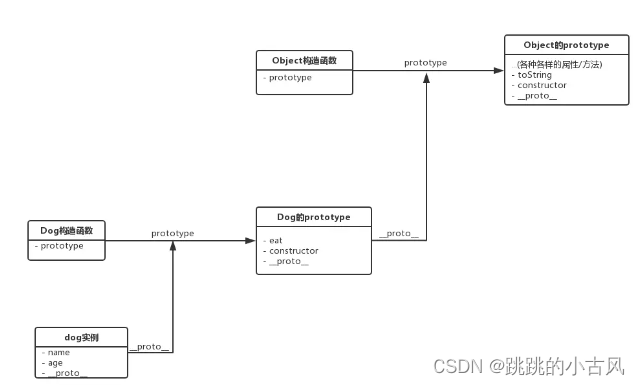
- 用原型实例指向创建对象的类,使用于创建新的对象的类共享原型对象的属性以及方法
在 JavaScript 中,每个构造函数都拥有一个prototype属性,它指向构造函数的原型对象
这个原型对象中有一个 constructor 属性指回构造函数;
每个实例都有一个__proto__属性,当我们使用构造函数去创建实例时,实例的__proto__属性就会指向构造函数的原型对象。
具体来说,当我们这样使用构造函数创建一个对象时:
// 创建一个Dog构造函数
function Dog(name, age) {
this.name = name
this.age = age
}
Dog.prototype.eat = function() {
console.log('肉骨头真好吃')
}
// 使用Dog构造函数创建dog实例
const dog = new Dog('旺财', 3)
// 输出"肉骨头真好吃"
dog.eat()
// 输出"[object Object]"
dog.toString()
明明没有在 dog 实例里手动定义 eat 方法和 toString 方法,它们还是被成功地调用了。
这是因为当我试图访问一个 JavaScript 实例的属性/方法时,它首先搜索这个实例本身;
当发现实例没有定义对应的属性/方法时,它会转而去搜索实例的原型对象;
如果原型对象中也搜索不到,它就去搜索原型对象的原型对象,这个搜索的轨迹,就叫做原型链。
结构型
装饰器模式
- 在不改变原对象的基础上,通过对其进行包装拓展,使得原有对象可以动态具有更多功能,从而满足用户的更复杂需求求
- 只添加不修改
- 单一职责原则:拆分职责,方便复用
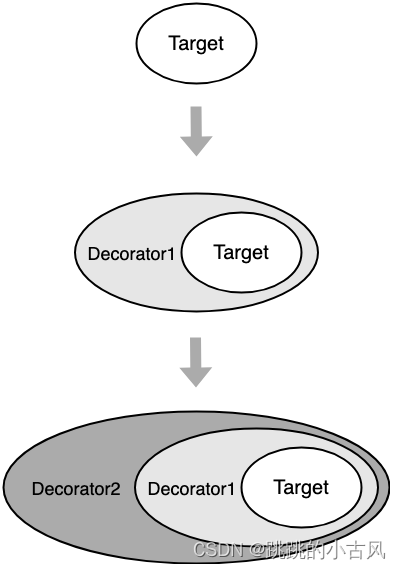
- 假设我们有一个计算函数,它的计算过程非常耗时,我们希望能够给它添加缓存功能,以提高性能。我们可以使用装饰器模式来实现这个功能
//定义装饰器函数
function cache(fn) {
const cache = new Map();
return function (num) {
if (cache.has(num)) {
console.log('Cache hit!');
return cache.get(num);
} else {
console.log('Cache miss!');
const result = fn(num);
cache.set(num, result);
return result;
}
};
}
//计算函数
function calculate(num) {
console.log('Calculating...');
let result = 0;
for (let i = 0; i < num; i++) {
result += i;
}
return result;
}
const cachedCalculate = cache(calculate);
console.log(cachedCalculate(10000000)); // Calculating... Cache miss! 49999995000000
console.log(cachedCalculate(10000000)); // Cache hit! 49999995000000
//当我们第一次调用cachedCalculate函数时,它会执行计算函数,并将结果缓存起来。当我们再次调用cachedCalculate函数时,它会直接从缓存中获取结果,而不需要重新计算
适配器模式
- 如不同手机插口的转接头
- 将一个类的接口转换成客户端所期望的接口,以便客户端可以使用这个类
- 适配器在内部调整,装饰器在外部约束
// 定义一个需要被适配的函数
function square(x) {
return x * x;
}
// 定义一个适配器函数,将输入参数转换为需要被适配函数的参数格式
function squareAdapter(obj) {
return square(obj.num);
}
// 定义一个对象,它的接口不符合需要被适配函数的接口
let obj = {
value: 5,
};
// 使用适配器函数将对象的接口转换为需要被适配函数的接口,并调用被适配函数
let result = squareAdapter({ num: obj.value });
console.log(result); // 25
//square() 是需要被适配的函数,它接受一个数字并返回它的平方。
//但是,我们有一个对象 obj ,它的接口不符合 square() 函数的接口(需要数字)。
//因此,我们需要编写一个适配器函数 squareAdapter() ,将obj对象的接口转换为 square() 函数的接口。
代理模式
为其他对象提供一种代理以控制对这个对象的访问。
事件代理 - 事件冒泡
虚拟代理 - 通过Image加载图片
为了延迟对象的创建或加载,而使用一个代理对象来代替真实对象,等到需要使用对象时才会真正地创建或加载。虚拟代理广泛应用在网络请求、大数据处理、图片加载等场景中.
//预加载图片
const image = (function () {
const imgNode = document.createElement('img');
document.body.appendChild(imgNode);
return {
setSrc: function (src) {
imgNode.src = src;
},
};
})();
// 代理容器
const proxyImage = (function () {
let img = new Image();
// 加载完之后将设置为添加的图片
img.onload = function () {
image.setSrc(this.src);
};
return {
setSrc: function (src) {
image.setSrc('loading.gif');
img.src = src;
},
};
})();
proxyImage.setSrc('https://image/path/file.jpg');
//如果使用 image.setSrc('https://image/path/file.jpg'),那么在图片被加载好之前,页面中有一段比较长的空白时间。于是我们引入 proxyImage,通过这个代理对象,在图片被真正加载好之前,页面中将出现 loading.gif 来占位,提示用户图片正在加载
缓存代理 - 缓存计算结果
为了避免重复计算或网络请求,而使用一个代理对象来缓存计算结果或网络请求结果,等到需要时直接调用缓存内容
let multi = function() {
let result = 1;
for (let i = 0; i < arguments.length; i++) {
result *= arguments[i];
}
return result;
}
let proxyMulti = (function(){
let cache = {};
return function() {
let args = Array.prototype.join.call(arguments, ',');
if(args in cache) {
return cache[args];
}
return cache[args] = multi.apply(this, arguments);
}
})();
proxyMulti(1,2,3,4); // 24
proxyMulti(1,2,3,4); // 24(从缓存中直接读取结果)
保护代理 - getter,setter保护核心数据
为了控制用户的访问权限,而使用一个代理对象来做出决策或验证,等到确定用户有足够权限时再执行对真实对象的访问
// 例子:代理接听电话,实现拦截黑名单
var backPhoneList = ['189XXXXX140']; // 黑名单列表
// 代理
var ProxyAcceptPhone = function(phone) {
// 预处理
console.log('电话正在接入...');
if (backPhoneList.includes(phone)) {
// 屏蔽
console.log('屏蔽黑名单电话');
} else {
// 转接
AcceptPhone.call(this, phone);
}
}
// 本体
var AcceptPhone = function(phone) {
console.log('接听电话:', phone);
};
// 外部调用代理
ProxyAcceptPhone('189XXXXX140');
ProxyAcceptPhone('189XXXXX141');
其他代理
- 防火墙代理: 控制网络资源的访问,保护主机不让“坏人”接近。
- 远程代理: 为一个对象在不同的地址空间提供局部代表, 在 Java 中,远程代理可以时另一个虚拟机中的对象。
- 智能引用代理: 取代了简单的指针,它在访问对象时执行一些附加操作,比如计算一个对象被引用的次数。
- 写时复制代理: 通常用于复制一个庞大对象的情况。写时复制代理延迟了复制的过程,当对象被真正修改时,才对它进行复制操作。写时- - 复制代理时虚拟代理的一种变体, DLL (操作系统中的动态链接库)时其典型运用场景。
行为型
策略模式
定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换。
- 原来写法
//实现一个计算员工奖金的程序,效绩为 S 则发基本工资的4倍,A 则3倍,以此类推。正常实现
let bonus = function (performance, salary) {
if(performance === "S") {
return salary*4;
}
if(performance === "A") {
return salary*3;
}
if(performance === "B") {
return salary*2;
}
}
- 优化写法
//该实现存在显著的缺点,如果随着效绩 的扩展,比如增加C,D,E, if 分支不断累加,使得代码越来越庞大
//使用策略
// js中函数也是对象,直接将 strategy 定义为函数
let strategy = {
"S": function ( salary ){
return salary*4;
},
"A": function ( salary ) {
return salary*3;
},
"B": function ( salary ) {
return salary*2;
}
}
let calculateBonus = function ( level, salary ) {
return strategy[ level ]( salary );
}
console.log(calculateBonus('A', 20000)) // 6000
状态模式
当控制一个对象状态的条件表达式过于复杂时的情况。把状态的判断逻辑转移到表示不同状态的一系列类中,可以把复杂的判断逻辑简化
- 原来写法
//有一个咖啡机,有不同的开关,同一个开关按钮,在不同的状态下,表现出来的行为是不一样的
- 美式咖啡态(american):只吐黑咖啡
- 普通拿铁态(latte):黑咖啡加点奶
- 香草拿铁态(vanillaLatte):黑咖啡加点奶再加香草糖浆
- 摩卡咖啡态(mocha):黑咖啡加点奶再加点巧克力
changeState(state) {
// 记录当前状态
this.state = state;
if(state === 'american') {
// 这里用 console 代指咖啡制作流程的业务逻辑
console.log('我只吐黑咖啡');
} else if(state === 'latte') {
console.log(`给黑咖啡加点奶`);
} else if(state === 'vanillaLatte') {
console.log('黑咖啡加点奶再加香草糖浆');
} else if(state === 'mocha') {
console.log('黑咖啡加点奶再加点巧克力');
}
}
- 优化写法
//该实现存在如下显著的缺点
1.状态之间的切换关系,是靠if、else语句,增加或者修改一个状态可能需要改变若干个操作,这使代码难以阅读和维护
class CoffeeMaker {
constructor() {
/**
这里略去咖啡机中与咖啡状态切换无关的一些初始化逻辑
**/
// 初始化状态,没有切换任何咖啡模式
this.state = 'init';
// 初始化牛奶的存储量
this.leftMilk = '500ml';
}
stateToProcessor = {
that: this,
american() {
// 尝试在行为函数里拿到咖啡机实例的信息并输出
console.log('咖啡机现在的牛奶存储量是:', this.that.leftMilk)
console.log('我只吐黑咖啡');
},
latte() {
this.american()
console.log('加点奶');
},
vanillaLatte() {
this.latte();
console.log('再加香草糖浆');
},
mocha() {
this.latte();
console.log('再加巧克力');
}
}
// 关注咖啡机状态切换函数
changeState(state) {
this.state = state;
if (!this.stateToProcessor[state]) {
return;
}
this.stateToProcessor[state]();
}
}
const mk = new CoffeeMaker();
mk.changeState('latte');
策略和状态模式区别
策略模式和状态模式的区别在于它们所关注的点不同,策略模式关注的是算法或行为的切换,状态模式关注的是对象的状态的切换。
观察者模式
观察者模式定义了一种一对多的依赖关系,让多个观察者对象同时监听某一个目标对象,当这个目标对象的状态发生变化时,会通知所有观察者对象,使它们能够自动更新
// 创建一个观察者(订阅者)对象
class Observer {
constructor() {
this.observers = [];
}
// 添加观察者
subscribe(callback) {
this.observers.push(callback);
}
// 移除观察者
unsubscribe(callback) {
this.observers = this.observers.filter(observer => observer !== callback);
}
// 通知观察者
notify(data) {
this.observers.forEach(observer => observer(data));
}
}
// 创建一个主题(被观察者)对象
class Subject {
constructor() {
this.observers = new Observer();
this.state = 0;
}
// 设置状态并通知观察者
setState(state) {
this.state = state;
this.observers.notify(this.state);
}
}
// 创建观察者实例
const observerA = data => console.log(`Observer A: ${data}`);
const observerB = data => console.log(`Observer B: ${data}`);
const observerC = data => console.log(`Observer C: ${data}`);
// 创建主题实例
const subject = new Subject();
// 订阅观察者
subject.observers.subscribe(observerA);
subject.observers.subscribe(observerB);
// 设置主题状态,触发通知
subject.setState(1);
// 取消订阅 observerA
subject.observers.unsubscribe(observerA);
// 再次设置主题状态,触发通知
subject.setState(2);
// 添加一个新观察者
subject.observers.subscribe(observerC);
// 再次设置主题状态,触发通知
subject.setState(3);
应用场景:
- DOM事件:可以将事件处理程序作为观察者,将事件对象作为主题,当事件发生时,通知所有的事件处理程序。
- jQuery的自定义事件:可以使用观察者模式实现自定义事件,当自定义事件发生时,通知所有的注册事件处理程序。
- 状态管理库(例如Redux、Vuex):状态管理库中的store可以作为主题,组件可以作为观察者,当状态发生变化时,通知所有的观察者。
观察者模式/发布订阅模式
- 观察者模式(Observer Pattern)定义了一种一对多的关系,让多个订阅者对象同时监听某一个发布者,或者叫主题对象,这个主题对象的状态发生变化时就会通知所有订阅自己的订阅者对象,使得它们能够自动更新自己。
- 发布订阅模式别名,非常形象地诠释了观察者模式里两个核心的角色要素——发布者和订阅者。
发布-订阅模式有一个调度中心
迭代器模式
- 提供一种方法顺序访问一个聚合对象中的各个元素,而又不需要暴露该对象的内部表示
- map foreach every some
内部迭代器
- 优点:内部迭代器不关心具体的实现,调用时非常方便
- 缺点:因为内部迭代器的迭代规则已经被提前规定好了,如果我们想同时迭代2个数组,下面的each函数是无法实现的
function each(arr, callback) {
// 对arr循环遍历,每一次遍历调用callback
for (let i = 0, l = arr.length; i < l; i++) {
callback.call(arr[i], i, arr[i]);
}
}
- 判断2个数组里元素的值是否完全相等
function compare(arr1, arr2) {
// 如果两个数组长度不相同,不可能相等
if (arr1.length !== arr2.length) {
console.log("arr1和arr2不相等");
return;
}
each(arr1, function (i, n) {
// i为arr1每一项索引,n为arr1每项的值
if (n !== arr2[i]) {
console.log("arr1和arr2不相等");
return;
}
console.log("arr1和arr2相等");
});
}
外部迭代器
必须显式地请求迭代下一个元素,它增加了一些调用的复杂度,但相对也增强了迭代器的灵活性,我们可以手工控制迭代的过程或者顺序
function Iterator(obj) {
var current = 0; // 记录当前的索引
// 下一个位置的索引
var next = function () {
current += 1;
};
// 是否已经迭代完成
var isDone = function () {
return current >= obj.length;
};
// 获取当前位置的数据
var getCurrentItem = function () {
return obj[current];
};
return {
next,
isDone,
getCurrentItem,
};
}
- 判断2个数组里元素的值是否完全相等
function compare(iterator1, iterator2) {
while (!iterator1.isDone() && !iterator2.isDone()) {
if (iterator1.getCurrentItem() !== iterator2.getCurrentItem()) {
console.log("arr1和arr2不相等");
return;
}
iterator1.next();
iterator2.next();
}
console.log("arr1和arr2相等");
}
var iterator1 = Iterator([1, 2, 3]);
var iterator2 = Iterator([2, 3, 4]);
compare(iterator1, iterator2); // arr1和arr2不相等