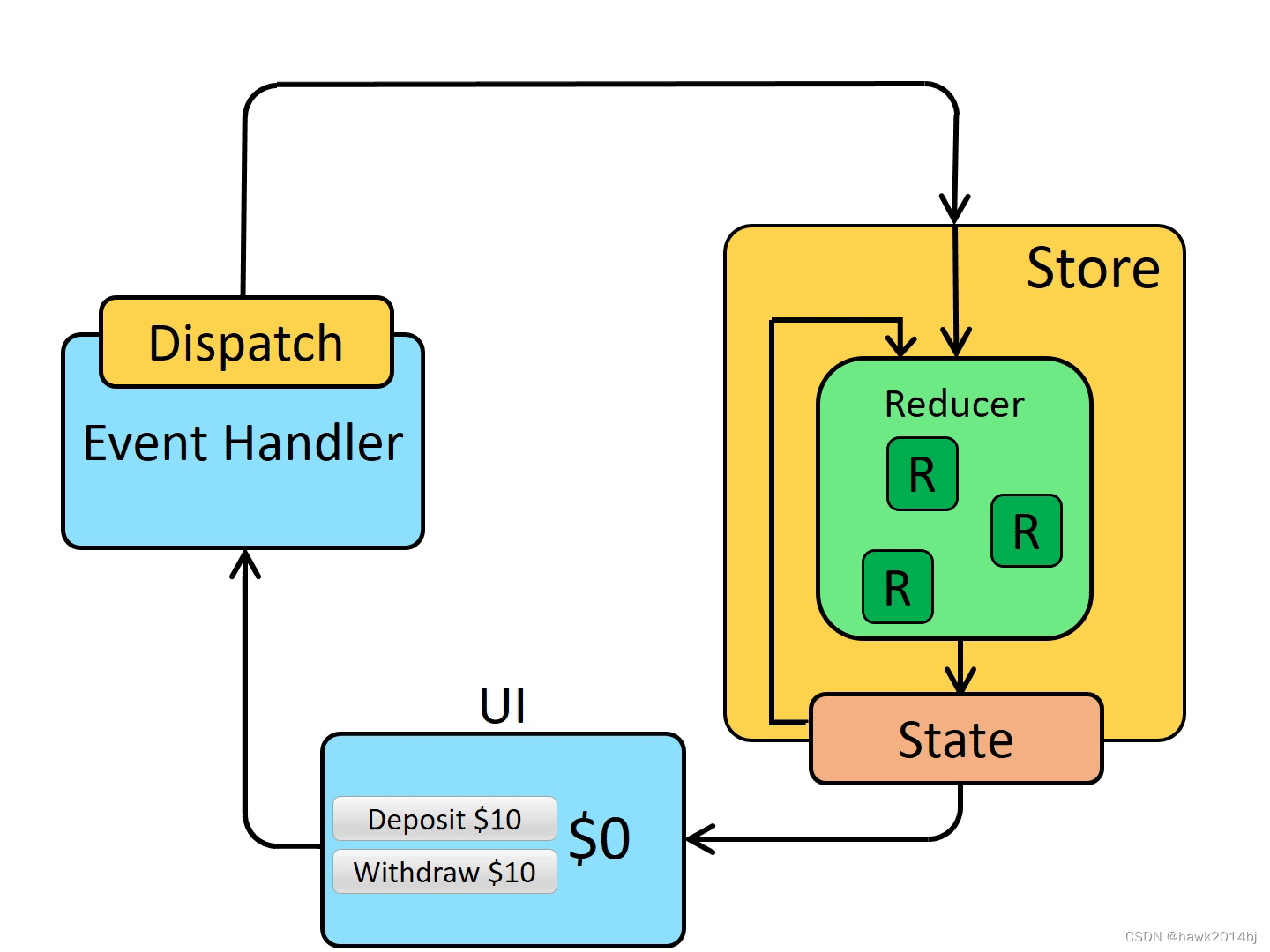
1、语音识别的过程
语音识别涉及三个过程:首先,需要设备的麦克风接收这段语音;其次,语音识别服务器会根据一系列语法 (基本上,语法是你希望在具体的应用中能够识别出来的词汇) 来检查这段语音;最后,当一个单词或者短语被成功识别后,结果会以文本字符串的形式返回 (结果可以有多个),以及更多的行为可以设置被触发。
2、示例
示例代码:
您如果想直接尝试的话可以先复制下面代码运气起来试试效果。
操作方法:将代码运行在浏览器,点击屏幕,允许麦克风权限,然后出说其中一种颜色。
结果1:识别成功,但是没听清楚您说的什么,页面不会有任何变化。
结果2:识别成功,页面背景切换为您说的那种颜色。
结果3:识别失败,失败原因将在页面底部展示。
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8" /> <meta http-equiv="X-UA-Compatible" content="IE=edge" /> <meta name="viewport" content="width=device-width" /> <title></title> <style> body, html { margin: 0; } html { height: 100%; } body { height: inherit; overflow: hidden; max-width: 800px; margin: 0 auto; } h1, p { font-family: sans-serif; text-align: center; padding: 20px; } div { height: 100px; overflow: auto; position: absolute; bottom: 0px; right: 0; left: 0; background-color: rgba(255, 255, 255, 0.2); } ul { margin: 0; } .hints span { text-shadow: 0px 0px 6px rgba(255, 255, 255, 0.7); } </style> </head> <body> <h1>语音识别转换器</h1> <p class="hints"></p> <div> <p class="output"><em>识别进度展示处</em></p> </div> </body> <script> var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition var SpeechGrammarList = SpeechGrammarList || window.webkitSpeechGrammarList var SpeechRecognitionEvent = SpeechRecognitionEvent || webkitSpeechRecognitionEvent var colors = [ 'aqua', 'azure', 'beige', 'bisque', 'black', 'blue', 'brown', 'chocolate', 'coral', 'crimson', 'cyan', 'fuchsia', 'ghostwhite', 'gold', 'goldenrod', 'gray', 'green', 'indigo', 'ivory', 'khaki', 'lavender', 'lime', 'linen', 'magenta', 'maroon', 'moccasin', 'navy', 'olive', 'orange', 'orchid', 'peru', 'pink', 'plum', 'purple', 'red', 'salmon', 'sienna', 'silver', 'snow', 'tan', 'teal', 'thistle', 'tomato', 'turquoise', 'violet', 'white', 'yellow', ] var recognition = new SpeechRecognition() if (SpeechGrammarList) { var speechRecognitionList = new SpeechGrammarList() var grammar = '#JSGF V1.0; grammar colors; public <color> = ' + colors.join(' | ') + ' ;' speechRecognitionList.addFromString(grammar, 1) recognition.grammars = speechRecognitionList } recognition.continuous = false recognition.lang = 'en-US' recognition.interimResults = false recognition.maxAlternatives = 1 var bg = document.querySelector('html') var hints = document.querySelector('.hints') var diagnostic = document.querySelector('.output') var colorHTML = '' colors.forEach(function (v, i, a) { colorHTML += '<span style="background-color:' + v + ';"> ' + v + ' </span>' }) hints.innerHTML = '点击页面,然后说出一种颜色来更改页面背景色' + '</br>' + colorHTML + '.' let flag = false document.body.onclick = function () { if (flag) return flag = true recognition.start() console.log('正识别中...') diagnostic.textContent = '正识别中...' } recognition.onresult = function (event) { var color = event.results[0][0].transcript bg.style.backgroundColor = color flag = false // console.log('Confidence: ' + event.results[0][0].confidence) console.log('识别成功,结果是:', color) diagnostic.textContent = '识别成功,结果是: ' + color + '.' } recognition.onspeechend = function () { recognition.stop() flag = false console.log('识别结束') } recognition.onnomatch = function (event) { flag = false console.log('识别成功,但是没有认出您说的颜色') diagnostic.textContent = '识别成功,但是没有认出您说的颜色' } recognition.onerror = function (event) { flag = false let msg = event.error == 'not-allowed' ? '没有麦克风权限' : event.error console.log('识别错误,原因是:', msg) diagnostic.textContent = '识别错误,原因是:' + msg } </script> </html>您可能出现的问题:
一、一直都提示没有麦克风权限
可能原因:
1、您没有开启当前页面的麦克风功能。
2、您的电脑或者手机没有麦克风功能。
解决方法:
1、您可以重新打开该页面,然后开启当前页面的麦克风权限。
2、佩戴耳机,利用耳机的麦克风功能
二、页面上只有文字显示,页面效果与示例图不一样
可能原因:
1、您使用的浏览器不支持语音识别。
2、代码有误。
解决方法:
1、pc端使用Chrome、Edge、Safari浏览器。手机端使用Safari、Samsung等浏览器或者在微信内部利用WebView打开链接进行访问。
2、检查代码。
三、建议使用Edge浏览器,成功率90%以上


3、代码解析
判断浏览器支不支持
var SpeechRecognition = SpeechRecognition || webkitSpeechRecognition; var SpeechGrammarList = SpeechGrammarList || webkitSpeechGrammarList; var SpeechRecognitionEvent = SpeechRecognitionEvent || webkitSpeechRecognitionEvent;将代码定义希望应用能够识别的语法。语法放在下面定义的变量
grammar中:var colors = [ 'aqua' , 'azure' , 'beige', 'bisque', 'black', 'blue', 'brown', 'chocolate', 'coral' ... ]; var grammar = '#JSGF V1.0; grammar colors; public <color> = ' + colors.join(' | ') + ' ;'使用
SpeechRecognition() 构造函数,定义一个 speech recognition 实例,控制对于这个应用的识别。还需要使用 SpeechGrammarList() 构造函数,创立一个 speech grammer list 对象var recognition = new SpeechRecognition(); var speechRecognitionList = new SpeechGrammarList();使用 SpeechGrammarList.addFromString() 把语法添加到列表 (list),这个方法接收两个参数,第一个是我们想要添加的包含语法内容的字符串,第二个是对添加的这条语法的权重 (权重值范围是 0~1),权重其实是相对于其他语法,这一条语法的重要程度。添加到列表的语法就是可用的,并且是一个
SpeechGrammar 实例。speechRecognitionList.addFromString(grammar, 1);然后通过设置
SpeechRecognition.grammars 属性值,把我们的 SpeechGrammarList添加到 speech recognition 实例。在继续往前走之前,我们还需要设置 recognition 实例其他的一些属性:
- SpeechRecognition.lang :设置识别的是什么语言。
- SpeechRecognition.interimResults :定义 speech recognition 系统要不要返回临时结果 (interim results),还是只返回最终结果。
- SpeechRecognition.maxAlternatives :定义每次结果返回的可能匹配值的数量。这有时有用,比如要的结果不明确,你想要用一个列表展示所有可能值,让用户自己从中选择一个正确的。
recognition.grammars = speechRecognitionList; //recognition.continuous = false; recognition.lang = "en-US"; recognition.interimResults = false; recognition.maxAlternatives = 1;开始语音识别
document.body.onclick = function () { if (flag) return flag = true recognition.start() console.log('正识别中...') diagnostic.textContent = '正识别中...' }接收、处理结果
一旦语音识别开始,有许多 event handlers 可以用于做结果返回的后续操作,除了识别的结果外还有些零碎的相关信息可供操作,这在收到一个成功的结果时候触发。
recognition.onresult = function (event) { var color = event.results[0][0].transcript bg.style.backgroundColor = color flag = false // console.log('Confidence: ' + event.results[0][0].confidence) console.log('识别成功,结果是:', color) diagnostic.textContent = '识别成功,结果是: ' + color + '.' }停止语音识别服务
一旦一个单词被识别就不能再说咯 (必须再点击屏幕再次开启语音识别)
recognition.onspeechend = function () { recognition.stop() flag = false console.log('识别结束') }处理未能识别的语音
你说的内容不在定义的语法中所以识别不了
recognition.onnomatch = function (event) { flag = false console.log('识别成功,但是没有认出您说的颜色') diagnostic.textContent = '识别成功,但是没有认出您说的颜色' }处理 error
识别出现问题
recognition.onerror = function (event) { flag = false let msg = event.error == 'not-allowed' ? '没有麦克风权限' : event.error console.log('识别错误,原因是:', msg) diagnostic.textContent = '识别错误,原因是:' + msg }