CUDA入门系列课程,从最基础着手,突出的就是一个字“细”!!
github项目包含代码、博客、课件pdf下载地址:https://github.com/sangyc10/CUDA-code!
在这里插入图片描述
CUDA编程基础入门系列
https://github.com/sangyc10/CUDA-code
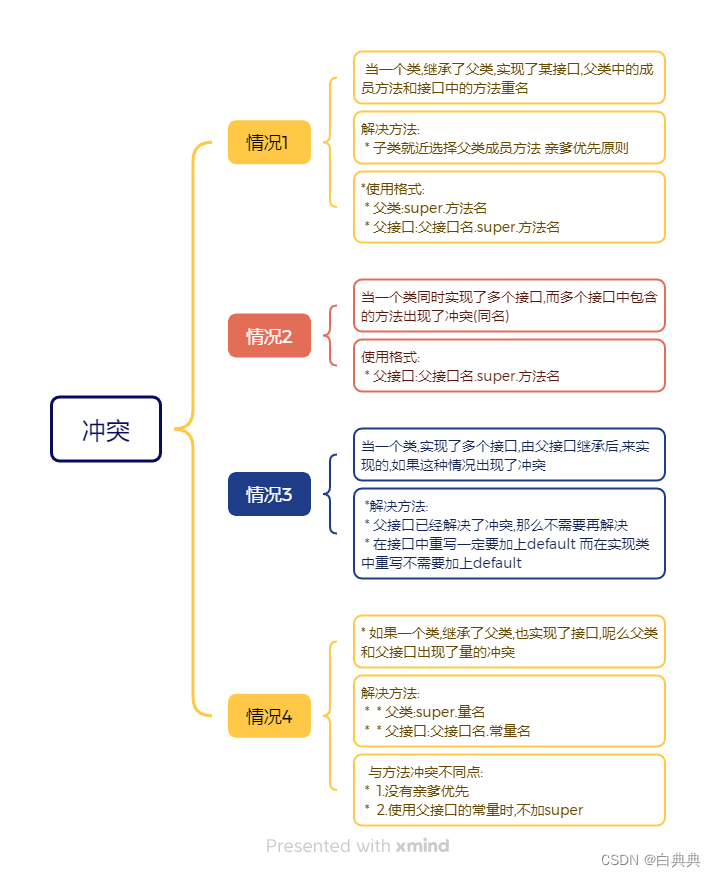
CUDA入门
- CUDA 概论
- CUDA安装
- nvidia-smi 工具
- CUDA编程
- CUDA 线程模型
- 线程索引计算
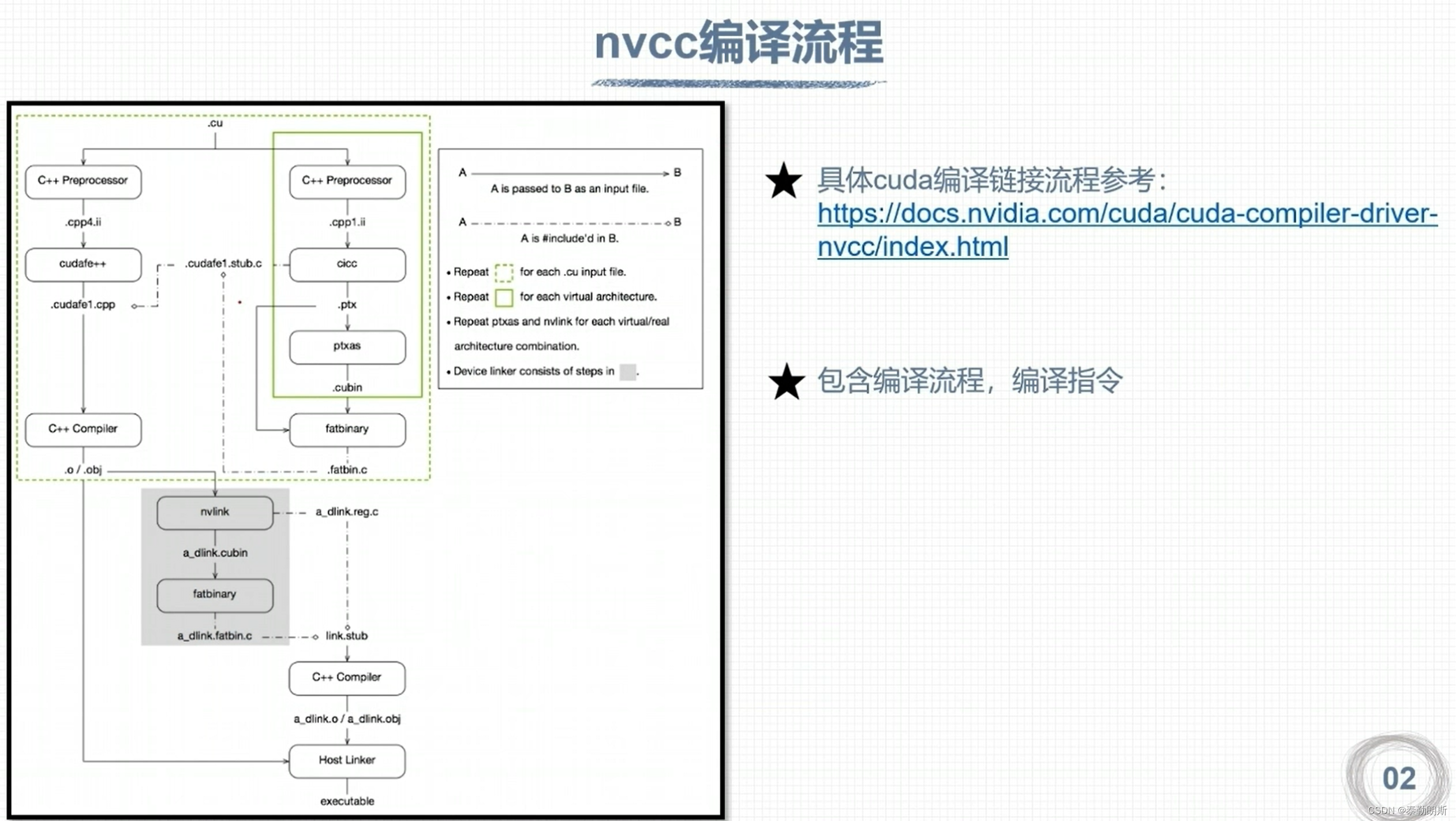
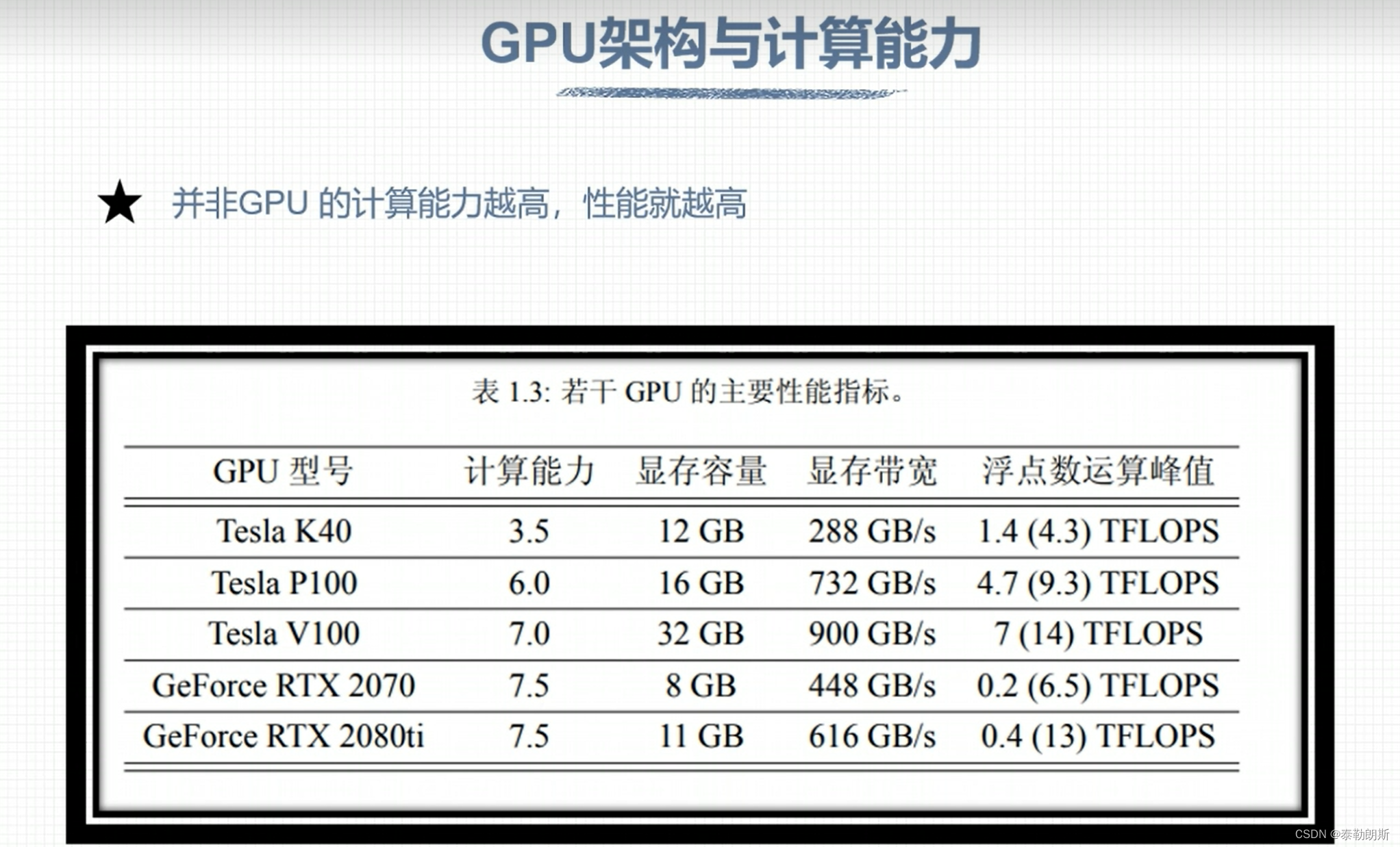
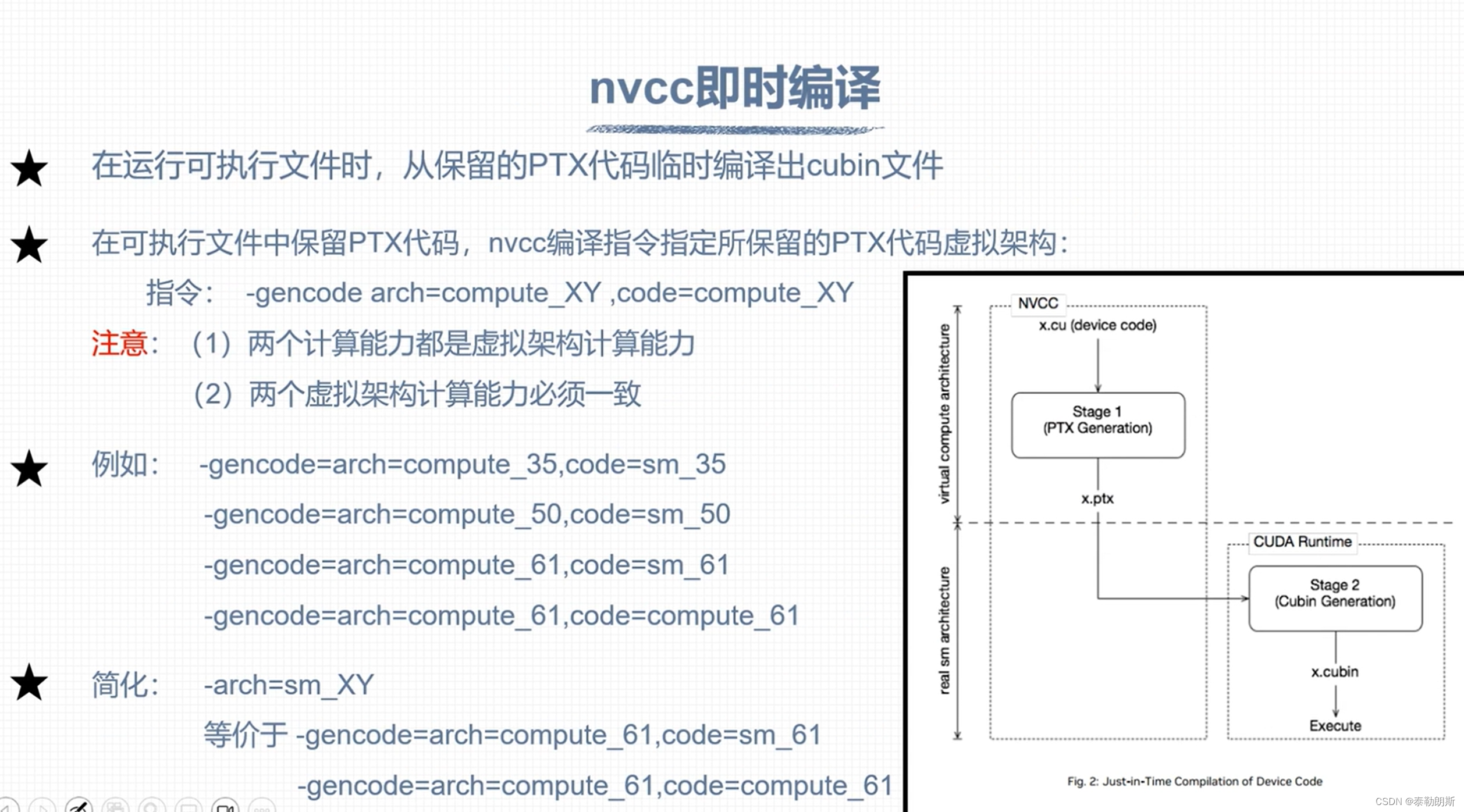
- nvcc 编译流程和GPU计算能力
- CUDA 程序兼容性问题
- CUDA 矩阵加法运算
- CUDA 错误检查
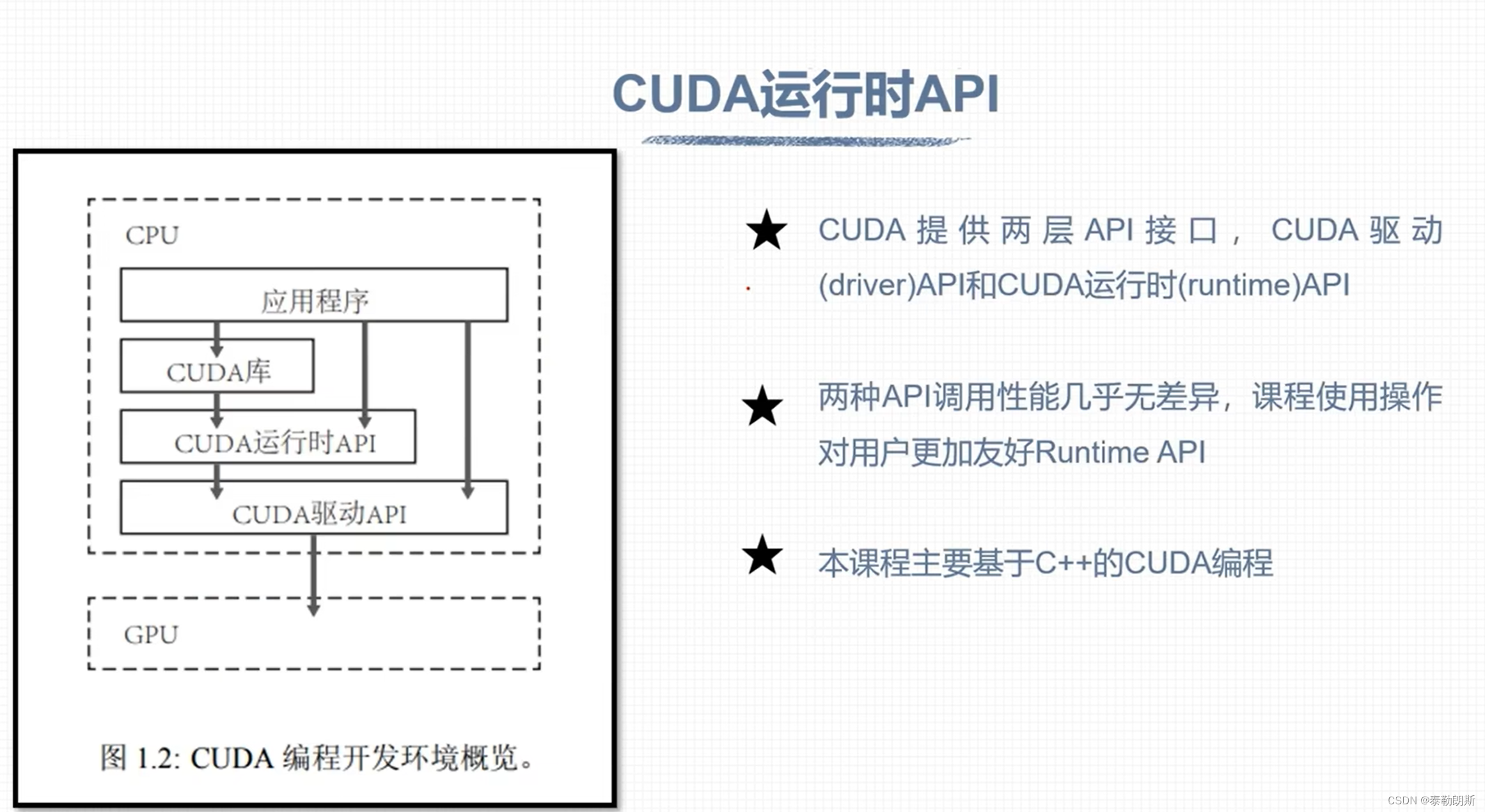
CUDA 概论
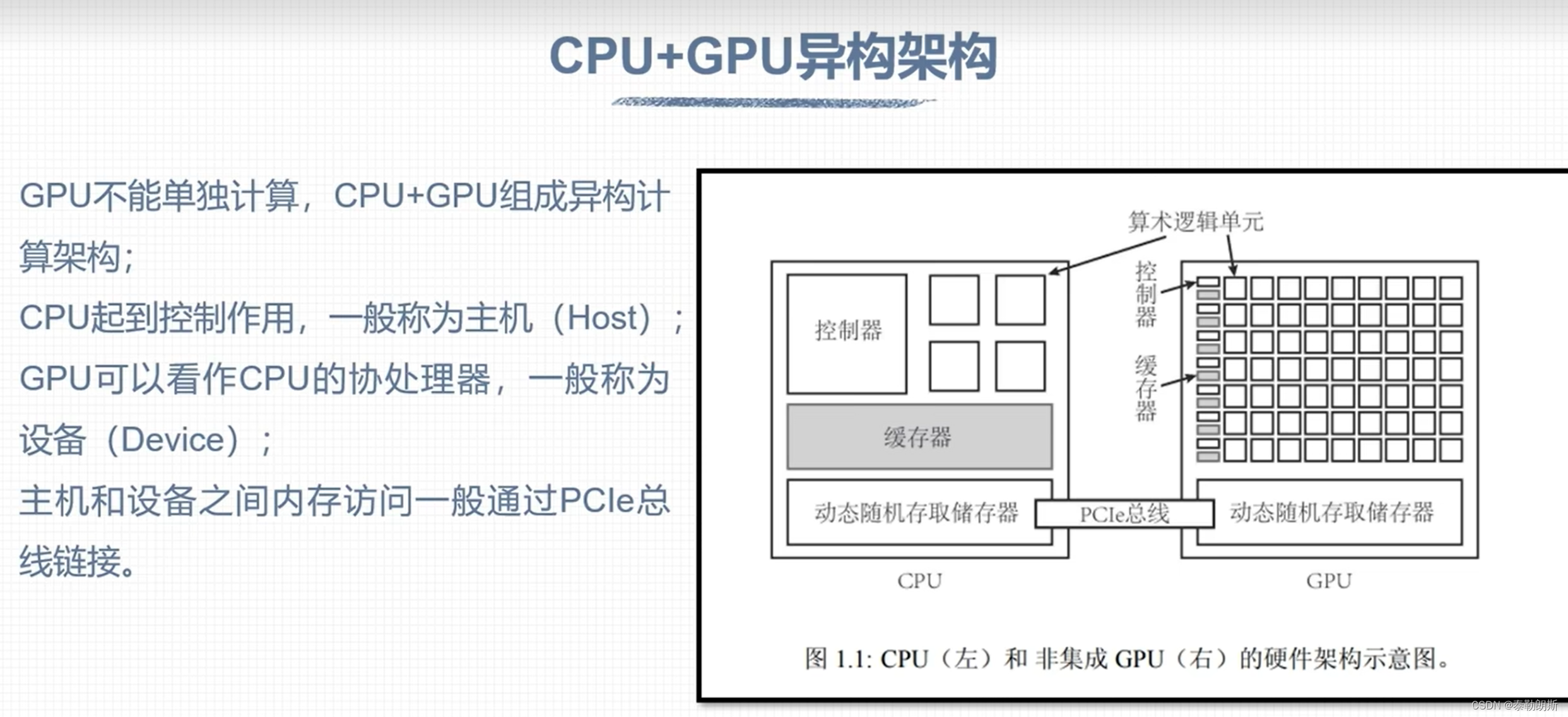

CUDA安装


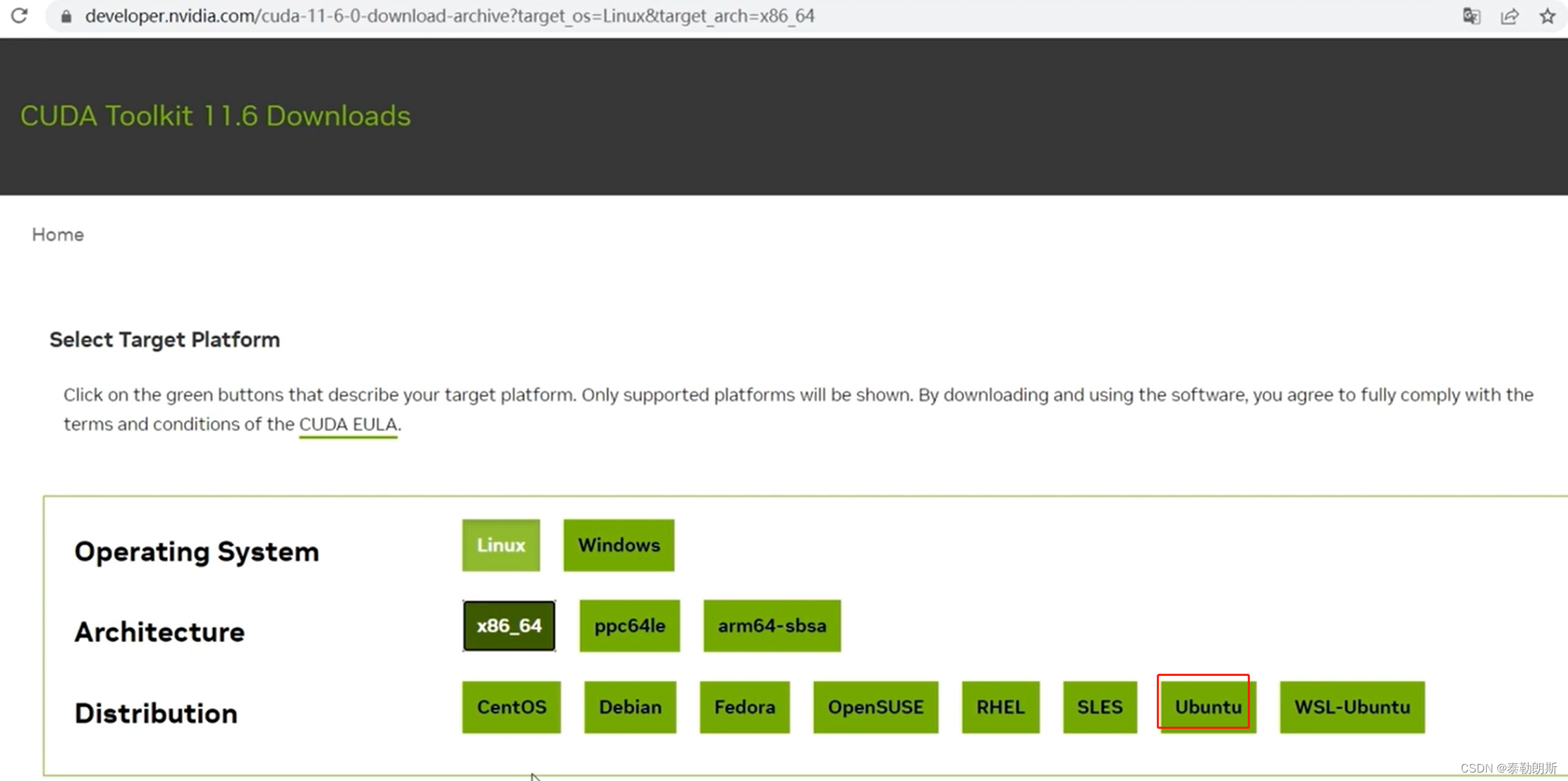

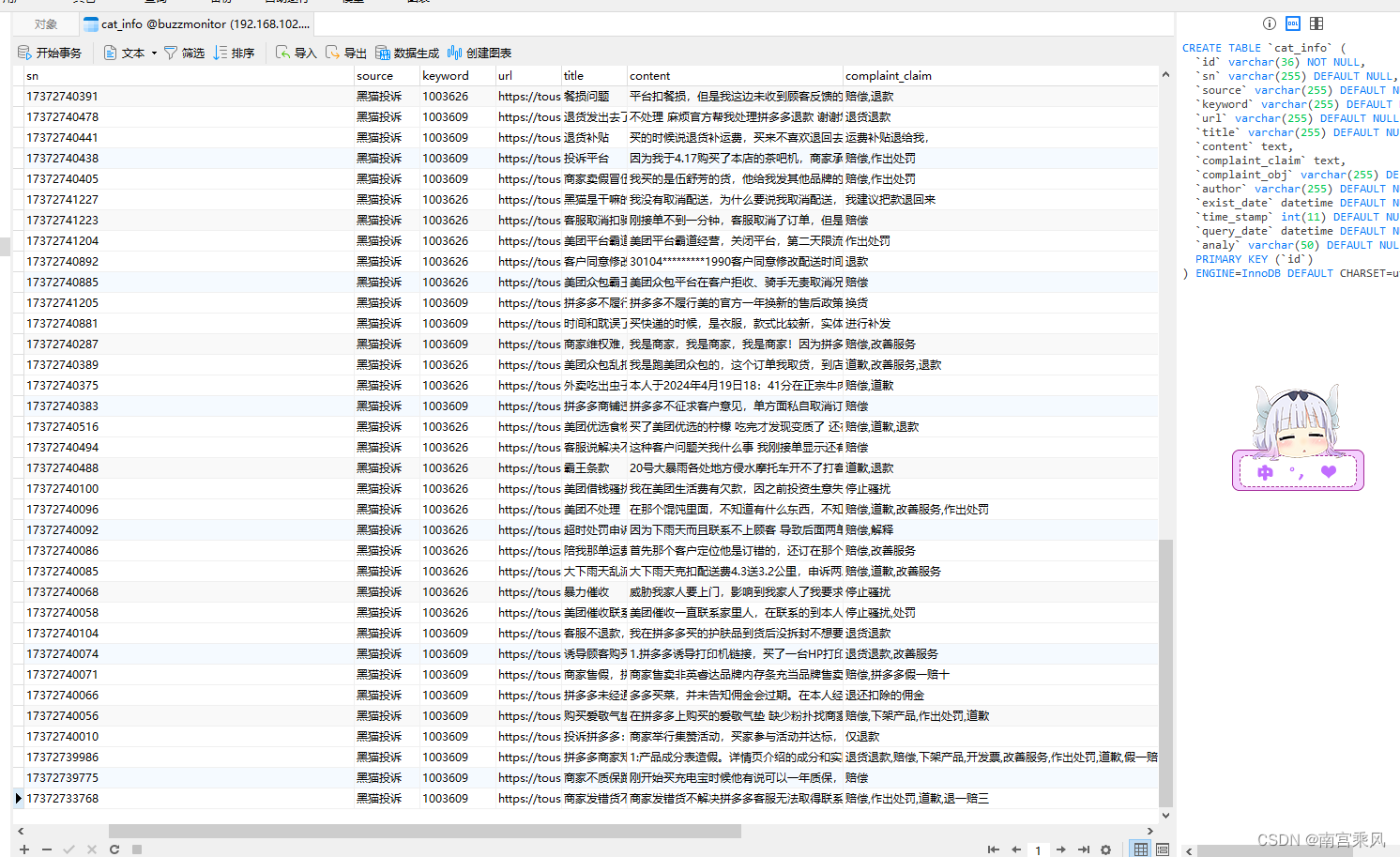
把上述命令依次执行就可以安装了,安装好执行:nvcc -V, nvidia-smi
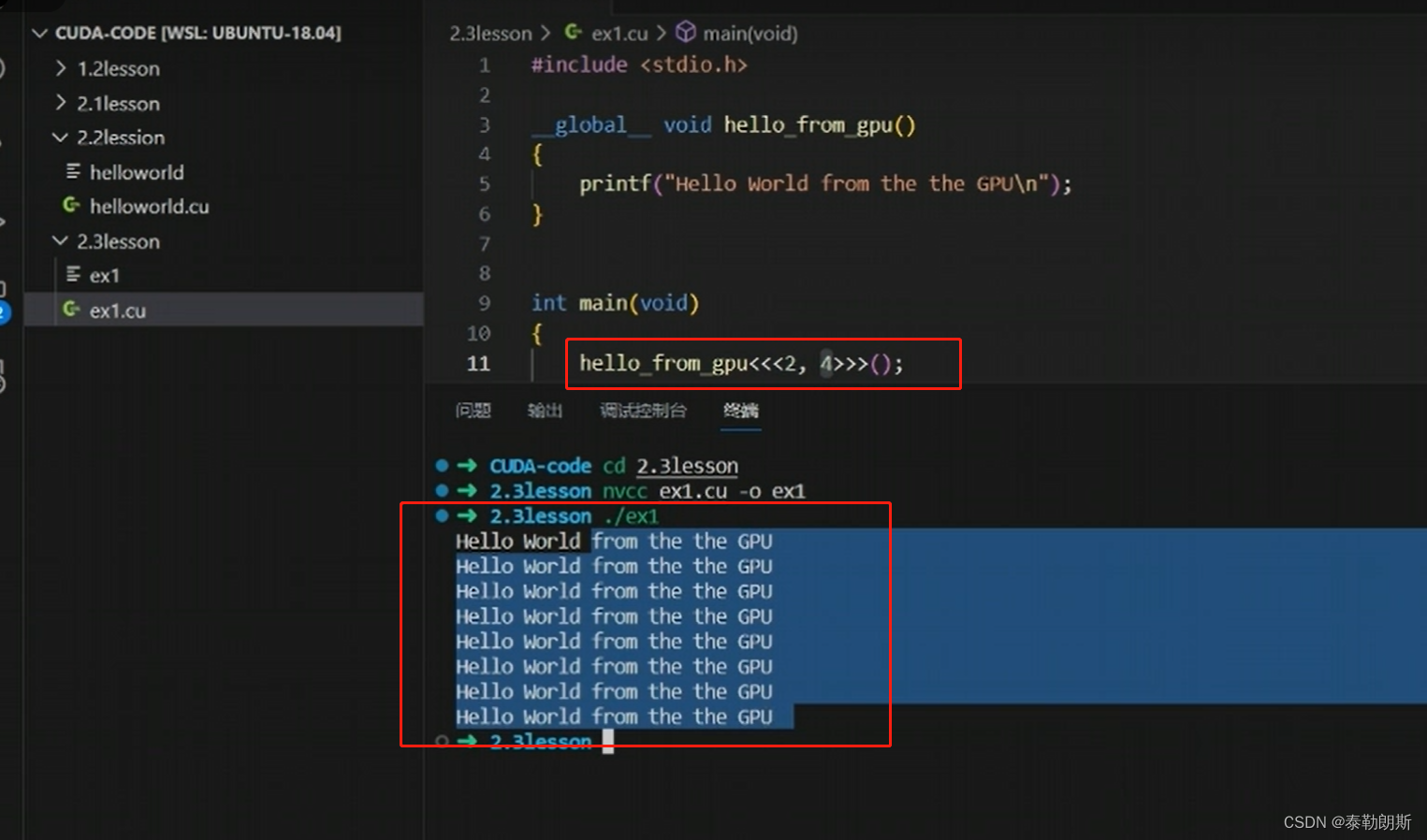
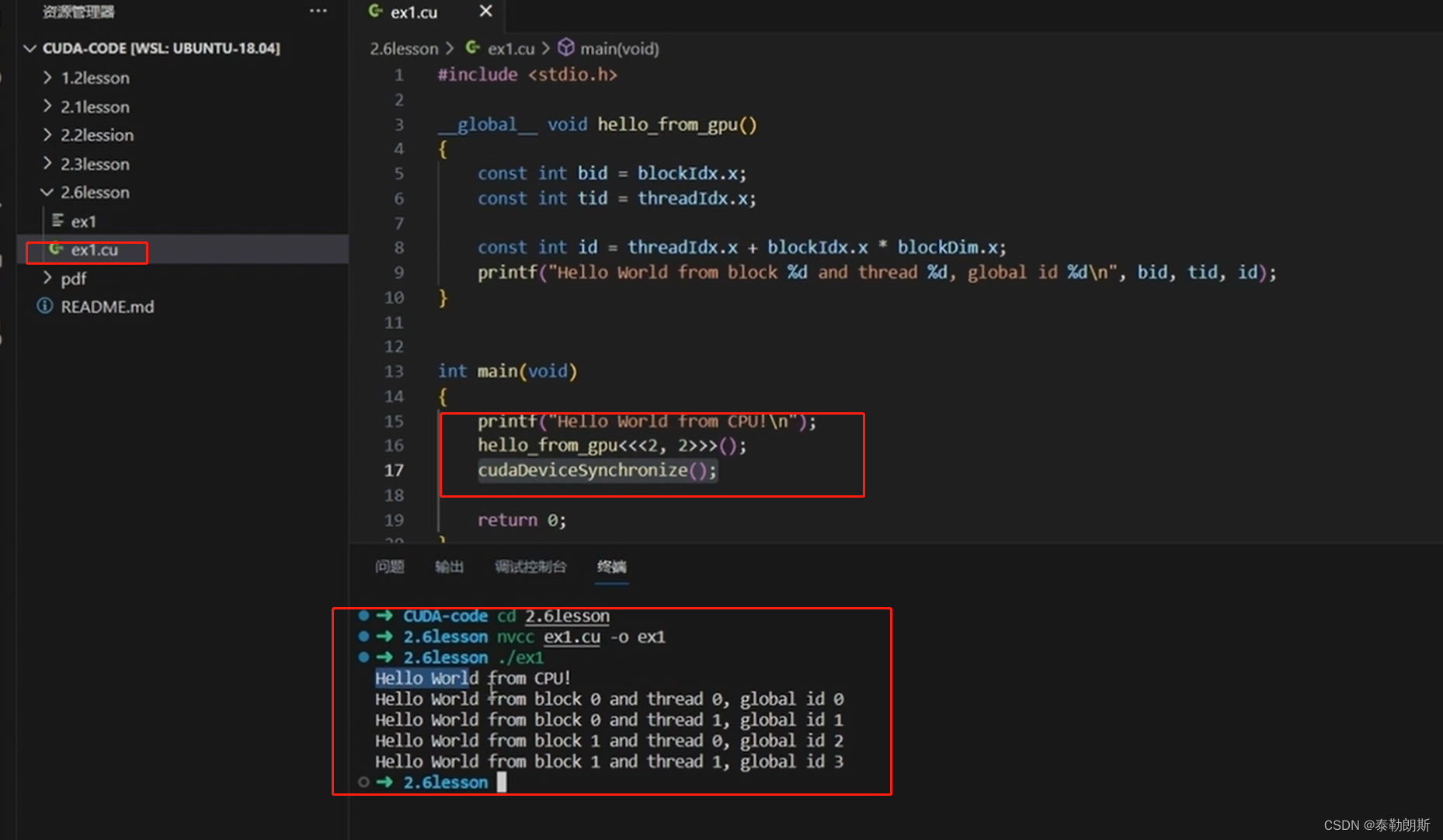
测试代码
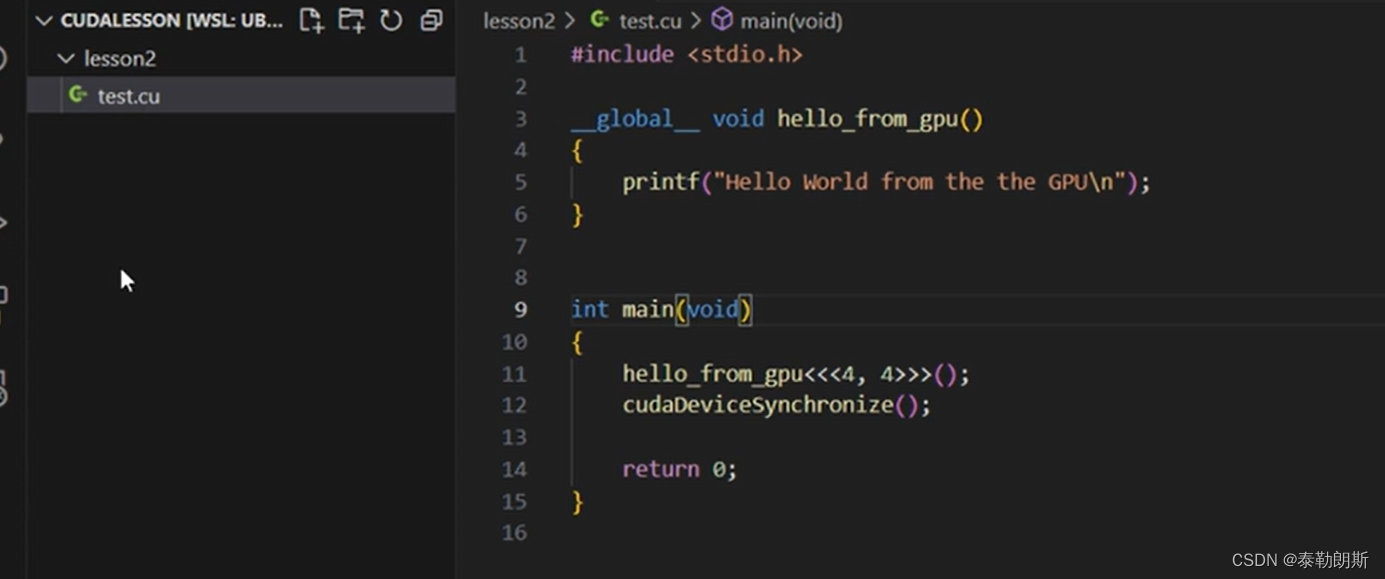
编译执行,
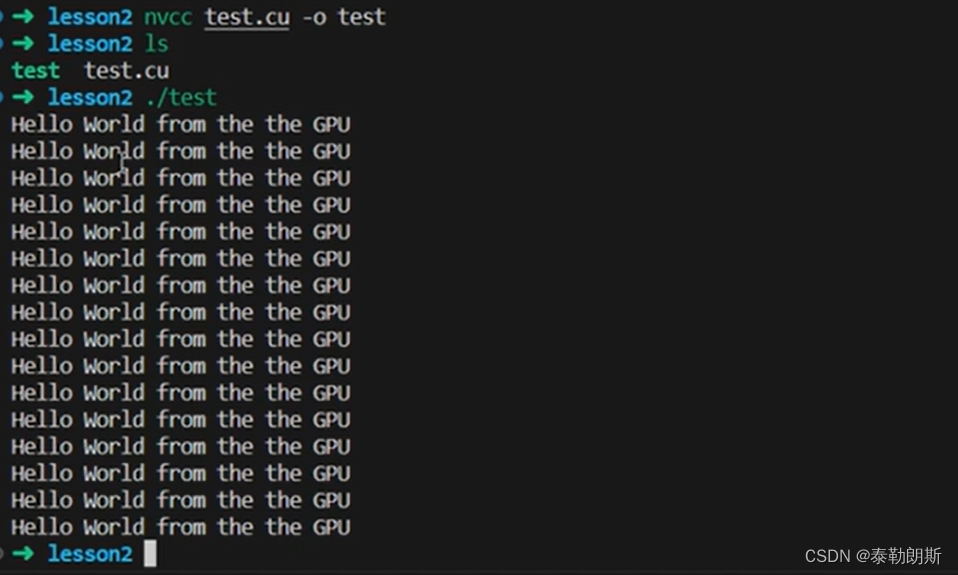
使用了4*4=16个线程,所以会打印16次
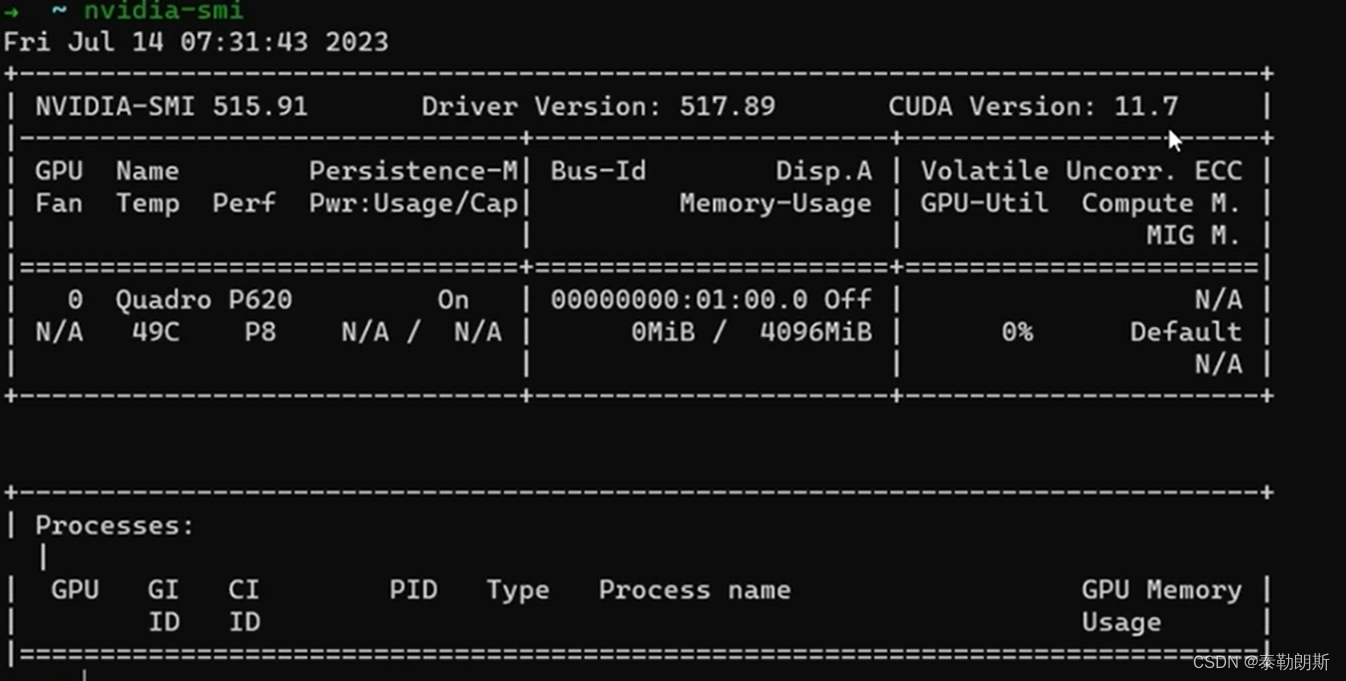
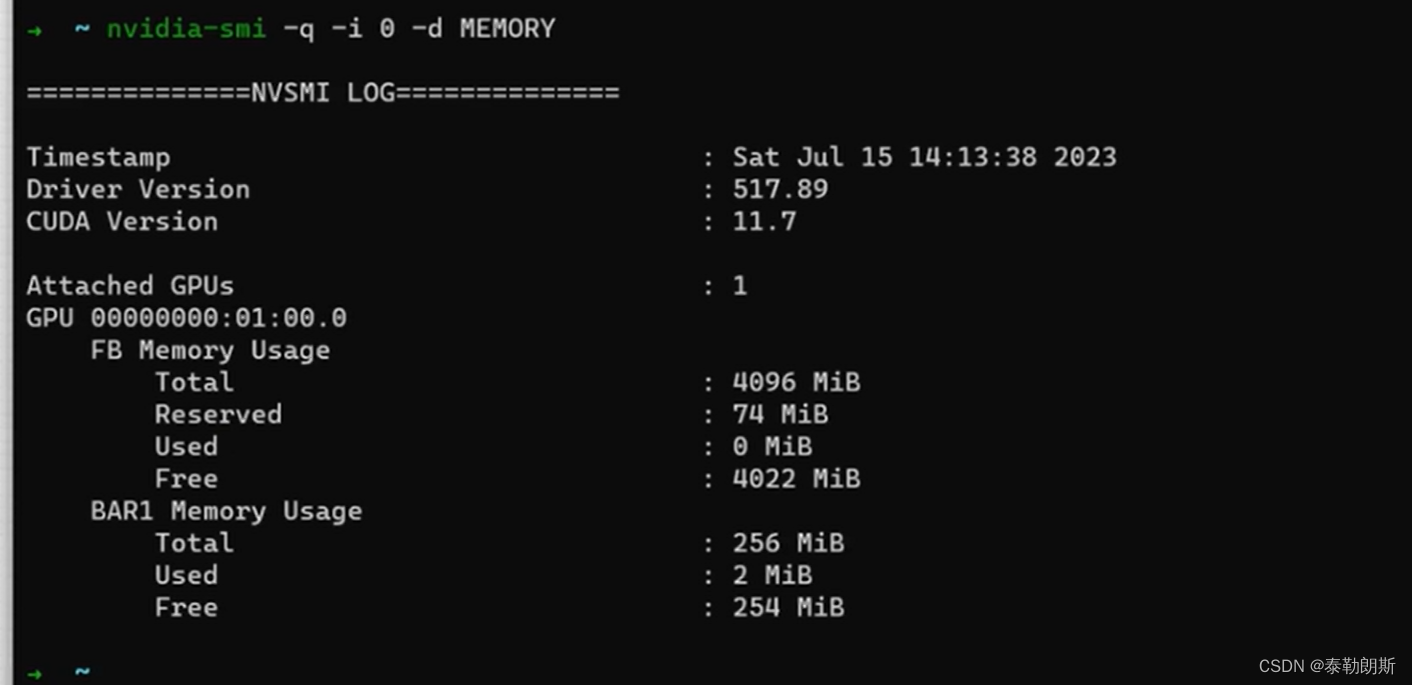
nvidia-smi 工具



CUDA编程


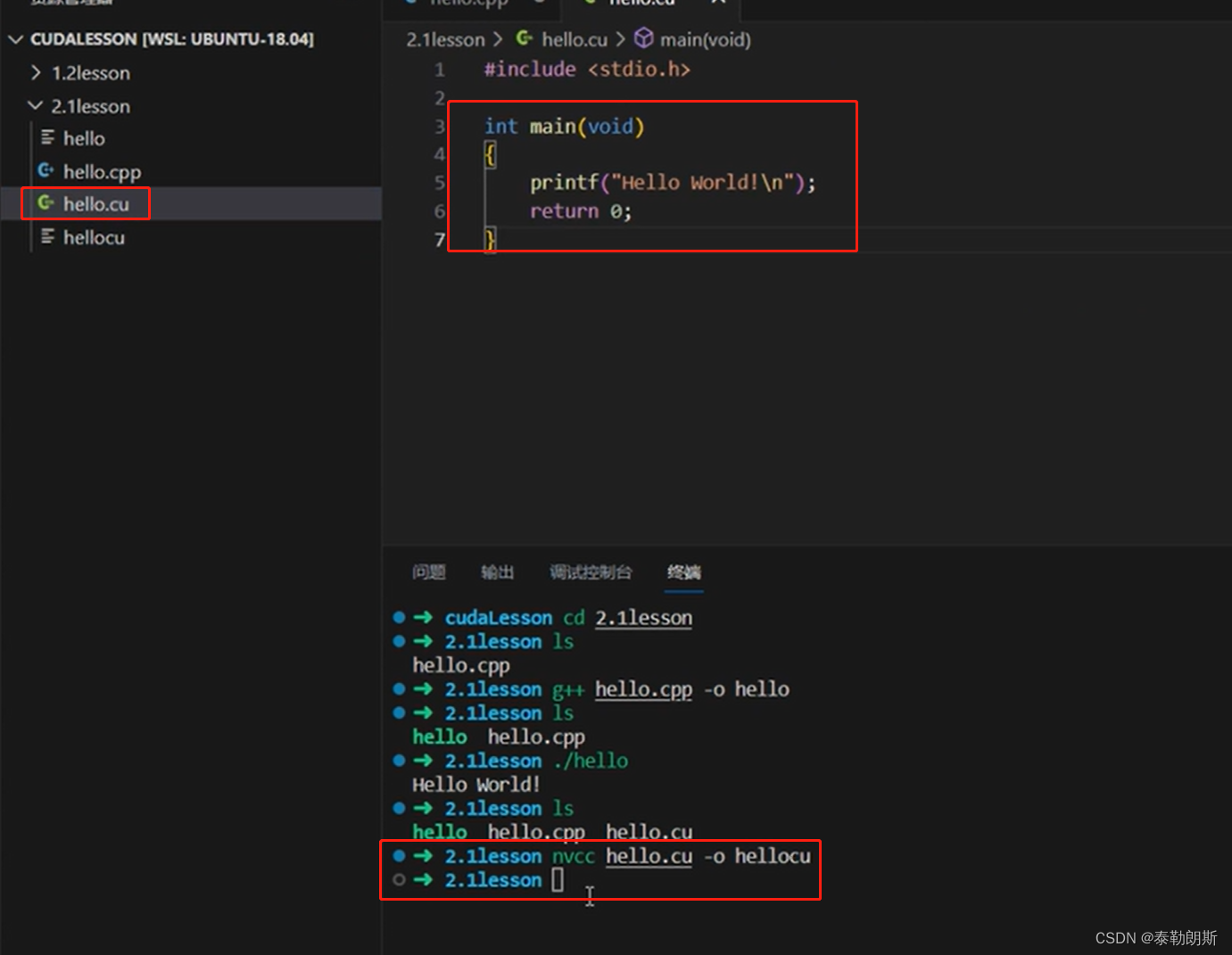



cudaDeviceSynchronize()是设备同步函数,等待核函数执行。
CUDA 线程模型

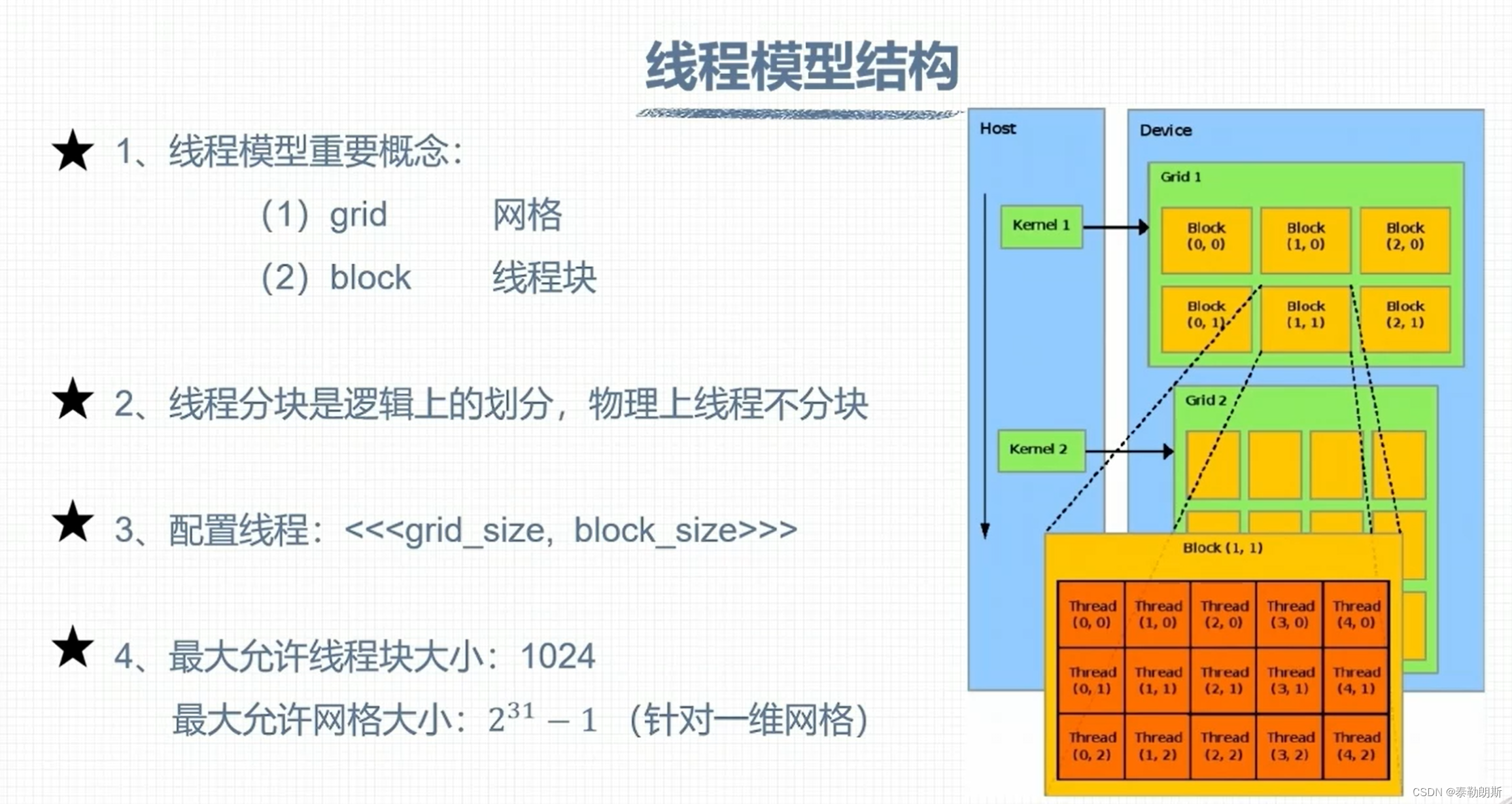

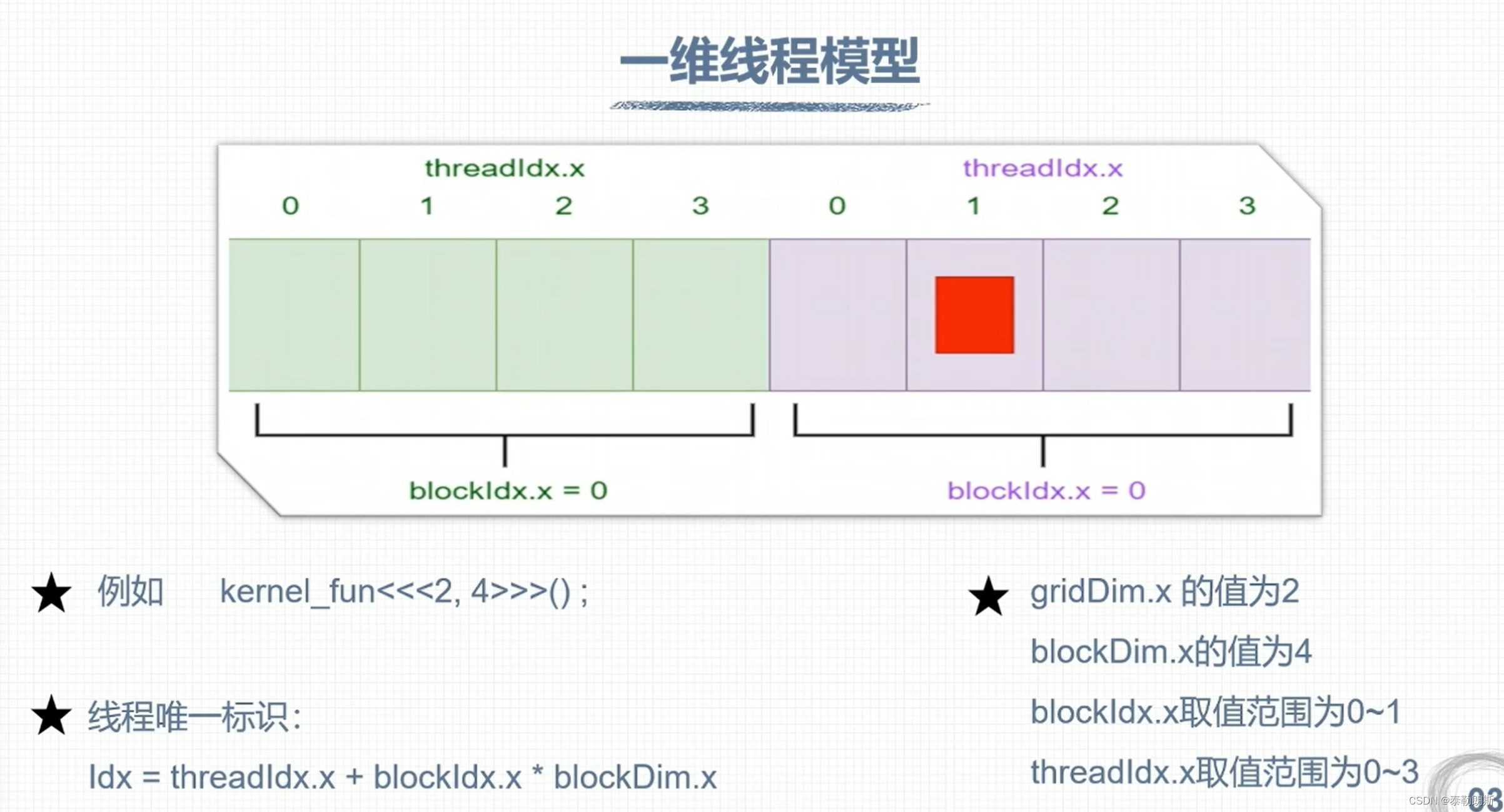
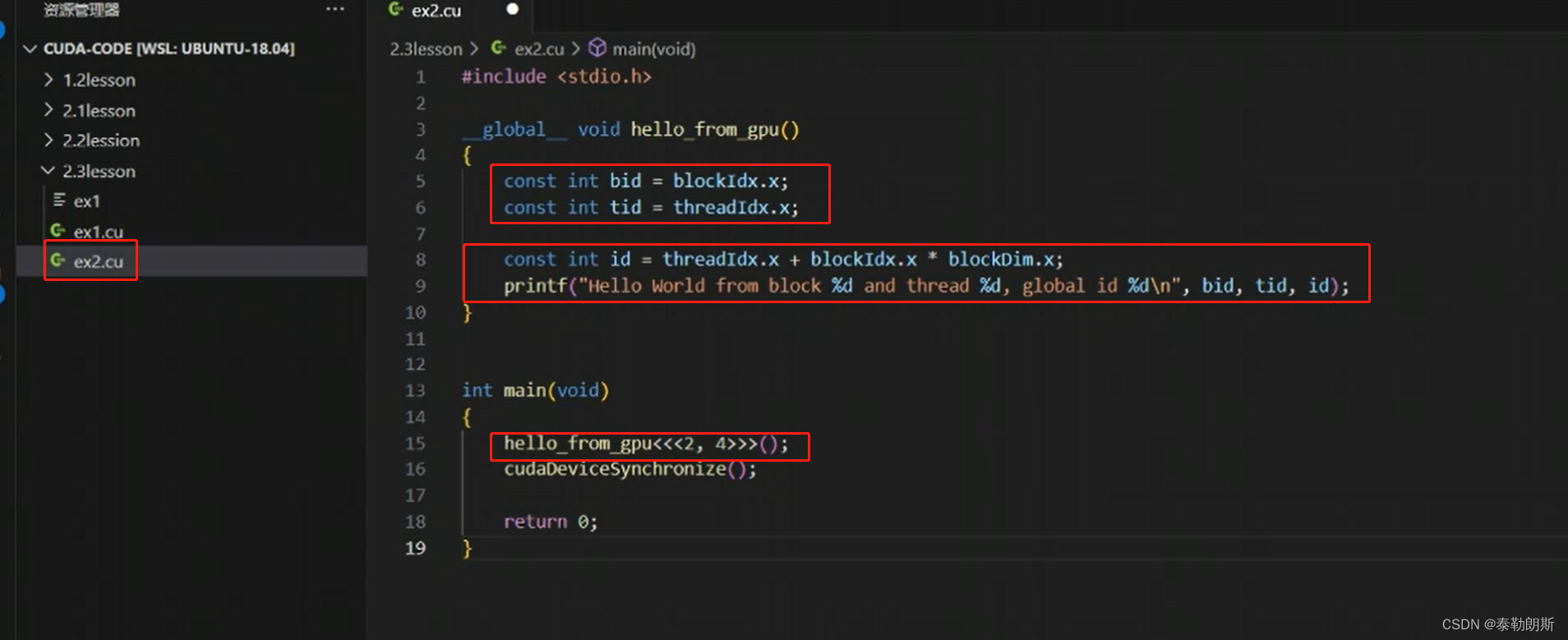
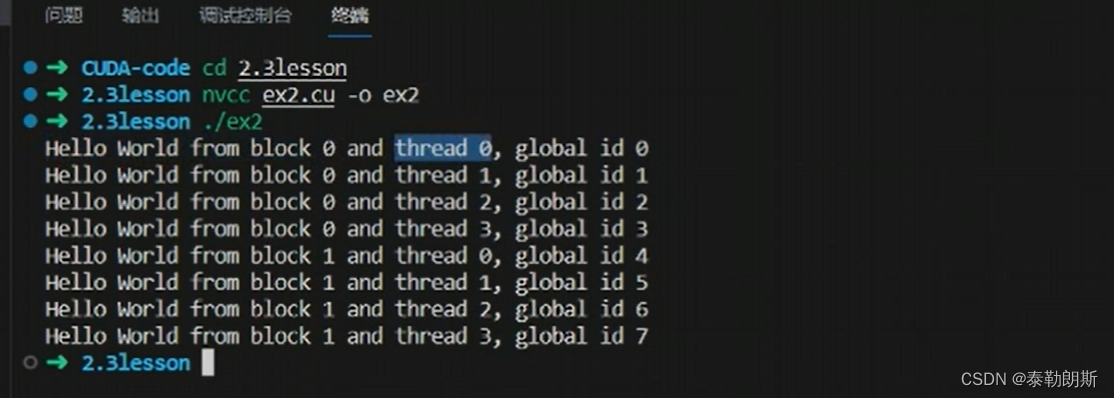




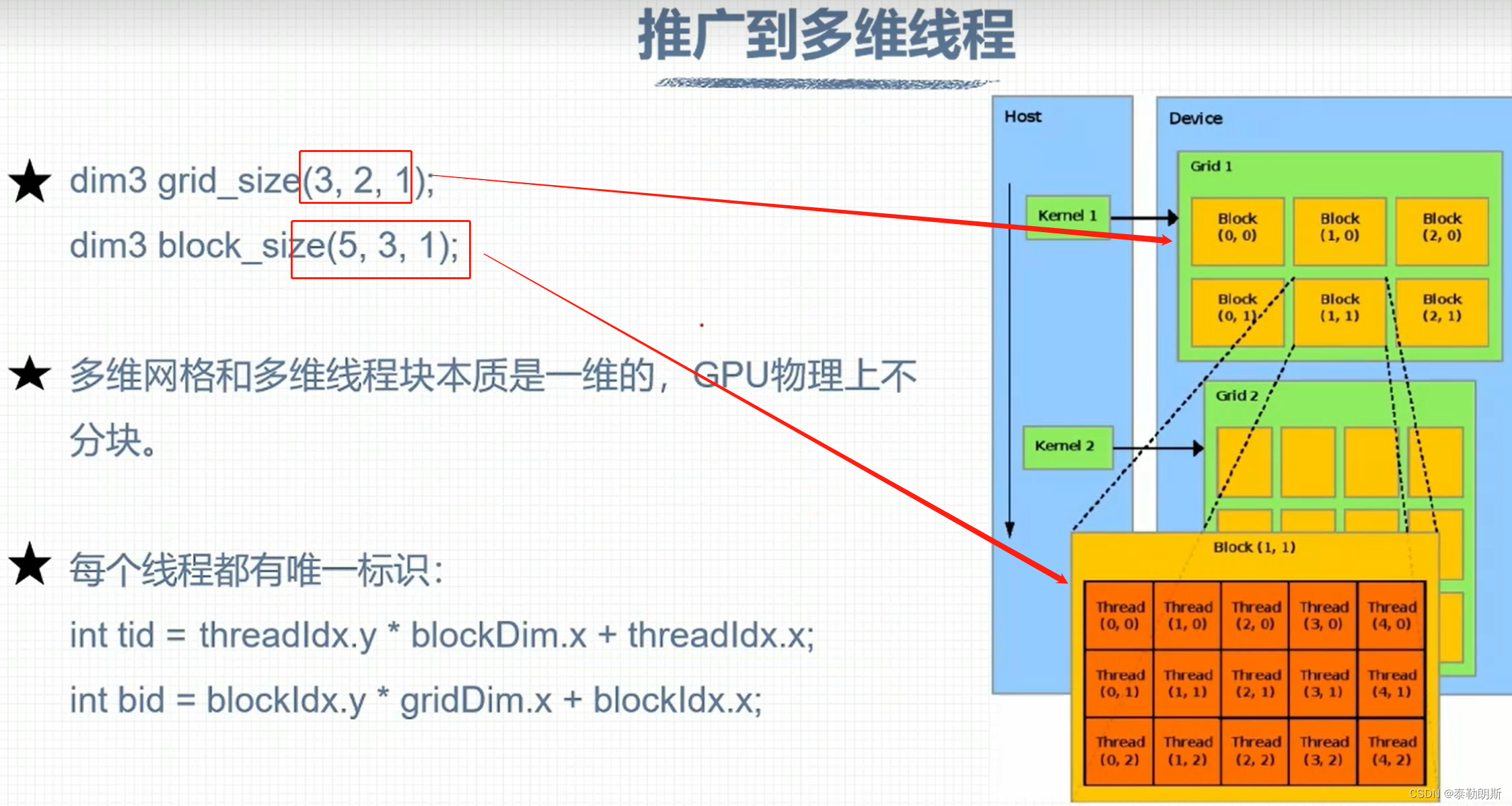
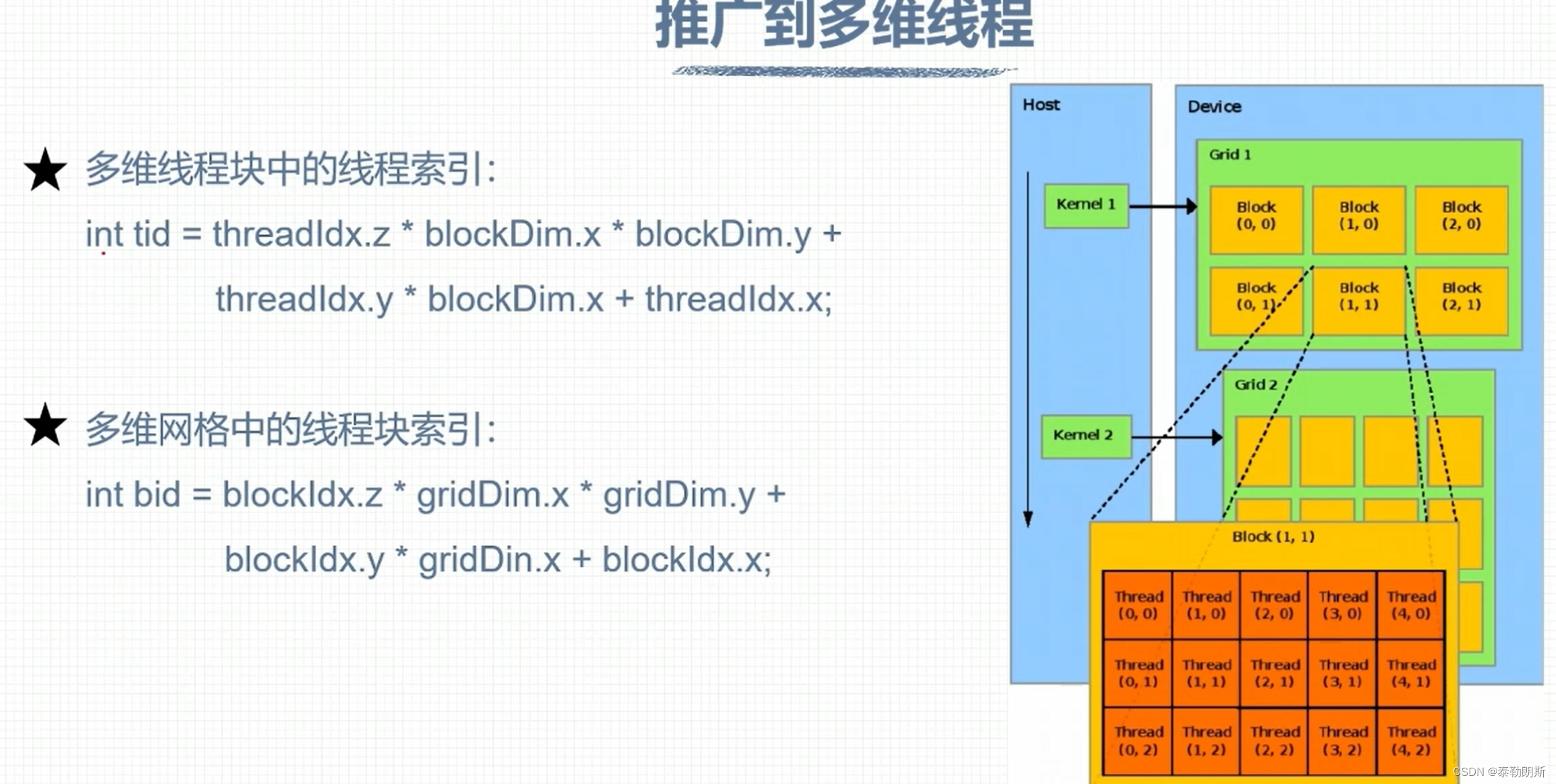

线程索引计算

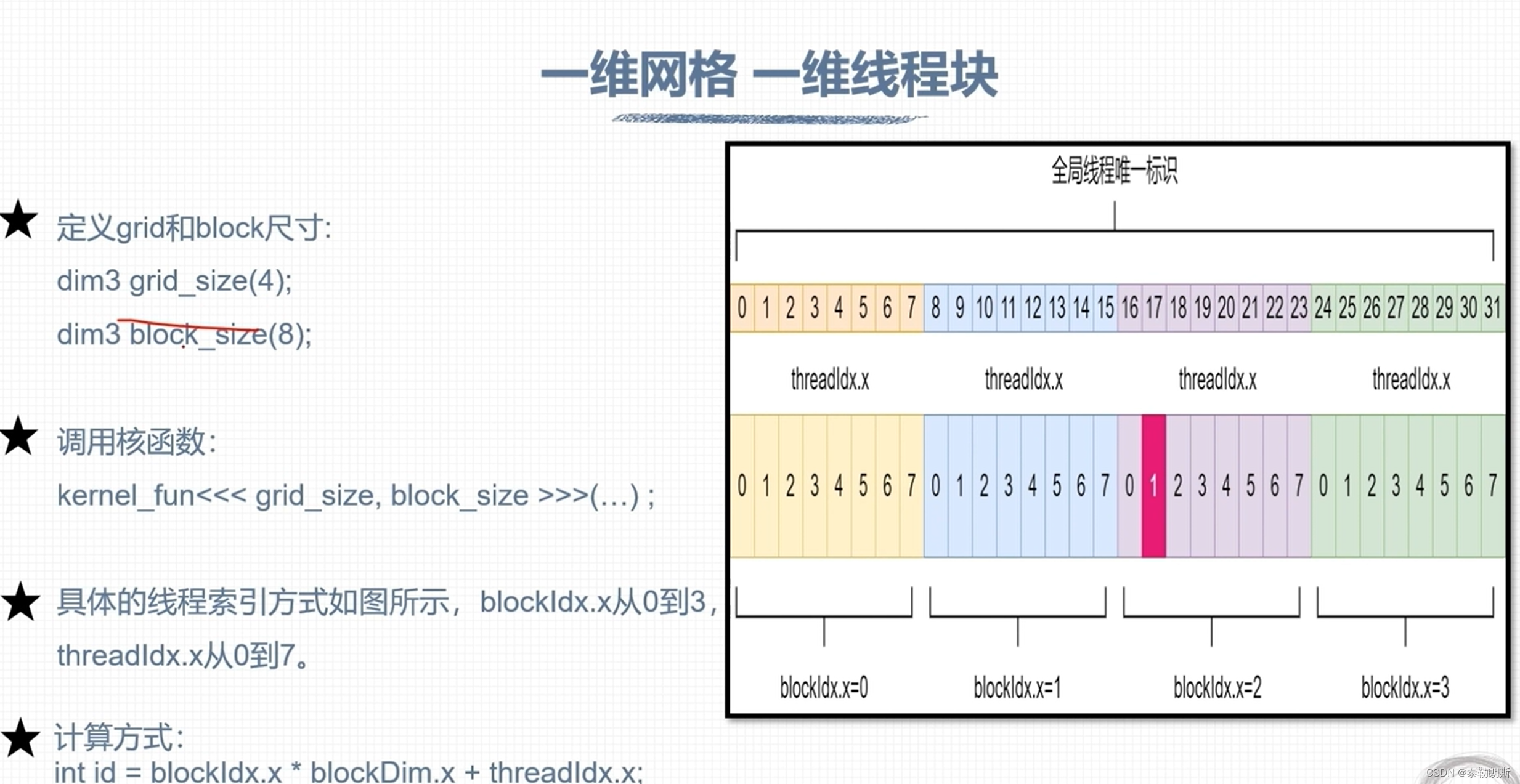
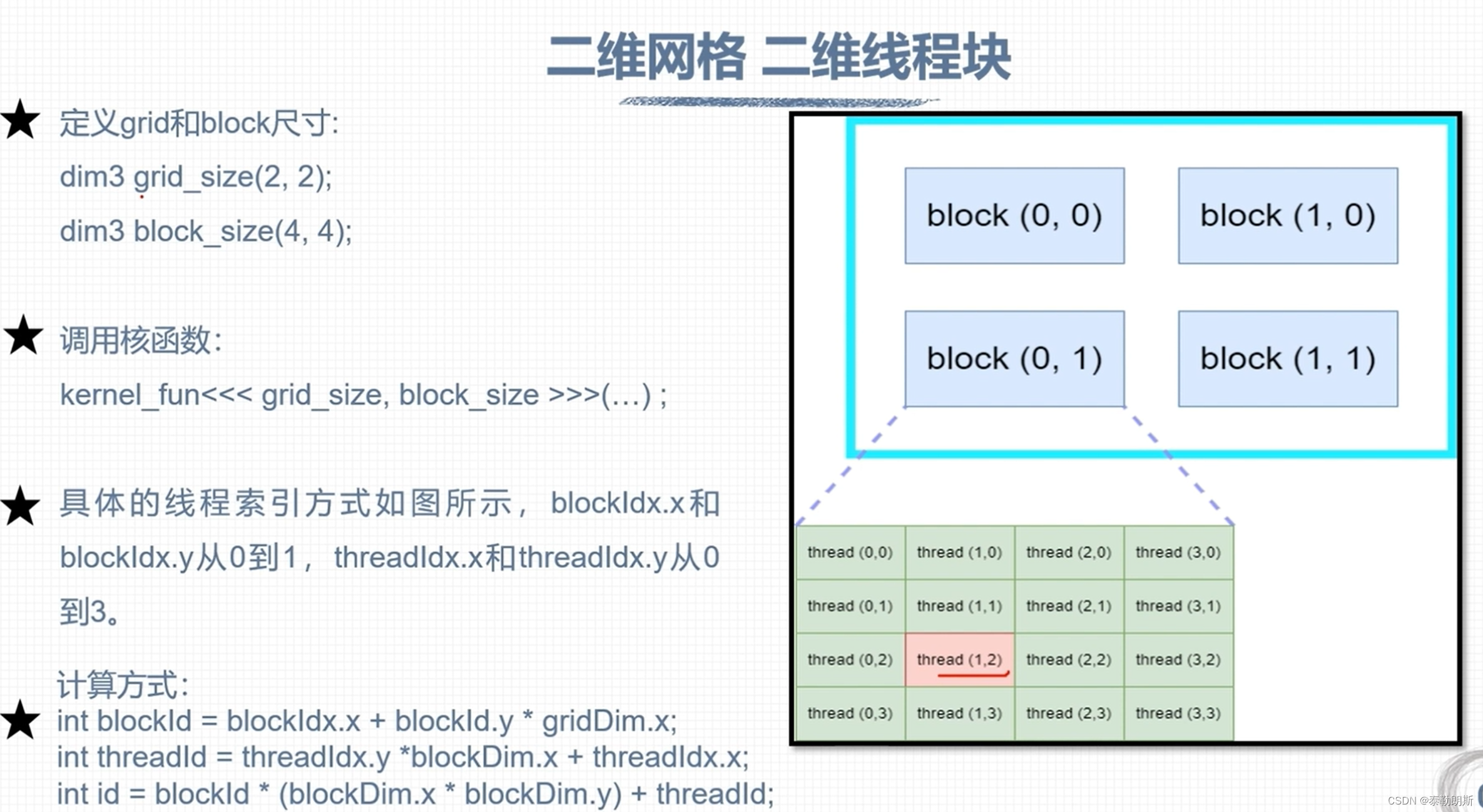




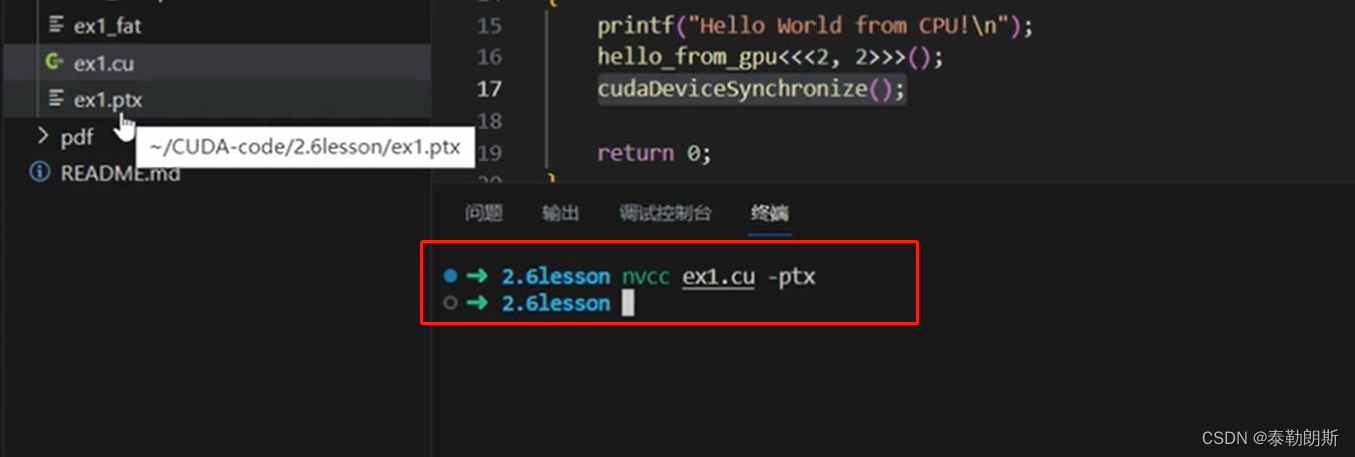
nvcc 编译流程和GPU计算能力



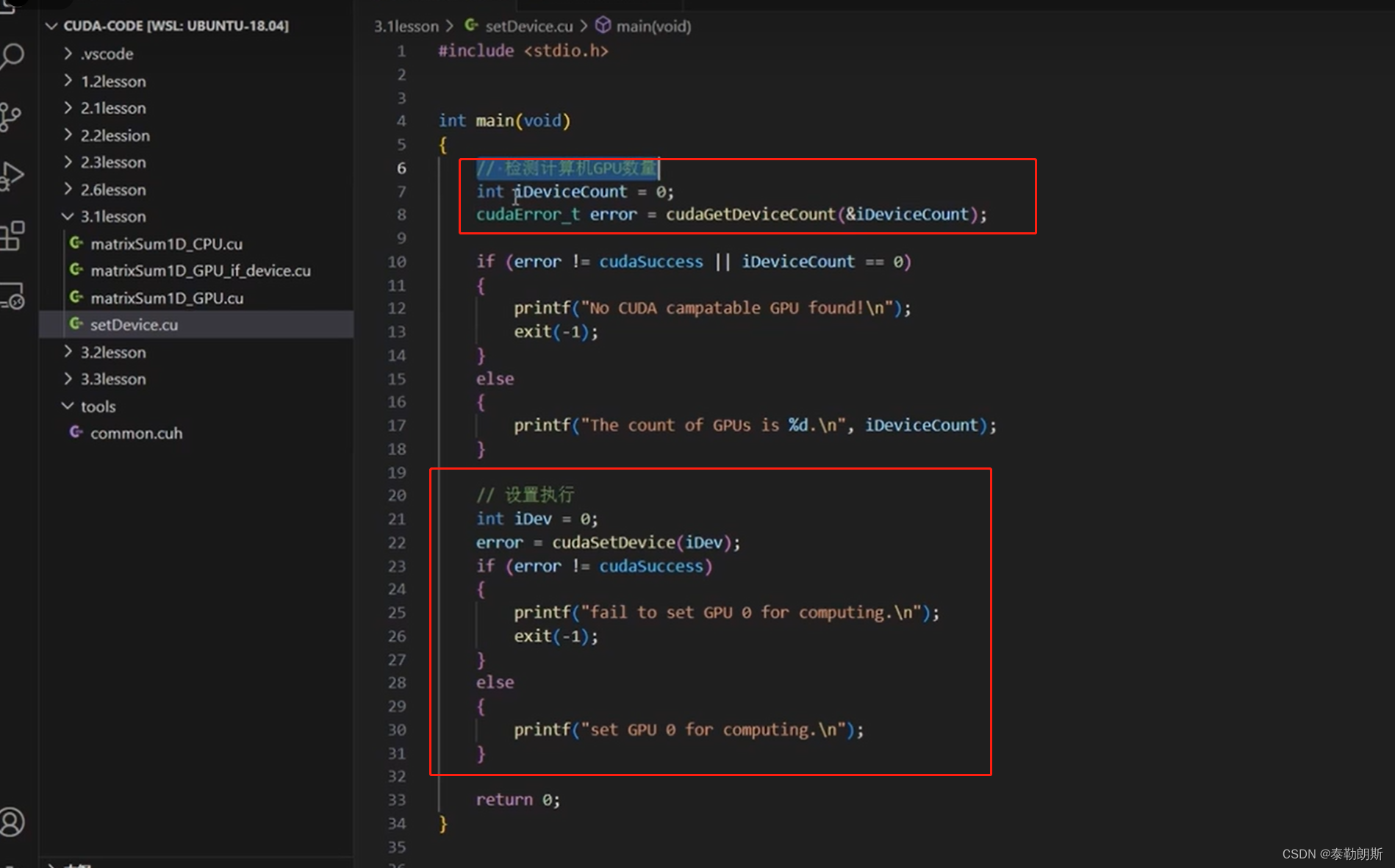
CUDA 程序兼容性问题


不要被下面的—误解了,应该是ppt的问题



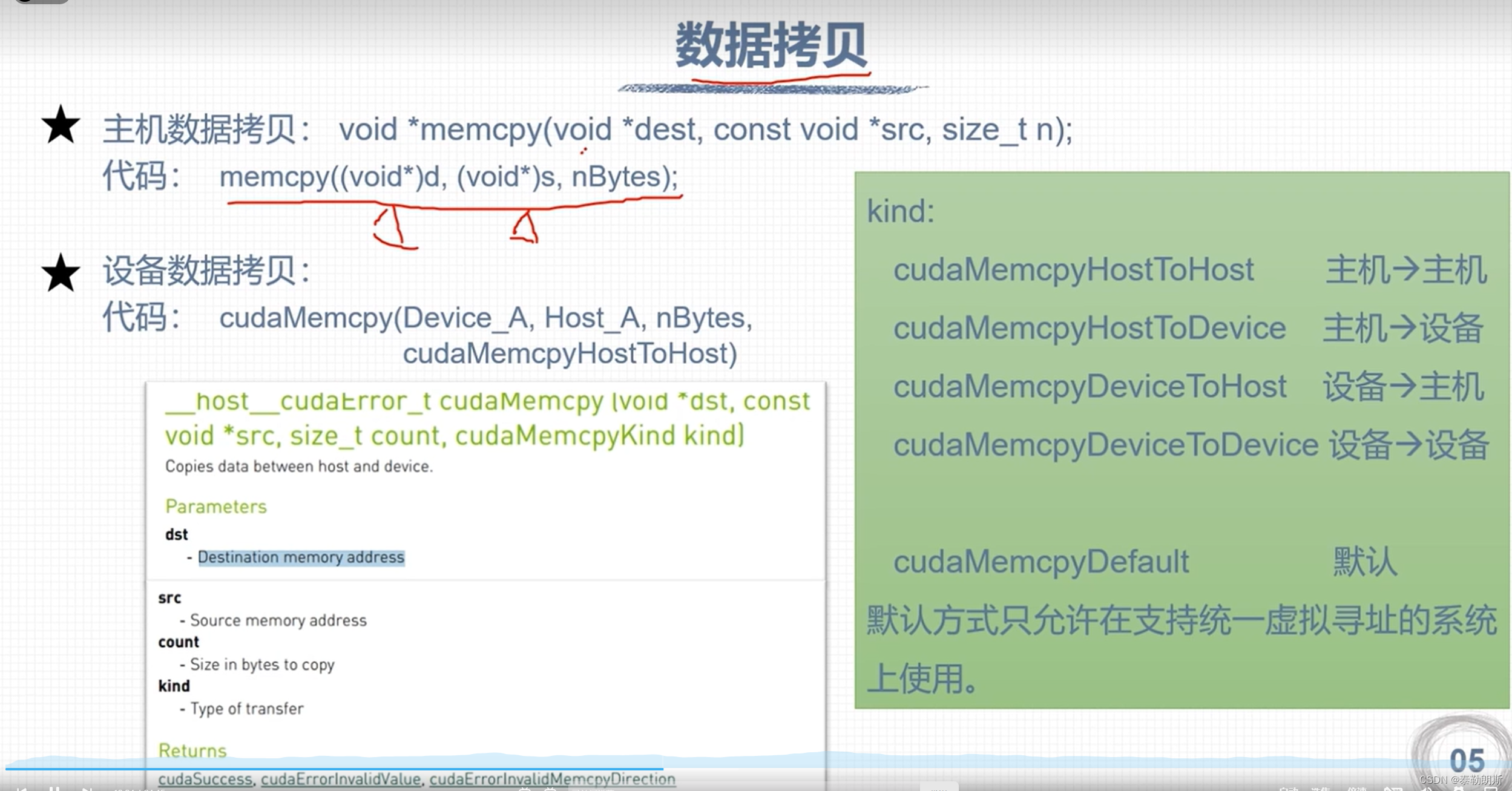
CUDA 矩阵加法运算



注意上面函数前面的__host__ device



示例代码
/*********************************************************************************************
* file name : matrixSum1D_GPU.cu
* author : 权 双
* date : 2023-08-04
* brief : 矩阵求和程序,通过调用核函数在GPU执行
***********************************************************************************************/
#include <stdio.h>
#include "../tools/common.cuh"
__global__ void addFromGPU(float *A, float *B, float *C, const int N)
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = tid + bid * blockDim.x;
C[id] = A[id] + B[id];
}
void initialData(float *addr, int elemCount)
{
for (int i = 0; i < elemCount; i++)
{
addr[i] = (float)(rand() & 0xFF) / 10.f;
}
return;
}
int main(void)
{
// 1、设置GPU设备
setGPU();
// 2、分配主机内存和设备内存,并初始化
int iElemCount = 512; // 设置元素数量
size_t stBytesCount = iElemCount * sizeof(float); // 字节数
// (1)分配主机内存,并初始化
float *fpHost_A, *fpHost_B, *fpHost_C;
fpHost_A = (float *)malloc(stBytesCount);
fpHost_B = (float *)malloc(stBytesCount);
fpHost_C = (float *)malloc(stBytesCount);
if (fpHost_A != NULL && fpHost_B != NULL && fpHost_C != NULL)
{
memset(fpHost_A, 0, stBytesCount); // 主机内存初始化为0
memset(fpHost_B, 0, stBytesCount);
memset(fpHost_C, 0, stBytesCount);
}
else
{
printf("Fail to allocate host memory!\n");
exit(-1);
}
// (2)分配设备内存,并初始化
float *fpDevice_A, *fpDevice_B, *fpDevice_C;
cudaMalloc((float**)&fpDevice_A, stBytesCount);
cudaMalloc((float**)&fpDevice_B, stBytesCount);
cudaMalloc((float**)&fpDevice_C, stBytesCount);
if (fpDevice_A != NULL && fpDevice_B != NULL && fpDevice_C != NULL)
{
cudaMemset(fpDevice_A, 0, stBytesCount); // 设备内存初始化为0
cudaMemset(fpDevice_B, 0, stBytesCount);
cudaMemset(fpDevice_C, 0, stBytesCount);
}
else
{
printf("fail to allocate memory\n");
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
exit(-1);
}
// 3、初始化主机中数据
srand(666); // 设置随机种子
initialData(fpHost_A, iElemCount);
initialData(fpHost_B, iElemCount);
// 4、数据从主机复制到设备
cudaMemcpy(fpDevice_A, fpHost_A, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(fpDevice_B, fpHost_B, stBytesCount, cudaMemcpyHostToDevice);
cudaMemcpy(fpDevice_C, fpHost_C, stBytesCount, cudaMemcpyHostToDevice);
// 5、调用核函数在设备中进行计算
dim3 block(32);
dim3 grid(iElemCount / 32);
addFromGPU<<<grid, block>>>(fpDevice_A, fpDevice_B, fpDevice_C, iElemCount); // 调用核函数
// cudaDeviceSynchronize();
// 6、将计算得到的数据从设备传给主机
cudaMemcpy(fpHost_C, fpDevice_C, stBytesCount, cudaMemcpyDeviceToHost);
for (int i = 0; i < 10; i++) // 打印
{
printf("idx=%2d\tmatrix_A:%.2f\tmatrix_B:%.2f\tresult=%.2f\n", i+1, fpHost_A[i], fpHost_B[i], fpHost_C[i]);
}
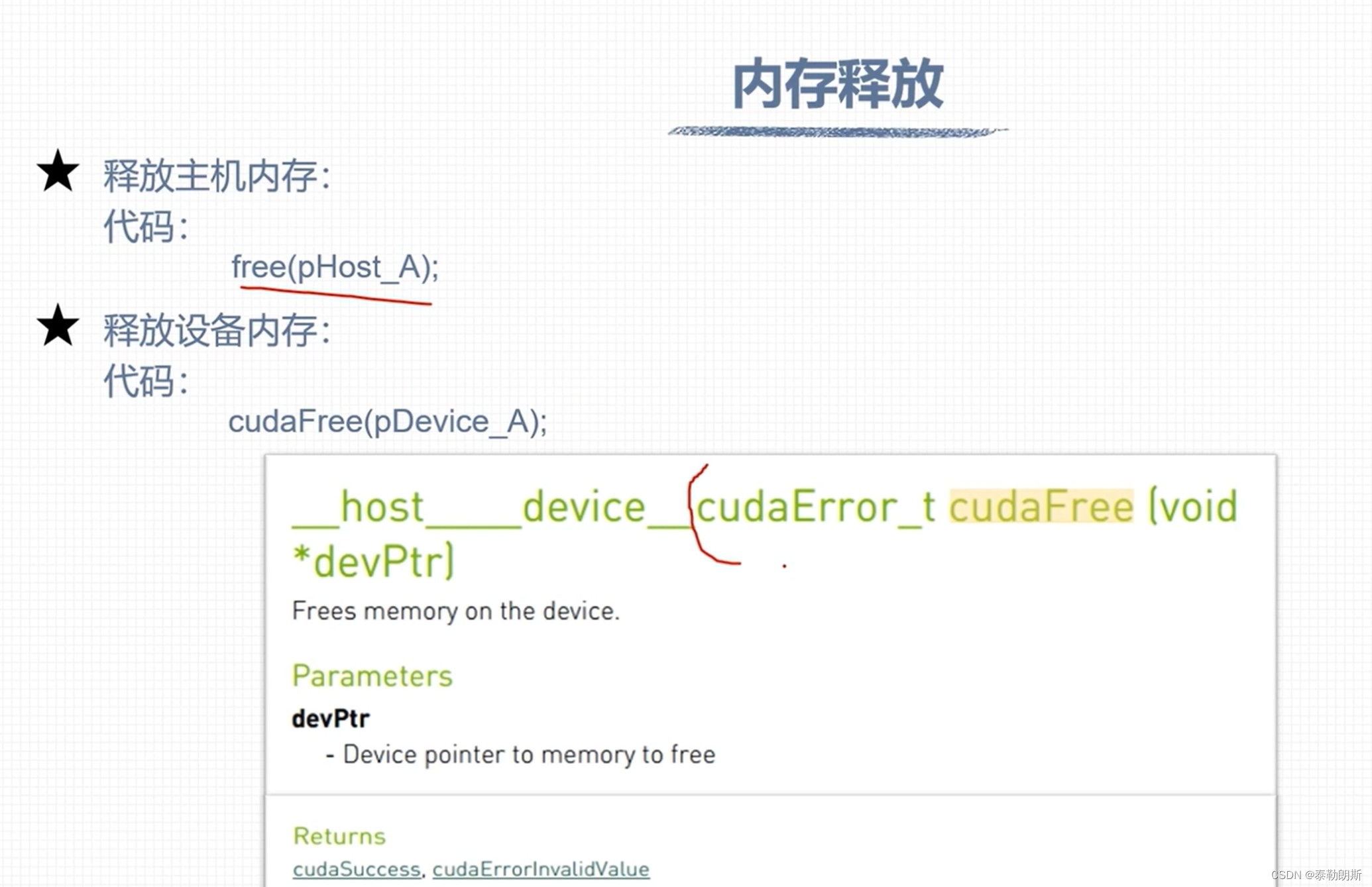
// 7、释放主机与设备内存
free(fpHost_A);
free(fpHost_B);
free(fpHost_C);
cudaFree(fpDevice_A);
cudaFree(fpDevice_B);
cudaFree(fpDevice_C);
cudaDeviceReset();
return 0;
}


__device__ float add(const float x, const float y)
{
return x + y;
}
__global__ void addFromGPU(float *A, float *B, float *C, const int N)
{
const int bid = blockIdx.x;
const int tid = threadIdx.x;
const int id = tid + bid * blockDim.x; // 513 32*17=544
if (id >= N) return;
C[id] = add(A[id], B[id]);
}