在机器学习的广袤星空中,支持向量机(Support Vector Machine,简称SVM)无疑是一颗璀璨的明珠。它以其独特的分类能力和强大的泛化性能,在数据分类、模式识别、回归分析等领域大放异彩。本文将详细剖析SVM算法的原理、特点、应用及其优缺点,带领读者走进SVM的奇妙世界。
一、SVM算法的基本原理
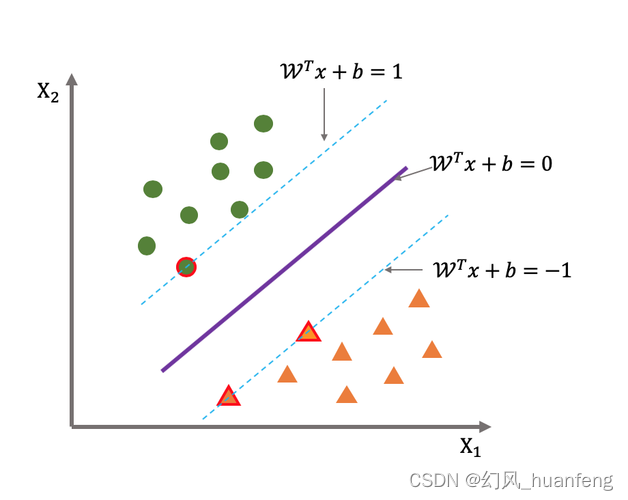
SVM算法是一种基于监督学习的分类算法,其核心思想是找到一个超平面,使得不同类别的样本点距离该超平面的距离最大化。这个超平面被称为最优超平面或决策边界。SVM通过求解一个二次规划问题来找到这个最优超平面,从而实现对数据的分类。
在SVM中,距离最优超平面最近的样本点被称为支持向量。这些支持向量在训练过程中起着关键作用,因为它们决定了最优超平面的位置。而远离最优超平面的样本点对分类结果的影响较小,因此在SVM中通常被忽略。
二、SVM算法的特点与优势
- 高效性:SVM算法通过求解二次规划问题来找到最优超平面,具有较高的计算效率。此外,SVM还可以利用核函数将非线性问题转化为线性问题,从而处理更为复杂的数据集。
- 泛化能力强:SVM算法通过最大化支持向量到最优超平面的距离来增强模型的泛化能力。这使得SVM在处理新数据时表现出色,能够应对各种复杂的分类任务。
- 对高维数据友好:SVM算法在处理高维数据时表现出良好的性能。在高维空间中,SVM可以通过寻找最优超平面来有效地分类数据,避免了维度灾难的问题。
三、SVM算法的应用领域
SVM算法在众多领域都有广泛的应用,包括但不限于以下几个方面:
- 图像识别:SVM在图像识别领域具有广泛的应用,如人脸识别、手写数字识别等。通过提取图像特征并构建SVM分类器,可以实现高效的图像分类任务。
- 文本分类:SVM在文本分类方面也表现出色,如新闻分类、情感分析等。通过对文本进行预处理和特征提取,SVM可以有效地对文本进行分类。
- 生物信息学:在生物信息学领域,SVM被广泛应用于基因表达数据的分析、蛋白质结构预测等方面。通过利用SVM强大的分类能力,可以帮助研究人员更好地理解生物数据。
四、SVM算法的优缺点分析
-
优点:
(1)SVM算法具有高效的计算性能和强大的泛化能力,能够处理各种复杂的分类任务。
(2)SVM对高维数据友好,能够有效地避免维度灾难的问题。
(3)SVM可以通过选择不同的核函数来处理非线性问题,具有较强的灵活性。 -
缺点:
(1)SVM算法对参数的选择较为敏感,不同的参数设置可能导致模型性能的差异。因此,在实际应用中需要进行参数调优。
(2)SVM在处理大规模数据集时可能会面临计算资源不足的问题。由于SVM需要求解二次规划问题,当样本数量较大时,计算复杂度会显著增加。
五、SVM算法的发展趋势与前景
随着机器学习技术的不断发展,SVM算法也在不断完善和优化。未来,SVM算法有望在以下几个方面取得更大的突破:
- 算法优化:通过改进SVM的求解算法和优化方法,降低计算复杂度,提高模型的训练速度和分类性能。
- 核函数选择:研究更加有效的核函数,以更好地处理非线性问题和复杂数据集。
- 与其他算法的结合:将SVM与其他机器学习算法(如深度学习、集成学习等)进行结合,形成更加强大的分类模型。
![40+ Node.js 常见面试问题 [2024]](https://img-blog.csdnimg.cn/img_convert/f95dcda7bc8d02d3c8ce811ac5651d49.jpeg)


![【Hadoop】-Apache Hive概述 Hive架构[11]](https://img-blog.csdnimg.cn/direct/f5070b63db8f4e439514474a37c5a988.png)