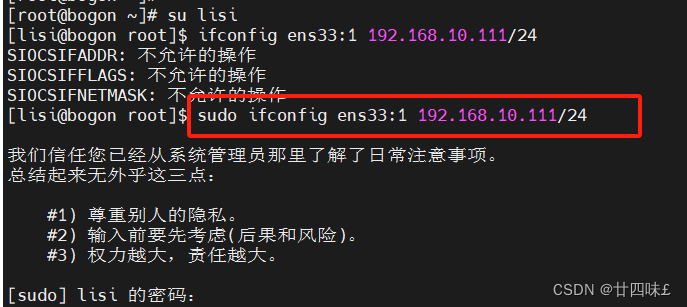
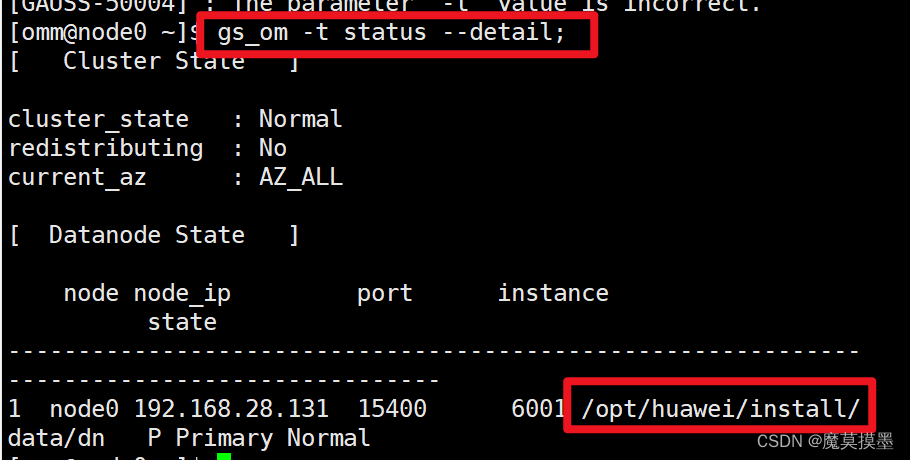
图片来源: Tatev Aslanyan
一、说明
我们将使用 PyTorch 从头开始构建生成式 AI、大型语言模型——包括嵌入、位置编码、多头自注意、残差连接、层归一化,Baby GPT 是一个探索性项目,旨在逐步构建类似 GPT 的语言模型。在这个项目中,我不会太详细地解释理论,而是主要展示编码部分。该项目从一个简单的 Bigram 模型开始,并逐渐融入了 Transformer 模型架构的高级概念。
按照教程进行操作,这是我的 Github 存储库
在这篇博客中,我们将讨论:
1. Introduction
- Explanation of hyperparameters in GPT model
2. Step 1: Data Preparation Including Tokenization
- Loading and preprocessing data for training
- Tokenization and data splitting
3. Step 2: Building a Simple Bigram Language Model
- Mini-batching for efficient training
- Defining the Bigram Language Model
- Training procedure using Adam optimizer
4. Step 3: Adding Positional Encodings
- Incorporating positional information
5. Step 4: Incorporating AdamW Optimizer
- Introduction to the AdamW optimizer
- Training the model with AdamW
6. Step 5: Introducing Self-Attention
- Explanation of Self-Attention mechanism
- Dot Product vs Sclaed Dot Product
- Implementation of Self-Attention in PyTorch
7. Step 6: Transitioning to Multi-Head Self-Attention
- Implementing Multi-Head Self-Attention
- Combining multiple attention heads
8. Step 7: Adding Feed-Forward Networks
- Implementing Feed-Forward neural network with ReLU activation
9. Step 8: Formulating Blocks (Nx in Model)
- Stacking Transformer blocks
- Explanation of the components within a Transformer block
10. Step 9: Adding Residual Connections
- Enhancing the Block class with residual connections
11. Step 10: Incorporating Layer Normalization
- Adding Layer Normalization to the model
12. Step 11: Implementing Dropout
- Introduction of Dropout for regularization
13. Step 12: Scaling Model - NVIDIA CUDA for GPU
- Instructions for scaling up the model using GPU acceleration
This blog provides a comprehensive overview of building a language model, starting from data preprocessing and tokenization, through the implementation of core Transformer components like self-attention, multi-head attention, and feed-forward networks, all the way to optimizing and scaling the model using GPU acceleration.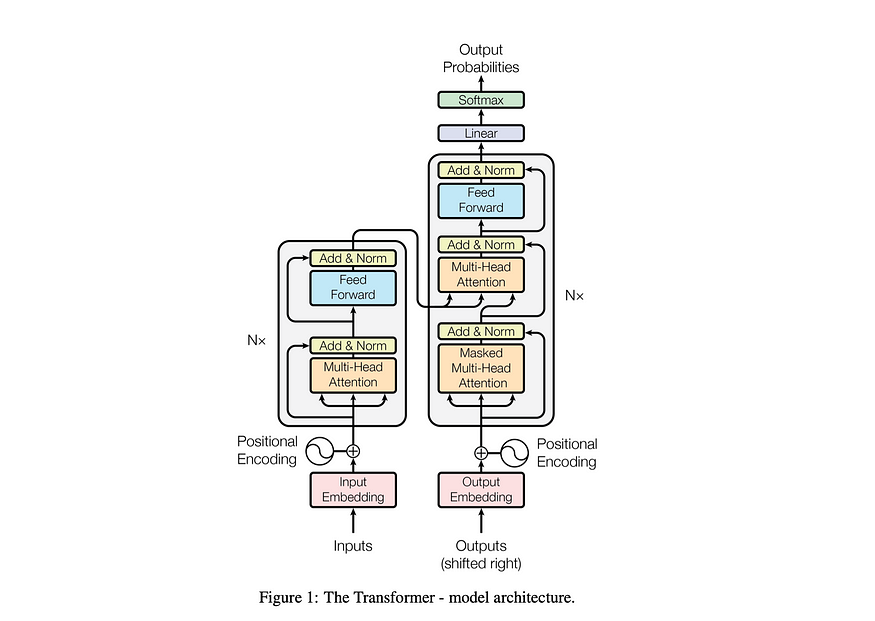
图片来源:Attention is All You Need Paper
二、GPT 模型中的超参数
使用以下超参数调整模型的性能:
batch_size:训练期间并行处理的序列数block_size:模型正在处理的序列的长度d_model:模型中的特征数(嵌入的大小)d_k:每个注意力头的特征数。num_iter:模型将运行的训练迭代总数Nx:模型中变压器块或层数。eval_interval:计算和评估模型损失的时间间隔lr_rate:Adam 优化器的学习率device:如果兼容的 GPU 可用,则自动设置为,否则默认为 。'cuda''cpu'eval_iters:平均评估损失的迭代次数h:多头注意力机制中的注意力头数dropout_rate:训练期间用于防止过拟合的辍学率
这些超参数经过精心选择,以平衡模型在不过度拟合的情况下从数据中学习的能力,并有效地管理计算资源。
三、解码器只是我们 GPT 的 Transformer 的一部分
OpenAI 于 2018 年发表的原始论文 [链接在这里]
3.1 CPU 与 GPU 模型示例
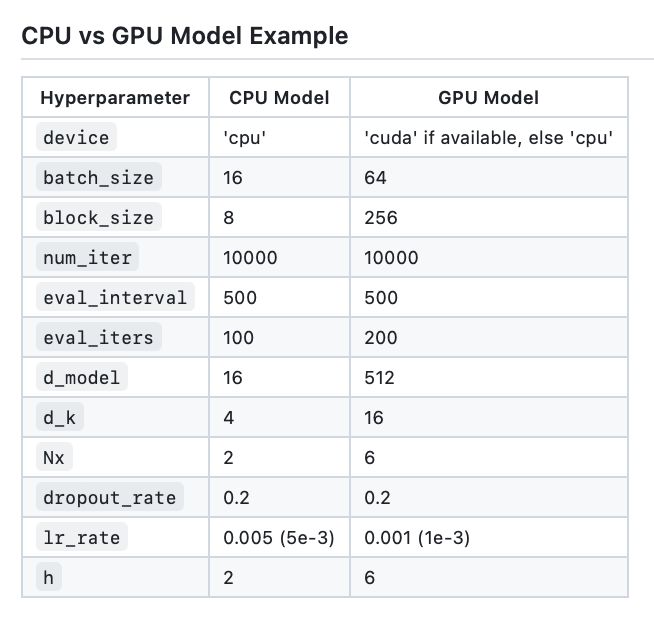
图片来源: Tatev Aslanyan
3.1 第 1 步:数据准备,包括标记化
- 负载数据:
open('./GPT Series/input.txt', 'r', encoding = 'utf-8') - BuildVocab:使用 和 创建词汇词典。
chars_to_intint_to_chars - CharacterTokenization:使用函数将字符串转换为整数,然后使用函数转换回整数。
encodedecode - DataSplit:将数据集划分为训练集 () 和验证集 ()。
train_datavalid_data
3.2 第 2 步:构建简单的 Bigram 语言模型(初始模型)
- 小批量:该函数以小批量的形式准备数据进行训练。
get_batch - BigramModel:定义类中的模型体系结构。
BigramLM - TrainModel:使用 Adam 优化器和损失估计概述训练过程。
3.2.1 小批量技术
小批量是机器学习中的一种技术,其中训练数据被分成小批量。在模型训练期间,每个小批次都单独处理。这种方法有助于:
- 有效利用内存:通过不一次将整个数据集加载到内存中,它可以减少计算开销。
- 更快的收敛:与单独处理每个数据点相比,批量处理数据可以带来更快的收敛。
- 改进泛化:小批量在训练过程中引入噪声,这可以帮助模型更好地泛化到看不见的数据。
# Function to create mini-batches for training or validation.
def get_batch(split):
# Select data based on training or validation split.
data = train_data if split == "train" else valid_data
# Generate random start indices for data blocks, ensuring space for 'block_size' elements.
ix = torch.randint(len(data)-block_size, (batch_size,))
# Create input (x) and target (y) sequences from data blocks.
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
# Move data to GPU if available for faster processing.
x, y = x.to(device), y.to(device)
return x, yay3.2.2 如何选择您的批量大小?
批量大小的选择对于训练 Baby GPT 等神经网络模型至关重要。以下是对其重要性的简要说明:
- 计算效率:更大的批量大小可以更有效地利用 GPU 的并行处理功能,从而加快训练速度。但是,超大批处理可能会超出 GPU 内存限制。
- 学习动态:较小的批次通常会为模型提供更频繁的更新,从而可能导致更快的收敛。但是,它们也可能导致训练不太稳定。
- 泛化:在批量大小和模型的泛化能力之间需要权衡。较小的批次往往可以更好地泛化,但可能会导致更嘈杂的梯度估计。
- 资源约束:最终,批处理大小的选择也受到可用计算资源的限制。较大的批处理需要更多的内存和计算能力。
- 模型性能:批量大小的选择会影响模型的最终性能。通常需要进行试验,以找到平衡训练速度、稳定性和模型准确性的最佳大小。

图片来源: Tatev Aslanyan
3.2.3 估计损失(负损失可能性或交叉熵)
该函数计算模型在指定迭代次数 (eval_iters) 内的平均损失。它用于在不影响其参数的情况下评估模型的性能。estimate_loss
该模型设置为评估模式,以禁用某些层(如流失),以实现一致的损失计算。计算训练和验证数据的平均损失后,模型将恢复到训练模式。此功能对于监控培训过程并在必要时进行调整至关重要。
@torch.no_grad()
def estimate_loss():
result = {}
# setting model in evaluation state
model.eval()
for split in ['train', 'valid_date']:
losses = torch.zeros(eval_iters)
for e in range(eval_iters):
X,Y = get_batch(split)
logits, loss = model(X,Y)
# storing each iterations loss
losses[e] = loss.item()
result[split] = losses.mean()
# setting back to training state
model.train()
return result3.3 第 3 步:添加位置编码
位置编码:使用类中的位置信息向模型添加位置信息。我们将位置编码添加到角色的嵌入中,就像在转换器架构中一样。positional_encodings_tableBigramLM
3.4 第 4 步:合并 Adam W Optimizer
在这里,我们设置并使用 AdamW 优化器在 PyTorch 中训练神经网络模型。Adam 优化器在许多深度学习场景中都受到青睐,因为它结合了随机梯度下降的另外两个扩展的优点:AdaGrad 和 RMSProp。
Adam 计算每个参数的自适应学习率。除了存储过去平方梯度的指数衰减平均值(如 RMSProp)之外,Adam 还保留了过去梯度的指数衰减平均值,类似于动量。
这使优化器能够调整神经网络每个权重的学习速率,从而在复杂的数据集和架构上进行更有效的训练。
AdamW 修改了将权重衰减合并到优化过程中的方式,解决了原始 Adam 优化器的一个问题,即权重衰减与梯度更新没有很好地分离,导致正则化的应用欠佳。
使用 AdamW 有时可以提高训练性能,并泛化到看不见的数据。我们之所以选择 AdamW,是因为它能够比标准的 Adam 优化器更有效地处理权重衰减,从而有可能改进模型训练和泛化。
optimizer = torch.optim.AdamW(model.parameters(), lr = lr_rate)
for iter in range(num_iter):
# estimating the loss for per X interval
if iter % eval_interval == 0:
losses = estimate_loss()
print(f"step {iter}: train loss is {losses['train']:.5f} and validation loss is {losses['valid_date']:.5f}")
# sampling a mini batch of data
xb, yb = get_batch("train")
# Forward Pass
logits, loss = model(xb, yb)
# Zeroing Gradients: Before computing the gradients, existing gradients are reset to zero. This is necessary because gradients accumulate by default in PyTorch.
optimizer.zero_grad(set_to_none=True)
# Backward Pass or Backpropogation: Computing Gradients
loss.backward()
# Updating the Model Parameters
optimizer.step()3.5 第 5 步:引入自我关注
自注意力是一种机制,允许模型以不同的方式权衡输入数据不同部分的重要性。它是 Transformer 架构的关键组件,使模型能够专注于输入序列的相关部分进行预测。
- 点积注意: 一种简单的注意力机制,它根据查询和键之间的点积计算加权值的总和。
- 缩放点积注意事项:对点积注意力的改进,通过键的维度缩小点积,防止梯度在训练期间变得太小。
- OneHeadSelfAttention:实现单头自注意力机制,允许模型关注输入序列的不同位置。该课程展示了注意力机制及其缩放版本背后的直觉。
SelfAttention
Baby GPT 项目中的每个相应模型都以前一个模型为基础,从自我注意力机制背后的直觉开始,然后是点积和缩放点积注意力的实际实现,最终集成了一个单头自我注意力模块。
class SelfAttention(nn.Module):
"""Self Attention (One Head)"""
""" d_k = C """
def __init__(self, d_k):
super().__init__() #superclass initialization for proper torch functionality
# keys
self.keys = nn.Linear(d_model, d_k, bias = False)
# queries
self.queries = nn.Linear(d_model, d_k, bias = False)
# values
self.values = nn.Linear(d_model, d_k, bias = False)
# buffer for the model
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
def forward(self, X):
"""Computing Attention Matrix"""
B, T, C = X.shape
# Keys matrix K
K = self.keys(X) # (B, T, C)
# Query matrix Q
Q = self.queries(X) # (B, T, C)
# Scaled Dot Product
scaled_dot_product = Q @ K.transpose(-2,-1) * 1/math.sqrt(C) # (B, T, T)
# Masking upper triangle
scaled_dot_product_masked = scaled_dot_product.masked_fill(self.tril[:T, :T]==0, float('-inf'))
# SoftMax transformation
attention_matrix = F.softmax(scaled_dot_product_masked, dim=-1) # (B, T, T)
# Weighted Aggregation
V = self.values(X) # (B, T, C)
output = attention_matrix @ V # (B, T, C)
retur 该类表示 Transformer 模型的基本构建块,用单个磁头封装自注意力机制。以下是对其组件和流程的深入了解:SelfAttention
- 初始化:构造函数初始化键、查询和值的线性层,所有层都具有维度。这些线性变换将输入投射到不同的子空间中,以便进行后续的注意力计算。
__init__(self, d_k)d_k - 缓冲区:将较低的三角矩阵注册为不被视为模型参数的持久缓冲区。该矩阵用于注意力机制中的掩码,以防止在每个计算步骤中考虑未来位置(在解码器自注意力中很有用)。
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size))) - 前向传球:该方法定义了在每次调用自注意力模块时执行的计算
forward(self, X)
3.6 第 6 步:过渡到多头自我关注

图片来源:Attention is All You Need Paper
MultiHeadAttention:组合类中多个磁头的输出。MultiHeadAttention 类是自注意力机制的扩展实现,具有上一步中的一个磁头,但现在多个注意力磁头并行运行,每个注意力磁头都专注于输入的不同部分。SelfAttentionMultiHeadAttention
class MultiHeadAttention(nn.Module):
"""Multi Head Self Attention"""
"""h: #heads"""
def __init__(self, h, d_k):
super().__init__()
# initializing the heads, we want h times attention heads wit size d_k
self.heads = nn.ModuleList([SelfAttention(d_k) for _ in range(h)])
# adding linear layer to project the concatenated heads to the original dimension
self.projections = nn.Linear(h*d_k, d_model)
# adding dropout layer
self.droupout = nn.Dropout(dropout_rate)
def forward(self, X):
# running multiple self attention heads in parallel and concatinate them at channel dimension
combined_attentions = torch.cat([h(X) for h in self.heads], dim = -1)
# projecting the concatenated heads to the original dimension
combined_attentions = self.projections(combined_attentions)
# applying dropout
combined_attentions = self.droupout(combined_attentions)
return combined_attentions3.7 步骤 7:添加前馈网络
FeedForward:在类中实现具有 ReLU 激活的前馈神经网络。将这种全连接的前馈添加到我们的模型中,就像在原始 Transformer 模型中一样。FeedForward
class FeedForward(nn.Module):
"""FeedForward Layer with ReLU activation function"""
def __init__(self, d_model):
super().__init__()
self.net = nn.Sequential(
# 2 linear layers with ReLU activation function
nn.Linear(d_model, 4*d_model),
nn.ReLU(),
nn.Linear(4*d_model, d_model),
nn.Dropout(dropout_rate)
)
def forward(self, X):
# applying the feedforward layer
return self.net(X)3.8 第 8 步:制定模块(模型中的 Nx)
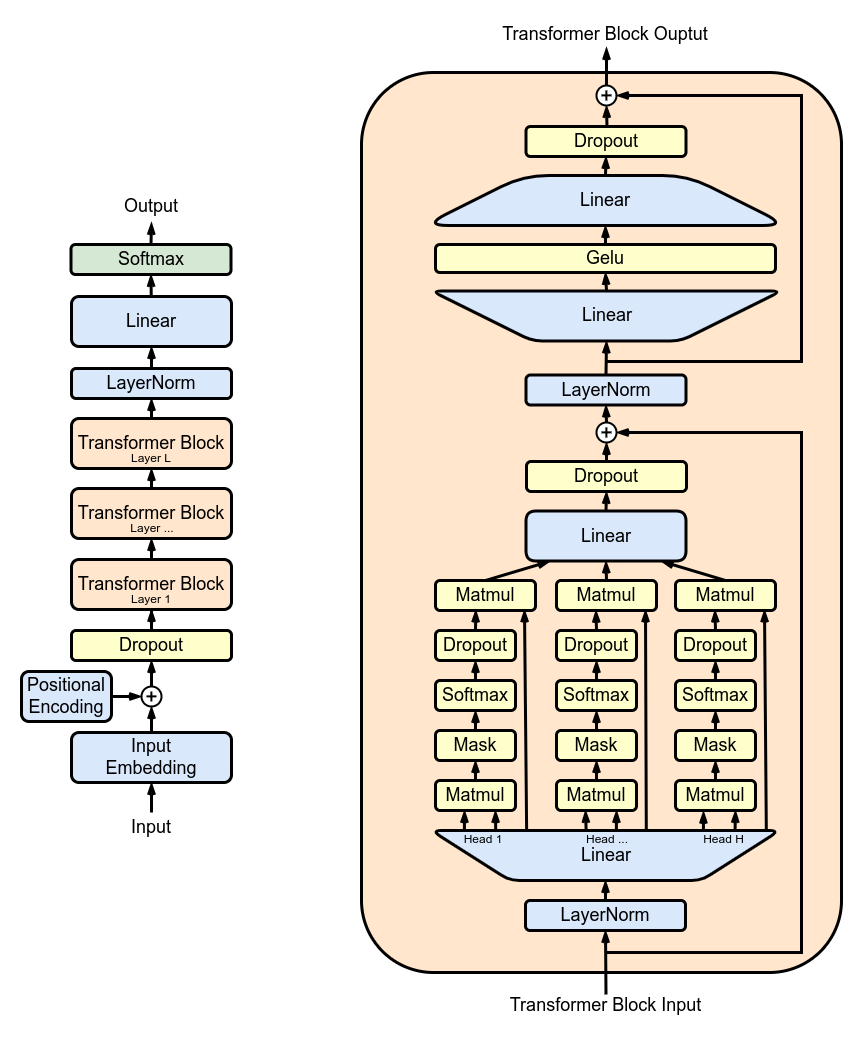
变压器块: 使用类堆叠变压器块以创建更深层次的网络架构。Block
深度和复杂性:在神经网络中,深度是指处理数据的层数。每个额外的层(或块,在Transformers的情况下)允许网络捕获输入数据的更复杂和抽象的特征。
顺序处理:每个 Transformer 模块处理其前一个模块的输出,逐渐建立对输入的更复杂的理解。这种顺序处理允许网络开发数据的深度分层表示。变压器块的组件
- 多头注意力:C对每个块进行集中,它通过同时关注序列的不同部分来处理输入。这种并行处理是模型理解复杂数据关系的关键。
- 前馈网络:它在关注后进一步处理数据,增加了另一层复杂性。
- 残余连接:它们有助于维持整个网络的信息流,防止输入数据通过层丢失,并有助于解决梯度消失问题。
- 图层归一化: 在每个主要组件之前应用,它可以稳定学习过程,确保跨深层的顺利训练。
class Block(nn.Module):
"""Multiple Blocks of Transformer"""
def __init__(self, d_model, h):
super().__init__()
d_k = d_model // h
# Layer 4: Adding Attention layer
self.attention_head = MultiHeadAttention(h, d_k) # h heads of d_k dimensional self-attention
# Layer 5: Feed Forward layer
self.feedforward = FeedForward(d_model)
# Layer Normalization 1
self.ln1 = nn.LayerNorm(d_model)
# Layer Normalization 2
self.ln2 = nn.LayerNorm(d_model)
# Adding additional X for Residual Connections
def forward(self,X):
X = X + self.attention_head(self.ln1(X))
X = X + self.feedforward(self.ln2(X))
return X3.9 步骤 9:添加残差连接
ResidualConnections:增强班级以包含剩余连接,提高学习效率。残差连接,也称为跳跃连接,是深度神经网络设计中的一项关键创新,尤其是在 Transformer 模型中。它们解决了训练深度网络的主要挑战之一:梯度消失问题。Block
# Adding additional X for Residual Connections
def forward(self,X):
X = X + self.attention_head(self.ln1(X))
X = X + self.feedforward(self.ln2(X))
return X3. 10 第 10 步:合并图层归一化
LayerNorm:使用 Block 类中的 nn.LayerNorm(d_model) 将层归一化添加到 Transformer.Normalizing 层输出。

class LayerNorm:
def __init__(self, dim, eps=1e-5):
self.eps = eps
self.gamma = torch.ones(dim)
self.beta = torch.zeros(dim)
def __call__(self, x):
# orward pass calculaton
xmean = x.mean(1, keepdim=True) # layer mean
xvar = x.var(1, keepdim=True) # layer variance
xhat = (x - xmean) / torch.sqrt(xvar + self.eps) # normalize to unit variance
self.out = self.gamma * xhat + self.beta
return self.out
def parameters(self):
return [self.gamma, self.beta]3.11 第 11 步:实现辍学
Dropout:作为正则化方法添加到 and 层中,以防止过拟合。我们将辍学添加到:SelfAttentionFeedForward
- 自我关注类
- 多头自我关注
- 前馈
3.12 第 12 步:扩展模型:适用于 GPU 的 NVIDIA CUDA
ScaleUp:通过扩展 、 、 、 和 来增加模型的复杂性。您将需要 CUDA 工具包以及配备 NVIDIA GPU 的机器来训练和测试这个更大的模型。batch_sizeblock_sized_modeld_kNx
如果要试用 CUDA 进行 GPU 加速,请确保安装了支持 CUDA 的相应 PyTorch 版本。
import torch
torch.cuda.is_available()您可以通过在 PyTorch 安装命令中指定 CUDA 版本来执行此操作,例如在命令行中:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113四、结论
以上论文是塔特夫·卡伦·阿斯兰扬的研究记录。因为来不及验证实践活动。这里暂时作为一个记录,等待日后研究和发现。论文的参考地址为:
BabyGPT: Build Your Own GPT Large Language Model from Scratch | by Tatev Karen Aslanyan | LunarTech