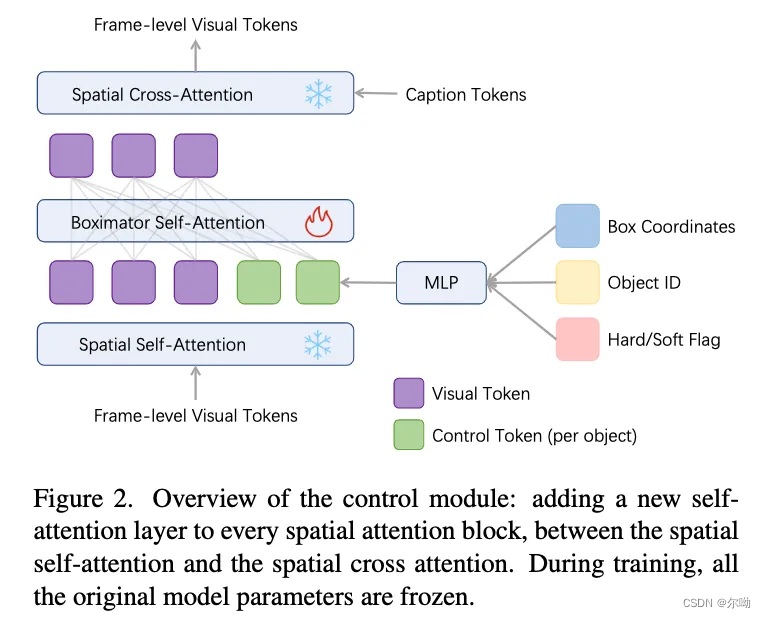
- 模型添加控制的方式是利用bbox和move path,在训练的时候冻结原始视频生成模型的参数,只是训练新添加的control module,
- 修改的位置是在spatial attetion里面,新添加了一个self attention
v = v + S e l f A t t n ( v ) v = v + T S ( S e l f A t t n ( [ v , h b o x ] ) ) v = v + C r o s s A t t n ( v , h t e x t ) v = v + SelfAttn(v) \\ v = v + TS(SelfAttn([v,h_{box}])) \\ v = v + CrossAttn(v,h_{text}) v=v+SelfAttn(v)v=v+TS(SelfAttn([v,hbox]))v=v+CrossAttn(v,htext) - 输入的控制信号是 t b = M L P ( F o u r i e r ( [ b l o c , b i d , b f l a g ] ) ) t_b=MLP(Fourier([b_{loc},b_{id},b_{flag}])) tb=MLP(Fourier([bloc,bid,bflag])),其中id使用rgb表示,并归一化到0-1之间,h_box包含固定数量的control token,多余的使用t_null填充
- 数据的处理是首先过滤掉运动幅度不大的视频,之后使用caption模型来标注视频首帧图片,提取其中的名词,之后使用开放域目标检测和object tracker来生成框并扩展到所有帧,在训练的过程中会进行crop操作,这个操作会使得有的bbox被裁剪掉,这种情况下在边框会留下一个线段,以此来应对一个object进入画面和从画面中离开的场景;
- 训练的过程中还要解决的一个问题是如何保持物体和框的对应关系,解决的办法是在训练的时候使用模型来生成框,这个框的颜色就是control token里面id的颜色,这个叫做self tracking,在不包含self tracking的训练阶段生成的时候不生成框;
- 训练分为三个阶段,stage1是self tracking+hard bbox,stage2是self tracking + soft bbox,stage3是soft bbox





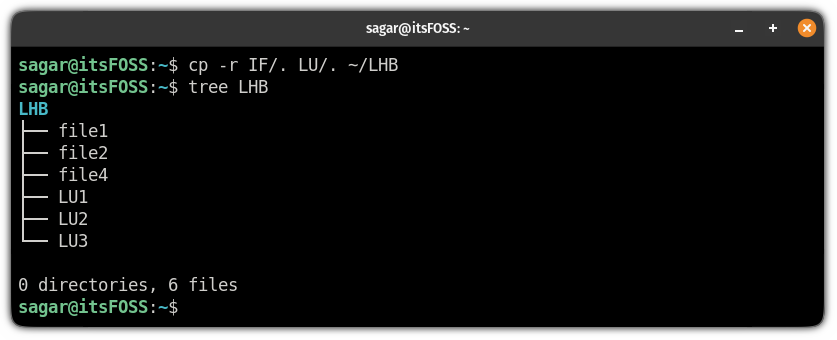

![[数据结构]——排序——插入排序](https://img-blog.csdnimg.cn/direct/61bff07359554a18b281a6a5d5bb0850.png)