引言:多任务学习的挑战与机遇
在深度学习领域,将大规模数据集上预训练的模型适配到各种下游任务是一种常见的策略。随之而来的是参数高效微调方法的兴起,这些方法旨在将预训练模型适配到不同任务,同时只训练最少量的参数。然而,大多数这些方法都是为单任务适配设计的,而在多任务学习(MTL)架构中进行参数高效训练仍是一个未被探索的领域。
在本文中,我们介绍了MTLoRA,这是一个用于MTL模型参数高效训练的新框架。MTLoRA采用了任务无关和任务特定的低秩适配模块,有效地解耦了MTL微调中的参数空间,使模型能够在MTL环境中平衡任务专业化和交互。我们将MTLoRA应用于基于层次化Transformer的MTL架构,将其适配到多个下游密集预测任务。我们在PASCAL数据集上的广泛实验表明,与完全微调MTL模型相比,MTLoRA在下游任务上实现了更高的准确率,同时减少了3.6倍的可训练参数数量。此外,MTLoRA在可训练参数数量与下游任务准确率之间建立了帕累托最优的权衡,超越了当前最先进的参数高效训练方法。

论文标题:MTLoRA: A Low-Rank Adaptation Approach for Efficient Multi-Task Learning
论文链接:https://arxiv.org/pdf/2403.20320.pdf
公众号【AI论文解读】后台回复“论文解读” 获取论文PDF!
MTLoRA框架简介:任务无关与任务特定的低秩适应
1. 多任务学习(MTL)的基本概念
多任务学习(MTL)是一种学习方法,旨在同时优化多个相关任务的性能,通过共享表示学习来提高模型的泛化能力。在MTL中,模型通过共享底层参数来学习跨任务的通用特征,同时保留一些任务特定的参数以捕获每个任务的独特性。这种方法不仅可以提高模型在各个任务上的表现,而且还能提高训练效率和模型的泛化能力。
2. 低秩适应(Low-Rank Adaptation)的应用
低秩适应(Low-Rank Adaptation,简称LoRA)是一种参数高效的微调方法,通过对预训练模型的权重矩阵进行低秩分解,来实现对新任务的适应。这种方法允许模型在保持原有权重结构的同时,通过训练较少的参数来适应特定任务,从而减少了计算负担和内存占用。LoRA在自然语言处理(NLP)和计算机视觉等领域都显示出了良好的适应性和效率。
3. MTLoRA的核心组件与作用
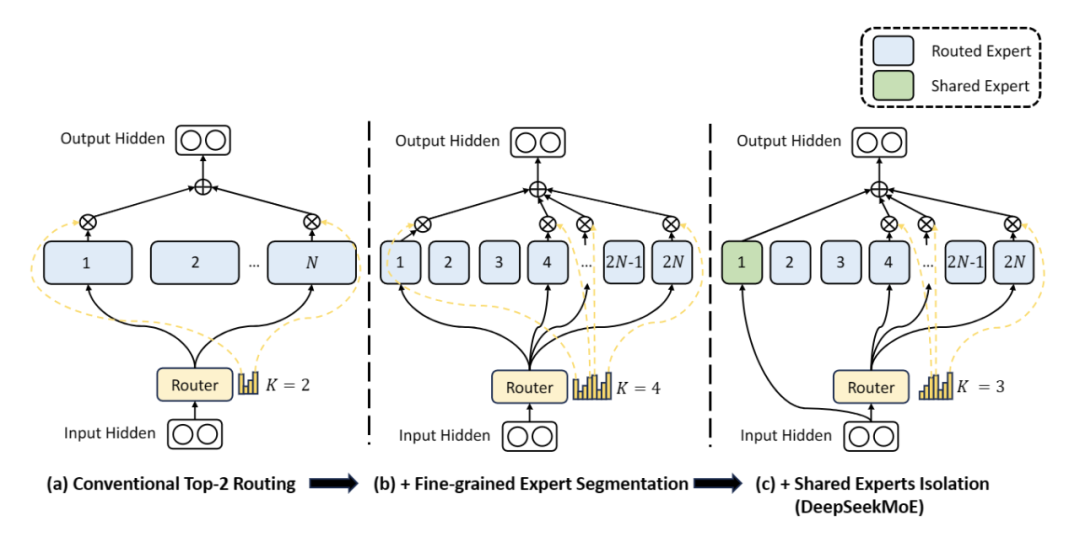
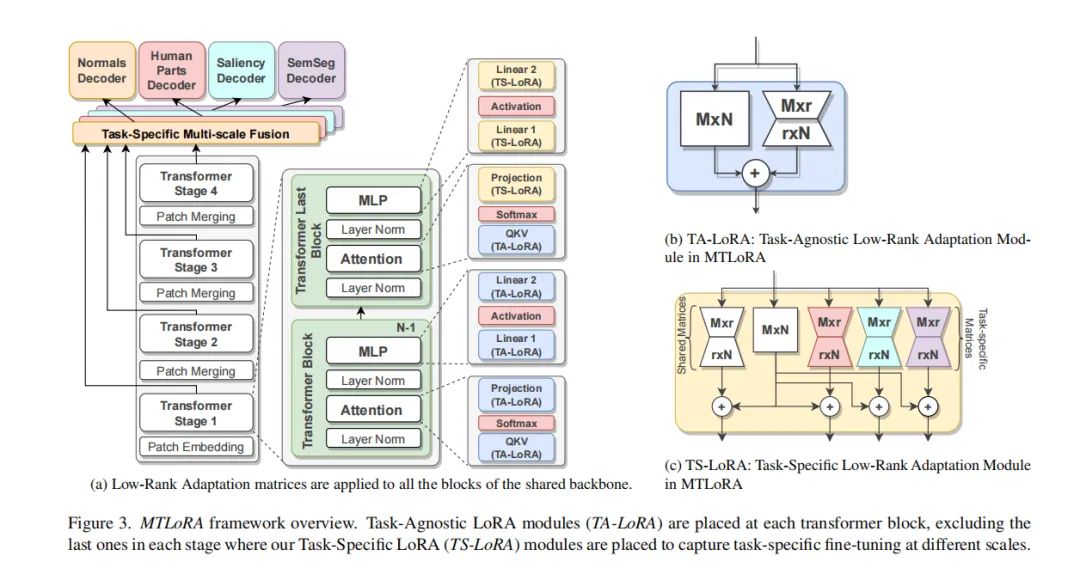
MTLoRA框架通过结合任务无关(Task-Agnostic)和任务特定(Task-Specific)的低秩适应模块,有效地解决了在多任务学习(MTL)中的参数高效微调问题。这两种模块共同作用,使得模型能够在学习跨任务共享特征的同时,也能捕获每个任务的特定特征。任务无关的低秩适应模块(TA-LoRA)旨在捕获多个下游任务之间的共享特征,而任务特定的低秩适应模块(TS-LoRA)则专注于学习每个任务的独特特征。这种策略不仅提高了模型在各个任务上的准确性,而且还显著减少了训练参数的数量,实现了准确性和效率的最优权衡。
实验设计:PASCAL数据集与评估指标
1. 数据集概述与任务类型
PASCAL数据集是一个广泛用于计算机视觉研究的标准数据集,包含了多种密集预测任务,如语义分割、人体部位检测、表面法线估计和显著性检测等。该数据集包含4,998张训练图像和5,105张验证图像,每张图像都有对应的多任务标注。这些多样化的任务类型使PASCAL数据集成为评估多任务学习模型性能的理想选择。
2. 评估指标与性能衡量
在PASCAL数据集上,各个任务的性能通过特定的评估指标来衡量。对于语义分割、显著性估计和人体部位分割任务,使用平均交并比(mean Intersection over Union,mIoU)作为评估指标。对于表面法线任务,则使用预测角度的根均方误差(root mean square error,rmse)来评估。此外,还引入了一个综合性能指标∆m,用于衡量模型在所有任务上的平均性能提升,从而全面评估MTLoRA框架在多任务学习中的效果。通过这些评估指标,可以准确地衡量MTLoRA在参数效率和任务准确性之间的权衡,证明了其在多任务学习中的优越性。
实验结果:MTLoRA的性能表现
1. 与全参数微调的对比
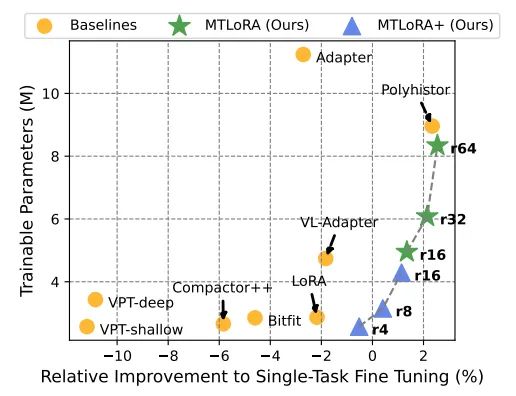
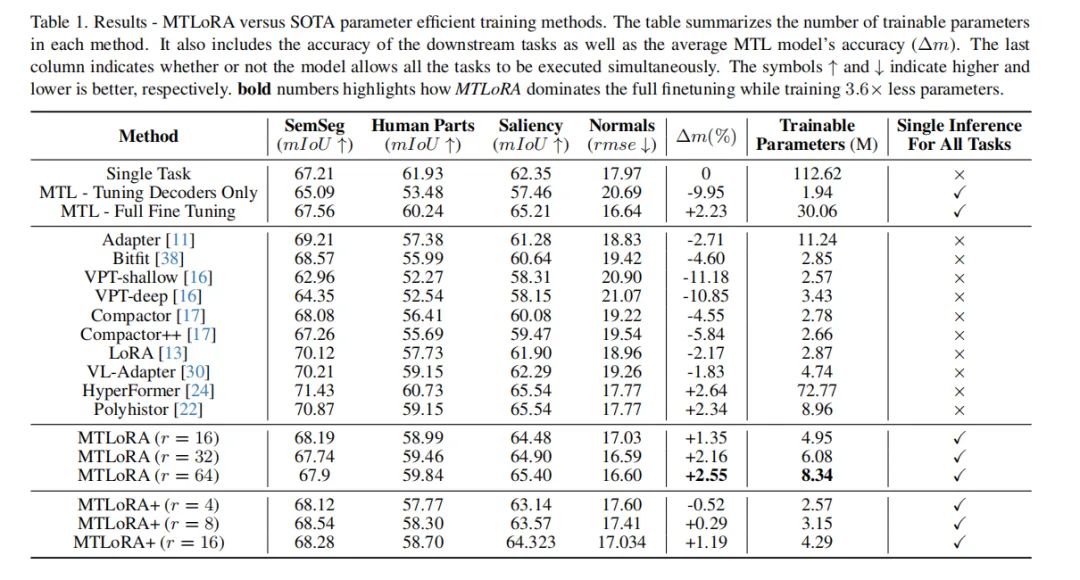
MTLoRA在多任务学习(MTL)模型的参数高效微调方面取得了显著的成就。与全参数微调相比,MTLoRA在保持或提高下游任务准确性的同时,显著减少了可训练参数的数量。实验结果显示,MTLoRA在PASCAL数据集上的多个下游密集预测任务中,相比于完全微调整个MTL模型,不仅提高了准确率,而且减少了3.6倍的可训练参数。此外,MTLoRA在参数数量和下游任务准确性之间建立了帕累托最优的权衡,超越了当前最先进的参数高效训练方法。
2. 与其他参数高效训练方法的对比
MTLoRA与其他单任务参数高效训练方法相比较,在多任务学习环境中展示了更高的准确性和效率。通过与Adapter、Bitfit、VPT-shallow、VPT-deep、Compactor、Compactor++、LoRA、VL-Adapter、HyperFormer和Polyhistor等方法的对比,MTLoRA在多任务执行中表现出更好的性能。特别是,MTLoRA能够在单次推理路径中同时执行所有任务,这对于需要效率和低延迟的应用至关重要。
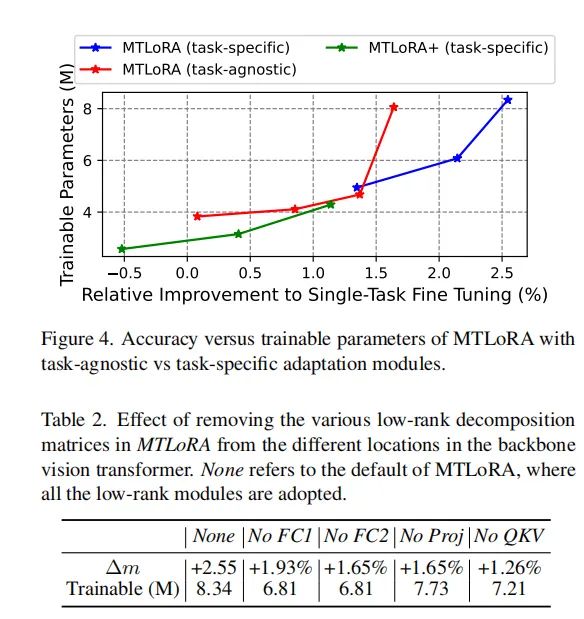

深入分析:MTLoRA的关键因素
1. 任务特定模块的影响
MTLoRA通过引入任务特定的低秩分解模块(TS-LoRA)和任务无关的低秩分解模块(TA-LoRA),有效地解决了MTL微调中的参数空间问题。任务特定模块的加入显著提高了参数高效微调过程中的准确性和效率。实验结果表明,与仅使用任务无关低秩分解模块相比,添加任务特定适应模块可以显著提升模型在多任务学习中的性能。
2. 不同适应位置的效果
在MTLoRA中,低秩分解模块被应用于多个位置,包括MLP块中的前馈层、QKV层和投影层。实验分析表明,调整QKV层的权重是最重要的,因为移除其低秩模块会导致最大的准确率下降。而移除MLP块第一线性层的适应性似乎相对较不重要。然而,每个低秩分解模块都能显著提高多个下游任务的整体性能,移除其中一些模块可以在训练过程中实现不同的准确性效率权衡。
3. 不同解码器的通用性测试
MTLoRA在应用于不同解码器时表现出良好的泛化能力。通过使用HRNet、SegFormer和ASPP等常用解码器进行测试,MTLoRA证明了其在不同解码器上的有效性。不同的解码器可以提供不同的准确性效率权衡,这为根据应用需求和可用资源调整训练预算提供了灵活性。
扩展研究:不同任务数量下的MTLoRA性能
在多任务学习(MTL)的背景下,MTLoRA作为一种新颖的参数高效微调框架,其性能随着任务数量的变化而变化是一个值得探讨的问题。以下是对不同任务数量下MTLoRA性能的分析。
1. 任务数量与模型效率的关系
MTLoRA框架通过在多任务学习模型中引入任务无关(Task-Agnostic)和任务特定(Task-Specific)的低秩适应(Low-Rank Adaptation)模块,实现了参数高效的微调。这些模块允许模型在保持参数数量较少的同时,有效地处理多个下游任务。然而,随着任务数量的增加,模型需要处理更多的任务特定信息,这可能会影响模型的效率。例如,表7显示了随着任务数量的增加,MTLoRA在保持较高准确性的同时,引入的额外参数数量较少,这表明MTLoRA能够有效地扩展到更多的任务而不会显著增加计算负担。
2. 不同任务数量下的准确性-效率权衡
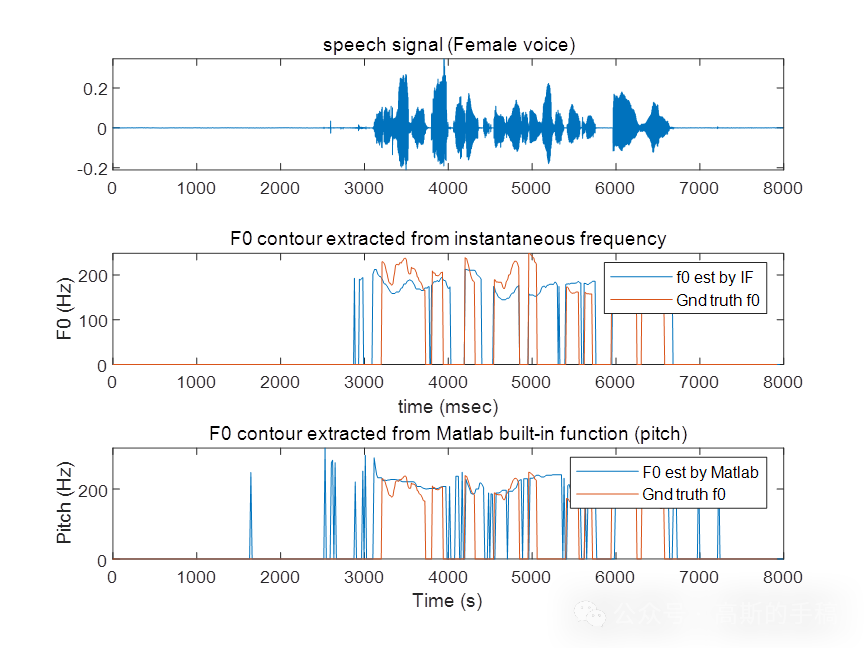
MTLoRA在不同任务数量下的准确性和效率之间建立了一个帕累托最优的权衡。如图1所示,MTLoRA在减少可训练参数数量的同时,实现了比完全微调MTL模型更高的准确性。此外,表6分析了不同任务数量下的浮点运算(FLOPs)开销,结果表明,与传统的单任务特定适应方法相比,MTLoRA在任务数量增加时的效率更高。这一点在多任务实时应用中尤为重要,因为它避免了传统方法中的分散执行路径,并且可以像SWIN的窗口计算一样进行批处理以提高效率。
结论与展望:MTLoRA在多任务学习中的应用前景
MTLoRA作为一种新颖的参数高效微调框架,已经在多任务学习(MTL)中展现出了显著的性能。通过引入任务无关和任务特定的低秩适应模块,MTLoRA不仅在参数数量上实现了显著减少(达到3.6倍降低),而且在多个下游密集预测任务中取得了比完全微调MTL模型更高的准确性。MTLoRA在准确性和可训练参数数量之间提供了帕累托最优的权衡,超越了现有的最先进的参数高效训练方法。
展望未来,MTLoRA的应用前景广阔。随着任务数量的增加,MTLoRA能够有效地扩展,而不会显著增加计算负担,这使得它适用于需要同时处理多个任务的实时应用。此外,MTLoRA的通用性使其能够与不同的解码器和变换器骨干网络一起使用,为不同的应用需求和可用资源提供灵活性。随着对参数高效微调方法需求的增加,MTLoRA及其未来的改进有望在多任务学习领域发挥重要作用。
额外的实验结果与分析
1. 实验结果的补充分析
在我们的研究中,我们引入了MTLoRA——一种新颖的多任务学习(MTL)模型的参数高效训练框架。MTLoRA通过任务无关(Task-Agnostic)和任务特定(Task-Specific)的低秩适应(Low-Rank Adaptation)模块,有效地解耦了MTL微调中的参数空间。这些模块使得模型能够在保持任务专业化和MTL环境中的交互的同时,实现参数高效的训练。
我们在PASCAL数据集上进行了广泛的实验,结果表明MTLoRA在减少可训练参数数量(降低了3.6倍)的同时,实现了比完全微调MTL模型更高的下游任务准确率。此外,MTLoRA在可训练参数数量和下游任务准确率之间建立了帕累托最优的权衡,超越了当前最先进的参数高效训练方法。
2. 任务特定模块的影响
为了展示任务特定低秩分解模块在MTLoRA中的有效性,我们比较了仅使用任务无关低秩分解模块的类似设置与MTLoRA和MTLoRA+的性能。结果清楚地表明,添加任务特定适应模块在参数高效微调中显著提高了准确率效率权衡。这表明任务特定模块能够有效地解开MTL中涉及的参数空间,从而在微调过程中促进了积极的知识共享,显著提升了每个下游任务的性能。
3. 不同位置的低秩分解模块的影响
我们在层次化Transformer编码器的四个不同位置插入了低秩分解模块:MLP块中的前馈层(FC1和FC2)、QKV层和投影层。我们分析了从这些层中移除低秩分解模块的影响,以了解适应这些权重的有效性。结果表明,适应QKV权重是最重要的,因为移除其低秩模块会导致最大的准确率下降。然而,从MLP块的第一线性层中移除适应似乎相对效果最小。然而,每个低秩分解模块都在提高多个下游任务的整体性能方面提供了显著的改进。移除其中一些可以在训练期间实现不同的准确率效率权衡。
4. 冻结非注意力模块的影响
除了微调低秩分解矩阵外,我们还解冻了补丁嵌入层、补丁合并层、层归一化和注意力层中的位置偏差。我们分析了冻结这些额外模块的影响,以提供与每个组件相关的准确率效率权衡的见解。结果表明,解冻所有这些模块可以获得最高的准确率。