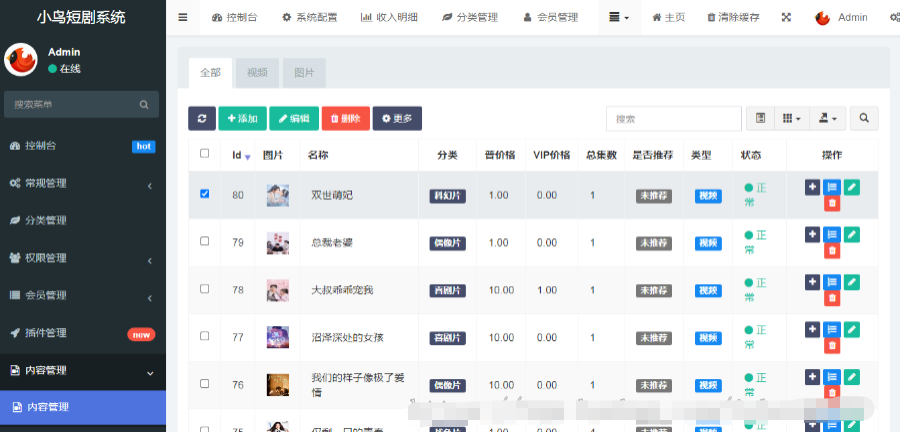
Gamba: Marry Gaussian Splatting with Mamba for Single-View 3D Reconstruction
Gamba:将高斯溅射与Mamba结合用于单视图3D重建
沈秋红 1 易轩宇 3 吴子可 3 潘周 2,4 2 张汉旺 3,5Shuicheng Yan5 Xinchao Wang12
严水成 5 王新潮 1 2
1National University of Singapore 2Singapore Management University
1 新加坡国立大学 2 新加坡管理大学
3Nanyang Technological University 4Sea AI Lab 5Skywork AI
3 南洋理工大学 4 Sea AI Lab 5 Skywork AI
Abstract 摘要 Gamba: Marry Gaussian Splatting with Mamba for Single-View 3D Reconstruction
We tackle the challenge of efficiently reconstructing a 3D asset from a single image with growing demands for automated 3D content creation pipelines. Previous methods primarily rely on Score Distillation Sampling (SDS) and Neural Radiance Fields (NeRF). Despite their significant success, these approaches encounter practical limitations due to lengthy optimization and considerable memory usage. In this report, we introduce Gamba, an end-to-end amortized 3D reconstruction model from single-view images, emphasizing two main insights: (1) 3D representation: leveraging a large number of 3D Gaussians for an efficient 3D Gaussian splatting process; (2) Backbone design: introducing a Mamba-based sequential network that facilitates context-dependent reasoning and linear scalability with the sequence (token) length, accommodating a substantial number of Gaussians. Gamba incorporates significant advancements in data preprocessing, regularization design, and training methodologies. We assessed Gamba against existing optimization-based and feed-forward 3D generation approaches using the real-world scanned OmniObject3D dataset. Here, Gamba demonstrates competitive generation capabilities, both qualitatively and quantitatively, while achieving remarkable speed, approximately 0.6 second on a single NVIDIA A100 GPU.
随着对自动化3D内容创建管道的需求不断增长,我们应对了从单个图像有效重建3D资产的挑战。以前的方法主要依赖于分数蒸馏采样(SDS)和神经辐射场(NeRF)。尽管这些方法取得了显著的成功,但由于冗长的优化和相当大的内存使用,这些方法遇到了实际的限制。在这份报告中,我们介绍了Gamba,一种基于单视图图像的端到端摊销3D重建模型,强调了两个主要观点:(1)3D表示:利用大量3D高斯进行高效的3D高斯溅射过程;(2)主干设计:引入了基于Mamba的顺序网络,该网络有助于上下文相关的推理和序列(令牌)长度的线性可扩展性,容纳了大量的高斯人Gamba在数据预处理、正则化设计和训练方法方面取得了重大进展。 我们评估了Gamba对现有的基于优化和前馈的3D生成方法,使用真实世界的扫描OmniObject 3D数据集。在这里,Gamba展示了具有竞争力的生成能力,无论是质量还是数量,同时在单个NVIDIA A100 GPU上实现了约0.6秒的卓越速度。
3Work in progress, partially done in Sea AI Lab and 2050 Research, Skywork AI
正在进行的工作,部分在Sea AI Lab和2050 Research,Skywork AI完成
1Introduction 一、导言
We tackle the challenge of efficiently extracting a 3D asset from a single image, an endeavor with substantial implications across diverse industrial sectors. This endeavor facilitates AR/VR content generation from a single snapshot and aids in the development of autonomous vehicle path planning through monocular perception Sun et al. (2023); Gul et al. (2019); Yi et al. (2023).
我们解决了从单个图像中有效提取3D资产的挑战,这是一项对不同工业部门具有重大影响的奋进。这一奋进有助于从单个快照生成AR/VR内容,并有助于通过单目感知开发自动驾驶车辆路径规划Sun et al.(2023); Gul et al.(2019); Yi et al.(2023)。
Previous approaches to single-view 3D reconstruction have mainly been achieved through Score Distillation Sampling (SDS) Poole et al. (2022), which leverages pre-trained 2D diffusion models Graikos et al. (2022); Rombach et al. (2022) to guide optimization of the underlying representations of 3D assets. These optimization-based approaches have achieved remarkable success, known for their high-fidelity and generalizability. However, they require a time-consuming per-instance optimization process Tang (2022); Wang et al. (2023d); Wu et al. (2024) to generate a single object and also suffer from artifacts such as the “multi-face” problem arising from bias in pre-trained 2D diffusion models Hong et al. (2023a). On the other hand, previous approaches predominantly utilized neural radiance fields (NeRF) Mildenhall et al. (2021); Barron et al. (2021), which are equipped with high-dimensional multi-layer perception (MLP) and inefficient volume rendering Mildenhall et al. (2021). This computational complexity significantly limits practical applications on limited compute budgets. For instance, the Large reconstruction Model (LRM) Hong et al. (2023b) is confined to a resolution of 32 using a triplane-NeRF Shue et al. (2023) representation, and the resolution of renderings is limited to 128 due to the bottleneck of online volume rendering.
以前的单视图3D重建方法主要是通过分数蒸馏采样(SDS)Poole et al.(2022)实现的,该方法利用预先训练的2D扩散模型Graikos et al.(2022); Rombach et al.(2022)来指导3D资产底层表示的优化。这些基于优化的方法已经取得了显著的成功,以其高保真度和通用性而闻名。然而,它们需要耗时的每个实例优化过程Tang(2022); Wang等人(2023 d); Wu等人(2024)来生成单个对象,并且还遭受伪影,例如由预训练的2D扩散模型中的偏差引起的“多面”问题Hong等人(2023 a)。另一方面,以前的方法主要利用神经辐射场(NeRF)Mildenhall et al.(2021);巴伦et al.(2021),其配备了高维多层感知(MLP)和低效的体绘制Mildenhall et al.(2021)。 这种计算复杂性极大地限制了有限计算预算的实际应用。例如,大型重建模型(LRM)Hong等人(2023 b)使用三平面NeRF Shue等人(2023)表示被限制为32的分辨率,并且由于在线体绘制的瓶颈,渲染的分辨率被限制为128。
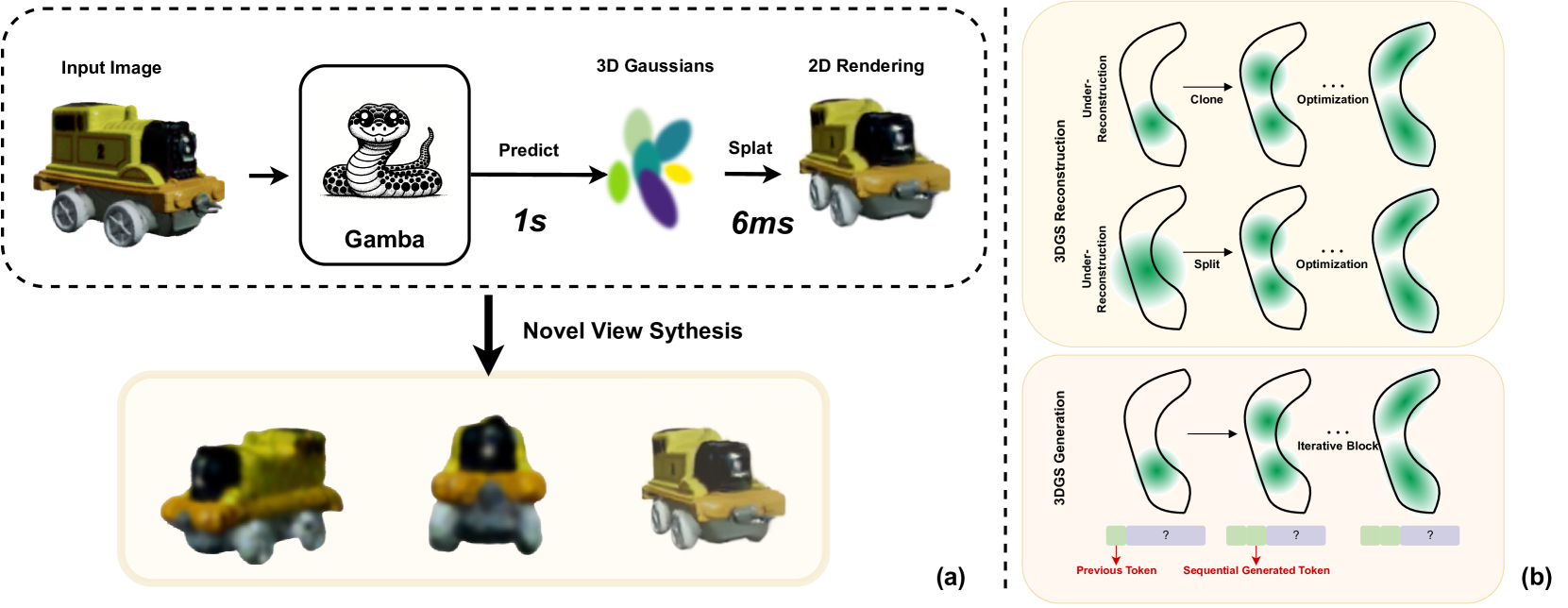
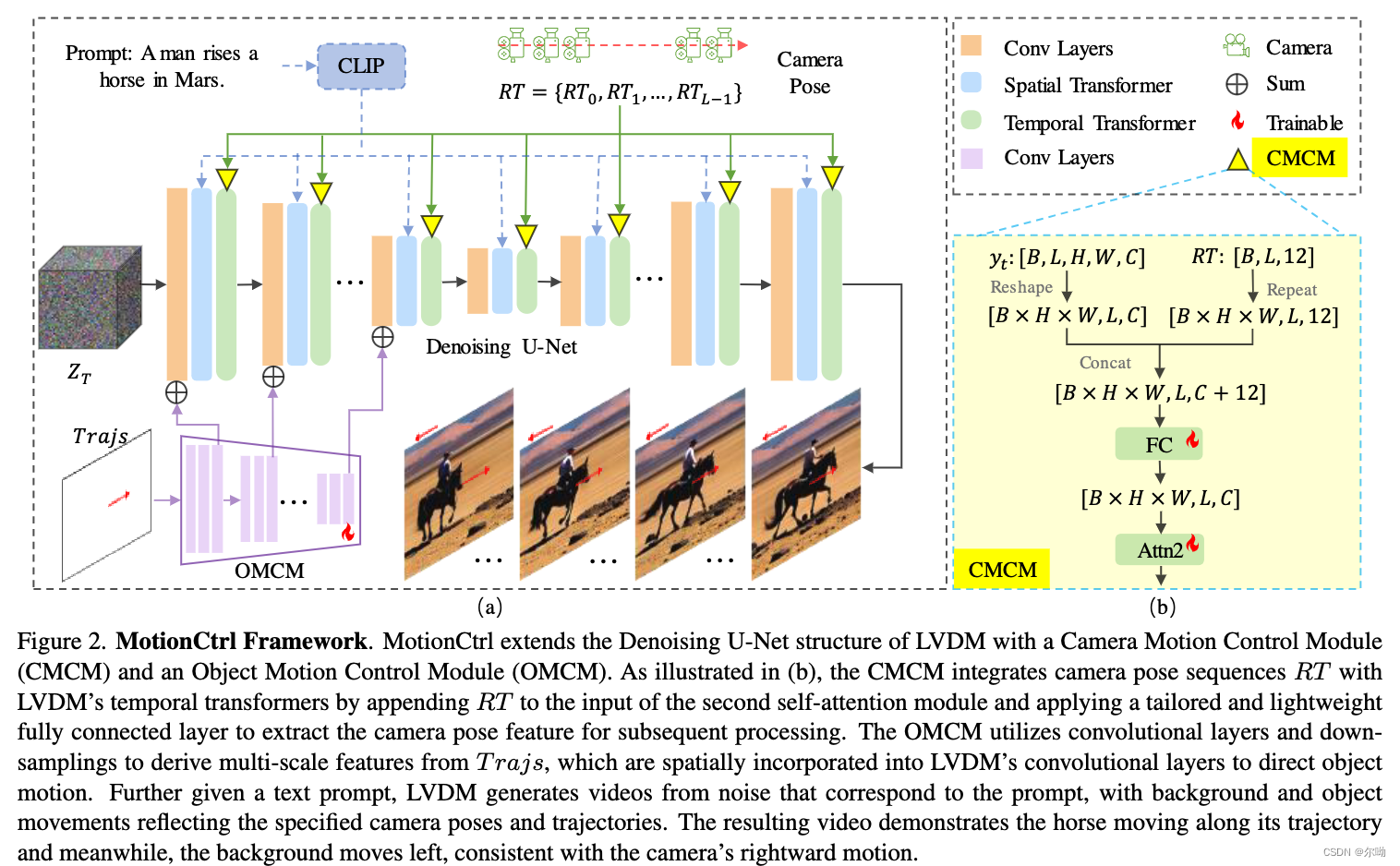
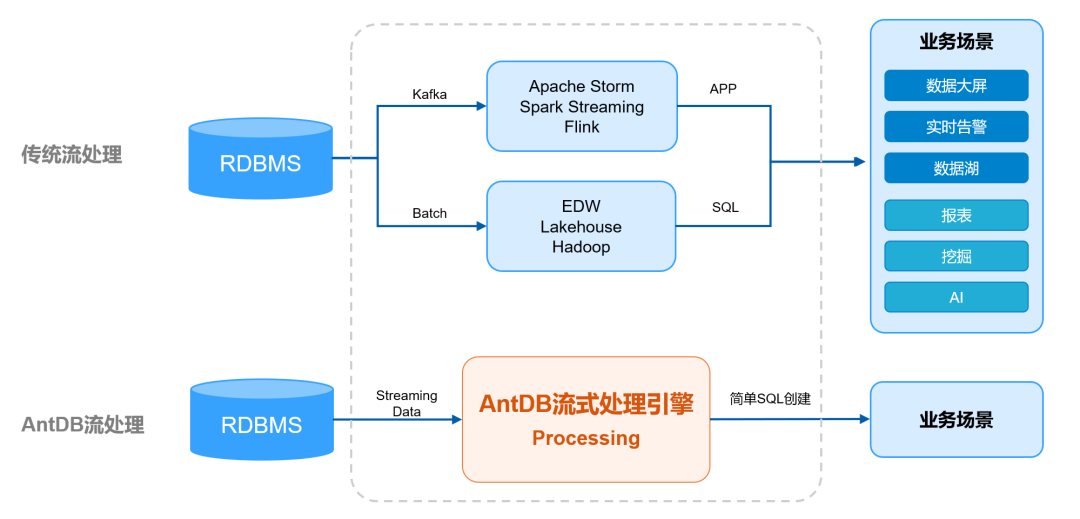
Figure 1:(a): We propose Gamba, an end-to-end, feed-forward single-view reconstruction pipeline, which marries 3D Gaussian Splatting with Mamba to achieve fast reconstruction. (b): The relationship between the 3DGS generation process and the Mamba sequential predicting pattern.
图1:(a):我们提出了Gamba,一个端到端的前馈单视图重建管道,它将3D高斯溅射与Mamba结合在一起,以实现快速重建。(b)3DGS生成过程与Mamba序列预测模式之间的关系。
To address these challenges and thus achieve efficient single-view 3D reconstruction, we are seeking an amortized generative framework with the groundbreaking 3D Gaussian Splatting, notable for its memory-efficient and high-fidelity tiled rendering Kerbl et al. (2023); Zwicker et al. (2002); Chen & Wang (2024); Wang et al. (2024). Despite recent exciting progress Tang et al. (2023), how to properly and immediately generate 3D Gaussians remains a less studied topic. Recent prevalent 3D amortized generative models Hong et al. (2023b); Wang et al. (2023b); Xu et al. (2024; 2023); Zou et al. (2023); Li et al. (2023) predominantly use transformer-based architecture as their backbones Vaswani et al. (2017); Peebles & Xie (2023), but we argue that these widely used architectures are sub-optimal for generating 3DGS. The crucial challenge stems from the fact that 3DGS requires a sufficient number of 3D Gaussians to accurately represent a 3D model or scene. However, the spatio-temporal complexity of Transformers increases quadratic-ally with the number of tokens Vaswani et al. (2017), which limits the expressiveness of the 3DGS due to the insufficient token counts for 3D Gaussians. Furthermore, the 3DGS parameters possess specific physical meanings, making the simultaneous generation of 3DGS parameters a more challenging task.
为了解决这些挑战,从而实现有效的单视图3D重建,我们正在寻求一个具有开创性的3D高斯溅射的摊销生成框架,以其高效的内存和高保真度平铺渲染而闻名Kerbl et al.(2023); Zwicker et al.(2002); Chen & Wang(2024); Wang et al.(2024)。尽管最近取得了令人兴奋的进展,但如何正确和立即生成3D高斯仍然是一个研究较少的话题。最近流行的3D摊销生成模型Hong et al.(2023 b); Wang et al.(2023 b); Xu et al.(2024; 2023); Zou et al.(2023); Li et al.(2023)主要使用基于transformer的架构作为其主干Vaswani et al.(2017);皮布尔斯和谢(2023),但我们认为,这些广泛使用的架构是次优的生成3DGS。关键的挑战来自于这样一个事实,即3DGS需要足够数量的3D高斯来准确地表示3D模型或场景。 然而,变形金刚的时空复杂度随着令牌数量的二次方增加Vaswani et al.(2017),由于3D高斯的令牌数量不足,这限制了3DGS的表现力。此外,3DGS参数具有特定的物理意义,使得同时生成3DGS参数成为更具挑战性的任务。
To tackle the above challenges, we start by revisiting the 3DGS reconstruction process from multi-view images. The analysis presented in fig 1(b) reveals that 3DGS densification during the reconstruction process can be conceptualized as a sequential generation based on previously generated tokens. With this insight, we introduce a novel architecture for end-to-end 3DGS generation dubbed Gaussian Mamba (Gamba), which is built upon a new scalable sequential network, Mamba Gu & Dao (2023a). Our Gamba enables context-dependent reasoning and scales linearly with sequence (token) length, allowing it to efficiently mimic the inherent process of 3DGS reconstruction when generating 3D assets enriched with a sufficient number of 3D Gaussians. Due to its feed-forward architecture and efficient rendering, Gamba is exceptionally fast, requiring only about 1 seconds to generate a 3D asset and 6 ms for novel view synthesis, which is 5000× faster than previous optimization-based methods Wu et al. (2024); Weng et al. (2023); Qian et al. (2023) while achieving comparable generation quality.
为了应对上述挑战,我们首先从多视图图像重新审视3DGS重建过程。图1(B)中呈现的分析揭示了重建过程期间的3DGS致密化可以被概念化为基于先前生成的令牌的顺序生成。有了这个见解,我们介绍了一种用于端到端3DGS生成的新架构,称为Gaussian Mamba(Gamba),它建立在一个新的可扩展顺序网络Mamba Gu & Dao(2023a)上。我们的Gamba支持上下文相关的推理,并与序列(令牌)长度呈线性关系,使其能够在生成富含足够数量的3D高斯的3D资产时有效地模拟3DGS重建的固有过程。由于其前馈架构和高效渲染,Gamba速度非常快,仅需约1秒即可生成3D资产,6 ms即可进行新颖的视图合成,比之前基于优化的方法快5000倍。 (2024); Weng等人(2023); Qian等人(2023),同时实现了相当的世代质量。
We demonstrate the superiority of Gamba on the OmniObject3D dataset Wu et al. (2023). Both qualitative and quantitative experiments clearly indicate that Gamba can instantly generate high-quality and diverse 3D assets from a single image, continuously outperforming other state-of-the-art methods. In summary, we make three-fold contributions:
我们证明了Gamba在OmniObject3D数据集Wu et al.(2023)上的优越性。定性和定量实验都清楚地表明,Gamba可以从单个图像立即生成高质量和多样化的3D资产,持续优于其他最先进的方法。总而言之,我们做出了三方面的贡献:
- •
We introduce GambaFormer, a simple state space model to process 3D Gaussian Splatting, which has global receptive fields with linear complexity.
·我们引入了GambaFormer,一个简单的状态空间模型来处理3D高斯溅射,它具有线性复杂度的全局感受野。 - •
Integrated with the GambaFormer, we present Gamba, an amortized, end-to-end 3D Gaussian Splatting Generation pipeline for fast and high-quality single-view reconstruction.
·与GambaFormer集成,我们提出了Gamba,这是一个摊销的端到端3D高斯溅射生成流水线,用于快速和高质量的单视图重建。 - •
Extensive experiments show that Gamba outperforms the state-of-the-art baselines in terms of reconstruction quality and speed.
广泛的实验表明,Gamba在重建质量和速度方面优于最先进的基线。
2Related Works 2相关作品
Amortized 3D Generation. Amortized 3D generation is able to instantly generate 3D assets in a feed-forward manner after training on large-scale 3D datasets Wu et al. (2023); Deitke et al. (2023); Yu et al. (2023), in contrast to tedious SDS-based optimization methods Wu et al. (2024); Lin et al. (2023); Weng et al. (2023); Guo et al. (2023); Tang (2022). Previous works Nichol et al. (2022); Nash et al. (2020) married de-noising diffusion models with various 3D explicit representations (e.g., point cloud and mesh), which suffers from lack of generalizablity and low texture quality. Recently, pioneered by LRM Hong et al. (2023b), several works utilize the capacity and scalability of the transformer Peebles & Xie (2023) and propose a full transformer-based regression model to decode a NeRF representation from triplane features. The following works extend LRM to predict multi-view images Li et al. (2023), combine with diffusion Xu et al. (2023), and pose estimation Wang et al. (2023b). However, their triplane NeRF-based representation is restricted to inefficient volume rendering and relatively low resolution with blurred textures. Gamba instead seeks to train an efficient feed-forward model marrying Gaussian splatting with Mamba for single-view 3D reconstruction.
分期付款的3D生成。分期3D生成能够在大规模3D数据集上训练后以前馈方式立即生成3D资产Wu et al.(2023);Deitke et al.(2023);Yu et al.(2023),与繁琐的基于SDS的优化方法Wu et al.(2024);Lin et al.(2023);Weng et al.(2023)形成对比。Guo等人(2023);Tang(2022)。Nichol等人(2022);Nash等人(2020)将去噪扩散模型与各种3D显式表示(例如,点云和网格),其遭受缺乏概括性和低纹理质量。最近,由LRM Hong等人(2023 b)开创的几项工作利用了Transformer皮布尔斯和Xie(2023)的容量和可扩展性,并提出了一个完整的基于transformer的回归模型来从三平面特征中解码NeRF表示。以下工作扩展LRM以预测多视图图像Li et al.(2023),联合收割机与扩散Xu et al.(2023),以及姿态估计Wang et al. (2023年b)。然而,他们的三平面NeRF为基础的表示是有限的,效率低下的体积渲染和相对较低的分辨率与模糊的纹理。相反,Gamba试图训练一个有效的前馈模型,将高斯溅射与Mamba结合起来,用于单视图3D重建。
Gaussian Splatting for 3D Generation. The explicit nature of 3DGS facilitates real-time rendering capabilities and unprecedented levels of control and editability, making it highly relevant for 3D generation. Several works have effectively utilized 3DGS in conjunction with optimization-based 3D generation Wu et al. (2024); Poole et al. (2022); Lin et al. (2023). For example, DreamGaussian Tang et al. (2023) utilizes 3D Gaussian as an efficient 3D representation that supports real-time high-resolution rendering via rasterization. Despite the acceleration achieved, generating high-fidelity 3D Gaussians using such optimization-based methods still requires several minutes and a large computational memory demand. TriplaneGaussian Zou et al. (2023) extends the LRM architecture with a hybrid triplane-Gaussian representation. AGG Xu et al. (2024) decomposes the geometry and texture generation task to produce coarse 3D Gaussians, further improving its fidelity through Gaussian Super Resolution. Splatter image Szymanowicz et al. (2023) and PixelSplat Charatan et al. (2023) propose to predict 3D Gaussians as pixels on the output feature map of two-view images. LGM Tang et al. (2024) generates high-resolution 3D Gaussians by fusing information from multi-view images generated by existing multi-view diffusion models Shi et al. (2023); Wang & Shi (2023) with an asymmetric U-Net. Among them, our Gamba demonstrates its superiority and structural elegance with single image as input and an end-to-end, single-stage, feed-forward manner.
用于3D生成的高斯溅射。3DGS的显式性质促进了实时渲染能力和前所未有的控制和可编辑性水平,使其与3D生成高度相关。几项工作已经有效地利用了3DGS与基于优化的3D生成Wu et al.(2024); Poole et al.(2022); Lin et al.(2023)。例如,DreamGaussian Tang等人(2023)利用3D高斯作为有效的3D表示,通过光栅化支持实时高分辨率渲染。尽管实现了加速,但使用这种基于优化的方法生成高保真3D高斯仍然需要几分钟和大量的计算内存需求。TriplaneGaussian Zou et al.(2023)使用混合三平面高斯表示扩展了LRM架构。Aug Xu et al. (2024)分解几何和纹理生成任务以产生粗略的3D高斯,通过高斯超分辨率进一步提高其保真度。飞溅图像Szymanowicz等人(2023)和PixelSplat Charatan等人(2023)提出将3D高斯预测为双视图图像的输出特征图上的像素。LGM Tang et al.(2024)通过融合来自现有多视图扩散模型生成的多视图图像的信息来生成高分辨率3D高斯模型Shi et al.(2023); Wang & Shi(2023)使用非对称U网。其中,我们的Gamba展示了其优越性和结构优雅的单一图像作为输入和端到端,单级,前馈的方式。
State Space Models. Utilizing ideas from the control theory Glasser (1985), the integration of linear state space equations with deep learning has been widely employed to tackle the modeling of sequential data. The promising property of linearly scaling with sequence length in long-range dependency modeling has attracted great interest from searchers. Pioneered by LSSL Gu et al. (2021b) and S4 Gu et al. (2021a), which utilize linear state space equations for sequence data modeling, follow-up works mainly focus on memory efficiency Gu et al. (2021a), fast training speed Gu et al. (2022b; a) and better performance Mehta et al. (2022); Wang et al. (2023a). More recently, Mamba Gu & Dao (2023b) integrates a selective mechanism and efficient hardware design, outperforms Transformers Vaswani et al. (2017) on natural language and enjoys linear scaling with input length. Building on the success of Mamba, Vision Mamba Zhu et al. (2024) and VMamba Liu et al. (2024) leverage the bidirectional Vim Block and the Cross-Scan Module respectively to gain data-dependent global visual context for visual representation; U-Mamba Ma et al. (2024) and Vm-unet Ruan & Xiang (2024) further bring Mamba into the field of medical image segmentation. PointMamba Liang et al. (2024a) and Point Cloud Mamba Zhang et al. (2024) adapt Mamba for point cloud understanding through reordering and serialization strategy. In this manuscript, we explore the capabilities of Mamba in single-view 3D reconstruction and introduce Gamba.
状态空间模型利用控制理论Glasser(1985)的思想,线性状态空间方程与深度学习的集成已被广泛用于处理序列数据的建模。在长距离依赖建模中,序列长度的线性缩放特性吸引了研究者的极大兴趣。以LSSL Gu et al.(2021 b)和S4 Gu et al.(2021 a)为先驱,利用线性状态空间方程进行序列数据建模,后续工作主要集中在内存效率Gu et al.(2021 a)、快速训练速度Gu et al.(2022 b; a)和更好的性能Mehta et al.(2022); Wang et al.(2023 a)。最近,Mamba Gu & Dao(2023 b)集成了选择机制和高效的硬件设计,在自然语言方面优于Transformers Vaswani et al.(2017),并享有输入长度的线性缩放。在Mamba成功的基础上,Vision Mamba Zhu et al.(2024)和VMamba Liu et al. (2024)分别利用双向Vim块和交叉扫描模块来获得用于视觉表示的数据依赖的全局视觉上下文; U-Mamba Ma等人(2024)和Vm-unet Ruan & Xiang(2024)进一步将Mamba引入医学图像分割领域。PointMamba Liang等人(2024 a)和Point Cloud Mamba Zhang等人(2024)通过重新排序和序列化策略调整Mamba以用于点云理解。在这篇手稿中,我们探讨了Mamba在单视图3D重建中的功能,并介绍了Gamba。
3Preliminary 3初步
3.13D Gaussian Splatting 3.13D高斯溅射
3D Gaussian Splatting (3DGS) Kerbl et al. (2023) has gained prominence as an efficient explicit 3D representation, using anisotropic 3D Gaussians to achieve intricate modeling. Each Gaussian, denoted as �, is defined by its mean �∈ℝ3, covariance matrix Σ, associated color �∈ℝ3, and opacity �∈ℝ. To be better optimized, the covariance matrix Σ is constructed from a scaling matrix �∈ℝ3 and a rotation matrix �∈ℝ3×3 as follows:
3D高斯溅射(3DGS)Kerbl等人(2023)作为一种有效的显式3D表示方法而获得了突出地位,使用各向异性3D高斯来实现复杂的建模。表示为 � 的每个高斯由其均值 �∈ℝ3 、协方差矩阵 Σ 、相关联的颜色 �∈ℝ3 和不透明度 �∈ℝ 定义。为了更好地优化,协方差矩阵 Σ 由缩放矩阵 �∈ℝ3 和旋转矩阵 �∈ℝ3×3 构造如下:
| Σ=������. | (1) |
This formulation allows for the optimization of Gaussian parameters separately while ensuring that Σ remains positive semi-definite. A Gaussian with mean � is defined as follows:
该公式允许单独优化高斯参数,同时确保 Σ 保持半正定。平均值为 � 的高斯分布定义如下:
| �(�)=exp(−12��Σ−1�), | (2) |
where � represents the offset from � to a given point �. In the blending phase, the color accumulation � is calculated by:
其中 � 表示从 � 到给定点 � 的偏移。在混合阶段中,颜色累积 � 通过下式计算:
| �=∑�∈������(��)∏�=1�−1(1−���(��)). | (3) |
3DGS utilizes a tile-based rasterizer to facilitate real-time rendering and integrates Gaussian parameter optimization with a dynamic density control strategy. This approach allows for the modulation of Gaussian counts through both densification and pruning operations.
3DGS利用基于瓦片的光栅化器来促进实时渲染,并将高斯参数优化与动态密度控制策略相结合。这种方法允许通过致密化和修剪操作来调制高斯计数。
3.2State Space Models 3.2状态空间模型
State Space Models (SSMs) Gu et al. (2021a) have emerged as a powerful tool for modeling and analyzing complex physical systems, particularly those that exhibit linear time-invariant (LTI) behavior. The core idea behind SSMs is to represent a system using a set of first-order differential equations that capture the dynamics of the system’s state variables. This representation allows for a concise and intuitive description of the system’s behavior, making SSMs well-suited for a wide range of applications. The general form of an SSM can be expressed as follows:
状态空间模型(State Space Models,SSM)Gu et al.(2021 a)已经成为建模和分析复杂物理系统的强大工具,特别是那些表现出线性时不变(LTI)行为的系统。SSM背后的核心思想是使用一组一阶微分方程来表示系统,这些微分方程捕获系统状态变量的动态。这种表示允许对系统的行为进行简洁和直观的描述,使SSM非常适合广泛的应用。SSM的一般形式可以表示如下:
| ℎ˙(�) | =�ℎ(�)+��(�), | (4) | ||
| �(�) | =�ℎ(�)+��(�). |
where ℎ(�) denotes the state vector of the system at time �, while ℎ˙(�) denotes its time derivative. The matrices �, �, �, and � encode the relationships between the state vector, the input signal �(�), and the output signal �(�). These matrices play a crucial role in determining the system’s response to various inputs and its overall behavior.
其中 ℎ(�) 表示系统在时间 � 的状态向量,而 ℎ˙(�) 表示其时间导数。矩阵 � 、 � 、 � 和 � 对状态向量、输入信号 �(�) 和输出信号 �(�) 之间的关系进行编码。这些矩阵在确定系统对各种输入的响应及其整体行为方面起着至关重要的作用。
One of the challenges in applying SSMs to real-world problems is that they are designed to operate on continuous-time signals, whereas many practical applications involve discrete-time data. To bridge this gap, it is necessary to discretize the SSM, converting it from a continuous-time representation to a discrete-time one. The discretized form of an SSM can be written as:
将SSM应用于现实世界问题的挑战之一是,它们被设计为对连续时间信号进行操作,而许多实际应用涉及离散时间数据。为了弥合这一差距,有必要离散SSM,将其从连续时间表示转换为离散时间表示。SSM的离散化形式可以写为:
| ℎ� | =�¯ℎ�−1+�¯��, | (5) | ||
| �� | =�¯ℎ�+�¯��. |
Here, � represents the discrete time step, and the matrices �¯, �¯, �¯, and �¯ are the discretized counterparts of their continuous-time equivalents. The discretization process involves sampling the continuous-time input signal �(�) at regular intervals, with a sampling period of Δ. This leads to the following relationships between the continuous-time and discrete-time matrices:
这里, � 表示离散时间步长,并且矩阵 �¯ 、 �¯ 、 �¯ 和 �¯ 是它们的连续时间等价物的离散化对应物。离散化处理涉及以规则间隔对连续时间输入信号 �(�) 进行采样,采样周期为 Δ 。这导致了连续时间矩阵和离散时间矩阵之间的以下关系:
| �¯ | =(�−Δ/2⋅�)−1(�+Δ/2⋅�), | (6) | ||
| �¯ | =(�−Δ/2⋅�)−1Δ�, | |||
| �¯ | =�. |
Selective State Space Models Gu & Dao (2023a) are proposed to address the limitations of traditional SSMs in adapting to varying input sequences and capturing complex, input-dependent dynamics. The key innovation in Selective SSMs is the introduction of a selection mechanism that allows the model to efficiently select data in an input-dependent manner, enabling it to focus on relevant information and ignore irrelevant inputs. The selection mechanism is implemented by parameterizing the SSM matrices �¯, �¯, and Δ based on the input ��. This allows the model to dynamically adjust its behavior depending on the input sequence, effectively filtering out irrelevant information and remembering relevant information indefinitely.
Gu & Dao(2023a)提出了选择性状态空间模型,以解决传统SSM在适应不同输入序列和捕获复杂的输入依赖动态方面的局限性。选择性SSM的关键创新是引入了一种选择机制,允许模型以依赖于输入的方式有效地选择数据,使其能够专注于相关信息并忽略不相关的输入。通过基于输入 �� 参数化SSM矩阵 �¯ 、 �¯ 和 Δ 来实现选择机制。这允许模型根据输入序列动态调整其行为,有效地过滤掉不相关的信息并无限期地记住相关信息。
4Method 4方法
In this section, we detail our proposed single-view 3D reconstruction pipeline with 3D Gaussian Splatting (Fig. 2), called “Gamba”, whose core mechanism is the GambaFormer to predict 3D Gaussian from a single input image (Section 4.2). We design an elaborate Gaussian parameter constrain robust training pipeline (Section 4.3) to ensure stability and high quality.
在本节中,我们详细介绍了我们提出的具有3D高斯溅射的单视图3D重建管道(图2),称为“Gamba”,其核心机制是GambaFormer,用于从单个输入图像预测3D高斯(第4.2节)。我们设计了一个精心设计的高斯参数约束鲁棒训练管道(第4.3节),以确保稳定性和高质量。
4.1Overall Training Pipeline
4.1整体培训管道
Given a set of multi-view images and their corresponding camera pose pairs {𝐱,�} of an object, Gamba first transforms the reference image 𝐱ref and pose �ref into learnable tokens, which are then concatenated with the initial positional embedding to predict a set of 3D Gaussians. Subsequently, the predicted 3D Gaussians are rendered into 2D multi-view images with differentiable renderer Kerbl et al. (2023), which are directly supervised by the provided ground-truth images {𝐱,�} at both reference and novel poses through image-space reconstruction loss.
给定对象的一组多视图图像及其对应的相机姿态对 {𝐱,�} ,Gamba首先将参考图像 𝐱ref 和姿态 �ref 转换为可学习的令牌,然后将其与初始位置嵌入连接以预测一组3D高斯。随后,利用可微分渲染器Kerbl等人(2023)将预测的3D高斯渲染成2D多视图图像,其通过图像空间重构损失在参考和新姿态两者处由所提供的地面实况图像 {𝐱,�} 直接监督。
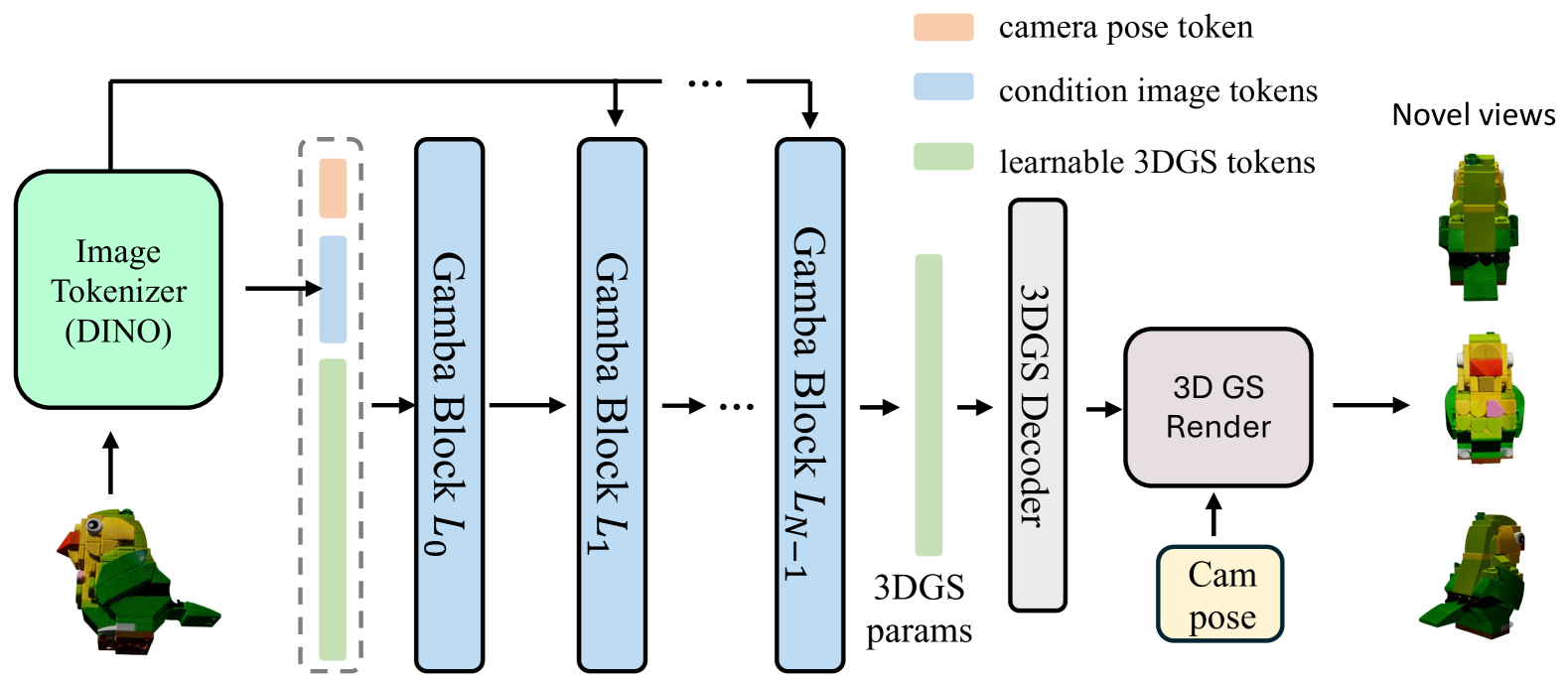
Figure 2:Overall architecture of Gamba.
图2:Gamba的整体架构。
4.2GambaFormer
Image Tokenizer. Parallel to previous work Hong et al. (2023b), the reference RGB image 𝐱∈ℝ�×�×� is tokenized with a visual transformer (ViT) model DINO v2 Oquab et al. (2023), which has demonstrated robust feature extraction capability through self-supervised pre-training, to extract both semantic and spatial representations of a sequence of tokens �∈ℝ�×�, with a length of � and channel dimensions as �.
图像标记器。与之前的工作Hong等人(2023 b)平行,参考RGB图像 𝐱∈ℝ�×�×� 用视觉Transformer(ViT)模型DINO v2 Oquab等人(2023)进行标记化,其已经通过自监督预训练证明了鲁棒的特征提取能力,以提取标记序列 �∈ℝ�×� 的语义和空间表示,长度为 � ,通道尺寸为 � 。
Camera Condition. As the camera poses �ref of the reference images vary across sampled 3D objects in training phase, we need to embed the camera features as a condition for our GambaFormer. We construct the camera matrix with the 12 parameters containing the rotation and translation of the camera extrinsic and 4 parameters [��,��,��,��] denoting the camera intrinsic, which are further transformed into a high-dimensional camera embedding � with a multi-layer perceptron (MLP). Note that Gamba does not depend on any canonical pose, and the ground truth � is only applied as input during training for multi-view supervision.
相机条件。由于在训练阶段,参考图像的相机姿势 �ref 在采样的3D对象中各不相同,因此我们需要将相机特征嵌入作为GambaFormer的条件。我们用12个包含摄像机外部旋转和平移的参数和4个表示摄像机内部的参数 [��,��,��,��] 构建摄像机矩阵,并进一步用多层感知器(MLP)将其转换为高维摄像机嵌入 � 。请注意,Gamba不依赖于任何规范姿势,并且地面实况 � 仅在多视图监督的训练期间作为输入应用。
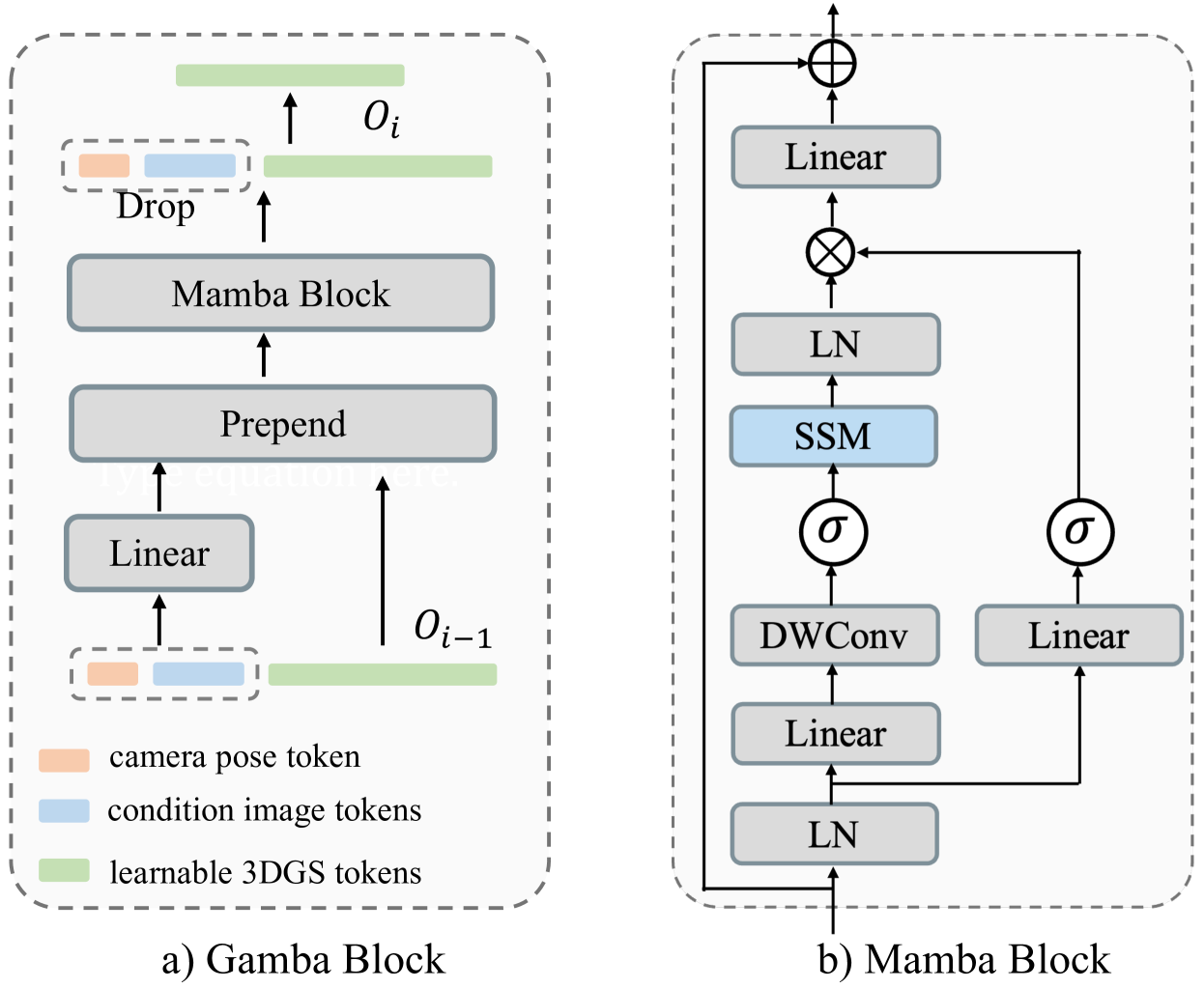
Figure 3:Single Gamba block, where layer normalization (LN), SSM, depth-wise convolution Chollet (2017), and residual connections are employed.
图3:单个Gamba块,其中采用了层归一化(LN),SSM,深度卷积Chollet(2017)和残差连接。
Predicting from 3DGS tokens. In the GambaFormer architecture, as shown in Fig.2, inputs are segmented into three distinct segments: the camera embedding �, reference image tokens �, and a set of learnable 3DGS embeddings �∈ℝ�×�, with � representing the total number of 3DGS tokens, typically set to �=16384, and � is the hidden dimension of each Gamba blocks.
从3DGS令牌预测。在GambaFormer架构中,如图2所示,输入被分割成三个不同的片段:相机嵌入 � ,参考图像标记 � 和一组可学习的3DGS嵌入 �∈ℝ�×� ,其中 � 表示3DGS标记的总数,通常设置为 �=16384 ,而 � 是每个Gamba块的隐藏维度。
Details of the Gamba block are shown in Fig. 3, alongside the original Mamba block architecture. The Mamba block is capable of efficiently processing long sequences of tokens; we note that the current Mamba variants Liu et al. (2024); Zhu et al. (2024); Liang et al. (2024b) do not involve traditional cross-attentions in their methods. Therefore, the use of cross-attention with Mamba remains unexplored. Given the inherent unidirectional scan order of Mamba, we propose using this characteristic to achieve conditional prediction. Specifically, the Gamba block consists of a single Mamba block, two linear projections, and simple prepend operations:
Gamba块的细节如图3所示,与原始的Mamba块架构并排。Mamba块能够有效地处理长序列的令牌;我们注意到当前的Mamba变体Liu et al.(2024);Zhu et al.(2024);Liang et al.(2024 b)在他们的方法中不涉及传统的交叉关注。因此,Mamba的交叉注意力的使用仍然是未知的。鉴于Mamba固有的单向扫描顺序,我们建议使用此特性来实现条件预测。具体来说,Gamba块由一个Mamba块、两个线性投影和简单的prepend操作组成:
| �� | =��(Prepend(���,���),��−1) | (7) | ||
| �� | =Drop(��,Index(���,���)) |
where ��∈ℝ�×16 and ��∈ℝ�×� denote the learnable camera projection and image token projection, respectively. Prepend refers to the operation of prepending projected camera embeddings and image tokens before the hidden 3DGS token features in each Gamba layer. Drop refers to the operation of removing the previously prepended tokens from the output �� of the Mamba block ��, based on their index.
其中 ��∈ℝ�×16 和 ��∈ℝ�×� 分别表示可学习的相机投影和图像标记投影。Prepend是指在每个Gamba层中隐藏的3DGS令牌特征之前预先放置投影相机嵌入和图像令牌的操作。Drop指的是基于它们的索引从Mamba块 �� 的输出 �� 中移除先前预先添加的令牌的操作。
Gaussian Decoder. With stacked Gamba layers, our GambaFormer is capable of retrieving hidden features for each 3DGS token associated with the target object. Subsequently, it predicts the details of 3D Gaussian Splatting parameters using a dedicated Gaussian Decoder. The Gaussian Decoder initially processes the output from the GambaFormer, employing several MLP layers in a feed-forward manner. Then it uses linear layers to separately predict the attributes of each 3D Gaussian ��: the center position ��∈ℝ3, opacity ��∈ℝ, and color ��∈ℝ12, given the adoption of first-order spherical harmonics. The position �� is predicted as a discrete probability distribution and is bound within the range of [−1,1] analogously to previous work in objection detection Duan et al. (2019).
高斯解码器。通过堆叠的Gamba层,我们的GambaFormer能够检索与目标对象相关的每个3DGS令牌的隐藏特征。随后,它使用专用的高斯解码器预测3D高斯溅射参数的细节。高斯解码器最初处理来自GambaFormer的输出,以前馈方式采用几个MLP层。然后,它使用线性层分别预测每个3D高斯 �� 的属性:中心位置 ��∈ℝ3 ,不透明度 ��∈ℝ 和颜色 ��∈ℝ12 ,假定采用一阶球谐函数。位置 �� 被预测为离散概率分布,并被限制在 [−1,1] 的范围内,类似于之前在目标检测中的工作Duan et al.(2019)。
4.3Robust Amortized Training.
4.3稳健的分期付款培训。
Gaussian Parameter Constraint. Parallel to AGG Xu et al. (2024), our amortized framework involves training a generator to concurrently produce 3D Gaussians for a broad array of objects from various categories, diverging from the traditional 3D Gaussian splatting approach where 3D Gaussians are individually optimized for each object. Therefore, we adopt the Gaussian parameter constraint mechanism to fit our feed-forward setting. Specifically, we use a fixed number of 3D Gaussians since the Mamba blocks only support a fixed token length. For the constraint on the predicted positions, our approach leverages a novel 2D Gaussian constraint instead of directly utilizing point clouds from the 3D surface for separating Zou et al. (2023) positions of 3D Gaussian or warm-up Xu et al. (2024), whose point cloud constraint largely limits the scalability of the pre-trained 3D reconstruction model.
高斯参数约束与AGG Xu et al.(2024)类似,我们的摊销框架涉及训练一个生成器,以同时为来自各种类别的大量对象生成3D高斯,这与传统的3D高斯溅射方法不同,其中3D高斯为每个对象单独优化。因此,我们采用高斯参数约束机制来适应我们的前馈设置。具体来说,我们使用固定数量的3D高斯,因为Mamba块只支持固定的令牌长度。对于预测位置的约束,我们的方法利用了一种新的2D高斯约束,而不是直接利用来自3D表面的点云来分离Zou等人(2023)的3D高斯位置或预热Xu等人(2024),其点云约束在很大程度上限制了预训练的3D重建模型的可扩展性。
Our key insight is that, though the given multi-view image sets cannot depict the accurate 3D surface, it can define a rough 3D range of the object. Based on this insight, we devise a more scalable approach for Gauusian position constraint using only multi-view image sets in training. Specifically, as illustrated in Fig. 4, when the projected 2D Gaussian center is outside the object’s contours, we impose an explicit constraint to pull it inside. This constraint is formulated as minimizing the distance between the 2D Gaussian center and the corresponding contour position at the same radial angles. For a fast approximation of each 2D Gaussian’s contour position, object masks are discretized into radial polygons by ray casting, then followed by linear interpolation between continuous angles. By explicitly constraining projected 2D Gaussians with multi-view image sets, the Gaussian Decoder can quickly converge to predict rough 3D shapes.
我们的关键见解是,虽然给定的多视图图像集不能描绘精确的3D表面,但它可以定义对象的粗略3D范围。基于这一见解,我们设计了一个更具可扩展性的方法,高斯位置约束只使用多视图图像集的训练。具体来说,如图4所示,当投影的2D高斯中心在对象轮廓之外时,我们施加显式约束以将其拉入内部。该约束被公式化为最小化2D高斯中心与相同径向角处的对应轮廓位置之间的距离。为了快速近似每个2D高斯的轮廓位置,对象掩模通过射线投射离散成径向多边形,然后在连续角度之间进行线性插值。通过用多视图图像集显式地约束投影的2D高斯,高斯解码器可以快速收敛以预测粗略的3D形状。
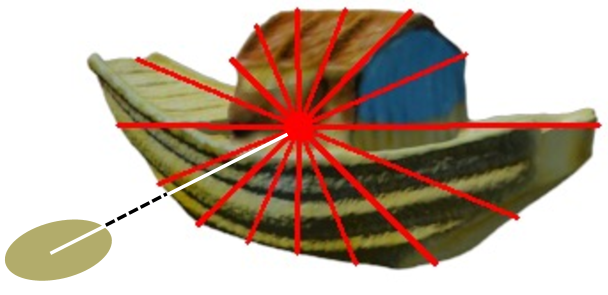
Figure 4:Radial polygon mask. Object masks are divided into polygon masks by 2D ray casting from the image center to the contours.
图4:径向多边形遮罩。通过从图像中心到轮廓的2D射线投射将对象掩模划分为多边形掩模。
Data Augmentation. Gamba primarily emphasizes reconstructing foreground objects, rather than modeling the background. Although our training data consist of single images with pure color backgrounds, we have observed that the 2D renderings during inference often present cluttered backgrounds. To avoid over-fitting this pattern, we implement a random color strategy for background generation. Furthermore, we employ a semantic-aware filter Yi et al. (2022) based on the CLIP similarity metric Radford et al. (2021), to select the canonical pose as the reference view for training stability and faster convergence.
数据扩充。Gamba主要强调重建前景对象,而不是对背景建模。虽然我们的训练数据由具有纯色背景的单个图像组成,但我们观察到,在推理过程中的2D渲染通常呈现混乱的背景。为了避免过度拟合这种模式,我们实现了一个随机颜色策略的背景生成。此外,我们采用基于CLIP相似性度量的语义感知过滤器Yi et al.(2022),拉德福et al.(2021)选择规范姿势作为训练稳定性和更快收敛的参考视图。
Training Objective. Taking advantage of the efficient tiled rasterizer Kerbl et al. (2023) for 3D Gaussians, Gamba is trained in an end-to-end manner with image-space reconstruction loss at both reference and novel views. Our final objective comprises four key terms:
培训目标。利用Kerbl等人(2023)针对3D高斯的高效平铺光栅化器,Gamba以端到端的方式进行训练,在参考视图和新视图处都有图像空间重建损失。我们的最终目标包括四个关键方面:
| ℒ=ℒMSE+�mask ⋅ℒmask +�lpips ⋅ℒlpips +�dist ⋅ℒdist , | (8) |
where ℒrgb is the mean square error (MSE) loss in RGB space; ℒmask and ℒlpips refer to the alpha mask loss and the VGG-based LPIPS loss Zhang et al. (2018), respectively. The last term, �dist, imposes an explicit constraint on the projected 2D Gaussians, also implemented as MSE, which is only adopted during initial training as this term converges exceptionally quickly.
其中 ℒrgb 是RGB空间中的均方误差(MSE)损失; ℒmask 和 ℒlpips 分别指Alpha掩模损失和基于VGG的LPIPS损失Zhang et al.(2018)。最后一项 �dist 对投影的2D高斯施加了显式约束,也被实现为MSE,其仅在初始训练期间被采用,因为该项收敛得非常快。
5Experiments 5实验
5.1Implementation Details
5.1实现细节
Datasets. We used a filtered OmniObject3D Wu et al. (2023) dataset for Gamba pre-training, which contains high-quality scans of real-world 3D objects. Following AGG Xu et al. (2024), we discarded tail categories with fewer than five objects and constructed our training set using 5463 objects from 197 categories in total. The test set is composed of 394 objects, with two left-out objects per category. We used Blender to render the RGB image with its alpha mask from 48 anchor viewpoints at a resolution of 512 × 512 for both training and testing.
数据集。我们使用了经过过滤的OmniObject3D Wu et al.(2023)数据集进行Gamba预训练,其中包含真实世界3D对象的高质量扫描。在AGG Xu等人(2024)之后,我们丢弃了少于5个对象的尾部类别,并使用来自197个类别的5463个对象构建了我们的训练集。测试集由394个对象组成,每个类别有两个遗漏的对象。我们使用Blender从48个锚视点以512 × 512的分辨率渲染RGB图像及其Alpha遮罩,用于训练和测试。
Network Architecture. We leveraged DINO v2 Oquab et al. (2023) as our input image tokenizer, which extracts 768-dimension feature tokens from reference image. The GambaFormer consists of 10 gamba blocks with hidden dimensions 1024, where layer normalization (LN), SSM, depth-wise convolution Shen et al. (2021), and residual connections are employed. The positional embeddings of the GambaFormer consist of 16384 tokens, each with 512 dimensions, corresponding to 16384 3D Gaussians. The Gaussian Decoder is an multi-layer perceptron (MLP) with 10 layers and 64 hidden dimensions, which decodes the output 3D Gaussian of shape (16384, 23) for splatting.
网络架构。我们利用DINO v2 Oquab等人(2023)作为我们的输入图像标记器,它从参考图像中提取768维特征标记。GambaFormer由10个具有隐藏维度1024的gamba块组成,其中采用层归一化(LN),SSM,深度卷积Shen et al.(2021)和残差连接。GambaFormer的位置嵌入由16384个标记组成,每个标记有512个维度,对应于16384个3D高斯。高斯解码器是一个具有10层和64个隐藏维度的多层感知器(MLP),它对输出的形状为(16384,23)的3D高斯进行解码以进行飞溅。
Pre-training. We trained Gamba on 8 NVIDIA A100 (80G) GPUs with batch size 256 for about 3 days. We applied the AdamW optimizer Loshchilov & Hutter (2017) with a learning rate of 1e-4 and a weight decay of 0.05. For each training object, we randomly sample six views among the 48 rendered views to supervise the reconstruction with the input view filtered through CLIP similarity. We set the loss weight �mask =0.01 and �lpips =0.1, respectively. Following Tang et al. (2024), we clip the gradient with a maximum norm of 1.0.
前期训练。我们在8个NVIDIA A100(80 G)GPU上训练了Gamba,批量大小为256,为期约3天。我们应用了AdamW优化器Loshchilov & Hutter(2017),学习率为1 e-4,权重衰减为0.05。对于每个训练对象,我们从48个渲染视图中随机抽取6个视图,以监督重建,并通过CLIP相似性过滤输入视图。我们分别设置损失重量 �mask =0.01 和 �lpips =0.1 。根据Tang等人(2024),我们以最大范数1.0裁剪梯度。
Inference. Gamba is an end-to-end feed-forward pipeline that only takes about 8 GB of GPU memory and less than 1 second on a single NVIDIA A100 (80G) GPU during inference, facilitating online deployment. Note that Gamba takes an arbitrary RGBA image as input with assumed normalized camera pose, and the output is 16384 numbers of 3D Gaussians for further splatting from any given pose.
推理。Gamba是一个端到端的前馈流水线,在推理过程中,在单个NVIDIA A100(80G)GPU上仅占用约8 GB GPU内存,不到1秒,便于在线部署。请注意,Gamba采用任意RGBA图像作为输入,并假设归一化相机姿态,输出是16384个3D高斯,用于从任何给定姿态进一步溅射。