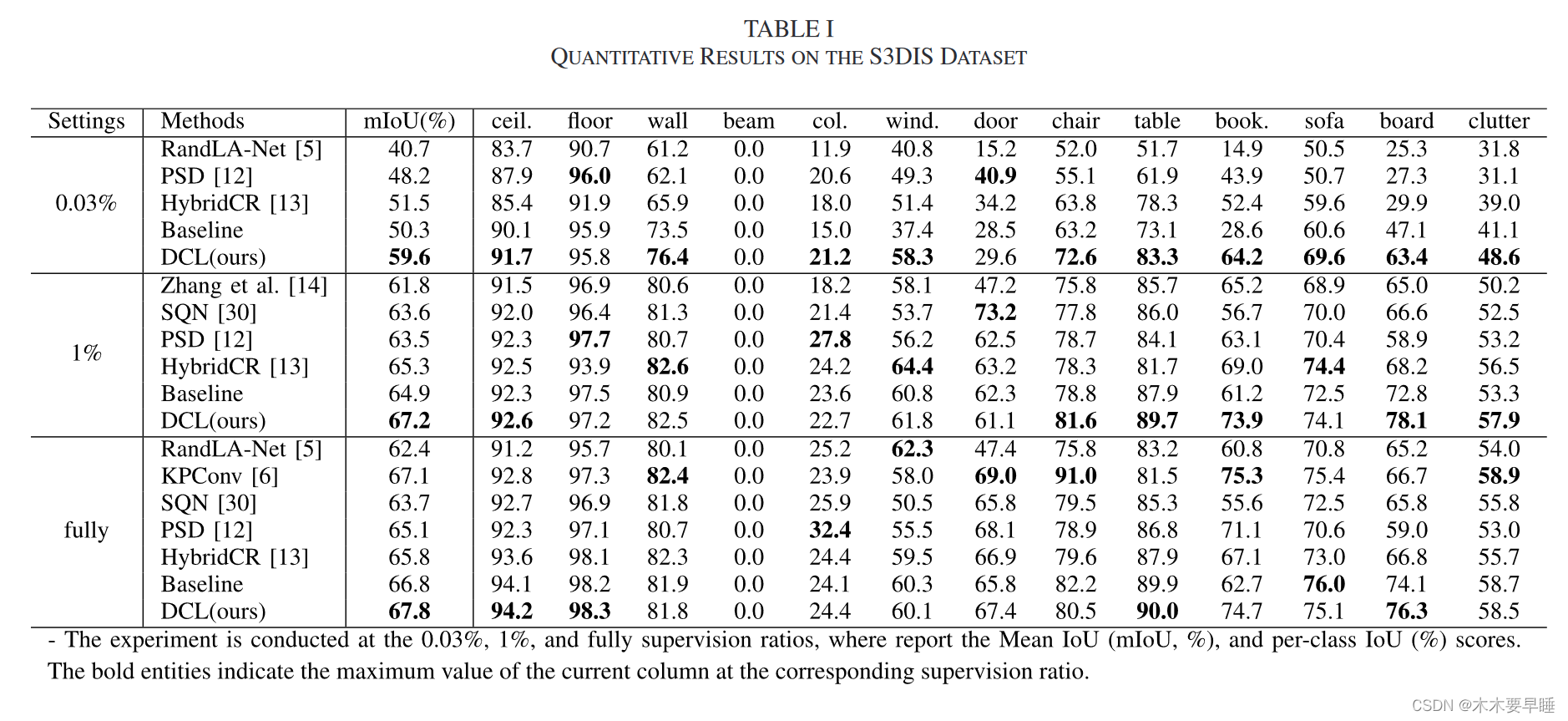
Weakly Supervised Learning for Point Cloud Semantic Segmentation With Dual Teacher
摘要:
为了增强特征学习能力,我们在这项工作中引入了双教师指导的对比学习框架,用于弱监督点云语义分割。双教师框架可以减少子网络耦合,促进特征学习。此外,交叉验证方法可以过滤掉低质量样本,伪标签校正模块可以提高伪标签的质量。经过清理的未标记数据被用于根据每个类别的原型构建对比损失,从而进一步提高分割性能。
介绍:
早期曾有过一些半监督或弱监督点云分割的尝试 [9]、[10]。最近,这类工作通常基于具有对比学习功能的连体网络 [11]、[12]、[13]、[14]、[15]。然而,这些研究存在一些局限性。首先,由于每个连体网络中的子网络具有相同的权重,它们通常依赖于专门的数据扰动来适应不同的场景 [11]、[12]、[13]。这就阻碍了弱监督学习在处理新数据集时的应用。其次,使用复杂的标签传播策略生成伪标签有时会导致错误预测的误差累积[14],[16]。
为了克服这些局限性,我们为弱监督学习框架引入了教师指导方法。如图 1 所示,许多传统的教师指导方法在训练中都会遇到网络耦合问题 [17], [18],而我们则为弱监督点云语义分割构建了一个双教师指导对比学习(Dual-teacher-guided Contrastive Learning,DCL)框架,由两对学生和教师网络组成。同一对中的教师和学生模型通过指数移动平均和一致性正则化进行更新,以便从未标明的数据中学习知识。每个教师模型还交叉指导不同配对中的学生模型,以避免网络耦合和偏差积累。
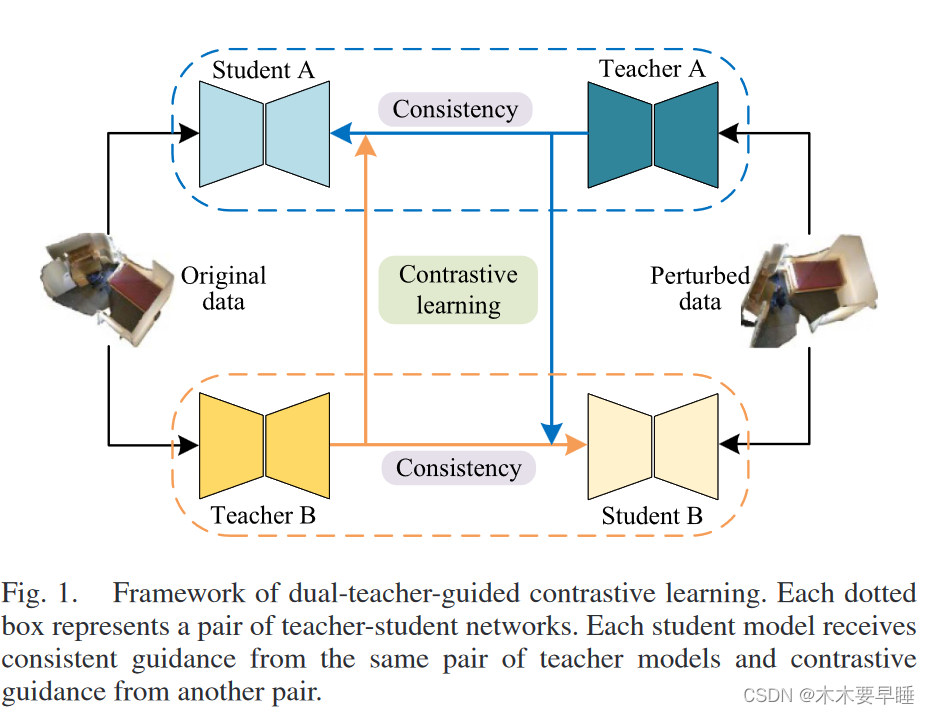
具体来说,我们利用教师模型对未标记数据的预测作为伪标签。为了获得可靠的伪标签,我们整合了双教师模型的预测结果,我们采用交叉验证的方法来过滤低质量的伪标签。此外,在交叉验证结果的基础上,我们构建了每个类别的教师指导原型,并提出了学生模型的伪标签校正模块?。所有弱监督损失都建立在特征级,这可以减少错误伪标签的干扰。对于无标签数据,我们的双教师指导对比学习框架鼓励学生模型从教师模型中转移特征知识。
相关工作:
Point Cloud Semantic Segmentation:
最近,以 PointNet [1] 和 PointNet++ [2] 为先驱,许多基于深度学习的方法被提出用于点云场景理解,特别是分类和分割。PointNet 是一种端到端的多层感知器网络,可以直接处理无序点云,PointNet++ 使用分层分组技术扩展了原有的 PointNet 架构。RandLA-Net [5] 采用随机抽样和局部特征聚合方法,保留了复杂的局部结构,对大规模点云具有很高的效率。RepSurf [19] 提出了一种新颖的特征表示法,利用伞状曲率来描述点云的空间结构。PointNeXt [3] 通过系统分析各个模块,重新审视了经典的 PointNet++。它提出了一种倒置残差瓶颈设计和可分离的 MLP。基于神经辐射场的方法 [20]、[21]、[22] 通过捕捉更精确的几何结构,为三维点云语义分割提供了强大的特定场景隐式表示。有几种方法 [23]、[24]、[25] 应用变换器和自我注意机制来处理点云。虽然这些方法在各种基准数据集上取得了长足的进步,但它们一般都需要完全注释的训练数据,需要付出密集而昂贵的劳动。
Weakly Supervised Learning on Point Cloud
对于弱监督学习来说,关键是从大量未标记数据中学习知识[26],[27]。Xuet 等人[28]提出了一种基于深度学习背景的弱监督方法,在这种方法中,训练只需要极少部分的标记点。Zhang 等人[14]构建了一个自监督预处理任务,通过着色学习先验分布,并提出了一种针对无标签点的稀疏标签传播方法。OTOC [29] 是一种新颖的自训练方法,带有一个图传播模块,用于迭代训练和标签传播。受自我监督学习的启发,PSD[12]采用了一种自我蒸馏框架,旨在实现扰动样本和原始样本之间的预测一致性。考虑到语义相似性,HybridCR [13] 引入了局部和全局引导的对比正则化,以促进点云的特征学习。SQN [30] 是一种语义查询网络,可为弱监督训练提供相关语义特征,它由一个点局部特征提取器和一个灵活的点特征查询网络组成。DAT[11]包含用于在点级和区域级扰动原始点云的自适应变换,旨在加强点云的局部和结构平滑性约束。然而,这些弱监督方法大多基于连体网络?,而连体网络更容易受到数据耦合和误差累积的影响。在这中,我们引入了教师和学生网络,以缓解弱监督点云分割中的这些问题。
Contrastive Learning
对比学习已被证明是一种有效的无监督学习技术。其核心思想是鼓励目标样本更接近同一类别的其他样本,同时远离不同类别的负面样本。PointContrast [31] 将对比学习引入点云场景,并提出了利用未标记点的 PointInfoNCE 损失。它随机选择不匹配的点作为负样本,当大部分节点来自同一类别时,这可能会影响特征学习。Jiang 等人[15]构建了一个记忆库,以确保从不同类别中选择负样本。HybridCR [13] 使用置信度阈值来选择用于计算对比损失的伪标签。
由于所选样本的质量是对比学习的关键,因此在这项工作中,我们提出了一种交叉验证方法来过滤低质量样本,并提出了一个伪标签校正模块来提高对比学习的效果。
模型方法:
为了增强对比学习的效果并缓解耦合问题,我们提出了一种简单而高效的双教师指导对比学习框架,用于弱监督语义分割,如图 2 所示。首先,将原始点云数据和扰动点云数据输入两对师生模型。整个框架由四个主要部分组成:监督分支,教师指导一致性正则化、交叉指导对比性正则化和伪标签校正模块。弱监督部分在特征级构建损失函数,促进学生模型从教师模型中学习高质量的表示方法。
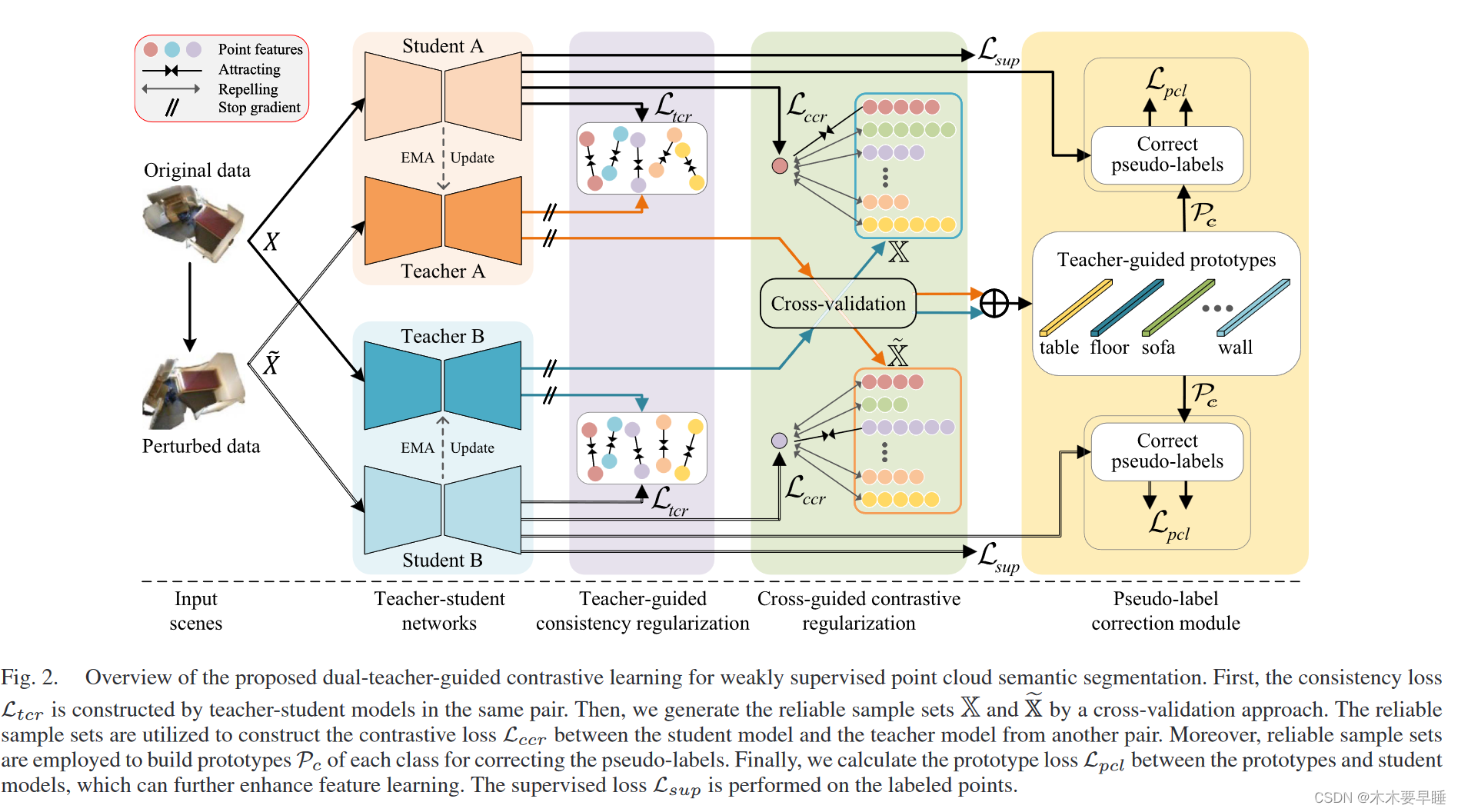
在此框架内,教师模型由历史学生模型的指数移动平均值(EMA)获得,因此可以提供更稳定的预测。教师模型预测的伪标签可以通过反向传播与其他损失函数一起交叉指导不同配对的学生模型。虽然教师模型或学生模型都可以用于推理,但我们在测试过程中习惯使用学生模型进行推理。
定义和术语如下。形式上,我们将 X = {XL,XU } 定义为训练数据集,其中 XL 是标注数据集,XU 是未标注数据集。在弱监督设置中,只有很小一部分训练数据是有标签的。然后,我们还应用一般的数据扰动方法来转换原始数据,扰动后的数据集定义为̃ X,它同样由一个有标签的数据集̃ XL 和一个无标签的数据集̃ XU 组成。
Network Architecture
在弱监督点云语义分割中,给定大量带有极小部分标签的点作为输入,网络训练的目标是学习将输入数据映射到标签的函数。拟议的框架由以下两对师生网络组成:
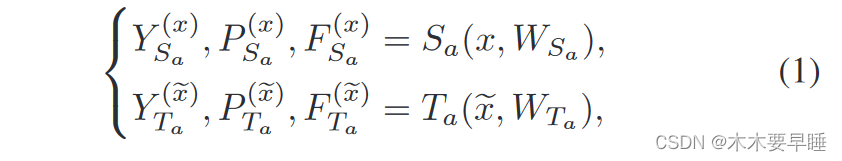
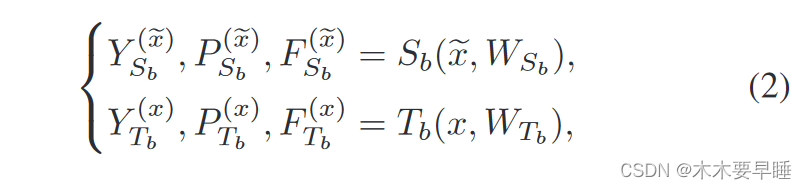
其中,S 和 T 分别代表学生模型和教师模型,下标 a 和 b 表示两对不同的模型。通过相应的权重 W,这些模型可以将输入数据 x 或 ̃ x 映射为输出标签 Y、置信度向量 P 和嵌入特征 F,上标代表相应的输入。变量中的下标表示相应的模型。
Supervised Branch
在弱监督学习中,标注数据通常用于交叉熵损失监督学习。然而,由于分类不平衡,某些类别中的标注数据可能很少,这会导致过度拟合。为了缓解这一难题,我们在监督学习过程中平滑真实标签,以计算交叉熵损失。给定与标注数据点 xl 相对应的one-hot处理格式的真实标签 Y (xl) L,我们对标签进行如下平滑处理:
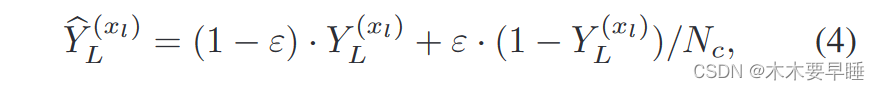
其中,Nc 是类别数,ε 是平滑系数,默认情况下等于 0.2
那么,学生模型 Sa 和 Sb 的监督损失如下:

Teacher-Guided Consistency Regularization
在这一部分,我们将重点关注如何利用大量未标注数据。其基本思想是一致性正则化,即强制模型在各种扰动下产生一致的预测结果。在这项工作中,我们将原始数据和扰动数据输入一对学生模型和教师模型,以鼓励教师模型指导学生模型。教师引导的一致性正则化定义如下:
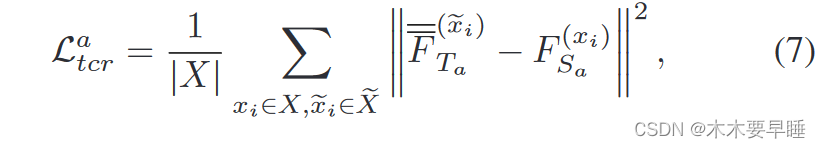
Cross-Guided Contrastive Regularization
如果同一对教师模型和学生模型相互学习,它们很可能会耦合在一起,并在迭代几次后变得相似。为了缓解这些问题,我们设计了一个双教师网络,即每个教师模型指导另一对中的学生。我们还为来自不同配对的学生和教师模型建立了对比正则化。
首先,我们需要确定可靠的样本。如果两个教师模型对一个未标注点的预测结果相同且置信度高,我们就认为该点是可靠的,可以用来指导学生模型。因此,我们采用交叉验证的方法来过滤掉不可靠的点,具体如下。对于学生模型 Sa 和教师模型 Tb,可靠样本集 X 来自:

P (xi) Tb 是教师模型 Tb 在 xi 点的概率输出,φ 是置信度阈值。因此,X 代表教师模型 Tb 输出的可靠样本集,用于指导学生模型 Sa。
其次,以学生模型 Sa 和教师模型 Tb 为样本,构建正负样本的对比正则化。这两种样本的获取方法如下。给定可靠集合 X 中的一个输入点 xi 作为锚点,由 Sa 和 Tb 提取的特征,即 F (xi) Sa 和 F (xi) Tb 形成一对正样本,这对样本在嵌入空间中预计是接近的。此外,负样本预计在嵌入空间中距离较远。我们使用二进制掩码 M(ij) 来识别 xi 和 xj 是否能形成负样本对,如下所示:
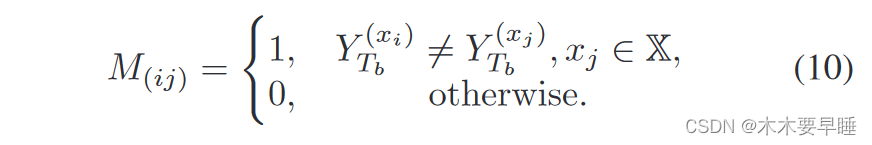
最后,我们提出了一种交叉对比正则化方法,该方法通过不同配对的教师模型来引导每个学生模型,其定义如下:

Pseudo-Label Correction Module
为了进一步提高伪标签的质量,我们提出了一个使用原型的伪标签校正模块,如图 3 所示。
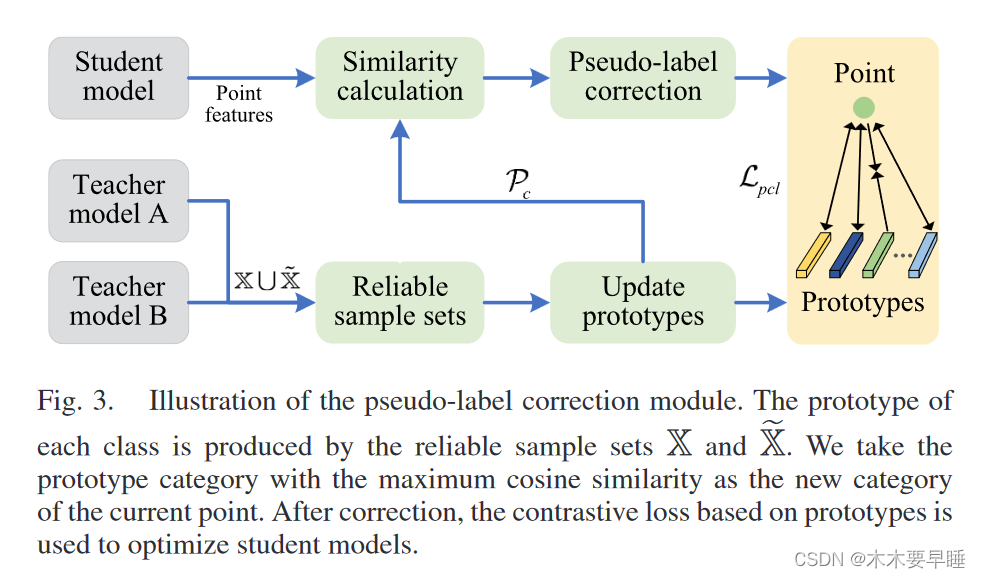
我们使用可靠样本 X 和 ̃ X 生成每个类别的当前原型:

在每一次训练迭代中,原型都会结合上一步的训练和下一步的训练进行更新。
校正后,我们建议在嵌入特征 F (xi) Sa 和相应的原型 Pyi 之间进行对比学习,具体如下:
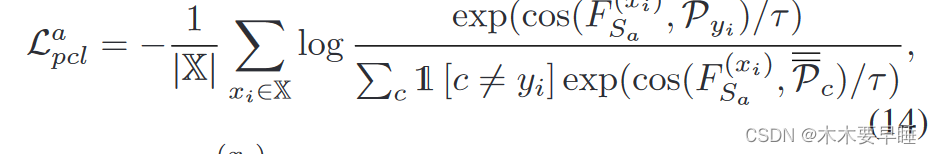
其中,yi = Y (xi) Sa,cos 为余弦相似度,τ 为温度标量。Lpacl 要求同一类别中的点靠近该类别的原型,远离其他类别的原型。Lbpcl 损失与 Lpacl 相似。