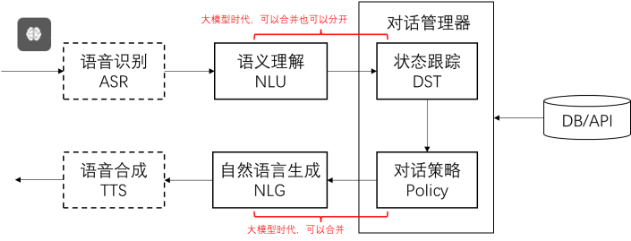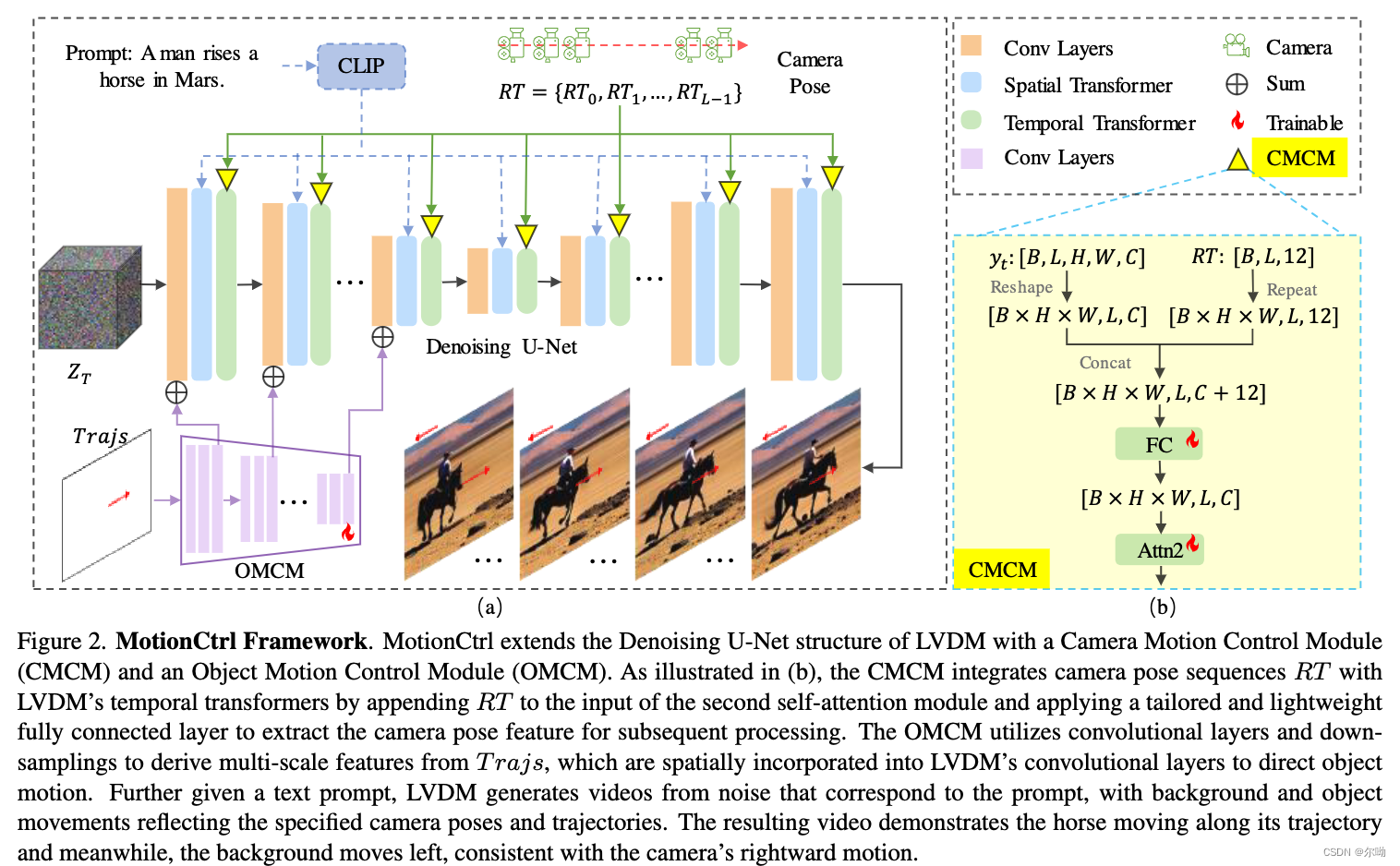
提出一个模型同时考虑到object motion和camra motion,分别对应着OMCM module和CMCM module,因为缺少同时包含text\trajectory\camera pose的数据,所以本文使用的是一个multistep的训练策略
- Camera Motion Control Module (CMCM)
a. 训练的数据:Realestate10K,存在两个问题,一个是没有caption标注,所以使用blip2来标注clip的首帧,1/4,1/2,3/4和尾帧,得到的标注拼接到一起,另一个问题是该数据集的场景比较单一,所以在训练的时候只是训练加入的fc层和temporal attention的第二个self attention层;
b. 交互的层:temporal transformer层
c. camera motion使用 3 ∗ 3 3*3 3∗3的rotation matrix和 3 ∗ 1 3*1 3∗1的translation matrix,对于每一个长度为L的clip可以得到 R T ∈ R L × 12 RT\in \mathbb{R}^{L\times 12} RT∈RL×12,之后扩展到 H × W × L × 12 H\times W \times L \times 12 H×W×L×12,得到的结果和temporal transformer的第一个self attention module的输出拼接,得到的结果经过a fully connected layer到原来的C个通道输入到下一层 - Object Motion Control Module (OMCM)
a. 训练的数据:使用ParticleSfM来生成webvid数据的运动物体trajectory,每个clip选取其中的32帧,得到dense的trajectory之后,在其中随机的选取N条轨迹,此时轨迹比较稀疏,所以还进行了一个gaussian filter操作,在训练的时候,首先使用dense trajectory,然后使用sparse trajectory,在训练的时候只是训练新添加的模块;
b. 交互的层:卷积层
c. 对于一个物体,有一条轨迹 { ( x 0 , y 0 ) , ( x 1 , y 1 ) , . . . , ( x L − 1 , y L − 1 ) } \{(x_0,y_0),(x_1,y_1),...,(x_{L-1},y_{L-1})\} {(x0,y0),(x1,y1),...,(xL−1,yL−1)},转换轨迹为相对位移的表示 { ( 0 , 0 ) , ( u 1 , v 1 ) , . . . , ( u L − 1 , v L − 1 ) } \{(0,0),(u_1,v_1),...,(u_{L-1},v_{L-1})\} {(0,0),(u1,v1),...,(uL−1,vL−1)},使用 u i = x i − x i − 1 , v i = y i − y i − 1 , i > 1 u_i = x_i-x_{i - 1},v_i = y_i-y_{i - 1},i > 1 ui=xi−xi−1,vi=yi−yi−1,i>1其中没有轨迹的位置使用的是(0,0)表示,转换后的轨迹尺寸 R L × H × W × 2 \mathbb{R}^{L\times H\times W\times 2} RL×H×W×2 - 实验
a. 训练:16frame, 256*256,sparse的轨迹数量设为8,bs=128, adam optimizer,lr= 1 × 1 0 − 4 1\times 10^{-4} 1×10−4, 8 × v 100 8\times v100 8×v100, 50000iteration(CMCM)+20000(OMCM dense)+20000(OMCM sparse)
b. 训练的checkpoints来自videocraft1
c. 评测:两种motion的控制使用不同的模块,对于camera motion,有8种基础+20种complicated,对于object motion设定了19种不同的trajectory;
d. 指标分为两种,一个包含FID,FVD和CLIP similarity,在1000个webvid clips上面进行计算,另一种指标来评测camera motion和object motion的cotrol能力,通过计算预测出来的camera pose与object trjectory和GT的欧式距离 - 和sota方法的对比,分别和animatediff的camera control以及videocomposer对比,animatediff使用lora来实现camera control,使用一页图片来展示qualitative的对比效果,还使用一张表格来展示定量的指标对比
- 消融实验:主要验证CMCM和OMCM integrate的位置、训练策略