InFusion: Inpainting 3D Gaussians via Learning Depth Completion from Diffusion Prior
InFusion:通过从扩散先验学习深度完成来修复3D高斯
Abstract 摘要 InFusion: Inpainting 3D Gaussians via Learning Depth Completion from Diffusion Prior
3D Gaussians have recently emerged as an efficient representation for novel view synthesis. This work studies its editability with a particular focus on the inpainting task, which aims to supplement an incomplete set of 3D Gaussians with additional points for visually harmonious rendering. Compared to 2D inpainting, the crux of inpainting 3D Gaussians is to figure out the rendering-relevant properties of the introduced points, whose optimization largely benefits from their initial 3D positions. To this end, we propose to guide the point initialization with an image-conditioned depth completion model, which learns to directly restore the depth map based on the observed image. Such a design allows our model to fill in depth values at an aligned scale with the original depth, and also to harness strong generalizability from large-scale diffusion prior. Thanks to the more accurate depth completion, our approach, dubbed InFusion, surpasses existing alternatives with sufficiently better fidelity and efficiency (i.e., ∼20× faster) under various complex scenarios. We further demonstrate the effectiveness of InFusion with several practical applications, such as inpainting with user-specific texture or with novel object insertion. Our code is public available at Infusion.
3D高斯最近成为一种有效的表示新的视图合成。这项工作研究了它的可编辑性,特别关注修复任务,其目的是用额外的点来补充不完整的3D高斯集,以实现视觉上和谐的渲染。与2D修复相比,3D高斯修复的关键是找出引入点的渲染相关属性,其优化在很大程度上受益于它们的初始3D位置。为此,我们建议使用图像条件深度完成模型来指导点初始化,该模型学习根据观察到的图像直接恢复深度图。这样的设计允许我们的模型以与原始深度对齐的尺度填充深度值,并且还利用大规模扩散先验的强大泛化能力。 由于更准确的深度完成,我们的方法,被称为InFusion,超越了现有的替代品,具有足够好的保真度和效率(即, ∼20× 更快)。我们进一步证明了InFusion在几个实际应用中的有效性,例如使用用户特定纹理或新对象插入进行修复。我们的代码在https://johanan528.github.io/Infusion/上公开。
Keywords:
Gaussian splatting 3D inpainting Monocular depth completion关键词:高斯溅射3D修复单目深度完成
1Introduction 一、导言
Recent developments in 3D representation [4, 96, 65, 45] have highlighted 3D Gaussians [45, 93, 102, 14, 107] as an essential approach for novel view synthesis, owing to the ability to produce photorealistic images with impressive rendering speed. 3D Gaussians offer explicit representation and the capability for real-time processing, which significantly enhances the practicality of editing 3D scenes. The study of how to editing 3D Gaussians is becoming increasingly vital, particularly for interactive downstream applications such as virtual and augmented reality (VR/AR). Our research focuses on the inpainting tasks that are crucial for the seamless integration of edited elements, effectively filling in missing parts and serving as a foundational operation for further manipulations.
3D表示[ 4,96,65,45]的最新发展突出了3D高斯[ 45,93,102,14,107]作为新颖视图合成的基本方法,因为它能够以令人印象深刻的渲染速度生成逼真的图像。3D高斯模型提供了显式表示和实时处理的能力,这大大增强了编辑3D场景的实用性。如何编辑3D高斯模型的研究变得越来越重要,特别是对于交互式下游应用,如虚拟现实和增强现实(VR/AR)。我们的研究重点是修复任务,这些任务对于编辑元素的无缝集成至关重要,有效地填充缺失部分并作为进一步操作的基础操作。
![[Uncaptioned image]](https://img-blog.csdnimg.cn/img_convert/ddc772b87275d33334f4e31417ab51d4.png)
Figure 1:We present InFusion, an innovative approach that delivers efficient, photorealistic inpainting for 3D scenes with 3D Gaussians. As demonstrated in (a), InFusion enables the seamless removal of 3D objects, along with user-friendly texture editing and object insertion. Illustrated in (b), InFusion learns depth completion with diffusion prior, significantly enhancing the depth inpainting quality for general objects. We show the visualizations of the unprojected points, which exhibit substantial improvements over baseline models [92, 44].
图1:我们介绍了InFusion,这是一种创新的方法,可以使用3D高斯为3D场景提供高效的照片级逼真的修复。如(a)所示,InFusion能够无缝移除3D对象,同时沿着用户友好的纹理编辑和对象插入。如(B)所示,InFusion学习具有扩散先验的深度完成,显著增强了一般对象的深度修复质量。我们展示了未投影点的可视化,这些点比基线模型有了实质性的改进[ 92,44]。
Initial explorations into 3D Gaussian inpainting have focused on growing Gaussians from the boundary of the uninpainted regions, using inpainted 2D multiview images for guidance [106, 13, 29]. This method, however, tends to produce blurred textures due to inconsistencies in the generation process, and the growing can be quite slow. Notably, the training quality for Gaussian models is significantly improved when the initial points are precisely positioned within the 3D scene, particularly on object surfaces. A practical solution to improve the fine-tuning of Gaussians is to predetermine these initial points where inpainting will occur, thereby simplifying the overall training process. In allocating initial points for Gaussian inpainting, the role of depth map inpainting can be pivotal. The ability to convert inpainted depth maps into point clouds facilitates a seamless transition to 3D space, while also leveraging the potential to train on expansive datasets [62, 63, 84].
对3D高斯修复的初步探索集中在从未修复区域的边界生长高斯,使用修复的2D多视图图像进行指导[ 106,13,29]。然而,由于生成过程中的不一致性,这种方法往往会产生模糊的纹理,并且生长可能非常缓慢。值得注意的是,当初始点精确定位在3D场景中时,高斯模型的训练质量得到了显着提高,特别是在物体表面上。改进高斯函数微调的一个实际解决方案是预先确定将发生修复的初始点,从而简化整个训练过程。在为高斯修复分配初始点时,深度图修复的作用可能是关键的。将修复后的深度图转换为点云的能力有助于无缝过渡到3D空间,同时还利用了在扩展数据集上训练的潜力[62,63,84]。
To this end, we introduce InFusion, an innovative approach to 3D Gaussian inpainting that leverages depth completion learned from diffusion models [1, 9, 75, 79]. Our method demonstrates that with a robustly learned depth inpainting model, we can accurately determine the placement of initial points, significantly elevating both the fidelity and efficiency of 3D Gaussian inpainting. In particular, we first inpaint the depth in the reference view, then unproject the points into the 3D space to achieve optimal initialization. However, current depth inpainting methodologies [92, 44, 67, 106] are often a limiting factor; commonly, they lack the generality required to accurately complete object depth, or they produce depth maps that misalign with the original, with errors amplified during unprojection. In this work, we harness the power of pre-trained latent diffusion models, training our depth inpainting model with diffusion-based priors to substantially enhance the quality of our inpainting results. The model exhibits a marked improvement in aligning with the unpainted regions and in reconstructing the depth of objects. This enhanced alignment capability ensures a more coherent extension of the existing geometry into the inpainted areas, leading to a seamless integration within the 3D scene. Furthermore, to address challenging scenarios involving large occlusions, we design InFusion with a progressive strategy that showcases its capability to resolve such complex cases.
为此,我们引入了InFusion,这是一种创新的3D高斯修复方法,它利用了从扩散模型中学习的深度完成[ 1,9,75,79]。我们的方法表明,使用鲁棒学习的深度修复模型,我们可以准确地确定初始点的位置,显着提高3D高斯修复的保真度和效率。特别是,我们首先在参考视图中对深度进行修补,然后将点取消投影到3D空间中以实现最佳初始化。然而,当前的深度修复方法[ 92,44,67,106]通常是一个限制因素;通常,它们缺乏准确完成对象深度所需的通用性,或者它们产生的深度图与原始深度图不对齐,在解投影期间误差被放大。 在这项工作中,我们利用预先训练的潜在扩散模型的力量,用基于扩散的先验知识训练我们的深度修复模型,以大幅提高修复结果的质量。该模型在与未着色区域对齐和重建对象深度方面表现出显着的改进。这种增强的对齐功能可确保现有几何图形更连贯地扩展到修复区域,从而实现3D场景内的无缝集成。此外,为了解决涉及大遮挡的具有挑战性的场景,我们设计了一个渐进的策略,展示了它解决这种复杂情况的能力。
Our extensive experiments on various datasets, which include both forward-facing and unbounded 360-degree scenes, demonstrate that our method outperforms the baseline approaches in terms of visual quality and inpainting speed, being 20 times faster. With the effective depth inpainting framework based on a pre-trained LDM, we demonstrate that the integration of 3D Gaussians with depth inpainting offers an efficient and feasible approach to completing 3D scenes. The strength of LDMs [79, 75] is pivotal to our approach, allowing our model to inpaint not just the background but also to complete objects. Beyond the core functionality, our method facilitates additional applications, such as user-interactive texture inpainting, which enhances user engagement by allowing direct input into the inpainting process. We also demonstrate the adaptability of our method for downstream tasks, including scene manipulation and object insertion, revealing the broad potential of our approach in the context of editing and augmenting 3D spaces.
我们在各种数据集上进行了广泛的实验,其中包括面向前方和无界的360度场景,结果表明,我们的方法在视觉质量和修复速度方面优于基线方法,快了20倍。通过基于预训练LDM的有效深度修复框架,我们证明了3D高斯与深度修复的集成提供了一种有效可行的方法来完成3D场景。LDM [79,75]的强度对我们的方法至关重要,使我们的模型不仅可以修复背景,还可以完成对象。除了核心功能之外,我们的方法还促进了其他应用程序,例如用户交互式纹理修复,通过允许直接输入到修复过程中来增强用户参与度。 我们还展示了我们的方法对下游任务的适应性,包括场景操作和对象插入,揭示了我们的方法在编辑和增强3D空间方面的广泛潜力。
2Related Work 2相关工作
2.1Image and Video Inpainting
2.1图像和视频修复
Image and video inpainting is an important editing task [104, 72, 109, 70, 81, 48, 18, 75] that aims to restore the missing regions within an image or video by inferring visually consistent content. Traditional works for image inpainting [5, 2, 94, 27, 3, 23] typically involve extracting low-level features to restore damaged areas. Similarly, in video inpainting [101, 33, 70, 38, 69, 86, 91], the restoration process is often approached as an optimization task based on patch sampling. However, these methods generally lack capacity when handling images with large missing regions or corrupted videos with complex motions. Recently, deep learning has not only empowered inpainting models to overcome these challenges in restoration but has also expanded their capacity to generate new, semantically plausible content [76]. State-of-the-art image inpainting methods [60, 92, 52, 24, 108, 81, 48, 18, 75] excel at effectively handling large mask inpainting tasks on high-resolution images; cutting-edge techniques on video inpainting [118, 51, 117, 104, 31, 112, 111, 53, 56, 5] commonly leverage flow-guided propagation and video Transformers to restore missing parts in videos with natural and spatiotemporally coherent content.
图像和视频修复是一项重要的编辑任务[ 104,72,109,70,81,48,18,75],旨在通过推断视觉上一致的内容来恢复图像或视频中丢失的区域。传统的图像修复工作[5,2,94,27,3,23]通常涉及提取低级特征以恢复受损区域。类似地,在视频修复中[ 101,33,70,38,69,86,91],恢复过程通常被视为基于补丁采样的优化任务。然而,这些方法在处理具有大缺失区域的图像或具有复杂运动的损坏视频时通常缺乏能力。最近,深度学习不仅使修复模型能够克服这些修复挑战,而且还扩展了它们生成新的、语义上合理的内容的能力[ 76]。 最先进的图像修复方法[ 60,92,52,24,108,81,48,18,75]擅长有效地处理高分辨率图像上的大掩模修复任务;视频修复的尖端技术[ 118,51,117,104,31,112,111,53,56,通常利用流引导传播和视频变换器来恢复具有自然和时空相干内容的视频中的丢失部分。
2.23D Scene Inpainting 2.23D场景修复
With the increasing accessibility of 3D reconstruction models, there is a growing demand for 3D scene editing [16, 120, 35, 73, 49, 110, 114]. 3D scene inpainting is one prominent application to fill in the missing parts within a 3D space, such as removing objects from the scene and generating plausible geometry and texture to complete the inpainted regions. Early inpainting works mainly focuses on performing geometry completion [20, 22, 42, 43, 103, 21, 34, 97, 74, 90]. Recent advancements in 3D inpainting techniques have facilitated the simultaneous inpainting of both semantics and geometry by successfully handling the interplay between these two aspects [100]. They can be broadly categorized into two groups based on the adopted 3D representation: NeRF [64] and Gaussian Splatting (GS) [46]. Some NeRF-based methods [68, 49, 47, 58, 87] leverage CLIP [77] or DINO features [10] to learn 3D semantics for inpainting; others [55, 67, 99, 15, 66, 95, 98] typically rely on 2D image inpainting models with depth or segmentation priors to optimize NeRFs through neural fields rendering. In contrast to inpainting on NeRF, several methods [106, 13, 39, 41] explore inpainting techniques on GS models, thanks to their notable advantages such as impressive rendering efficiency and high-quality reconstruction. In our paper, we further improve the efficiency and the quality of 3D inpainting within GS settings.
随着3D重建模型的可访问性越来越高,对3D场景编辑的需求也越来越大[ 16,120,35,73,49,110,114]。3D场景修复是一个突出的应用程序,用于填充3D空间中缺失的部分,例如从场景中删除对象并生成合理的几何形状和纹理以完成修复的区域。早期的修复工作主要集中在执行几何完成[ 20,22,42,43,103,21,34,97,74,90]。3D修复技术的最新进展通过成功处理语义和几何两个方面之间的相互作用,促进了这两个方面的同时修复[ 100]。根据所采用的3D表示,它们可以大致分为两组:NeRF [ 64]和高斯溅射(GS)[ 46]。 一些基于NeRF的方法[ 68,49,47,58,87]利用CLIP [ 77]或DINO特征[ 10]来学习修复的3D语义;其他[ 55,67,99,15,66,95,98]通常依赖于具有深度或分割先验的2D图像修复模型,通过神经场渲染来优化NeRF。与NeRF上的修复相比,几种方法[ 106,13,39,41]探索了GS模型上的修复技术,这要归功于它们的显着优势,例如令人印象深刻的渲染效率和高质量的重建。在我们的论文中,我们进一步提高的效率和质量的3D修复GS设置。
2.3Diffusion Models for Monocular Depth
2.3单目深度的扩散模型
The explicit nature of 3D Gaussians makes the accurate allocation of inpainted points within 3D scenes (e.g., object surfaces) highly beneficial for 3D scene inpainting via optimization. A direct and effective solution is to utilize the 2D depth prior of reference views obtained through monocular depth estimation [28, 32, 119, 54, 78, 8, 105] or completion [57, 113, 59, 85, 6, 30, 115, 61] models to initialize the inpainted 3D points. Thanks to the superior performance of latent diffusion models (LDM) [88, 36, 89, 79, 75, 9, 7, 80], it opens up the possibility of enhancing depth learning by leveraging or distilling the capabilities of these models. Several methods have attempted to employ diffusion priors for estimating monocular depth [44, 40, 26, 83, 82, 116]. However, learning from LDM for monocular depth completion (or inpainting) receives less attention. While some methods [67, 99] employ LaMa [92] to inpaint depth in the Jet color space, the precision of the resulting inpainted depth map is compromised due to the lossy quantization process when converting metric depth to the Jet color space. To the best of our knowledge, our work is the first resolve this problem by training an accurate depth completion model from diffusion prior [75].
3D高斯的显式性质使得3D场景内的修复点的准确分配(例如,对象表面)经由优化对3D场景修复非常有益。一个直接有效的解决方案是利用通过单目深度估计[ 28,32,119,54,78,8,105]或完成[ 57,113,59,85,6,30,115,61]模型获得的参考视图的2D深度先验来初始化修复的3D点。由于潜在扩散模型(LDM)的上级性能[ 88,36,89,79,75,9,7,80],它开辟了通过利用或提取这些模型的能力来增强深度学习的可能性。有几种方法试图采用扩散先验来估计单眼深度[ 44,40,26,83,82,116]。然而,从LDM学习单眼深度完成(或修复)受到的关注较少。 虽然一些方法[67,99]采用LaMa [ 92]在Jet颜色空间中进行深度修补,但由于将度量深度转换为Jet颜色空间时的有损量化过程,因此所得到的修补深度图的精度会受到影响。据我们所知,我们的工作是第一次通过从扩散先验训练精确的深度补全模型来解决这个问题[ 75]。
3Method 3方法
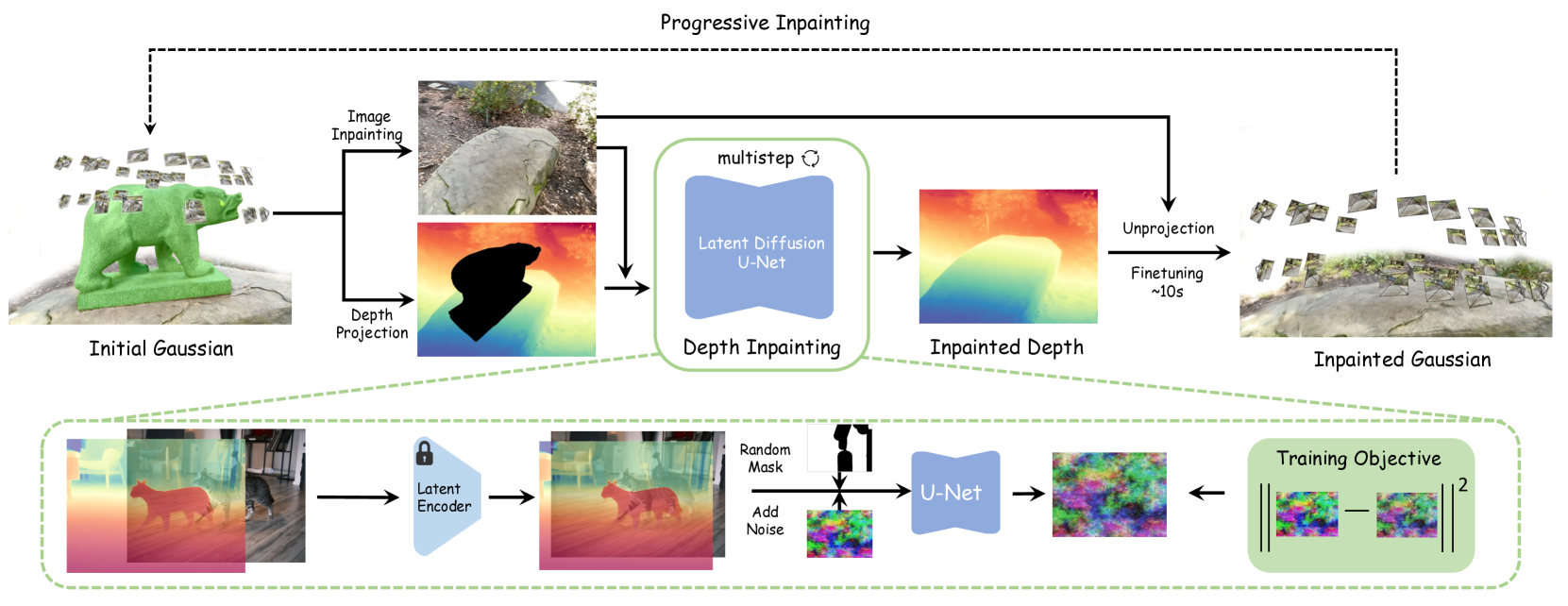
Figure 2:Illustration of Infusion driven by Depth Inpainting. Top: To remove a target from the optimized 3D Gaussians, our InFusion first inpaints a selected one-view RGB image and applies the proposed diffusion model for depth inpainting to the depth projection of the targeted 3D Gaussians. The progressive scheme addresses view-dependent occlusion issues by utilizing other unobstructed viewpoints. Bottom: A detailed view of the training pipeline for the depth inpainting U-Net is presented. We employ a mask-driven denoising diffusion for training of the U-Net, which utilizes a frozen latent tokenizer by taking the RGB image and depth map as inputs.
图2:由深度修复驱动的灌注图示。顶部:为了从优化的3D高斯模型中移除目标,我们的InFusion首先对选定的单视图RGB图像进行修复,并将所提出的深度修复扩散模型应用于目标3D高斯模型的深度投影。渐进式方案通过利用其他无遮挡视点来解决与视点相关的遮挡问题。下图:呈现了深度修复U-Net的训练管道的详细视图。我们采用掩码驱动的去噪扩散来训练U-Net,该U-Net通过将RGB图像和深度图作为输入来利用冻结的潜在标记器。
3.1Overview
Formally, 3D scenes can be represented by 3D Gaussians Θ , given a collection of multi-view images ℐ={��}�=1�, accompanied by respective camera poses Π={��}�=1� [46]. Our objective is to edit the scene Θ with a particular focus on inpainting, which aims to supplement an incomplete set of 3D Gaussians. The complexity of 3D Gaussian inpainting arises due to potential inconsistencies in the supervision provided by the 2D inpainted images from multiview. Nevertheless, three key observations inspire our solution design to address the challenges:
形式上,3D场景可以由3D高斯 Θ 表示,给定多视图图像 ℐ={��}�=1� 的集合,伴随着相应的相机姿势 Π={��}�=1� [ 46]。我们的目标是编辑场景 Θ ,特别关注修复,旨在补充不完整的3D高斯集。3D高斯修复的复杂性是由于来自多视图的2D修复图像提供的监督中的潜在不一致而产生的。然而,三个关键的观察结果启发了我们的解决方案设计来应对挑战:
- •
The reconstruction quality of the optimized 3D Gaussians for novel view synthesis is highly sensitive to the initialization, especially when the view number is limited. Hence, we are motivated to carefully place the initial points within the inpainting regions for enhancing the inpainting quality.
·用于新视图合成的优化的3D高斯的重建质量对初始化高度敏感,特别是当视图数量有限时。因此,我们的动机是仔细放置修复区域内的初始点,以提高修复质量。 - •
Contemporary research indicates that the initialization of 3D Gaussians with unprojected depth maps[19, 71, 12] yields promising results due to explicitness. This observation implies that using inpainted depth images for initializing the missing region could be advantageous.
·当代研究表明,由于显式性,使用未投影深度图[19,71,12]初始化3D高斯会产生有希望的结果。该观察结果意味着使用经修复的深度图像来初始化缺失区域可能是有利的。 - •
Incorporating a diffusion prior [1, 9, 75, 79, 44] into depth estimation markedly improved accuracy especially for general objects. This finding indicates that a similar approach can be adopted to leverage diffusion priors for benefiting depth inpainting.
·将扩散先验[1,9,75,79,44]引入深度估计显着提高了精度,特别是对于一般对象。这一发现表明,可以采用类似的方法来利用扩散先验,以利于深度修复。
Leveraging the key observations discussed earlier, our pipeline is illustrated in Figure 2. Starting with the 3D Gaussians Θ, we first segment out and discard unwanted Gaussians under the guidance of masks ℳ={��}�=1�, which delineate the targeted regions for modification. As mentioned, depth inpainting can play a crucial role in determining the initial placement of Gaussians. To achieve this, we select a reference view and perform inpainting on both the image and its corresponding depth map to facilitate accurate unprojection. Existing depth inpainting models may not possess the versatility needed for precise depth completion or may produce depths that are inconsistent with the unpainted regions. Such misalignments lead to suboptimal inpainting outcomes. To address this, we develop a more generalized depth inpainting model that harnesses the strengths of natural diffusion processes. In situations with substantial occlusion, relying on a single reference view may prove insufficient. To solve this, our approach incorporates multiple reference views through a progressive inpainting strategy.
利用前面讨论的关键观察结果,我们的管道如图2所示。从3D高斯曲线 Θ 开始,我们首先在掩模 ℳ={��}�=1� 的指导下分割并丢弃不需要的高斯曲线,掩模 ℳ={��}�=1� 描绘了用于修改的目标区域。如前所述,深度修复可以在确定高斯的初始位置方面发挥至关重要的作用。为了实现这一点,我们选择一个参考视图,并对图像及其相应的深度图进行修复,以促进准确的反投影。现有的深度修复模型可能不具备精确深度完成所需的多功能性,或者可能产生与未绘制区域不一致的深度。这种未对准导致次优的修复结果。为了解决这个问题,我们开发了一个更通用的深度修复模型,利用自然扩散过程的优势。在有大量遮挡的情况下,依赖于单个参考视图可能证明是不够的。 为了解决这个问题,我们的方法通过渐进式修复策略结合了多个参考视图。
The remainder of our methods are structured as the following. We describe the specifics of the diffusion-based depth completion model in Sec. 3.2 and use this model to do 3D scene inpainting in Sec. 3.3. Finally, we provide the details of progressive inpainting in Sec. 3.4.
我们的方法的其余部分结构如下。我们在第二节中描述了基于扩散的深度完井模型的细节。3.2并利用该模型在Sec. 3.3.最后,我们提供了渐进式修复的细节。3.4.
3.2Diffusion Models for Depth Completion
3.2深度完井的扩散模型
A precise and reliable depth inpainting model is essential to obtain a well-founded set of initial points for inpainting Gaussians. We build our depth completion model on latent diffusion models (LDMs) [79] for the strong priors due to their training on extensive, internet-scale collections of images. Given a set of color images and their corresponding depth, as well as various random masks, we seek to learn a model with the ability to inpaint the masked depth. The following three sections describe our diffusion-based depth completion model in details.
一个精确可靠的深度修复模型对于获得一组良好的初始点来修复高斯图像至关重要。我们在潜在扩散模型(LDM)[ 79]上构建深度补全模型,因为它们是在广泛的互联网规模的图像集合上训练的。给定一组彩色图像及其相应的深度,以及各种随机掩码,我们试图学习一个能够对掩码深度进行修补的模型。以下三个部分详细描述了我们的基于扩散的深度完井模型。
Diffusion Models We formulate depth completion as a task of conditional denoising diffusion generation. The LDMs operates by conducting diffusion processes within a lower-dimensional latent space, facilitated by a pre-trained Variational Auto-Encoder (VAE) ℰ. Diffusion steps are performed on these noisy latents where a denosing U-Net �� iteratively removes noise to get clean latents. During inference, the U-Net is applied to denoise pure Gaussian noise into a clean latent. The image recovery is then achieved by passing these refined latents through the VAE decoder 𝒟. This ensures that the depth completion model benefits from the powerful generative capabilities inherent in LDMs while also maintaining efficiency by operating within a compressed latent space.
扩散模型我们将深度补全公式化为条件去噪扩散生成的任务。LDM通过在低维潜在空间内进行扩散过程来操作,由预训练的变分自动编码器(VAE) ℰ 促进。对这些有噪声的潜伏期执行扩散步骤,其中去噪U-Net �� 迭代地去除噪声以获得干净的潜伏期。在推理过程中,U-Net被应用于将纯高斯噪声去噪为干净的潜势。然后通过使这些细化的潜伏期通过VAE解码器 𝒟 来实现图像恢复。这确保了深度补全模型受益于LDM中固有的强大生成能力,同时还通过在压缩的潜在空间内操作来保持效率。
Training We develop our model on top of a pre-trained text-to-image LDM (Stable Diffusion [79]) to save computational resources and enhance training efficiency. Modifying the existing model architecture, we adapt it for image-conditioned depth completion tasks. An outline of the refined fine-tuning process is presented in Fig. 2.
训练我们在预训练的文本到图像LDM(稳定扩散[79])之上开发我们的模型,以保存计算资源并提高训练效率。修改现有的模型架构,我们适应它的图像条件的深度完成任务。图2中给出了精细微调过程的概要。
Our depth completion diffusion model accepts a trio of inputs: a depth map �, a corresponding color image �, and a mask �. Leveraging the frozen VAE, we encode both the color image and the depth map into a latent space, which serves as the foundation for training our conditional denoiser. To accommodate the VAE encoder’s design for 3-channel (RGB) inputs when presented with a single-channel depth map, we duplicate the depth information across three channels to create an RGB-like representation. We apply a linear normalization to ensure the depth values predominantly reside within the interval [−1,1] following Marigold [44], thereby conforming to the VAE’s expected input range. This normalization is executed via an affine transformation delineated as follows:
我们的深度补全扩散模型接受三个输入:深度图 � ,对应的彩色图像 � 和掩码 � 。利用冻结的VAE,我们将彩色图像和深度图编码到一个潜在空间中,这是训练我们的条件去噪器的基础。为了适应VAE编码器在呈现单通道深度图时针对3通道(RGB)输入的设计,我们在三个通道上复制深度信息以创建类似RGB的表示。我们应用线性归一化以确保深度值主要位于Marigold [ 44]之后的间隔 [−1,1] 内,从而符合VAE的预期输入范围。该归一化通过如下描绘的仿射变换来执行:
| �′=�−�2�98−�2×2−1, | (1) |
where �2 and �98 represent the 2�� and 98�ℎ percentiles of individual depth maps, respectively. Such normalization facilitates the model’s concentration on affine-invariant depth completion, enhancing the robustness of the algorithm against scaling and translation.
其中 �2 和 �98 分别表示各个深度图的 2�� 和 98�ℎ 深度。这种归一化有助于模型集中于仿射不变深度完成,增强算法对缩放和平移的鲁棒性。
The normalized depth �′ and the color image are first encoded into the latent space with the encoder of the VAE:
首先利用VAE的编码器将归一化深度 �′ 和彩色图像编码到潜在空间中:
| �(�′)=ℰ(�′),�(�)=ℰ(�), | (2) |
The encoder produces a 4-channel feature map that has a lower resolution than the original input. To construct the image-conditioned depth completion model, we initially resize the mask � to align with the dimensions of �(�′), yielding �′=downsample(�). We then create a composite feature map by concatenating the noisy latent depth code ��(�′), the element-wise product of the clean latent depth code and the downscaled mask ��(�′)=�(�′)⊙�′, and the latent image code �(�), along with �′, as follows:
编码器产生一个4通道特征图,其分辨率低于原始输入。为了构建图像调节的深度补全模型,我们首先调整掩模 � 的大小以与 �(�′) 的尺寸对齐,从而产生 �′=downsample(�) 。然后,我们通过将噪声潜深代码 ��(�′) 、干净潜深代码和缩小掩模 ��(�′)=�(�′)⊙�′ 的逐元素乘积以及潜像代码 �(�) 与 �′ 一起沿着连接来创建合成特征图,如下所示:
| ��=cat(��(�′),��(�′),�(�),�′), | (3) |
along the channel dimension, where ��(�′)=���(�′)+���. The concatenated feature map ��, comprising 4+4+4+1=13 channels, is subsequently fed into the U-Net-based denoiser ��.
沿着通道尺寸,其中 ��(�′)=���(�′)+��� .包括 4+4+4+1=13 个通道的级联特征图 �� 随后被馈送到基于U-Net的去噪器 �� 中。
At training time, U-Net parameters � are updated by taking a data pair (�,�,�) from the training set, noising � with sampled noise � at a random timestep �, computing the noise estimate �^=��(��) and minimizing the denoising diffusion objective function following DDPM [36]:
在训练时,通过从训练集中获取数据对 (�,�,�) ,以随机时间步长 � 用采样噪声 � 对 � 进行噪声化,计算噪声估计 �^=��(��) 并根据DDPM最小化去噪扩散目标函数来更新U-Net参数 � [ 36]:
| ℒ=𝔼�,�,�∥�−��(��)∥22, | (4) |
where �∈{1,2,…,�} indexes the diffusion timesteps, �∈𝒩(0,�), and ��, the noisy latent at timestep �, is calculated as Eq. 3.
其中, �∈{1,2,…,�} 索引扩散时间步, �∈𝒩(0,�) 和 �� ,时间步 � 处的噪声潜伏被计算为等式:3.
Inference The inference of our depth completion model commences with an input comprising a depth map �, its corresponding color image �, and a mask � that delineates the target completion region. The color image � undergoes SDXL-based [75] image inpainting, resulting in �~=ℱ�(�,�), where ℱ� represents the image inpainting model. Subsequently, we generate the concatenated feature map as defined in Eq. 3, which is then progressively refined according to the fine-tuning scheme. Leveraging the non-Markovian sampling strategy from DDIM [89] with re-spaced steps facilitates an accelerated inference. The final depth map is then derived from the latent representation decoded by the VAE decoder 𝒟, followed by channel-wise averaging for post-processing.
我们的深度补全模型的推断开始于包括深度图 � 、其对应的彩色图像 � 和描绘目标补全区域的掩模 � 的输入。彩色图像 � 经过基于SDXL的图像修复,得到 �~=ℱ�(�,�) ,其中 ℱ� 表示图像修复模型。随后,我们生成如等式中定义的级联特征图。3,然后根据微调方案逐步细化。利用DDIM [ 89]的非马尔可夫采样策略,重新间隔步骤有助于加速推理。然后,从由VAE解码器 𝒟 解码的潜在表示导出最终深度图,随后进行逐通道平均以用于后处理。
3.3Inpainting 3D Gaussians with Diffusion Priors
3.3基于扩散先验的3D高斯图像修复
The trained diffusion model generates plausible depth completions, thereby serving as an effective initialization for the 3D Gaussians. Upon removing undesired points from 3D Gaussians, a set of reference views {��(��)}�=1� is selected, where �(��)∈{1,2,…,�} and � denotes the total number of chosen views. For forward-facing and certain 360-degree inward-facing datasets, a single reference view (�=1) is usually sufficient, whereas for more complex 360-degree scenes with occlusions, multiple reference views (�>1) are required. In instances with �>1, a progressive inpainting strategy is employed, detailed further in Sec. 3.4. The current discussion is focused on the �=1 scenario.
经过训练的扩散模型生成合理的深度补全,从而用作3D高斯的有效初始化。在从3D高斯图中移除不期望的点之后,选择一组参考视图 {��(��)}�=1� ,其中 �(��)∈{1,2,…,�} 和 � 表示所选视图的总数。对于前向和某些360度内向数据集,单个参考视图( �=1 )通常就足够了,而对于具有遮挡的更复杂的360度场景,则需要多个参考视图( �>1 )。在具有 �>1 的实例中,采用渐进式修复策略,在第2.1.2节中进一步详述。3.4.当前讨论的重点是 �=1 场景。
Assuming without loss of generality, for �=1, we designate the �(�1)�ℎ view as the single reference. Initially, the color image ��(�1)⊙��(�1) is inpainted using an SDXL-based inpainting model to yield the restored image �~�(�1). The depth for the �(�1)�ℎ view is then determined analogous to color rendering in GS:
在不失一般性的情况下,对于 �=1 ,我们指定 �(�1)�ℎ 视图作为单个引用。最初,使用基于SDXL的修补模型修补彩色图像 ��(�1)⊙��(�1) 以产生恢复图像 �~�(�1) 。然后,类似于GS中的颜色渲染来确定 �(�1)�ℎ 视图的深度:
| ��(�1)=∑�∈��(�1)����∏�=1�−1(1−��), | (5) |
where �� denotes the z-coordinate in the world coordinate system, and �� represents the density of the corresponding point. It is important to note that the resulting depth � is incomplete, as it derives from Θ. To address this, we apply our diffusion-based depth completion model ℱ�, which produces the refined depth map:
其中 �� 表示世界坐标系中的z坐标,并且 �� 表示对应点的密度。重要的是要注意,所得到的深度 � 是不完整的,因为它是从 Θ 导出的。为了解决这个问题,我们应用了我们的基于扩散的深度补全模型 ℱ� ,它产生了细化的深度图:
| �~�(�1)=ℱ�(��(�1),�~�(�1),��(�1)). | (6) |
With the completed depth map �~�(�1), the inpainted image �~�(�1), and the corresponding camera pose Π�(�1), we unproject �~�(�1) and �~�(�1) from image space to 3D coordinates to form a colored point cloud 𝒫�(�1). This point cloud is then merged with the original 3D Gaussian point cloud to achieve a robust initialization Θ′ for subsequent GS fine-tuning.
利用完成的深度图 �~�(�1) 、修复后的图像 �~�(�1) 和对应的相机姿态 Π�(�1) ,我们将 �~�(�1) 和 �~�(�1) 从图像空间解投影到3D坐标以形成彩色点云 𝒫�(�1) 。然后将该点云与原始3D高斯点云合并,以实现用于后续GS微调的鲁棒初始化 Θ′ 。
Ultimately, the preliminary Gaussian model Θ′ are fine-tuned merely 50∼150 iterations to yield the final Gaussian model Θ~, using solely the selected view image ��(�1). The optimization is also guided by ℒ1 combined with D-SSIM at the �(�1)�ℎ view:
最终,仅使用所选择的视图图像 ��(�1) ,仅对初始高斯模型 Θ′ 进行50次 ∼ 150次迭代微调,以产生最终高斯模型 Θ~ 。优化也由 ℒ1 结合 �(�1)�ℎ 视图中的D-SSIM指导:
| ℒ�(�1)=(1−�)∥��(�1)′−�~�(�1)∥1+�⋅D-SSIM(��(�1)′,�~�(�1)), | (7) |
where ��(�1)′ denotes the image rendered from the �(�1)�ℎ viewpoint. We set �=0.2 across all experiments and provide comprehensive details of the learning schedule and additional experimental settings in Sec. 4.1.
其中 ��(�1)′ 表示从 �(�1)�ℎ 视点渲染的图像。我们在所有实验中设置了 �=0.2 ,并在第二节中提供了学习时间表和其他实验设置的全面详细信息。4.1.
3.4Progressive Inpainting
3.4渐进修复
For occlusion-rich, complex scenes, multiple reference views (�>1) are imperative. To solve these challenges, we implement a progressive inpainting approach. Commencing with the initial reference view �(�1) from the selected views 𝒮={�(�1),�(�2),…,�(��)}, we apply Gaussian inpainting as delineated in Sec. 3.3. Subsequent to this, we render the color image, depth map, and associated mask from the next reference view �(�2). This process is iterated, employing Gaussian inpainting for each successive reference view until the view �(��) is addressed. This progressive technique effectively accommodates the complexities, especially for occlusions.
对于遮挡丰富的复杂场景,必须使用多个参考视图( �>1 )。为了解决这些挑战,我们实施了渐进式修复方法。从来自所选视图 𝒮={�(�1),�(�2),…,�(��)} 的初始参考视图 �(�1) 开始,我们应用如在第2节中描绘的高斯修补。3.3.在此之后,我们从下一个参考视图 �(�2) 渲染彩色图像、深度图和相关联的遮罩。迭代该过程,对每个连续的参考视图采用高斯修补,直到视图 �(��) 被寻址。这种渐进技术有效地适应了复杂性,特别是对于遮挡。
4Experiments 4实验
4.1Experiments Setup 4.1实验设置

Figure 3:Qualitative Comparison with Baselines. Zoom in for details. Our method exhibits sharp textures that maintain 3D coherence, whereas baseline approaches often yield details that appear blurred.
图3:与基线的定性比较。放大查看详细信息。我们的方法具有清晰的纹理,保持3D的连贯性,而基线方法往往会产生模糊的细节。

Figure 4:Qualitative Comparison with Baselines. We delve into more challenging scenarios, including those with multi-object occlusion, where our method uniquely stands out by accurately inpainting the obscured missing segments.
图4:与基线的定性比较。我们深入研究了更具挑战性的场景,包括那些具有多对象遮挡的场景,其中我们的方法通过准确地修复被遮挡的缺失片段而独特地脱颖而出。

Figure 5:Ablation study on depth inpainting, we present comparative results against widely-used other baselines, along with the corresponding point cloud visualizations. The comparisons distinctly reveal that our approach successfully inpaints shapes that are correctly aligned with the existing geometry.
图5:消融研究深度修补,我们提出了比较结果对广泛使用的其他基线,沿着与相应的点云可视化。比较清楚地表明,我们的方法成功地inpaints的形状,正确对齐现有的几何形状。

Figure 6:Ablation study on progressive inpainting. InFusion can adeptly handle inpainting tasks for views that substantially deviate from the initial reference frames.
图6:渐进式修复的消融研究。InFusion可以熟练地处理大幅偏离初始参考帧的视图的修复任务。

Figure 7:User-interactive Texture Inpainting. InFusion allows users to modify the appearance and texture of targeted areas with ease.
图7:用户交互式纹理修复。InFusion允许用户轻松修改目标区域的外观和纹理。

Figure 8:Object Insertion. Through editing a single image, users are able to project objects into a real three-dimensional scene. This process seamlessly integrates virtual objects into the physical environment, offering an intuitive tool for scene customization.
图8:对象插入。通过编辑单个图像,用户能够将对象投影到真实的三维场景中。此过程将虚拟对象无缝集成到物理环境中,为场景定制提供了直观的工具。

Figure 9:Limitations. As the lighting of the surrounding region increasingly differs from the reference, the inpainted area becomes less harmonious with these views. InFusion struggles to adapt inpainted regions to variations in lighting conditions.
图9:局限性。随着周围区域的照明与参考的差异越来越大,修复后的区域与这些视图变得不那么和谐。InFusion努力使修复区域适应光照条件的变化。
Training settings To train a diffusion model with broad generalizability for depth inpainting and to facilitate generalized Gaussian inpainting, we train our LDM models using the SceneFlow dataset [62], which comprises FlyingThings and Driving scenes. This dataset offers an extensive collection of over 100,000 frames, each accompanied by ground truth depth, and rendered from a variety of synthetic sequences. During training, masks are randomly generated for each iteration using either a square, random strokes, or a combination of both techniques. We initialize the LDM with pre-trained depth prediction weights sourced from the Marigold [44]. We also tested other pre-trained weight which is presented in the supplementary. The training process spans 200 epochs, with an initial learning rate of 1e-3, which is scheduled to decay after every 50 epochs. Utilizing eight A100 GPUs, the training process is completed within one day.
训练设置为了训练具有广泛泛化能力的扩散模型进行深度修复并促进广义高斯修复,我们使用SceneFlow数据集[ 62]训练我们的LDM模型,其中包括FlyingThings和Driving场景。该数据集提供了超过100,000帧的广泛集合,每个帧都伴随着地面真实深度,并从各种合成序列中呈现。在训练期间,使用正方形、随机笔划或这两种技术的组合为每次迭代随机生成掩码。我们使用来自Marigold的预训练深度预测权重初始化LDM [ 44]。我们还测试了补充资料中提供的其他预训练权重。训练过程跨越200个epoch,初始学习率为1 e-3,每50个epoch后衰减一次。利用八个A100 GPU,训练过程在一天内完成。
Evaluation settings We evaluate our method across a variety of datasets, which include forward-facing scenes and the more complex unbounded 360-degree scenes. For the forward-facing datasets, we adhere to the rigorous evaluation settings established by SPIn-NeRF [67]. To further demonstrate the text-guided 3D inpainting capabilities of our method, we also introduce our own captured sequences including large occlusion between objects. The challenging unbounded 3D scenes are taken from the Mip-NeRF [4], featuring large central objects within realistic backgrounds, and the 3DGS, which includes a variety of intricate objects from free-moving camera angles. These datasets are particularly challenging for 3D inpainting. We emphasize that our LDM depth inpainting methods were not trained on any of these datasets. For scene masking, we used masks from SAM-Track [17], dilating them by 9 pixels to reliably remove any undesired parts.
评估设置我们在各种数据集上评估我们的方法,其中包括面向前方的场景和更复杂的无界360度场景。对于面向前的数据集,我们坚持SPIn-NeRF [ 67]建立的严格评估设置。为了进一步展示我们的方法的文本引导的3D修复能力,我们还介绍了我们自己捕获的序列,包括对象之间的大遮挡。具有挑战性的无界3D场景取自Mip-NeRF [ 4],具有逼真背景中的大型中心对象,以及3DGS,其中包括来自自由移动相机角度的各种复杂对象。这些数据集对于3D修复来说特别具有挑战性。我们强调,我们的LDM深度修复方法没有在任何这些数据集上训练。对于场景遮罩,我们使用SAM-Track [ 17]中的遮罩,将它们放大9个像素以可靠地去除任何不需要的部分。