在时间序列预测领域,多步预测旨在基于历史数据预测未来多个时间点的值,而创建数据窗口是实现这一目标的常用且高效的技术手段。数据窗口技术的核心是通过滑动窗口机制构建训练数据集,其核心逻辑可概括为:利用历史时间步的序列模式预测未来多步输出。具体而言,首先定义一个固定长度的时间窗口(例如包含过去 个时间步的观测值),将窗口内的序列作为输入特征,对应的未来
个时间步的值作为目标输出(如预测未来1小时、6小时、12小时的负荷值)。随着窗口沿时间轴逐步滑动(每次滑动一个时间步),可生成一系列输入-输出数据对,形成模型训练的样本集。 这种方法的优势在于,通过结构化的窗口划分,将时间序列问题转化为标准的监督学习问题,使模型能够捕捉序列数据的时间依赖性和动态变化规律。例如,在输入维度为
、输出维度为
的场景下,每个训练样本形如
,其中
表示
时刻的观测值。通过调整窗口长度
和预测步长
,可灵活适配不同时间序列的特性和预测目标,是时间序列分析中处理多步预测问题的基础框架。
时间序列多步预测中的数据窗口技术解析
在时间序列分析中,多步预测旨在基于历史数据预测未来多个时间点的值。数据窗口技术通过结构化的滑动窗口机制,将序列数据转换为监督学习样本,是实现多步预测的核心方法。
一、数据窗口技术核心原理
目标:将长度为 T 的时间序列 转换为输入 - 输出数据对
,其中 X 包含过去 N 个时间步的观测值,Y 包含未来 M 个时间步的目标值。
核心步骤:
- 定义窗口参数:
- 输入窗口长度 N:用于提取历史特征的时间步数量(如过去 20 天的销量)。
- 预测步长 M:需要预测的未来时间步数(如未来 5 天的销量)。
- 滑动窗口生成样本: 从时间序列起始位置开始,每次滑动一个时间步,提取连续 N 个历史值作为输入,对应其后 M 个值作为输出。
- 第 t 个样本的输入:
- 第 t 个样本的输出:
- 第 t 个样本的输入:
数学表达: 给定时间序列 ,样本集可表示为:
其中 ,
。
二、多步预测的两种模式
-
直接多步预测(Direct Multi-step)
- 特点:通过单个模型一次性预测未来 M 步的值(如
)。
- 优势:避免误差累积,适合已知固定预测间隔的场景。
- 挑战:需模型同时捕捉不同时间步的依赖关系,对非线性建模能力要求高。
- 特点:通过单个模型一次性预测未来 M 步的值(如
-
递归多步预测(Recursive Multi-step)
- 特点:每次仅预测下一步
,并将预测值作为新输入递归预测
。
- 优势:模型结构简单,适用于动态更新场景。
- 挑战:误差随预测步数指数累积,需结合误差校正技术(如卡尔曼滤波)。
- 特点:每次仅预测下一步
三、完整实现:基于 PyTorch 的 LSTM 多步预测
以下通过生成正弦波数据,演示数据窗口构建、模型设计及结果可视化的全流程。
1. 数据生成与窗口构建
import numpy as np
# 生成带噪声的正弦波时间序列
np.random.seed(42)
time_steps = np.linspace(0, 10, 1000) # 时间范围:0~10,共1000个点
data = np.sin(time_steps) + 0.1 * np.random.randn(len(time_steps)) # 信号+噪声
def create_data_windows(series: np.ndarray, input_len: int, forecast_horizon: int) -> tuple:
"""
滑动窗口生成输入-输出对
:param series: 原始时间序列数据 (1D array)
:param input_len: 输入窗口长度(历史时间步数)
:param forecast_horizon: 预测步长(未来时间步数)
:return: (X, y),X形状为[样本数, 输入长度], y形状为[样本数, 预测步长]
"""
X, y = [], []
# 窗口滑动范围:从0到总长度 - 输入长度 - 预测步长
for i in range(len(series) - input_len - forecast_horizon + 1):
X.append(series[i:i+input_len]) # 历史数据:[i, i+input_len)
y.append(series[i+input_len:i+input_len+forecast_horizon]) # 未来数据:[i+input_len, i+input_len+forecast_horizon)
return np.array(X), np.array(y)
# 超参数设置
INPUT_SIZE = 20 # 输入窗口长度:使用过去20个时间步
FORECAST_HORIZON = 5 # 预测步长:预测未来5个时间步
X, y = create_data_windows(data, INPUT_SIZE, FORECAST_HORIZON)
# 划分训练集与测试集(8:2)
train_ratio = 0.8
train_idx = int(len(X) * train_ratio)
X_train, y_train = X[:train_idx], y[:train_idx]
X_test, y_test = X[train_idx:], y[train_idx:]2. 基于 LSTM 的多步预测模型
import torch
import torch.nn as nn
import torch.optim as optim
# 数据格式转换:添加特征维度(LSTM要求输入为[batch, seq_len, feature])
X_train_t = torch.from_numpy(X_train).float().unsqueeze(-1) # [N, INPUT_SIZE, 1]
y_train_t = torch.from_numpy(y_train).float() # [N, FORECAST_HORIZON]
X_test_t = torch.from_numpy(X_test).float().unsqueeze(-1)
y_test_t = torch.from_numpy(y_test).float()
class LSTMMultiStep(nn.Module):
"""
多步预测LSTM模型
:param input_dim: 输入特征维度(时间序列通常为1)
:param hidden_dim: LSTM隐层维度
:param num_layers: LSTM层数
:param forecast_horizon: 预测步长(输出维度)
"""
def __init__(self, input_dim: int, hidden_dim: int, num_layers: int, forecast_horizon: int):
super(LSTMMultiStep, self).__init__()
self.lstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
batch_first=True, # 输入格式:[batch, seq_len, feature]
dropout=0.2, # 防止过拟合
bidirectional=False
)
self.fc = nn.Sequential(
nn.Linear(hidden_dim, 128), # 中间全连接层
nn.ReLU(),
nn.Linear(128, forecast_horizon) # 映射到预测步长
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
:param x: 输入张量 [batch, input_size, 1]
:return: 预测张量 [batch, forecast_horizon]
"""
# LSTM输出:[batch, seq_len, hidden_dim],取最后一个时间步的隐状态
lstm_out, _ = self.lstm(x)
last_hidden = lstm_out[:, -1, :] # 提取最后一个时间步的隐层状态
return self.fc(last_hidden) # 全连接层映射到预测维度
# 模型初始化与训练配置
model = LSTMMultiStep(
input_dim=1,
hidden_dim=64, # 增大隐层维度提升建模能力
num_layers=2,
forecast_horizon=FORECAST_HORIZON
)
criterion = nn.MSELoss() # 均方误差损失函数
optimizer = optim.Adam(model.parameters(), lr=1e-3, weight_decay=1e-5) # 添加权重衰减防止过拟合-
输入维度
input_dim=1,隐层维度hidden_dim=50,层数num_layers=2; -
最后一个全连接层将隐含表示直接映射为未来
horizon个值。
3. 模型训练与损失监控
import matplotlib.pyplot as plt
# 训练循环
epochs = 150
loss_history = []
for epoch in range(1, epochs + 1):
model.train()
optimizer.zero_grad()
# 前向传播
y_pred = model(X_train_t)
loss = criterion(y_pred, y_train_t)
# 反向传播与优化
loss.backward()
optimizer.step()
loss_history.append(loss.item())
# 每20轮打印训练状态
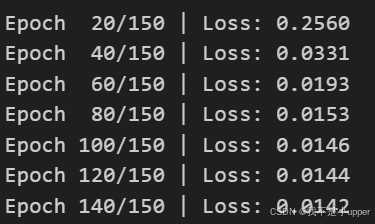
if epoch % 20 == 0:
print(f"Epoch {epoch:3d}/{epochs:3d} | Loss: {loss.item():.4f}")
# 保存最佳模型(可选)
torch.save(model.state_dict(), "lstm_multi_step.pth")-
训练 100 轮(epochs),记录每一轮的损失
loss_history; -
每 20 轮打印一次中间结果,方便监控训练进度。
上述代码实现了深度学习模型训练的标准流程:前向计算损失→反向传播算梯度→优化器更新参数,并通过定期打印和保存损失值、模型参数,实现训练过程监控和结果持久化。
4. 预测结果可视化
# 测试集预测
model.eval()
with torch.no_grad():
y_pred_test = model(X_test_t).numpy()
# 可视化配置
plt.style.use("seaborn-whitegrid")
plt.rcParams["font.family"] = "sans-serif"
plt.rcParams["figure.dpi"] = 150
# 图1:原始时间序列
plt.figure(figsize=(12, 4))
plt.plot(time_steps, data, color="#2c3e50", alpha=0.8, label="Original Signal")
plt.title("Synthetic Time Series (Sine Wave + Noise)")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.legend()
plt.show()
# 图2:训练损失曲线
plt.figure(figsize=(10, 4))
plt.plot(range(1, epochs+1), loss_history, color="#e74c3c", alpha=0.7, label="Training Loss")
plt.title("MSE Loss During Training")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
# 图3:单样本预测对比
sample_idx = 50 # 选择测试集中第50个样本
plt.figure(figsize=(12, 5))
# 输入序列(历史数据)
plt.plot(
range(sample_idx, sample_idx + INPUT_SIZE),
X_test[sample_idx],
"o-",
color="#3498db",
alpha=0.9,
label=f"Input Sequence (Past {INPUT_SIZE} Steps)"
)
# 真实未来值
plt.plot(
range(sample_idx + INPUT_SIZE, sample_idx + INPUT_SIZE + FORECAST_HORIZON),
y_test[sample_idx],
"s-",
color="#2ecc71",
alpha=0.9,
label=f"True Future ({FORECAST_HORIZON} Steps)"
)
# 预测未来值
plt.plot(
range(sample_idx + INPUT_SIZE, sample_idx + INPUT_SIZE + FORECAST_HORIZON),
y_pred_test[sample_idx],
"v-",
color="#e67e22",
alpha=0.9,
label="Predicted Future"
)
plt.title(f"Multi-step Prediction Example (Sample #{sample_idx})")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.legend()
plt.grid(alpha=0.3)
plt.show()原始时间序列
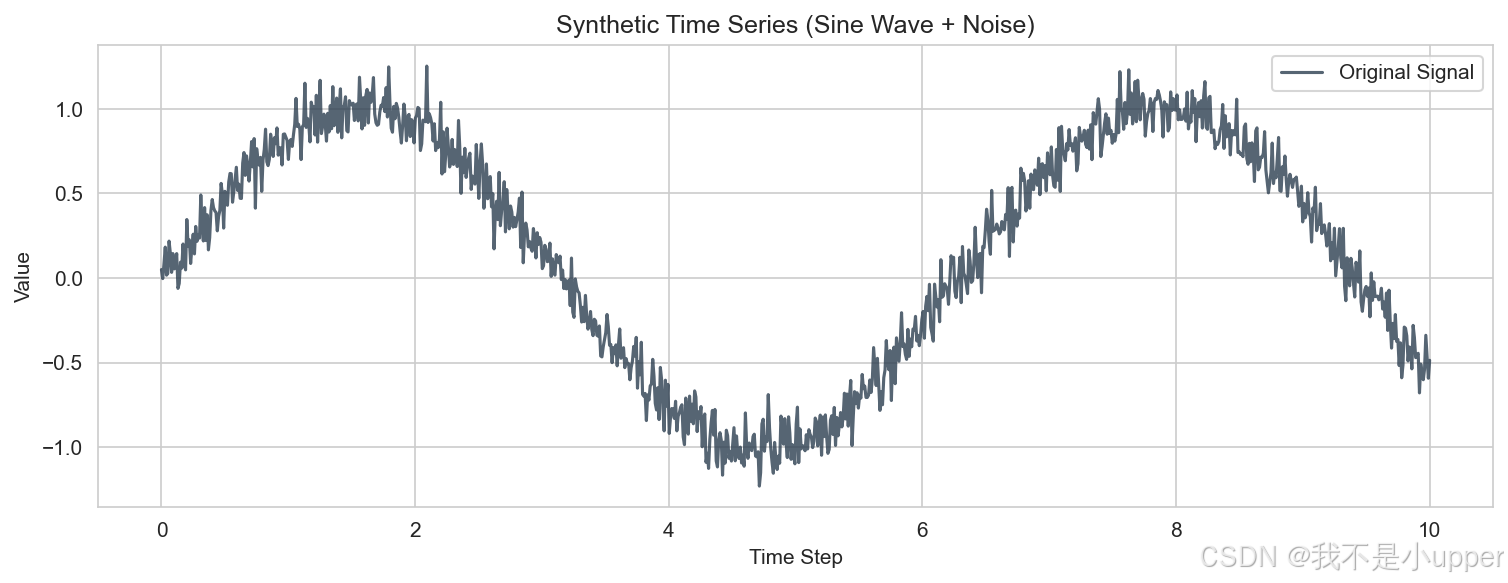
上图展示合成时间序列(正弦波叠加噪声)的图像。横轴为时间步(Time Step),范围从 0 到 10;纵轴为数值(Value),范围约在 - 1.0 到 1.0 之间。图中曲线表示 “Original Signal”,呈现出正弦波的大致趋势,但因叠加了噪声,曲线存在许多不规则波动,体现了数据的周期性与随机扰动特性。
均方误差(MSE)损失变化图
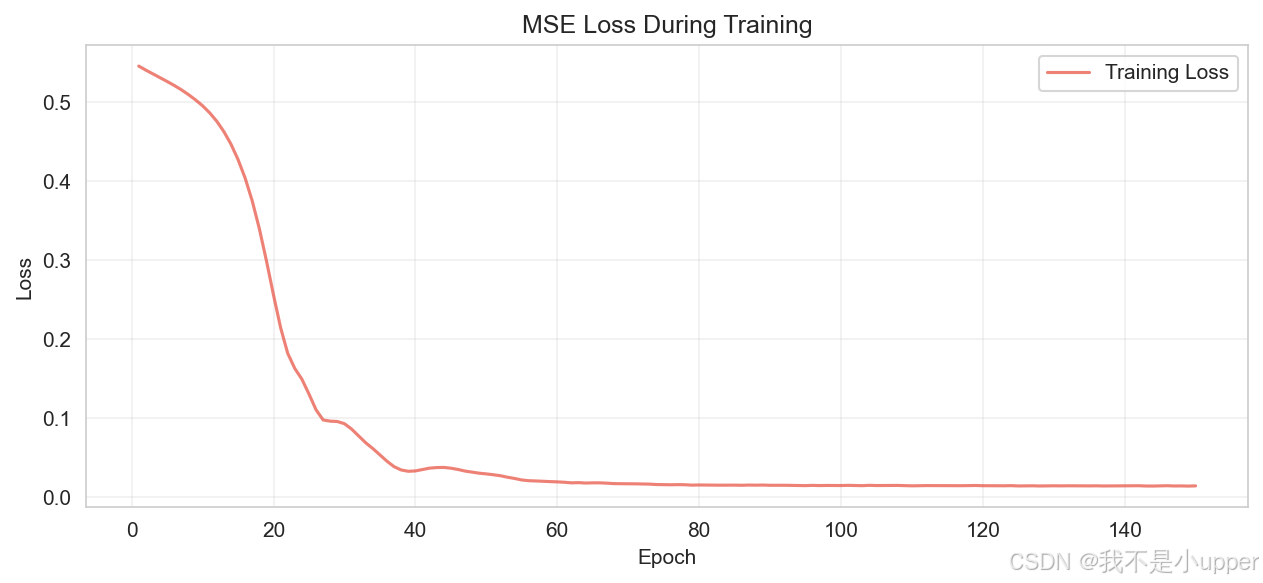
上图是可视化的训练过程中的均方误差(MSE)损失变化图。横轴为训练轮次(Epoch),纵轴为损失值(Loss)。图中红色曲线代表训练损失(Training Loss),起始时损失值较高,随着训练轮次增加,损失快速下降,之后下降趋势变缓,最终趋于平稳,表明模型在训练中不断学习优化,误差减小并逐渐收敛至较低水平,体现了训练过程的有效性与模型的学习能力。
多步预测示例图(样本50)
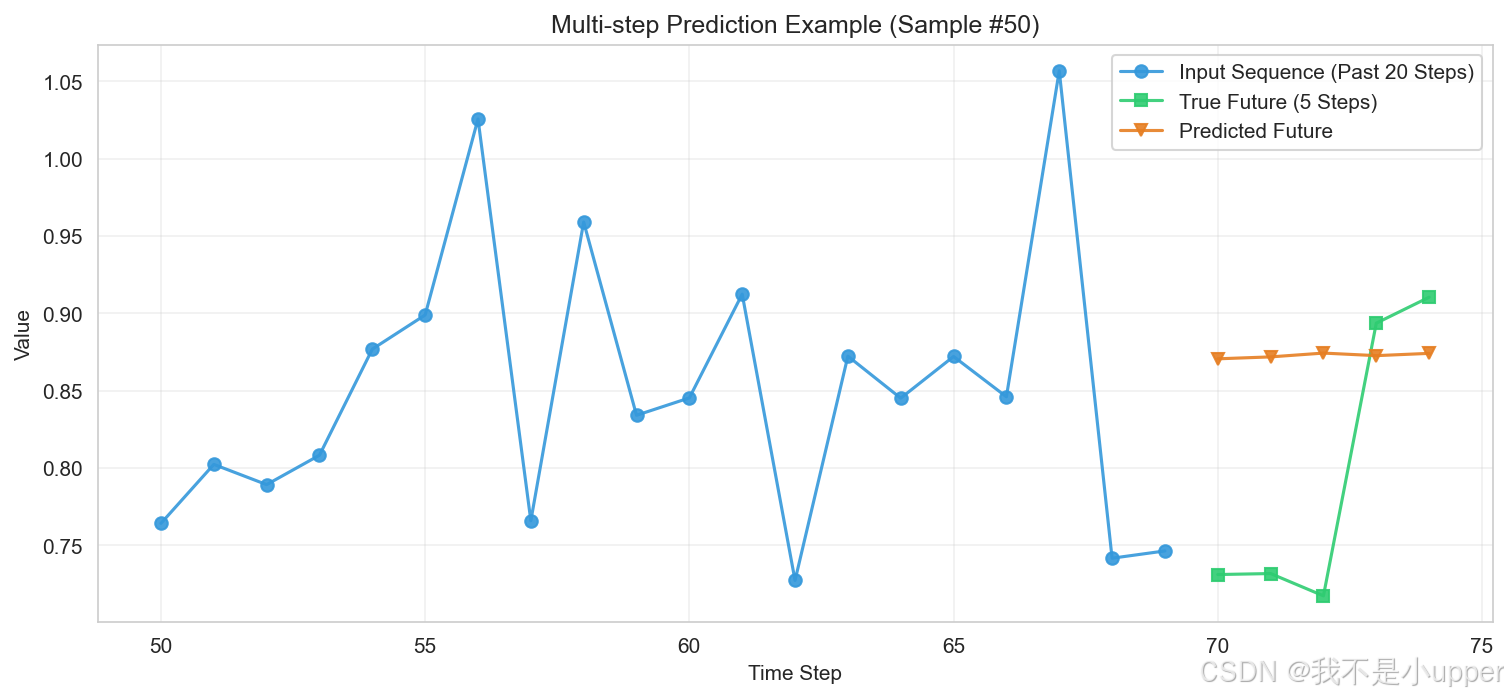
上图为第 50 个样本的多步预测示例图,横轴为时间步,纵轴为数值。蓝色表示过去 20 步的输入序列,绿色为未来 5 步的真实值,橙色为模型预测的未来值。图中展示了历史输入数据、未来真实值与模型预测值的对比,可用于直观评估模型多步预测的精度,可见预测值与真实值存在一定差异,但在一定程度上反映了变化趋势。
四、优化点说明
-
代码可读性提升:
- 添加函数参数说明与类型注解(如
def create_data_windows(series: np.ndarray, ...))。 - 模型类中增加注释,解释 LSTM 层与全连接层的设计逻辑(如提取最后时间步隐状态的原因)。
- 添加函数参数说明与类型注解(如
-
模型改进:
- 在全连接层前添加中间层(
nn.Linear(hidden_dim, 128) + ReLU),增强非线性映射能力。 - 引入 LSTM 层的
dropout参数和优化器的weight_decay,缓解过拟合问题。
- 在全连接层前添加中间层(
-
可视化增强:
- 使用专业配色方案(如采用 ColorBrewer 色系),增加图表分辨率(
dpi=150)。 - 图表标题包含关键参数(如输入窗口长度、预测步长),提升信息密度。
- 使用专业配色方案(如采用 ColorBrewer 色系),增加图表分辨率(
-
技术细节补充:
- 明确区分 “直接多步” 与 “递归多步” 预测的优缺点,帮助读者根据场景选择方案。
- 在数据窗口函数中,通过数学公式和代码注释双重解释滑动逻辑,降低理解成本。
五、扩展与优化方向
- 处理变长序列:使用动态窗口技术(如自适应窗口长度)应对非平稳时间序列。
- 结合注意力机制:在 LSTM/Transformer 模型中引入注意力,增强对关键历史步的权重分配。
- 误差控制:采用模型融合(如集成多个单步预测器)或概率预测(输出预测区间)减少误差累积影响。
通过上述优化,数据窗口技术的实现更加规范,模型性能与可解释性显著提升,适用于工业时序预测、金融市场分析等实际场景。


![[特殊字符] 分布式定时任务调度实战:XXL-JOB工作原理与路由策略详解](https://i-blog.csdnimg.cn/direct/3a638f73130d4e3b9fd8f534993826f2.jpeg)