文末有视频讲解
在上一个模块中,我和小伙伴们一起学习了 Redis 最核心的命令,主要涉及 String、List、Hash、Set、Sorted Set 五种数据结构的命令,同时,我们还介绍了每种数据结构的实战场景,并带领小伙伴们使用 Java 语言中的 Lettuce 客户端,实现了每种实践场景的核心代码。
经过上一模块的学习之后,相信小伙伴们已经知道如何结合实际需求使用 Redis 了。如果只是达到 应用的层次,在进行面试或者做架构设计的时候,是远远不够的,我们需要更进一步,了解 Redis 中这五种数据结构的底层实现原理,才能达到 用好的层次,从而让我们在面试和工作中脱颖而出。
因此,这一模块我们将从源码级别抽丝剥茧,介绍 Redis 五大数据结构的底层原理,读完本模块之后,小伙伴们就会对 Redis 五大数据结构的原理有透彻清晰的理解。
下面我们就开始看 Redis 的字符串实现了,Redis 并没有直接用 C 语言的字符串,而是自己搞了一个 sds 的结构体来表示字符串,这个 sds 的全称是 Simple Dynamic String,翻译过来就是“简单的动态字符串”。
Redis 为什么自定义字符串实现?
这里我们需要首先解决一个前置问题:Redis 为什么不用 C 语言的字符串,而非要自己搞一个出来呢?
我汇总了下,主要有以下三个原因。
第一个原因是“安全的二进制存储”,在有的场景里面,我们在字符串里可能需要存 \0 这种特殊字符。比如说,Hello \0 World! \0 这种数据,如下:
如果直接用 C 语言字符串的话,\0 表示字符串结尾,那我就会认为是到 Hello 字符串就完了,对不对?为了要存 \0 这种特殊字符,sds 就不再把 \0 当作字符串的结尾,而是明确地记录字符串的长度,比如说存个 length 字段,我就知道到第一个 \0 的时候,字符串还没结束。这样的话,我们就可以在字符串里面存储 \0 这种特殊字符了,我们也把这种能存储特殊字符的方式叫作 “安全的二进制存储”。
第二个原因是减少 CPU 的消耗,这是明确存储字符串长度的另一个好处。在第 3 讲《先导基础篇:10 分钟 C 语言入门》那篇文章中说过,就是 C 语言字符串是个简单的 char 数组,没有 length 之类的属性来记录字符串长度,那我们要获得一个字符串长度的时候,就要从头开始一个一个字符地遍历,直到遇到 \0 这种结束符。那每次拿 length 都遍历一遍,会非常消耗 CPU,所以 sds 记录字符串长度呢,就省下了这部分 CPU。
第三个原因,就是字符串的扩缩容问题。如果用 C 字符串的话,char 数组的长度需要在创建字符串的时候,就确定下来。如果说我需要在这个字符串后边追加数据,就类似于 Java 里面的字符串相加操作,我们就需要重新申请这个 char 数组的空间,把相加之后的字符串拷贝进去,然后把原来字符串空间释放掉,这就会比较消耗资源。
Redis sds 呢,会预先多申请一部分空间预留,比如说我创建了一个长度为 50 的字符串,sds 实际上是申请了 100 个字符的空间,这样的话我后面有新的字符加进来的时候,就可以不用再进行扩容了。
在缩容的场景里面也是类似的。把一个原生的 C 字符串变短的话,需要立刻进行内存拷贝;要是用 Redis sds 的话,直接修改里面的 len 字段就行,不用进行任何内存拷贝,是不是很 nice!
通过上面的描述,我们也就知道 Redis 自定义字符串实现的原因了,与此同时我们也能大概猜出来 Redis 字符串的结构。我们需要有一个 char 类型的数组来记录字符串的实际值,然后一个 int 类型的 length 字段来记录 char 数组使用了多少个字节,还要有一个 int 类型的 alloc 字段来记录 char 数组分配的总长度。大致结构如下:
struct sds {
int len; // 记录char数组实际使用了多少个字节
int alloc; // 记录char数组的实际长度
char buf[]; // 存储字符串
};
为什么有 5 个 sds 结构体?
下面来看看 Redis 的设计,跟我们上面的设计是不是一样的。
在 Redis 源码的 sds.h 这个文件里面,我们可以看到 5 个 sdshdr 结构体,从 sdshdr5 一直到 sdshdr64,这 5 个结构体就是 Redis 字符串的真身。
那为什么会有 5 个 sds 结构体呢?我们通过对比下面的 sdshdr8 和 sdshdr16 ,就可以得到答案:5 个 sds 分别用来存储不同长度的字符串。
-
sdshdr8 里面的 len、alloc 字段都是 uint8_t 这个类型,在很多语言中,例如 Java, int 就是 32 位,而 C 语言里面有多种长度的 int 值,uint8_t 就是占 8 位的无符号 int 值,能表示的最大值就是 2^8-1,那它的 buf 数组,最大长度就是 2^8 -1。也就是说,sdshdr8 能表示长度在 2^8-1 这个范围内的字符串,再长的话,buf 数组就存不下了。
-
sdshdr16 里面的 len 和 alloc 字段都是 uint16_t 类型,也就是占 16 位的无符号 int 值,能表示的最大值就是 2^16-1。也就是说,sdshdr16 能表示长度在 2^16-1 这个范围内的字符串,再长的话,buf 数组也就存不下了。
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; // 下面的buf数组已经使用了多少字节
uint8_t alloc; // 下面的buf数组实际分片
unsigned char flags; // 低三位用来表示字符串的类型
char buf[]; // 用来存储字符串数据
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
同理,小伙伴们可以自己翻看一下 sdshdr32、sdshdr64 两个结构体,这两个结构体里面的 int 值,分别是 32 位和 64 位的。
现在是不是感觉到了 Redis 在存储空间上的优化功力呢?如果字符串 abc 同时用 sdshdr8 和 sdshdr 16 存储的话,仅仅是 len 和 alloc 两个字段,sdshdr8 就比 sdshdr 16 节省了两个字节。当存储的字符串数量级起来的时候,比如说达到了 10 亿级别,每个字符串节省 1 个字节,就能省出将近 1 G 的空间,这个空间还是很可观的!所以,后面我们会看到,Redis 创建 sds 实例的时候,会根据字符串的长度,决定使用哪种类型的 sds 。
__attribute__ ((__packed__)) 是什么鬼东西?
说完为什么有 5 个 sds 结构体之后,我们再来看看 sds 结构体定义的一些细节,其中,最显眼的就是,struct 关键字之后跟的__attribute__ ((__packed__)) 这段乱七八糟的东西。要说这个,我们就要先来介绍一下内存对齐的一点知识。
这里我们先写一个 sdemo 结构体,这里 typedef struct 是另一种定义结构体的方式,其实和前面直接用 struct 定义结构体一样的效果,具体如下:
typedef struct {
char c1; // 1字节
short s; // 2字节
char c2; // 1字节
int i; // 4字节
} sdemo;
可以看到,这个结构体里面有四个字段,分别是:c1,这是个 char 类型的字段,占一个字节,这个地方和 Java 不太一样,Java 里面一个 char 类型的字段,占用 2 个字节;然后是一个 short 类型的 s 字段,占两个字节;接下来又是一个 char 类型的 c2 字段;最后是一个 int 类型的 i,占四个字节。
按照我们正常的想法,c1、s、c2 还有 i 这些字段都是紧凑地排列在内存里面的,就跟下面这张图一样:
下面我们就写一个示例,输出一下 sdemo 里面各个字段的地址。前面在《先导基础篇:10 分钟 C 语言入门》那一讲中提到,这个 & 符就是取地址的意思,我们这里先定义一个 sdemo 的实例,然后取一下这个 sdemo 实例本身的地址,接着再取一下这个实例中各个字段的地址,输出一下。
void testsdemo() {
sdemo a; // 创建一个sdemo实例
printf("%p\n", &a);
printf("%p\n", &a.c1);
printf("%p\n", &a.s);
printf("%p\n", &a.c2);
printf("%p\n", &a.i);
}
void main() {
testsdemo();
}
// 输出
0x7ffee382b890
0x7ffee382b890
0x7ffee382b892
0x7ffee382b894
0x7ffee382b898
我们会发现,sdemo 里面各个字节的排布是下图这样的:
编译器会在 c1 之后填充一个字符,在 c2 后面填充三个字符,这样的话,就四字节对齐了。
那为什么要进行内存对齐呢?嗯,这主要跟具体的平台有关系,比如说我的机器每次读内存的时候,都是从四字节的位置开始读,每次读取四个字节,这样的话,我读取一个 int 的时候,就希望它的起始位置在四字节倍数的位置,这样读取一次就可以完成一个 int 的读取。那如果我的 int 首地址放到了一个奇数的地址上,就像这样:
这种情况就会导致我读两次内存后,才能读出来一个完整的 int 值。
一般情况下,我们是不需要关心内存对齐的事情的,因为编译器在编译代码的时候,会直接根据机器的这个平台完成代码对齐的这些操作。但是,有的场景里面,我们不能进行内存对齐,例如, sds 中需要使用指针前后移动的方式,获取结构体中指定的字段值。 这个时候,我们就可以在结构体前面加上__attribute__ ((__packed__)) 指令。
来写个例子试一下,我在 sdemo 结构体前面加上这个指令,让它不进行内存对齐:
typedef struct __attribute__ ((__packed__)) {
char c1; // 1字节
short s; // 2字节
char c2; // 1字节
int i; // 4字节
} sdemo;
我们依旧执行前面的 testsdemo() 方法,得到输出是这样的:
0x7ffeea539898
0x7ffeea539898
0x7ffeea539899
0x7ffeea53989b
0x7ffeea53989c
那在内存里面的结构就是这样的,内存是非常紧凑的,没有任何填充:
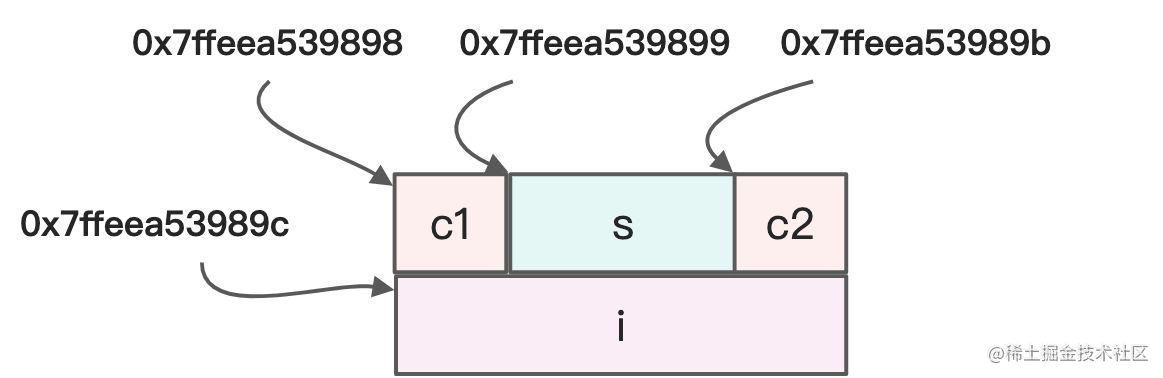
所以说,__attribute__ ((__packed__)) 的主要目的就是不进行内存填充,这样,sds 就可以安全地用指针前后移动的方式,获取到指定字段值,而不用担心指针前后移动的过程中,碰到填充的空白字节。在介绍 flags 字段的时候,我们就会看到 sds 是如何通过指针移动来确定自身类型的,你也可以在阅读下面这部分内容时,仔细体会一下 __attribute__ ((__packed__)) 的作用。
你有没有关注到 sds 中的 flags 呢?
既然内存对齐能够帮助我们更快地读取数据,那为什么 Redis 不进行内存对齐呢?这个就跟我们 sds 里面的结构有关了。
我们来关注一下 flags 这个字段。
它是个 8 位的 char 类型,其实里面只用了低 3 位来保存字符串的类型,0、1、2、3、4 分别对应了 sdshdr5 到 64 这五个 sdshdr 结构体。小伙伴们可能会问,为啥要用个 flags 来标识类型呢?不是已经分了五个 sds 类型吗,直接通过结构体的类型区分不就好了?
这是因为 Redis 在 5 个 sds 结构体上层,又封了一层,在 sds.h 里面,我们可以看到一行 typedef 代码,typedef 是 C 语言里面用来定义别名的,这里给 char 指针起了个别名,别名叫作 sds。
typedef char* sds;
好家伙,大名鼎鼎的 sds 居然只是一个 char 指针,那这个 char 指针指向哪里呢?其实指向的就是我们前面介绍的 5 种 sdshdr 中的一种 。比如我用 sdshdr8 来存储一个字符串,那 sds 指向的就是 sdshdr8 实例里面,buf 数组的起始位置,就是这种结构:
Redis 使用字符串的时候,都是使用的 sds 这个指针。Redis 只需要从 sds 指针往前找一个字节,就可以拿到这个 flags 值,通过读这个 flags 的低三位值,Redis 就可以知道当前的这个 sds 实例,是 5 种类型的哪一种。比如,图里面的 flags 低三位是 1,那就是 sdshdr8,这样也就确定了 len 和 alloc 的具体长度都是 8 位。接下来 Redis 就可以继续往前读数据,拿到 len 和 alloc 值。根据这两个值,我们就可以从 sds 指针往后的位置,读写 buf 数组了。
sds 指针和 5 个 sdshdr 结构体之间的关系,是不是有种 Java 里面接口和实现类的感觉?sds 像是个接口,sdshdr8 这些结构体是具体实现。
好,说明白了 flags 字段的作用,其实我们也就明白了,为什么 Redis sds 不进行内存对齐了,对吧?因为 sds 这个指针要向前读取 flags、len、alloc 这些值,要是读到空白字符,就跪了。必须要让这些字段紧凑连在一起,才能实现刚才说的这种效果。
sdshdr5 真的没用吗?
最后来看一个前面留下的坑,前面并没有提到 sdshrd5 这个结构体。小伙伴们可以看一下 Redis 源码对 sdshdr5 结构体的注释里面,其中有这样一句话 Note: sdshdr5 is never used,翻译过来是说 “sdshdr5 没有被使用”,真的是这样吗?
先说结论:并不是没用!Redis 里面 Key 都是字符串,Key 小于 32 个字节的时候,会用 sdshdr5;value 的话,即使小于 32 字节,也会用 sdshdr8。
这主要是因为我们的 Key 是不变的,而 Value 值呢,可能会经常变化,sdshdr5 可能很快就发生扩容了。我们在后面详细介绍字符串编码的时候,会详细说明这个地方的实现逻辑。
这里还有一个要说明的地方。我们来看 sdshdr5 这个结构体的代码,它为了节省空间,并没有再单独搞个 len 字段,而是用了 flags 字段的高 5 位来存了 len 字段,也就是字符串的使用长度。它里面也没有再搞个 alloc 字段出来,总之,就是为了省内存。
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; // 低3位存sdshdr的类型,高5位存储len信息
char buf[];
};
总结
在这一节课中,我主要是带小伙伴们逛了一下 Redis sds 的核心实现。
这里我再帮小伙伴们梳理一下本节课的核心思路。
- 首先,我们一起分析了一下 Redis 自定义字符串的三个主要原因,然后深入到 Redis 的源码中,介绍了 Redis 中 5 个核心 sds 结构体的定义,它们分别负责抽象不同长度的字符串。
- 接下来,我们深入解析了 sds 结构体的一些特性,例如,sds 结构体会禁止内存对齐,sds 指针指向的实际是 buf 字段的第一个字节,通过指针迁移得到 flags 字段才能判断当前 sds 的类型。
- 最后,我们专门介绍了 sdshdr5 结构体,说明了它只会在 Key 中使用。
下一节课我将带领小伙伴们继续分析 Redis sds,着重分析 Redis sds 的核心方法实现。
说透 Redis 7 - 杨四正 - 掘金小册核心原理剖析+源码解读+实践应用,全方位带你吃透 Redis 7。「说透 Redis 7」由杨四正撰写,979人购买![]() https://s.juejin.cn/ds/kaY9xnj/
https://s.juejin.cn/ds/kaY9xnj/









![[机器视觉]目标检测评价指标及其实现](https://img-blog.csdnimg.cn/f74a9f3d532647aebc9d079c4030b8d2.png)