HashMap的扩容原理
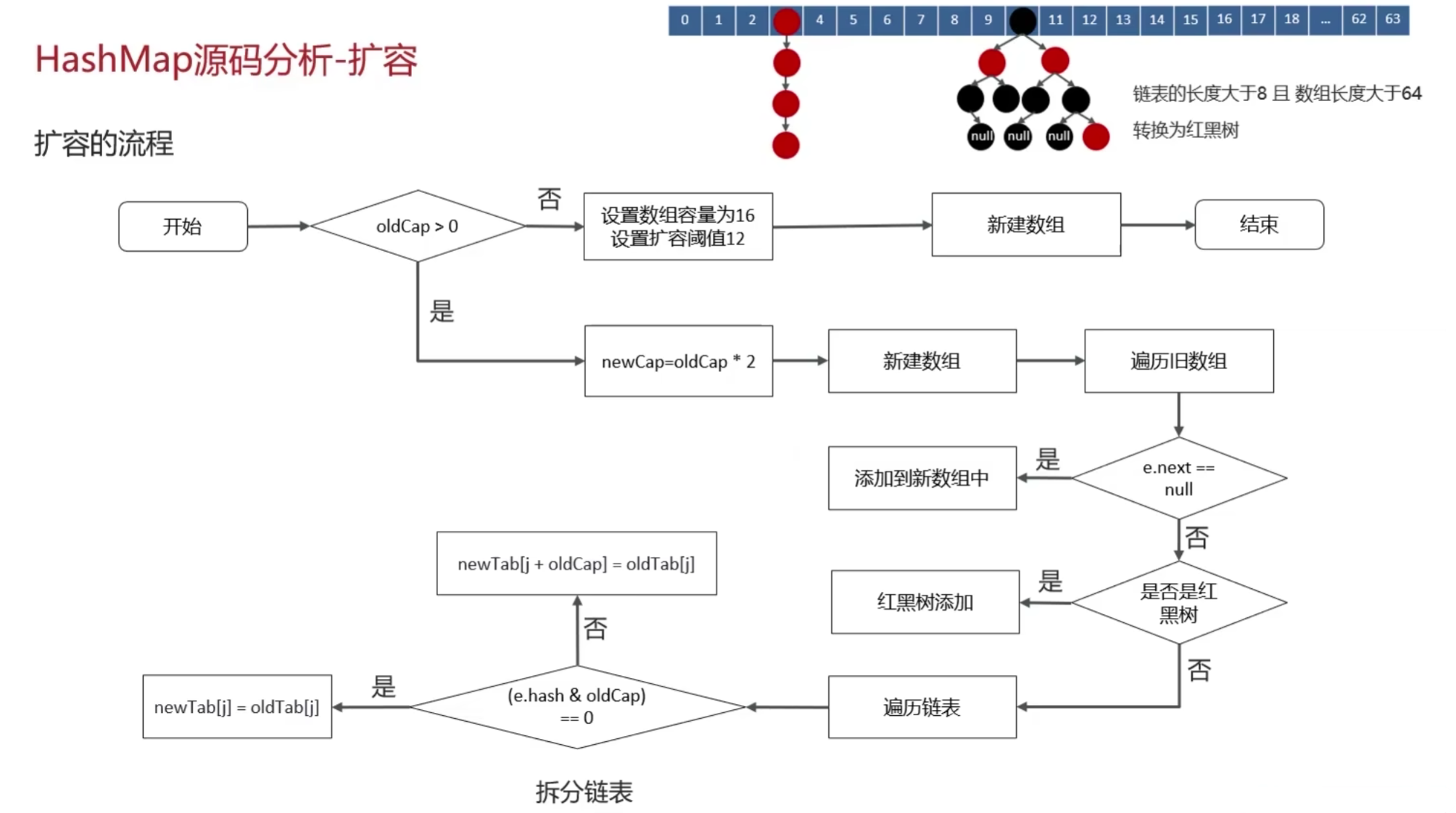
1.扩容流程图
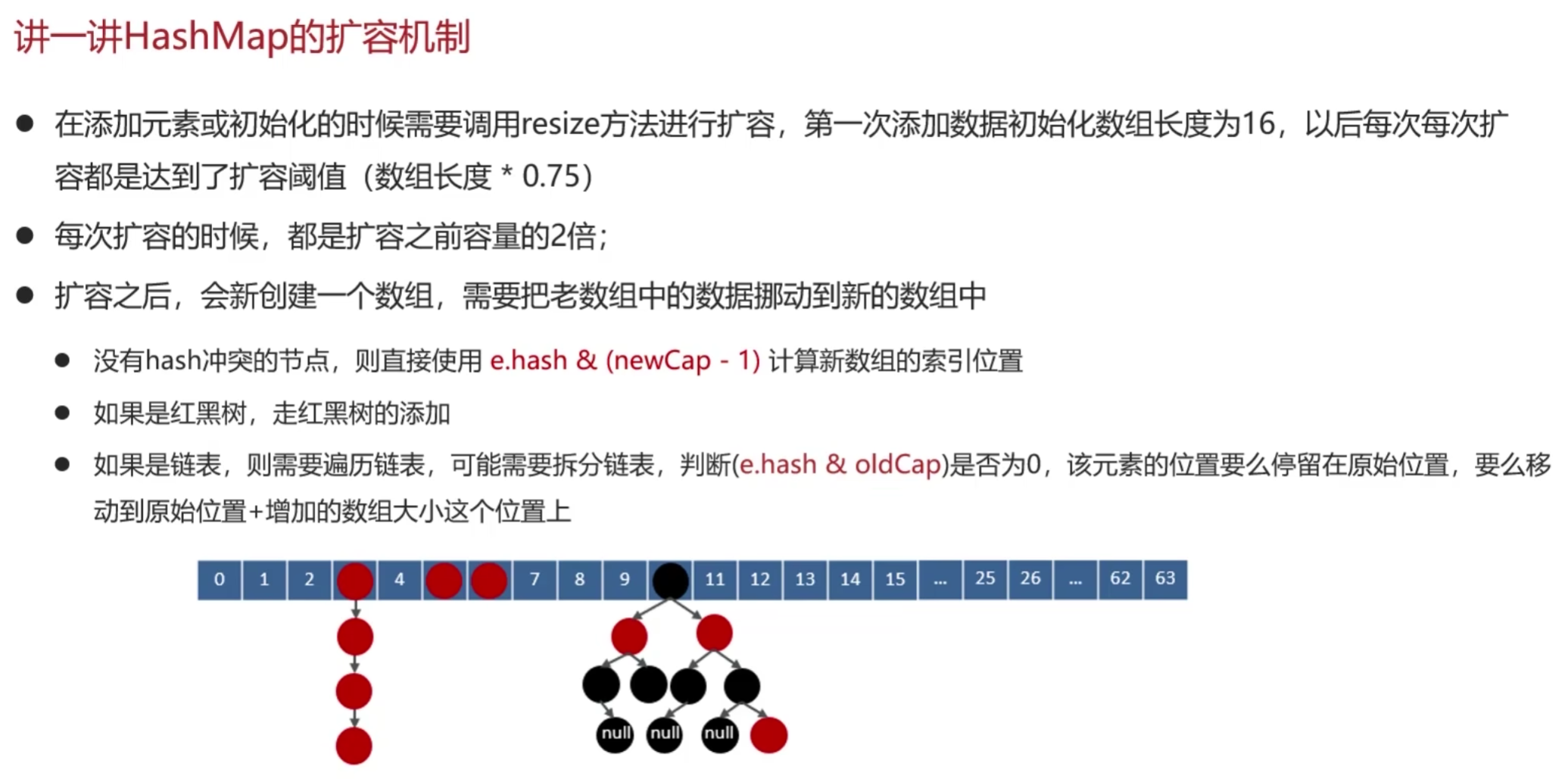
注:拆分链表的规则
这里拆分链表时的一个比较:e.hash & oldCap == 0 意思是:某一个节点的hash值和老数组容量求&运算。如果等于0,当前元素在老数组中的位置就是在新数组中的位置。如果不等于0,它存储的位置是:原来老数组中的位置 + 老数组容量。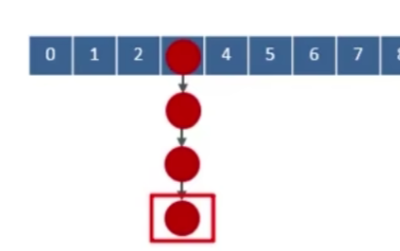
例:假设老数组容量是16,新数组就是32
现在要拆分标明的这个节点,该点在老数组中的位置是3。如果该点的hash & oldCap == 0。则把该点挂在新数组的也是3的位置。如果不为0,则挂在 3 + 16 = 19 的位置。
2.扩容源码分析(有注释) jdk8
//扩容、初始化数组
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
//如果当前数组为null的时候,把oldCap老数组容量设置为0
int oldCap = (oldTab == null) ? 0 : oldTab.length;
//老的扩容阈值
int oldThr = threshold;
int newCap, newThr = 0;
//判断数组容量是否大于0,大于0说明数组已经初始化
if (oldCap > 0) {
//判断当前数组长度是否大于最大数组长度
if (oldCap >= MAXIMUM_CAPACITY) {
//如果是,将扩容阈值直接设置为int类型的最大数值并直接返回
threshold = Integer.MAX_VALUE;
return oldTab;
}
//如果在最大长度范围内,则需要扩容 OldCap << 1等价于oldCap*2
//所以每次扩容就是原来的两倍
//运算过后判断是不是最大值并且oldCap需要大于16
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold 等价于oldThr*2
}
//如果oldCap<0,但是已经初始化了,像把元素删除完之后的情况,那么它的临界值肯定还存在, 如果是首次初始化,它的临界值则为0
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
//数组未初始化的情况,将阈值和扩容因子都设置为默认值
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;// 默认容量16
// 默认加载因子 * 默认容量 = 16 * 0.75 = 12
// 阈值,超过就触发扩容逻辑
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
//初始化容量小于16的时候,扩容阈值是没有赋值的
if (newThr == 0) {
//创建阈值
float ft = (float)newCap * loadFactor;
//判断新容量和新阈值是否大于最大容量
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
//计算出来的阈值赋值
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
//根据上边计算得出的容量 创建新的数组
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
//赋值
table = newTab;// table就是我们存储数据的数组!
//扩容操作,判断不为空证明不是初始化数组
if (oldTab != null) {
//遍历数组
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
//判断当前下标为j的数组如果不为空的话赋值个e,进行下一步操作
if ((e = oldTab[j]) != null) {
//将数组位置置空
oldTab[j] = null;
//判断是否有下个节点
if (e.next == null)
//如果没有,就重新计算在新数组中的下标并放进去
newTab[e.hash & (newCap - 1)] = e;
//有下个节点的情况,并且判断是否已经树化
else if (e instanceof TreeNode)
//进行红黑树的操作
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
//有下个节点的情况,并且没有树化(链表形式)
else {
//比如老数组容量是16,那下标就为0-15
//扩容操作*2,容量就变为32,下标为0-31
//低位:0-15,高位16-31
//定义了四个变量
// 低位头 低位尾
Node<K,V> loHead = null, loTail = null;
// 高位头 高位尾
Node<K,V> hiHead = null, hiTail = null;
//下个节点
Node<K,V> next;
//循环遍历
do {
//取出next节点
next = e.next;
//通过 与操作 计算得出结果为0
if ((e.hash & oldCap) == 0) {
//如果低位尾为null,证明当前数组位置为空,没有任何数据
if (loTail == null)
//将e值放入低位头
loHead = e;
//低位尾不为null,证明已经有数据了
else
//将数据放入next节点
loTail.next = e;
//记录低位尾数据
loTail = e;
}
//通过 与操作 计算得出结果不为0
else {
//如果高位尾为null,证明当前数组位置为空,没有任何数据
if (hiTail == null)
//将e值放入高位头
hiHead = e;
//高位尾不为null,证明已经有数据了
else
//将数据放入next节点
hiTail.next = e;
//记录高位尾数据
hiTail = e;
}
}
//如果e不为空,证明没有到链表尾部,继续执行循环
while ((e = next) != null);
//低位尾如果记录的有数据,是链表
if (loTail != null) {
//将下一个元素置空
loTail.next = null;
//将低位头放入新数组的原下标位置
newTab[j] = loHead;
}
//高位尾如果记录的有数据,是链表
if (hiTail != null) {
//将下一个元素置空
hiTail.next = null;
//将高位头放入新数组的(原下标+原数组容量)位置
newTab[j + oldCap] = hiHead;
}
}
}
}
}
//返回新的数组对象
return newTab;
}小结





![[管理者与领导者-163] :团队管理 - 高效执行力 -1- 高效沟通的架构、关键问题、注意事项](https://img-blog.csdnimg.cn/direct/364a6da3aa4e4fe2affb311e89c33c71.png)