文章目录
- 一、Synchronized原理
- 加锁过程
- 锁消除
- 锁粗化
- 二、线程安全的集合类
- 多线程环境使用ArrayList
- 多线程环境使用队列
- 多线程环境下使用哈希表
一、Synchronized原理
我们表面看到的,两个线程针对同一对象加锁,就会产生阻塞等待,但实际我们的Synchronized有许多特性,以及内存实现的一些优化机制。
1.刚开始的时候是乐观锁,如果锁冲突较大,就转换为悲观锁
2.刚开始是轻量级锁,如果锁被占有的时间较长,就转换为重量级锁
3.实现轻量级锁大概率会用到自旋锁策略
4.是一种可重入锁
5.是一种不公平锁
6.不是读写锁
加锁过程
我们的JVM将Synchronized锁分为以下状态: 无锁,偏向锁,轻量级锁,重量级锁,会根据锁冲突的情况,依次进行升级。
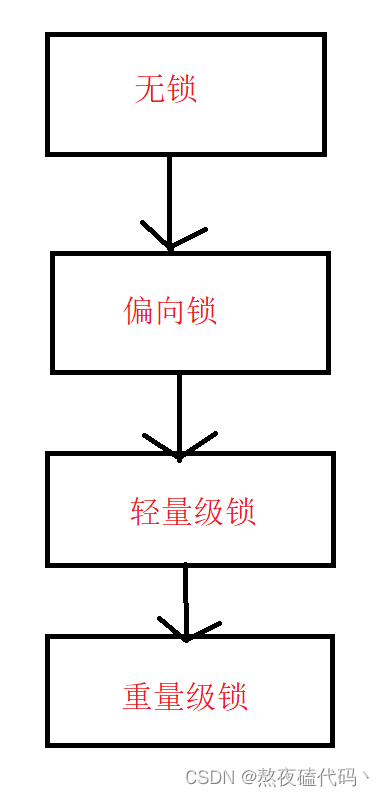
当我们使用Synchronized的时候,我们优先会进入偏向锁的状态。
偏向锁: 偏向锁并不是真正的加锁,只是在对象头中做一个标记(并没有加锁,这个操作比加锁轻许多),如果在执行代码过程中,并没有其他线程来尝试加锁,那么在执行完Synchronized之后,取消偏向锁。如果有其他线程来尝试加锁,我们会将偏向锁升级为轻量级锁。
我们的Synchronized采取偏向锁这一操作也很好理解,加锁是有一定开销的,我们能不加就不加,但是标记还是得做,用来判断合适升级为轻量级锁。
轻量级锁:随时锁竞争,我们的Synchronized从偏向锁转为轻量级锁(自旋锁),基于CAS实现的。
如果其他的线程很快的释放锁,那么我们的自旋锁是非常合适的,因为并没有阻塞等待,而且一直尝试获取锁,但是如果其他线程长时间占用锁,那么我们自旋是十分的浪费CPU资源的,大概率我们Synchronized在自旋过程中,内部有一个计数器来记录我们自旋了多少次,自旋达到一次的次数我们就会升级为重量级锁。
重量级锁(挂起等待锁): 当我们自旋不能快速获取到锁时,就会升级为重量级锁。
这里会使用到我们内核提供的互斥锁mutex 的一组API,操作系统内核提供的加锁功能,如果我们发生了锁竞争,我们的线程就会被放到阻塞队列中,不参与CPU调度,当锁被释放了之后,线程才有机会被调度,因为调度是随机的,所以它有机会获取到锁。
锁消除
这个也很好理解,在一些不需要加锁的场景下,我们加锁了,编译器和JVM会判断我们的锁是否可以消除,如果可以消除,直接就消除了。
比如我们String提供了StringBuffer和StringBuilder,StringBuffer是线程安全的,在方法中加了Synchronized,但是当我们在单线程操作下,不会涉及到线程安全问题,所以我们编译器会直接将锁消除掉。
锁粗化
锁的粒度: Synchronized代码块所包含代码越多,锁的粒度越粗,包含的代码越少,锁的粒度越细。
正常情况下,我们希望锁的粒度越细越好,因为我们加锁的代码是不能够并发执行的。
但有一些情况下,我们锁的粒度粗一点越好。
我们两次加锁解锁的时间间隙非常小,分开加锁会造成额外的加锁解锁的时间开销,而且中间间隙很小,就算并发效果也不是很明显,这里还不如直接搞一把大锁。
这个举一个例子:
我们过年在房间吃花生,会剥皮,但是垃圾桶在客厅,我们现在有两种方案,第一种,剥一个花生,就去客厅扔一下皮,第二种,我们先把皮放在卫生纸上,等积攒一部分再去客厅扔,我们扔皮这个操作就相当于加锁。
二、线程安全的集合类
我们的集合类中,大部分都是不安全的,也有一些是安全的但是不建议使用,比如: Vector,Stack,HashTable,他们的关键方法都带有Synchronized。
我们举例说明如果在多线程环境下,使用线程不安全的集合。
多线程环境使用ArrayList
1.在我们认为会产生线程安全问题的地方加锁,Synchronized或者ReentrantLock都可以。
2.使用Collections.synchronizedList(new Arraylist),synchronizedList的关键方法都加了Synchronized.
3.使用CopyOnWritArrayList: CopyOnWrit (COW 简称:写时拷贝),简单的来说如果我们针对该ArrayList进行读操作,那么我们不做任何操作。如果我们进行写操作,那么我们就拷贝一份ArrayList,然后对新的进行写操作,如果在修改过程中有读操作,那么就去读旧ArrayList,当我们新的ArrayList写完了之后,让旧的指向新的(这个指向的操作相当于引用的赋值是原子的).
我们的COW的操作:
优点: 在读多写少的情况下,因为没有加锁操作,所以效率很高
缺点: 1. 如果我们的ArrayList存放的元素非常的多,那么我们会占用大量的内存空间
2. 我们的新写的数据不能被第一时间读取到。
多线程环境使用队列
| 队列 | 作用 |
|---|---|
| ArrayBlockingQueue | 基于数组实现的阻塞队列 |
| LinkedBlockingQueue | 基于链表实现的阻塞队列 |
| PriorityBlockingQueue | 基于堆实现的带优先级的阻塞队列 |
| TransferQueue | 最多只包含一个元素的阻塞队列 |
多线程环境下使用哈希表
我们的HashMap是线程不安全的,Hashtable是线程安全的,但是它直接在方法上加了Synchronized。
java为我们提供了优化了的线程安全的哈希表:ConcurrentHashMap
这里我们需要着重了解: ConcurrentHashMap与Hashtable的区别是什么?
1.最大的优化:ConcurrentHashMap 相比于 Hashtable大大缩小了锁冲突的概率,将一把大锁准换为多把小锁。
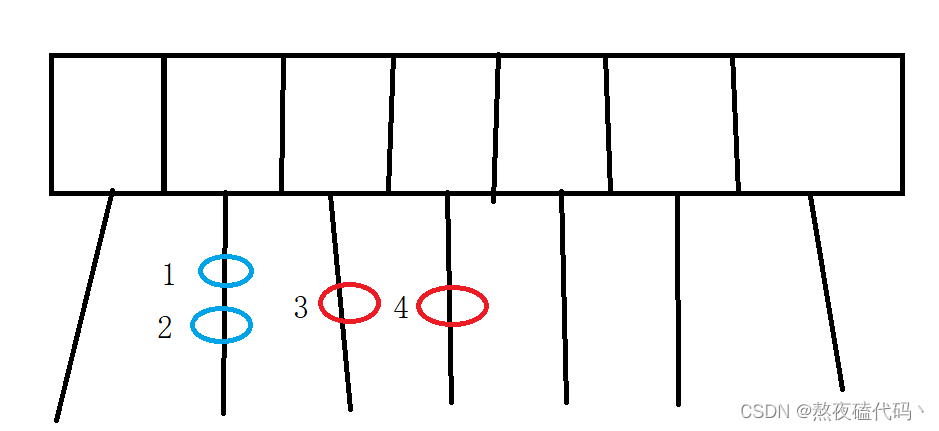
我们的哈希表中,元素1,2是在同一条链表上,如果线程一去操作(修改,删除等)元素1,线程二去操作(修改,删除等)元素2,是否有线程安全问题?
如果我们的1,2是相邻的,如果我们进行了插入或者删除操作,那么这两结点的next指向就会发上改变。
如果我们的线程一去操作元素3,线程二去操作元素4,存在线程安全问题吗?
因为我们的元素3和元素4,是存于不同的链表中,相当于我们的多线程同时修改不同的变量,是不存在线程安全问题的,所以这个情况我们情况不需要加锁的。
我们的Hashtable是直接加了一把大锁,相当于只要两个线程去操作哈希表,即使是不同链表上的元素,也是不允许的。
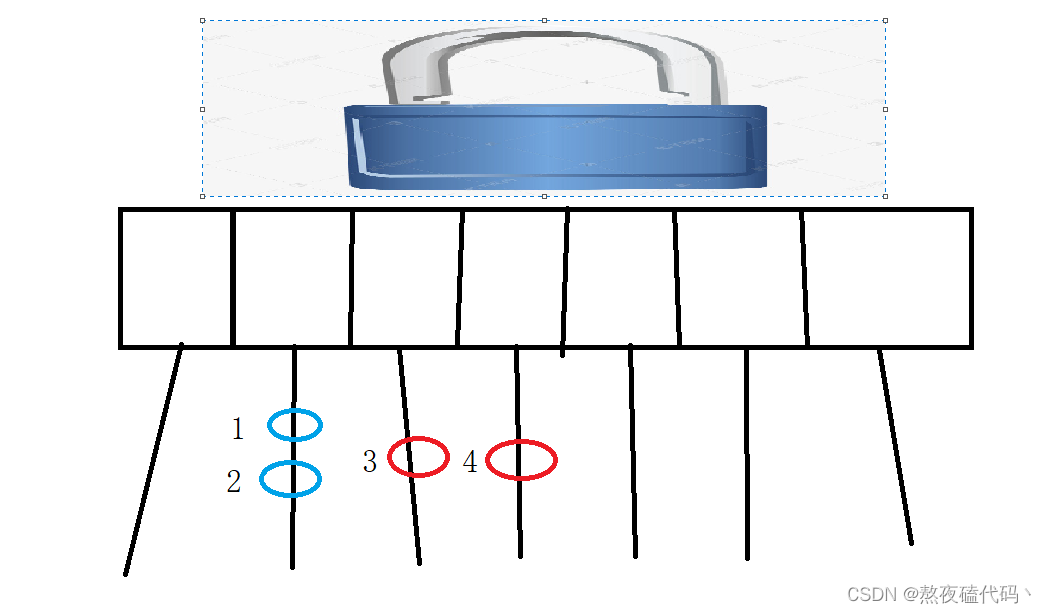
ConcurrentHashMap为我们每一条链表提供了一把锁,每个链表的头结点作为锁对象,大大降低了锁冲突的概率。
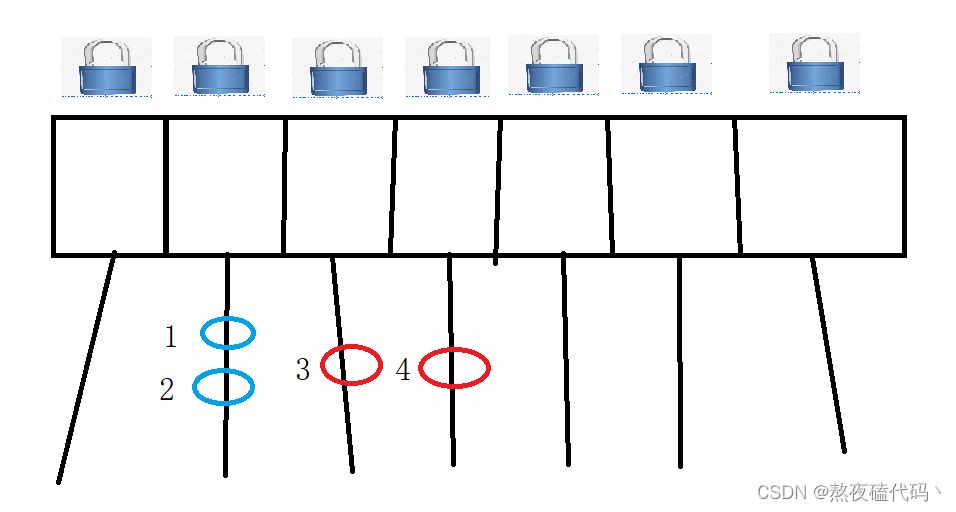
我们锁的粒度变小了。
当我们不同线程操作1 2 时,是针对同一把锁,会产生锁竞争,保证线程安全。
当我们不同线程操作3 4 时,是针对不同的锁进行加锁,所以不会产生锁竞争。
我们的JDK1.8之前,ConcurrentHashMap使用的是分段锁。
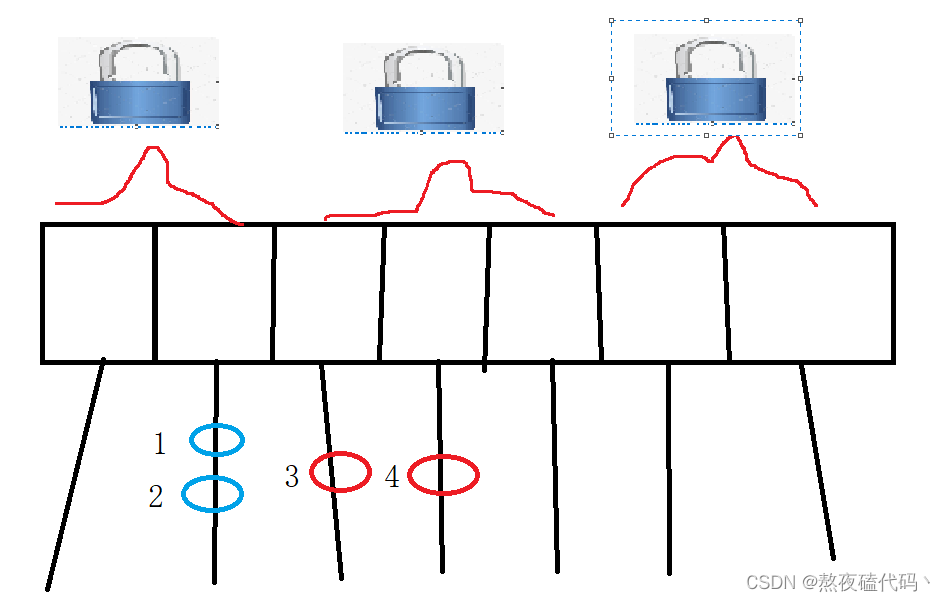
我们的分段锁的本质也是缩小锁的范围,来降低锁冲突的概率,但是不够彻底,粒度还是不够细,而且实现起来也更麻烦。
2. ConcurrentHashMap只对写加锁,针对读操作不加锁。
我们的读操作没有进行加锁,而是使用了volatile来保证我们每次都是从内存读取的结果,只针对写操作加锁,加锁仍然是使用"桶锁"(针对每个链表加锁,降低了锁冲突的概率)。
3.ConcurrentHashMap内部充分利用CAS特性,来减少加锁的操作,比如通过CAS来维护size属性
4.针对扩容操作,采取了"化整为零"的策略
我们的HashMap和Hashtable扩容这一操作,是直接创建一个新数组,然后将旧的数组上的每个元素搬到新数组上,但是如果我们哈希表中的元素特别多时,当我们某一次进行put时,会突然感到十分的耗时。
我们ConcurrentHashMap这里采取的策略是: 创建一个新的数组,每次只搬运一小部分,当进行put操作时,直接往新数组上添加,同时搬运一部分旧的元素到新数组上,当进行get操作时,新旧数组都进行查询,当进行remove操作时,新旧数组先查询,查询到了直接进行删除即可,当我们所有元素都搬运好了之后,然后在释放旧数组。
** Hashtable和HashMap、ConcurrentHashMap 之间的区别?**
HashMap: 线程不安全,key允许为Null
Hashtable: 线程安全,并且key不允许为Null,每个方法使用Synchronized加锁
ConcurrentHashMap: 线程安全,并且key不允许为Null,使用Synchronized锁每个链表的头结点元素,降低锁冲突概率,充分利用了CAS机制,优化了扩容机制,采用"化整为零"的策略。

![[Zombodb那些事]Zombodb与ElasticSearch的Bulk通信](https://img-blog.csdnimg.cn/img_convert/870876621cfadb4f557258d0c5b446fa.png)