Zombodb与ElasticSearch的Bulk通信
0.前言
Zombodb是一个PostgreSQL插件,使用rust编写,支持pg14以下版本。Zombodb可以允许PostgreSQL查询ElasticSearch中的内容。本篇为《Zombodb那些事》第一篇,后面将更新其他部分内容。
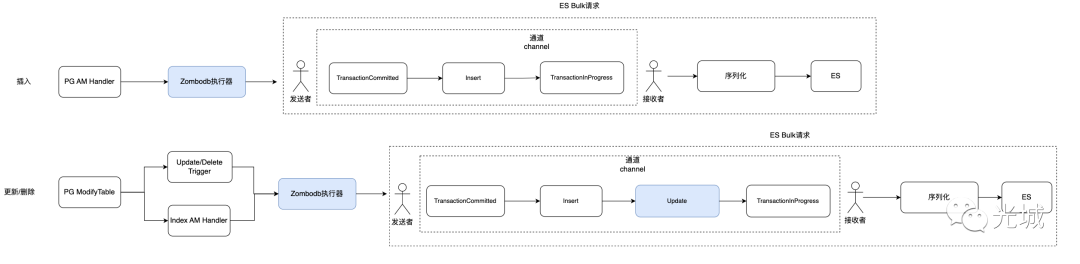
Zombodb会在pg数据库上创建Zombodb索引,当插入/删除/更新数据时在pg上执行的时候到底经历了什么过程呢?
例如:往foo表中插入一条记录,zombodb与es之间的通信是什么?
insert into foo (id) values (1);再比如:更新foo表中的一条记录,zombodb与es之间的通信是什么?
update foo set id = id where id = 1;同理,删除又做了什么呢?
当插入的数据比较大的时候,Zombodb是如何防止OOM?如何保证高性能的请求?又如何保证在用户取消执行SQL时,ES与数据库中的数据能够保持一致?
为了回答这些问题,便有了这篇文章。
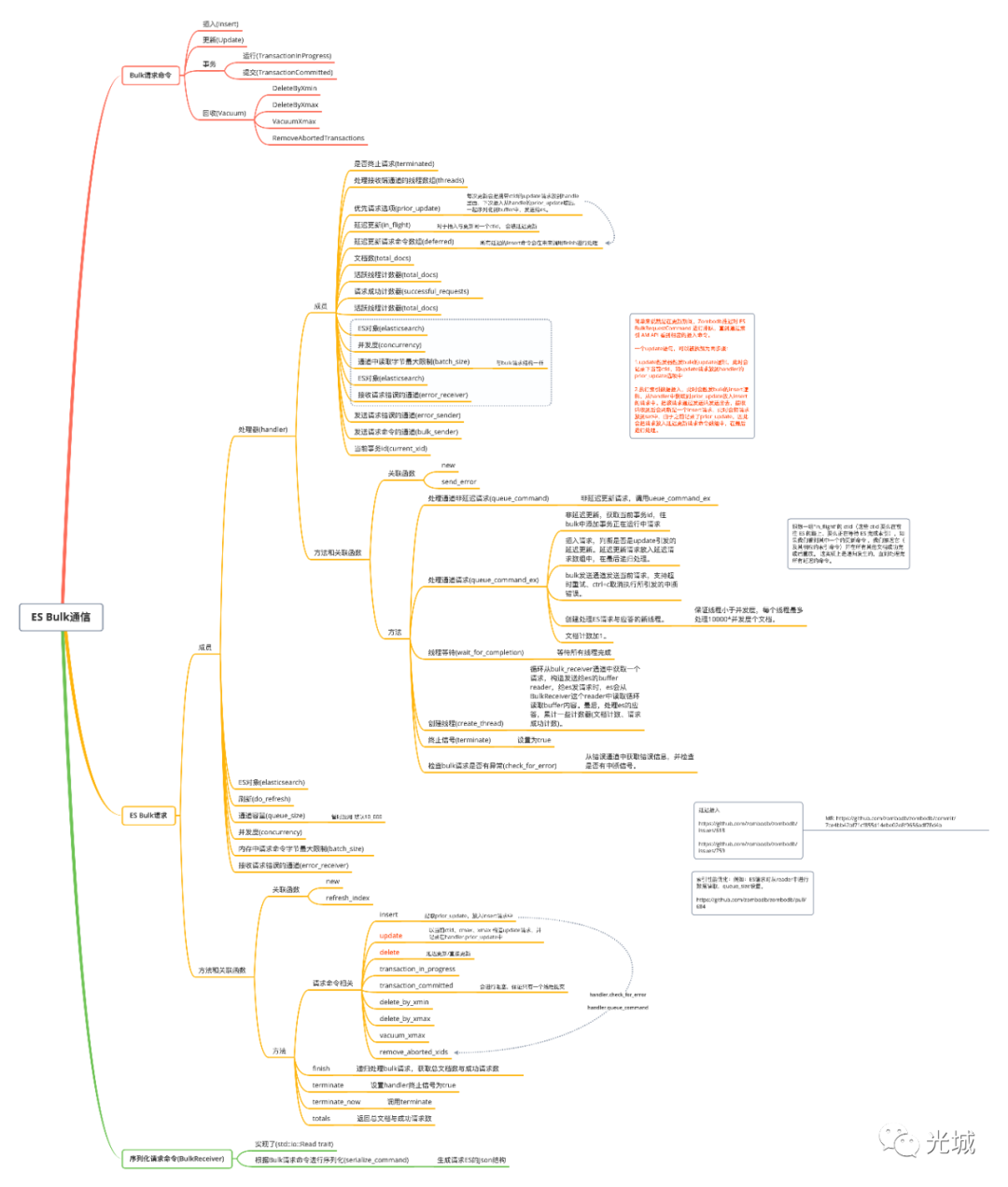
1.Bulk实现概要
在Zombodb中,bulk.rs实现了往ES发送Bulk请求,并处理应答。
Bulk内核层面,有三个结构体、一个枚举。
BulkRequestCommand Bulk请求命令枚举类型
ElasticsearchBulkRequest ES Bulk请求结构体
Handler 处理器结构体
BulkReceiver Bulk请求命令序列化Buffer结构体
首先来看Bulk请求命令:
// 伪代码
pub enum BulkRequestCommand<'a> {
Insert {ctid: u64, ...}
Update {...}
...
}
ES Bulk请求实现机制为委托设计模式,通过使用内部的handler处理器实现,而ES Bulk结构体本身是对外提供接口,例如:插入/更新/删除等操作。

ES Bulk本身内容详细的来说:
处理器
是ES Bulk请求的处理器,在内部会创建发送端与接收端通道,
ES Bulk请求结构体会把前面准备好的Bulk请求命令通过发送端通道发出去,同时创建多个线程,每个线程会通过接收端通道从通道中循环读取每一个Bulk请求命令,随后发给ES,对ES的应答进行处理。当然处理器的工作是比较复杂的,这里只是简单的说了一下工作原理,后续会详细阐述。
ES对象
ES对象会在后面的内核分析中讲解这一块内容,本节不做额外说明,简单理解为给ES直接打交道的对象,例如:给es发送mapping请求、setting请求、刷新请求等等。
在这里ES对象主要的作用在于:刷新索引(refresh操作)、给ES发送请求。
刷新
---immediate策略 CREATE INDEX idxtest ON test USING zombodb ((test.*)) WITH (url='http://localhost:9200/', refresh_interval='immediate'); ---other策略,zombodb会把5s传递给索引设置项_settings CREATE INDEX idxtest ON test USING zombodb ((test.*)) WITH (url='http://localhost:9200/', refresh_interval='5s');对应ES的refresh操作,此处为布尔值,表示是否进行刷新,如果进行刷新,会获取用户在创建索引时的刷新策略,此处有三个值:immediate、async、other。表示立刻刷新、异步刷新、不做刷新操作(这个策略下ES会在后台自动刷新)。refresh_interval是一个GUC值,默认是-1,跟immediate等价,下面是两个例子。
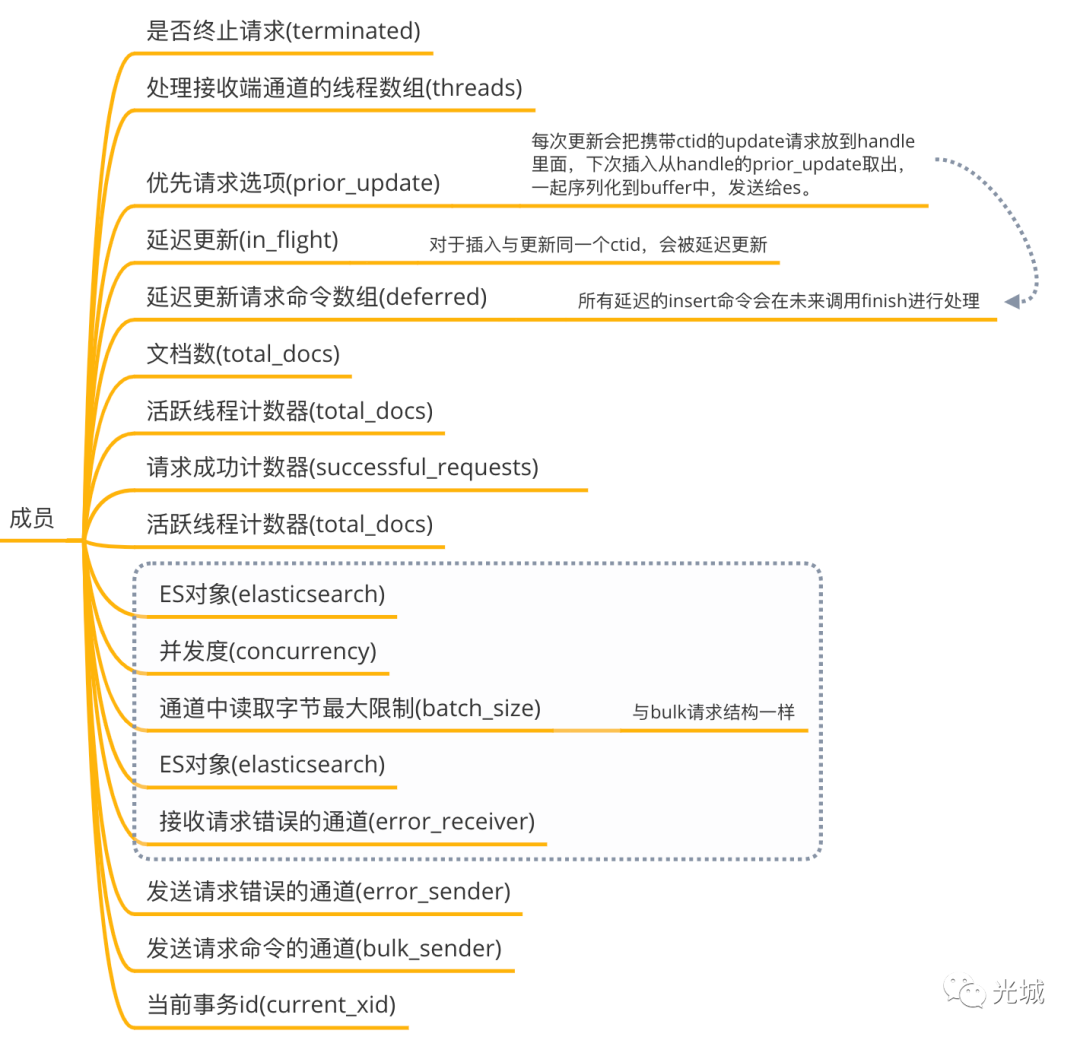
并发相关
queue_size通道容量并没有使用,估计是Zombodb的bug,上游传递的是10_000,代码里面多处写了这个字面量,估计是没替换成这个变量。
concurrency并发度,从ES的shards、CPU核心数、用户指定的并发度取最小值。
CREATE INDEX idxevents ON events USING zombodb ((events)) WITH (bulk_concurrency=2); batch_size内存中请求命令字节最大限制,在给ES发起bulk请求之前,会从BulkReceiver(是一个reader)读取数据,由于数据可能比较大,例如:插入一篇非常多文字的文章,Zombodb实现了std::io::Read ,在读取的时候可以拿到每次读取字节的偏移量,下次接着读。但是,BulkReceiver中会有个接收端通道,每次从对象中缓存的请求命令进行读取。如果取不出来,则从handler的接收端通道读取,此时可能会出现OOM的问题,batch_size是用来控制每次读取的最大限制。
error_receiver为接收请求错误的通道,处理器handle在遇到错误时,会通过handler的error_sender发送错误信息,error_receiver则会从通道中接收错误信息。
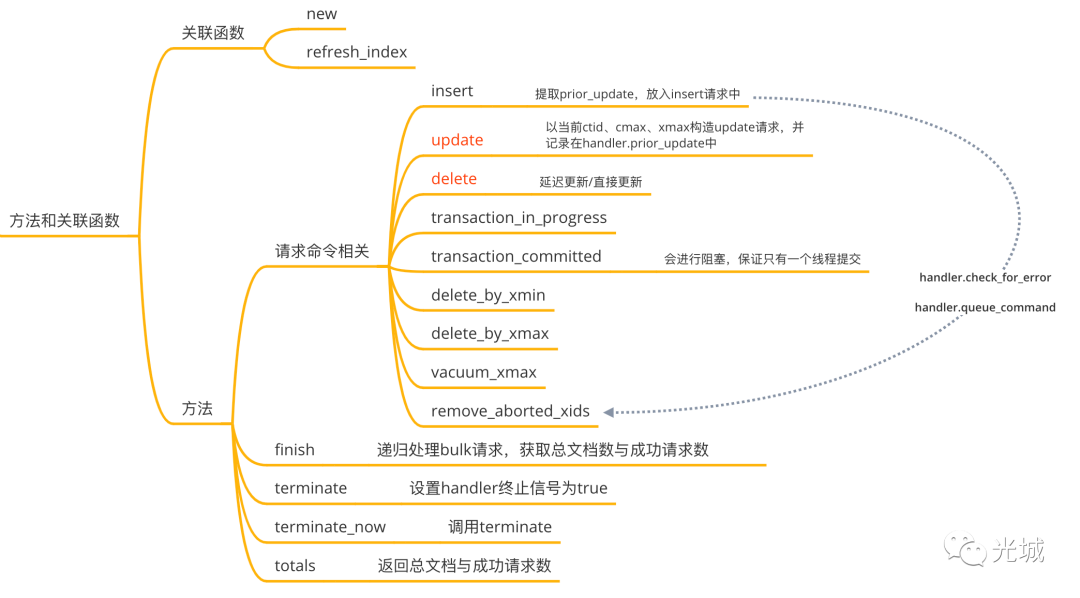
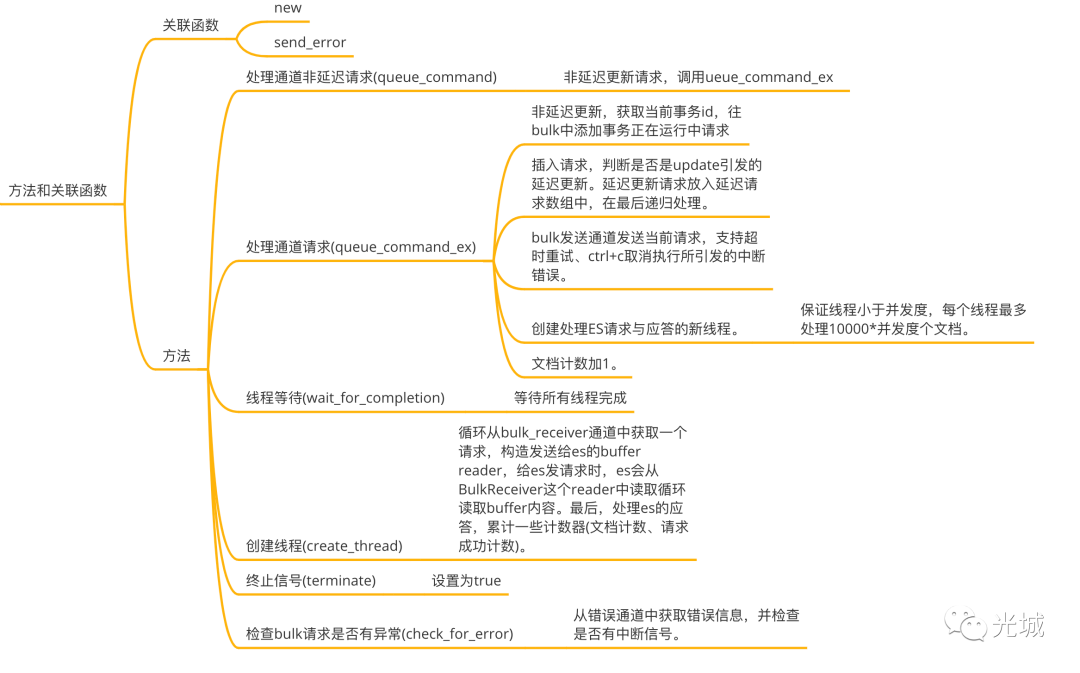
2.处理器Handler
在上面一小节提到ES Bulk对外的接口会通过调用内部的handler来完成相应的功能,因此最核心的内容为handler的相关操作,一起来看看handler里面包含了什么内容,又是怎么实现并发控制、ES请求。
在Zombodb内部会将请求划分为:
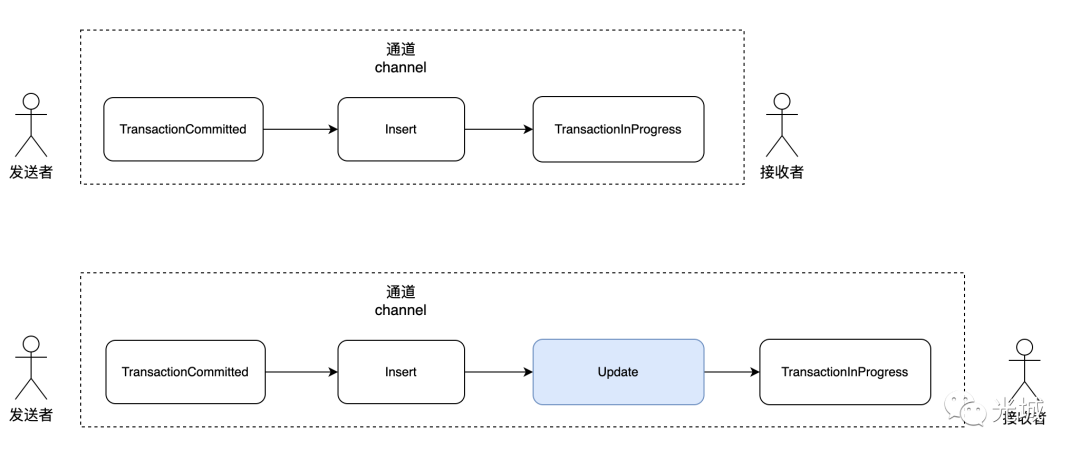
非延迟请求
insert into foo (id) values (1);这种请求比较简单,handler直接收到insert的command后,此时调用queue_command(false),将请求命令发送出去,接收端收到之后根据请求过来的command序列化到buffer中,发送给ES,处理应答结果。
延迟请求
update foo set id = id where id = 1;延迟请求比较有意思了,简单来说就是在更新期间,Zombodb推迟对 ES BulkRequestCommand 进行排队,直到通过索引 AM API 看到相应的插入命令。
一个update语句,可以被拆解为两步骤:
1.update触发器触发bulk的update逻辑,此时会记录下当前ctid,将update请求放到handler的prior_update选项中。
2.执行索引数据插入,此时会触发bulk的insert逻辑,从handler中获取到prior_update放入insert的请求中。把该请求通过发送端发送出去(通过调用queue_command(false))),接收端收到后会判断是一个insert请求,此时会将请求放到set中,由于之前记录了prior_update,因此会把请求放入延迟插入请求命令数组中(调用queue_command_ex(is_deferred=true)),再最后进行处理。
handler中最核心的工作是通过queue_command来实现的,queue_command会去调用queue_command_ex,只不过queue_command处理非延迟请求,queue_command_ex可以通过是否延迟请求参数控制。
pub fn queue_command(
&mut self,
command: BulkRequestCommand<'static>,
) -> Result<(), crossbeam_channel::SendError<BulkRequestCommand<'static>>> {
self.queue_command_ex(command, false)
}
pub fn queue_command_ex(is_deferred: bool)
}queue_command_ex中操作如下:
非延迟插入,获取当前事务id,将xid放入
Zombodb执行器(后续文章说明)的数组中,通过执行器的es对象发起transaction_in_progress请求命令,回调queue_command。插入请求会放入延迟插入通道中。
bulk发送通道发送请求命令,此时支持超时重试、执行sql时的ctrl+c中断响应。
创建bulk接收通道的线程,用来将刚才的请求对象序列化ES Json字节流,ES应答包处理。
文档数加1。
以一个实际插入为例,此时为非延迟插入请求。
insert into foo (id) values (1);
第一次通道中放入事务正在运行的命令:
TransactionInProgress {
xid: 856,
}第二次通道中放入实际插入的数据命令:
Insert {
prior_update: None,
ctid: 1,
cmin: 1,
cmax: 1,
xmin: 865,
// xmax: u64, 此时没 xmax
builder: JsonBuilder<'a>, // 插入的一条记录json格式
}第三次通道中放入事务提交的命令
TransactionCommitted {
xid: 865,
}那如果换成延迟插入请求:

update foo set id = id where id = 1;第一次通道中放入事务正在运行的命令:
TransactionInProgress {
xid: 866,
}第二次通道中放入更新命令:这里是由更新触发触发器调用。
Update {
ctid: 1,
cmax: 1,
xmax: 866,
}第三次通道中放入实际插入的数据命令:
Insert {
prior_update: None,
ctid: 2,
cmin: 1,
cmax: 1,
xmin: 866,
// xmax: u64, 此时没 xmax
builder: JsonBuilder<'a>, // 插入的一条记录json格式
}第四次通道中放入事务提交的命令:
TransactionCommitted {
xid: 866,
}
handler中有如下成员,下面列的比较详细,就不多赘述了,延迟插入的实现是通过prior_update、in_flight、deferred这三个变量来实现。handler最本质的工作是将所有延迟插入的请求放入到deferred数组中,将创建的多个线程放入线程数组中,最后由ElasticsearchBulkRequest的finish递归处理:
延迟请求,调用queue_command_ex(true),递归调用finish,获取处理的总文档数与请求成功数
非延迟请求,直接调用wait_for_completion,等待所有线程完成,获取处理的总文档数与请求成功数。
当然在finish中还会去根据用户是否传递刷新索引选项来决定用何种策略去refresh ES。
3.序列化请求命令
在前面我们知道handler会创建通道,会把请求命令通过发送端发送出去,接收端收到进行处理,那么如何处理的?处理了哪些东西?
这就引入了BulkReciever结构,接收端通道得到的Bulk请求命令是一个枚举类型,并不是一个真正的数据,而给ES的请求必须是json格式,同时为了高效的传输数据,防止rust oom的问题,引入了这么一层抽象。
通过BulkReciever实现std::io::Read trait,根据不同的请求枚举命令,序列化出不同的json结构,这里的细节是放入了字节流数组中,读取的时候按照偏移量进行读取。

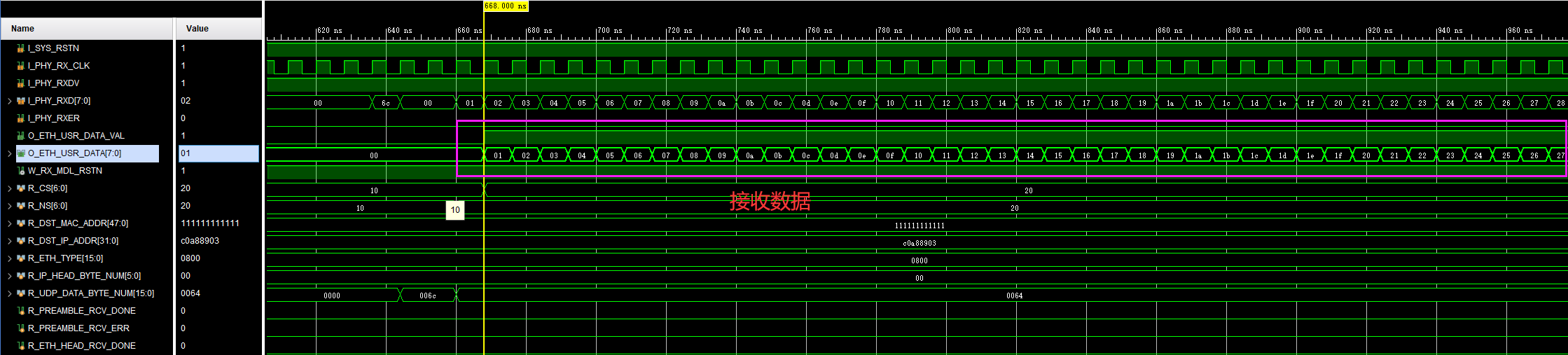
以最复杂的插入请求为例,由于上面提到的延迟请求更新问题,这里需要判断是否有延迟插入,如果有,先序列化一下,随后再序列化当前插入请求命令。
还是以上述的插入与更新为例,非延迟插入:
insert into foo (id) values (1);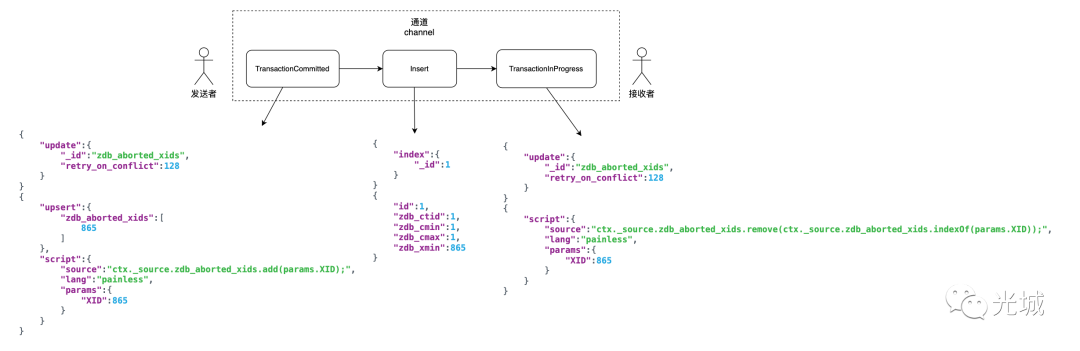
延迟插入:
update foo set id = id where id = 1;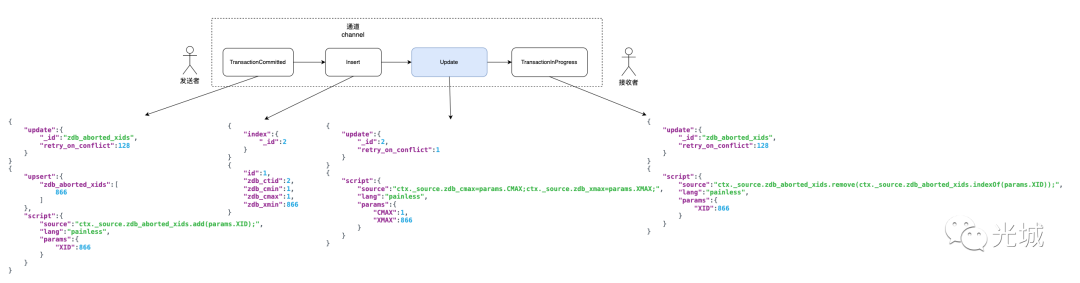
上面两图中的json串为BulkReciever所做的核心逻辑,根据不同的请求命令生成对应的Json串。
4.一些细节
实际实现层面,Zombodb解决了诸多问题,例如:性能问题、delete问题、延迟插入问题等等。
4.1 延迟插入问题
延迟插入的内容在前面也详细的阐述,它解决了HOT所带来的问题。相关issue:
https://github.com/zombodb/zombodb/issues/618
https://github.com/zombodb/zombodb/issues/759
MR:https://github.com/zombodb/zombodb/commit/7ce4bb42bf71cf855d14ebe02e8f9656adf78d4b
delete问题在上面759中有涉及到,复现SQL为:
BEGIN;
INSERT INTO cats VALUES (1, 'foo');
UPDATE cats SET value = 'bar' WHERE id = 1;
DELETE FROM cats WHERE id = 1;
COMMIT;由于早期的delete实现是直接把update请求放入通道中就完事了,但是如果在同一个事务中先Update再Delete,则会存在update es失败问题,这个问题主要的原因在于Zombodb做了延迟插入,例如:delete之前的update会先update再insert,在insert会被延迟,由于事务还未提交, es中是没有数据的,所以碰到delete的时候,直接更新就会update es失败。因此,现在ES Bulk请求的delete实现为:
if self.handler.in_flight.contains(&ctid) {
self.handler.deferred.push(command);
Ok(())
} else {
self.handler.queue_command(command)
}4.2 性能问题
索引性能优化:例如:ES请求时从reader中进行数据读取,queue_size设置等的代码被合入主干的MR为:
https://github.com/zombodb/zombodb/pull/684
在这个MR中提到了很多ES插入的优化点,例如:batch_size、queue_size、bluk容量等等,其实就是前面讲的内容。
在给ES发送请求后得到的回包也是经过cbor经过压缩,可以看到解析是由serde_cbor来做的,同时传递给es的url的format也是cbor。
{}/_bulk?format=cbor&filter_path={}