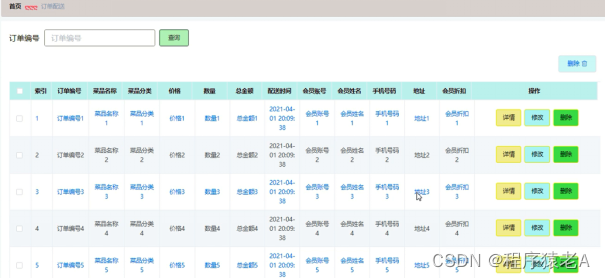
到目前为止,我们一直在说,我们得到一个 SQL 查询,我们希望可以解析它,将其转化为某种逻辑计划,然后生成我们可以用于执行的物理计划。而这正是查询优化器【Optimizer】的功能,对于给定的 SQL ,优化器的职责就是负责找出“成本【Cost】”最低且正确【Correct】的执行计划,该计划有最低的。
需要注意的是,“成本【Cost】”这个是一个相对的术语,他因人而异,对于我们,可能成本就是速度的别名,而对于某些领域,成本可能指的是减少网络消息的数量,降低能源消耗等等。
这是 DBMS 中最难实现的部分(已证明是 NP 完全的), 如果你擅长于此,你将获得 $$$ 报酬。
没有优化器【Optimizer】能真正产生“最优”的计划:
- 使用估算【estimation】技术来猜测实际的计划成本。
- 使用启发式【heuristics】来限制搜索空间。
1. 逻辑计划 vs 物理计划
优化器生成从逻辑代数表达式【logical algebra expression】到最佳等效物理代数表达式【physical algebra expression】的映射。
- 逻辑计划是对我们想要做的事情的高级描述,比如我要扫描一个表,
- 物理计划将代表我们将用来执行该逻辑操作的确切执行方法,比如我将使用索引在某字段上扫描,我们前面讲过操作符的迭代器模型或者向量模型,它们都是物理操作符的体现
物理操作符【Physical Operator】使用访问路径【Access Path】定义特定的执行策略。
- 它们可能取决于它们所处理的数据的物理格式(即排序【sorting】、压缩【compression】)。比如如果数据是按 order by 顺序排列的,那么我们可能就不需要排序了
- 从逻辑到物理并不总是 1:1 的映射。
下面是 SQL 在数据库系统内的高层次上的执行路径:

- Application:比如我们的Java应用,他们是数据库的使用者,它们想数据系统发送了一个 SQL 查询
- 在数据库系统内碰到的第一件事,可能就是 SQL Rewriter,他是可选择,并不是所有系统都有,它们通常会根据正则表达式对 SQL 作一些语法检查与重写
- 现在我们得到了一个 SQL 查询,我们将其送入解析器【Parser】,它会产出一个抽象语法树,其实就是 SQL 中的单词所组成的树结构,
- 接下来是 Binder,我们将获取 ast 中的这些单词【token】,并将它们实际映射到内部数据库对象,因此我们需要查看系统目录【System catalog】,比如我们现在碰到 from 后面跟着一些字符串,根据系统目录的解释,我们知道 from 之后的就是表名。所以当你收到表明不存在,或者列名不存在时,他就是在 Binder 阶段出现的。最终 Binder 输出一个逻辑计划。
- 接下来逻辑计划被送入 Tree Rewriter,很多系统都有这一节点,它也会从系统目录获取信息,比如我们的主键,外键,等等,来调整我们的逻辑计划,
- 最后,重写的逻辑计划被输出到优化器,优化器会从系统目录获取信息,而且也会从成本模型中获取数据 ,它会帮助我们预测某个查询计划可能的执行调用【execution calls】,最终它会产出成本最低的物理计划,就可以交给执行引擎去执行了。很多系统也称它为编译器【compiler】,都是一个东西。
注:本图中的优化器是一个基于成本的优化器,优化器还支持基于规则的。
住:Catalog中存储着关于数据的元数据,你可以将其认为是一个mini的数据库
2. 查询优化
2.1 如何进行查询优化
启发式/规则【Heuristics / Rules】:
- 重写查询【Query】以删除愚蠢/低效的东西。比如:始终先进行选择,或者今早下推谓词
- 这些技术可能需要检查目录【Catalog】,但不需要检查数据【data】。
基于成本的搜索【Cost-based Search】
- 使用模型来估计执行计划的成本。
-
为一个查询枚举多个等效计划【equivalent plans】,并选择成本最低的一个。
2.2 什么是逻辑计划优化【Logical Plan Optimization】
使用模式匹配规则将逻辑计划转换为等效逻辑计划。
目标是增加在搜索【search】中枚举最佳计划的可能性,基于成本查询会枚举出所有可能的查询计划,我们可以使用这些逻辑计划优化,来帮助我们走捷径,简而言之,就是它可以指导成本模型去只考虑那些我们知道可能会成为最优的查询计划,而不需要把时间花在那些愚蠢的计划上。
我们无法比较操纵前后或更改前后的计划,因为没有成本模型,但可以“引导”向首选方向进行转换。
3.启发式【Heuristics】/基于规则【Rule-Based】的优化【A】
假定我们有两张表,分别是 Emp 表,即雇员表,以及 Dep 表,即部门表
在 Catalog 中,对于这两张表,我们有如下的元数据:
- 黑色三角是聚簇索引列,空白三角是二级索引列
- Catalog 中维护着记录总数,以及占用的页面总数

下面是我们即将优化的 SQL 查询:

我们下面要做的就是针对查询计划做成本分析:

第一版优化,使用块嵌套循环【block nested loop】/页嵌套循环【page nested loop,Page NL】,来替换掉笛卡尔积:

第二版,我们可以使用排序归并连接,来替换块嵌套循环【block nested loop】算法:

第三版,
- 我们将选择谓词下推,使得连接【Join】是建立在选择谓词之上,这样我们就可以使用索引进行范围访问,
- Dep 表是要明显小的表,我们将其置换到左表,即外表位置上。
- 对于上述产出的输出表,我们可以使用内嵌循环索引连接【Nested Loop Index Join】

最终,我们有了这样一颗逻辑查询计划,但是我们不能将其发给执行引擎处理,因为他只是一份逻辑计划。
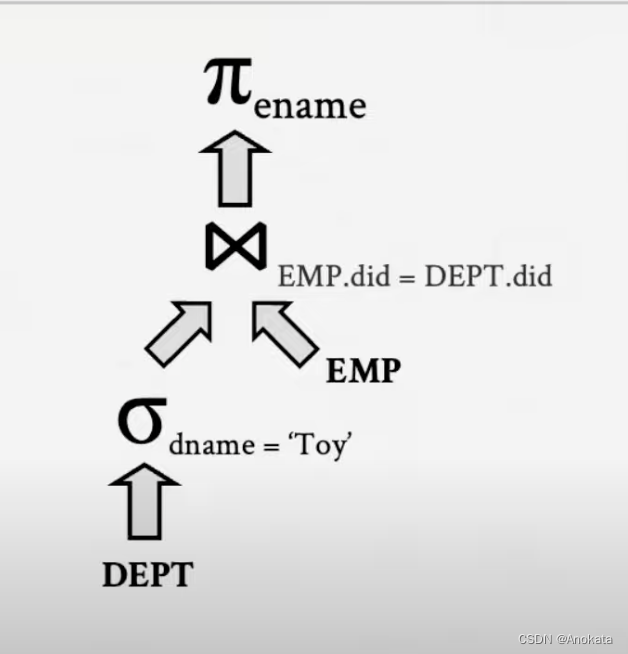
我们需要在其之上,像下图这样添加一些注释,它的意义是:
- 首先,我们使用查询Dept表,访问路径是:非聚簇的b树,并将数据通过管道发给后面的连接操作福
- EMP表则使用文件扫描的访问路径进行查询
- 接下来我们使用内嵌索引循环,来连接两个输入
- 最后通过简单的映射即可得到结果
因此,我们希望运行时系统执行的操作的详细信息都必须放入一个数据结构中,该数据结构能够捕获树以及所有红色的东西,然后发送到查询调度程序执行

3.1 Query Optimization (QO)
1. 确定候选等效树(逻辑)。 这是一个NP-hard 问题,所以空间很大。
2. 对于每个候选者,找到其对应的执行计划树(物理)。 我们需要估计每个计划的成本。
3. 选择最佳的整体(物理)计划。
但是实际上:DBMS 只是从所有可能的计划的子集中进行选择, 毕竟估计耗时也是有成本的。
3.2 规则优化
我们下面来总结一下常见的规则
3.2.1 谓词下推

在该规则中,我们不需要知道每个表中的数据,就可以应用规则,因为及早应用谓词,总会有效的。
3.2.2 替换笛卡尔积

3.2.3 映射下推

3.3 等价
下面是操作之间等价替换,两边的操作具有相同的语意,且是安全的。

3.启发式【Heuristics】/基于规则【Rule-Based】的优化【B】
常见的规则有:
- 拆分连接谓词【Split Conjunctive Predicates 】
- 谓词下推【Predicate Pushdown】
- 连接替换笛卡尔积【Replace Cartesian Products with Joins】
- 投影下推【Projection Pushdown】
需要注意的是,虽然规则会用到 Catalog,但是规则通常不需要关注数据,它们只是应用规则罢了。
3.1 拆分连接谓词【Split Conjunctive Predicates 】
SQL 查询如下:
SELECT ARTIST.NAME
FROM ARTIST, APPEARS, ALBUM
WHERE ARTIST.ID=APPEARS.ARTIST_ID
AND APPEARS.ALBUM_ID=ALBUM.ID
AND ALBUM.NAME="Andy's OG Remix"
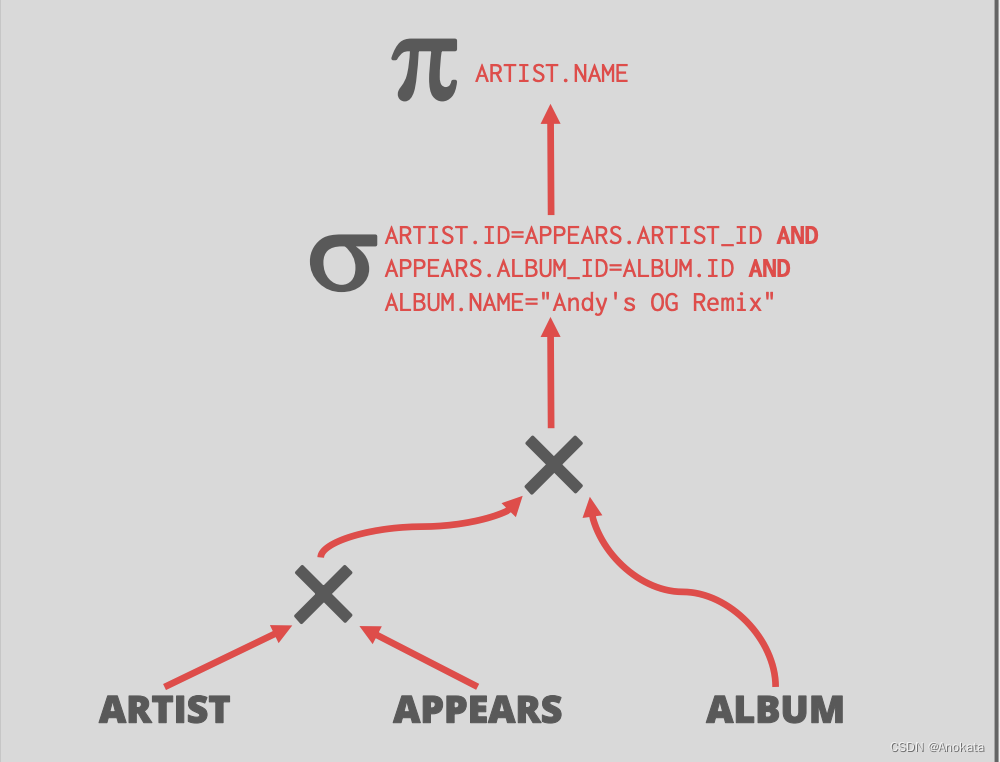
首先我们在 where 条件中看到一堆的 and ,将谓词分解为最简单的形式,以便优化器更轻松地移动它们(现在先不要关注表之间的的笛卡尔积)。

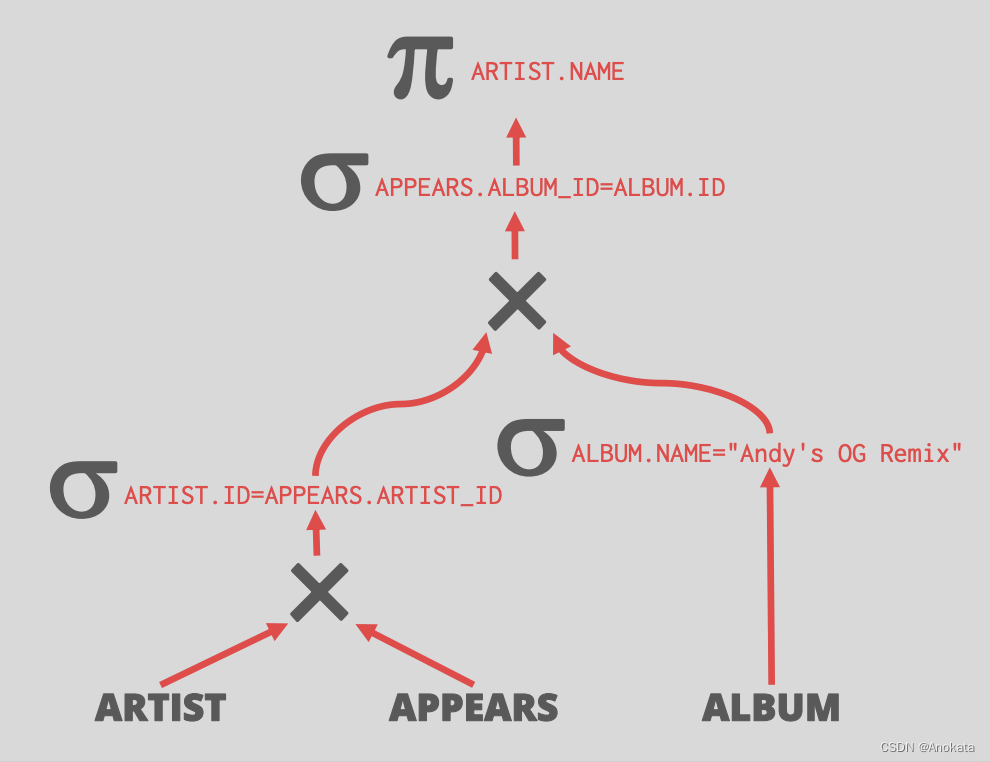
3.2 谓词下推【Predicate Pushdown】
这里的想法是,我们希望在查询计划中,可以尽快过滤尽可能多的数据,因此我们将把谓词下推到有足够的信息来实际应用这些谓词的最低点。
回到我们的例子,我们基本上对这三个表进行完整的顺序扫描,这里我们实际上是在作笛卡尔积。
对于 ALBUM.NAME="Andy's OG Remix" 这个谓词,他只涉及 ALBUM 表,所以我们可以将其下推到对 ALBUM 的查询处 。
而对于 ARTIST.ID=APPEARS.ARTIST_ID 这个谓语词,我们也可以将其下推。
下推后的查询计划如下:
3.3 替换笛卡尔积
使用连接谓词【join predicate】将所有笛卡尔积替换为内连接【inner join】。
在我们的查询计划中,一共有两处笛卡尔积,替换后的查询计划如下所示:
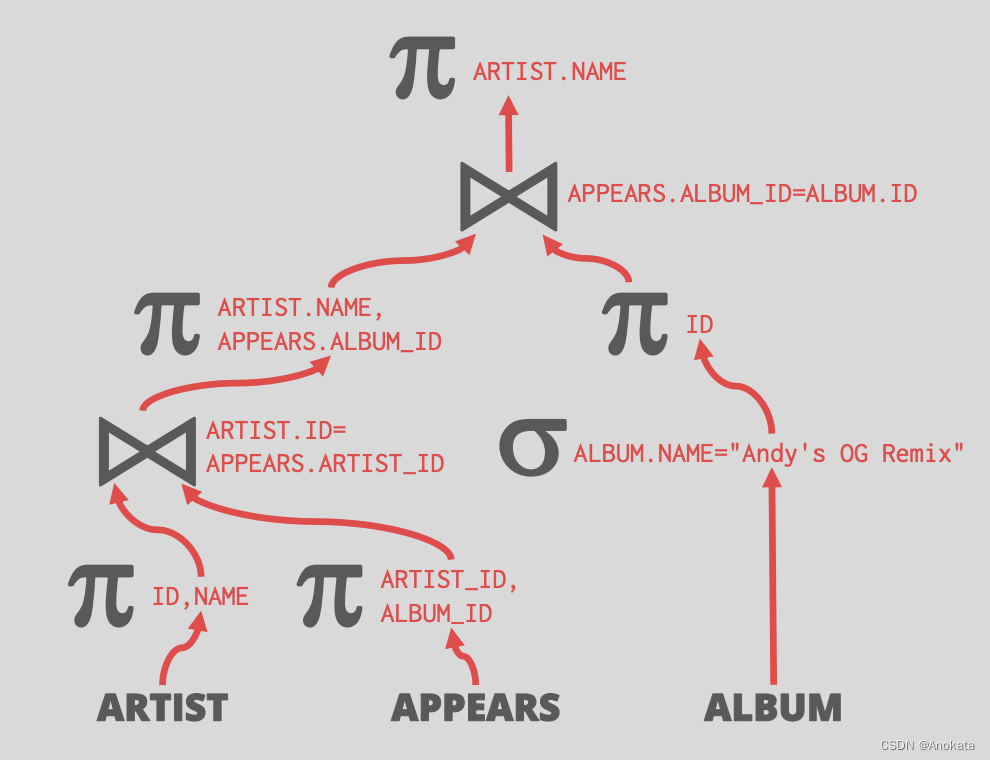
 3.4 映射下推【Projection Pushdown】
3.4 映射下推【Projection Pushdown】
这只在提前物化模型下有效!!!
从查询计划树的最底层开始消除冗余的属性,这样我们也不需要向上传递,因为输出中也不需要这些属性,这样就可以降低物化成本。
3.5 内嵌子查询【NESTED SUB-QUERIES】
DBMS 将 where 子句中的嵌套子查询视为函数,该函数接收参数,并返回单个值或者多个值(集合)。
内嵌子查询有两种,第一种是关联【correlate】内嵌,即内查询引用了外查询的一些东西,第二种是无关联【uncorrelate】内嵌,即内查询没有引用外查询的地方。
针对这两种内嵌子查询,也有两种相应的方法来优化它们:
- 重写以去关联【de-correlate】,或者扁平化它们,基本的实现就是将内嵌查询重写为连接【Join】
- 分解【Decompose】嵌套查询【nested query】,使其单独运行,将其将结果存储到临时表中,然后可以注入【injecting】标量值(如果需要的话)或进行连接【join】。
例子:
1️⃣ 下面是例子要优化的 SQL ,

2️⃣ 首先我们根据子查询的内容,可以分析出这是一个关联内嵌,我们可以使用重写,用于连接【Join】,将子查询片平化

对于较困难的查询,优化器将查询分解为多个块【block】,然后一次集中处理一个块。
子查询的结果会被写入临时表,该临时表在查询完成后被丢弃。
我们下面来看一个分解查询的例子:
1️⃣ 下面是一个较为复杂的内嵌查询,首先它不依赖任何外查询的东西,因此它完全可以单独运行

2️⃣ 愚蠢的方法是,我们对于外部查询中的每一个元组,都执行一遍这个子查询, 但很明显这种方法的耗时会非常久
3️⃣ 更好方案是我们将该子查询单独运行,并将结果通过标量值插入方式,引入到外查询中

3.6 表达式重写
优化器将查询的表达式(例如 WHERE/ON 子句谓词)转换为最小表达式集。
使用 if/then/else 子句或模式匹配规则引擎实现。
- 搜索与模式匹配的表达式。
- 找到匹配项后,重写表达式。
- 如果没有更多匹配的规则,则停止。
3.6.1 不可能/不必要的谓词

我们知道 1 = 0是不可能的,我们直接将其替换为 false 表达式

我们来看下一个

基于数据库的实现,我们知道 NOW 函数不会返回 NULL,因此也重写掉


3.6.2 归并谓词【Merging Predicate】

很明显,这里有一个范围的优化点:

4.基于成本的查询优化
到目前,我们已经学了如何使用规则来遍历逻辑计划,并将其转换为新的查询计划,然后在遍历数的时候,对于表达式,我们也可以基于一定的规则,将其进行重写。
接下来我们将讨论基于成本的查询优化,需要注意的是,绝大部分系统是成本+规则一起使用,规则可以帮助我们那些永远不会成为最优方案的东西,然后我们就可以应用基于成本的查询【Cost-Bassed Search】。
4.1 成本估计
DBMS 使用成本模型来预测在给定数据库状态下的查询计划【Query Plan】的行为。
- 这是一种内部成本,允许 DBMS 将一个计划与另一个计划进行比较。
运行每个可能的计划来确定此信息的成本太高,因此 DBMS 需要一种方法来推导出此信息。
4.2 成本模型的组成
选择1:物理成本【Physical Costs】
- 预测 CPU 周期、I/O、缓存未命中、RAM 消耗、网络消息……
- 很大程度上取决于硬件。
选择2:逻辑成本【Logical Costs】
- 估计每个操作符的输出大小。
- 独立于操作符算法。
- 需要估计操作符结果大小。
选择3:算法成本【Algorithmic Costs】,基本没有 DB 使用它,它只存在于学术研究中
- 操作符算法实现的复杂性
4.3 PostGres 成本模型
使用由“神奇”常数因子加权的 CPU 和 I/O 成本的组合。
默认设置显然适用于没有大量内存的磁盘驻留数据库:
- 在内存中处理元组比从磁盘读取元组快 400 倍。
- 顺序 I/O 比随机 I/O 快 4 倍

4.4 STATISTICS
我们实际生成此成本模型的方式是:DBMS 在其内部目录【Catalog】中存储有关表【tables】、属性【attributes】和索引【indexes】的内部统计信息。
不同的系统在不同的时间更新它们。
手动调用方式有:
- Postgres/SQLite: ANALYZE
- Oracle/MySQL: ANALYZE TABLE
- SQL Server: UPDATE STATISTICS
- DB2: RUNSTATS
4.4.1 选择基数【SELECTION CARDINALITY】
我们接下来通过一个真实的例子,即如何计算谓词的选择性,来探究统计成本模型。
谓词 P 的选择性 (sel) 是符合条件的元组的分数。
首先为了尽可能的简单,我们的谓词只是个简单的相等条件:

Equality Predicate: A=constant
- sel(A=constant) = #occurences / |R|
- 例子: sel(age=9) = 4/45
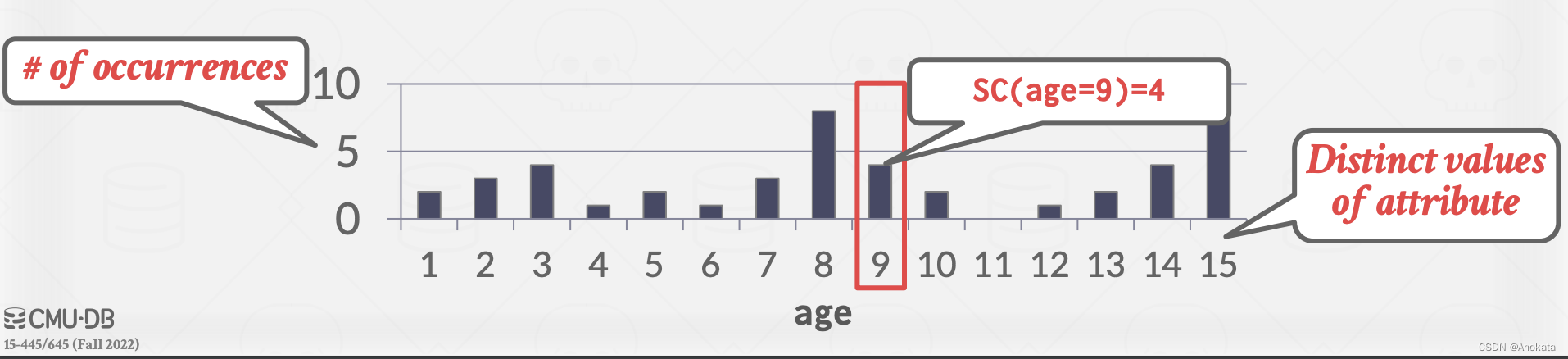
我们要做三个大的假设来简化我们的计算活动,如果你正在构建一个基于成本的优化器,这些是你要做的第一个假设,因为它会使数学更容易,也就更容易实现成本估计。
假设1:统一数据【Uniform Data】,即所有的值出现的概率是相同的,但是这在现实中是不可能的,解决办法是我们需要维护一个重量级列表【heavy hitter list】,或者是一个精确计数器,用来追踪重复率最高的 top 10 的值。
- 值的分布(除了重量级的)是相同的
假设2:独立谓词【Independent Predicates】,即谓词互相独立,我们可以将它们独立的计算,最终乘起来得到最终的选择性。
- 属性上的谓词是独立的
假设3:包容性原则【Inclusion Principle】,对于内表中的任意元组做连接【Join】,我们保证外表中一定有一个可以对应的元组。
- 连接键的域【domain】重叠,因此内部关系中的每个键也将存在于外表中。
当然我们知道这些假设都是不对的。
比如属性之间存在关联性,那么我们计算得到的选择性就不准确。
考虑一个关于汽车数据库:
- 品牌数 = 10,型号数 = 100
针对下面的查询:
- (make="Honda" AND model="Accord")
根据谓词独立和统一数据这两个假设,我们得到的选择性为:1/10 × 1/100 = 0.001
但是,只有本田【Honda】生产真正的雅阁,因此选择性应该为:1/100 = 0.01
4.4.2 统计方法
在实际生产中,我们有三种实现统计的方案,当然,我们仍然不能去扫描整个表来确认某个 SQL 的选择性:
- 直方图【Histograms】:维护列中每个值(或值范围)的出现计数。
- 草图【Sketches】:概率数据结构,给出给定值的近似计数
- 抽样【Sampling】:DBMS维护每个表的一个小子集,然后使用它来对表达式求值,以计算其选择性。
4.4.3 直方图
我们在前面其实已经见过直方图了,我们假设每个值的出现并不是相等的。
在直方图中,为每一个值存储一个直方图的成本是非常大的。
在下图中,我们值存储了15个直方图,假设每一个的计数都是32bit,那么我的总占用也就 60 字节。但是随着值域的增大,我们占用的内存也随之变大。因此没有任何系统会为每一个值存储一个计数器。
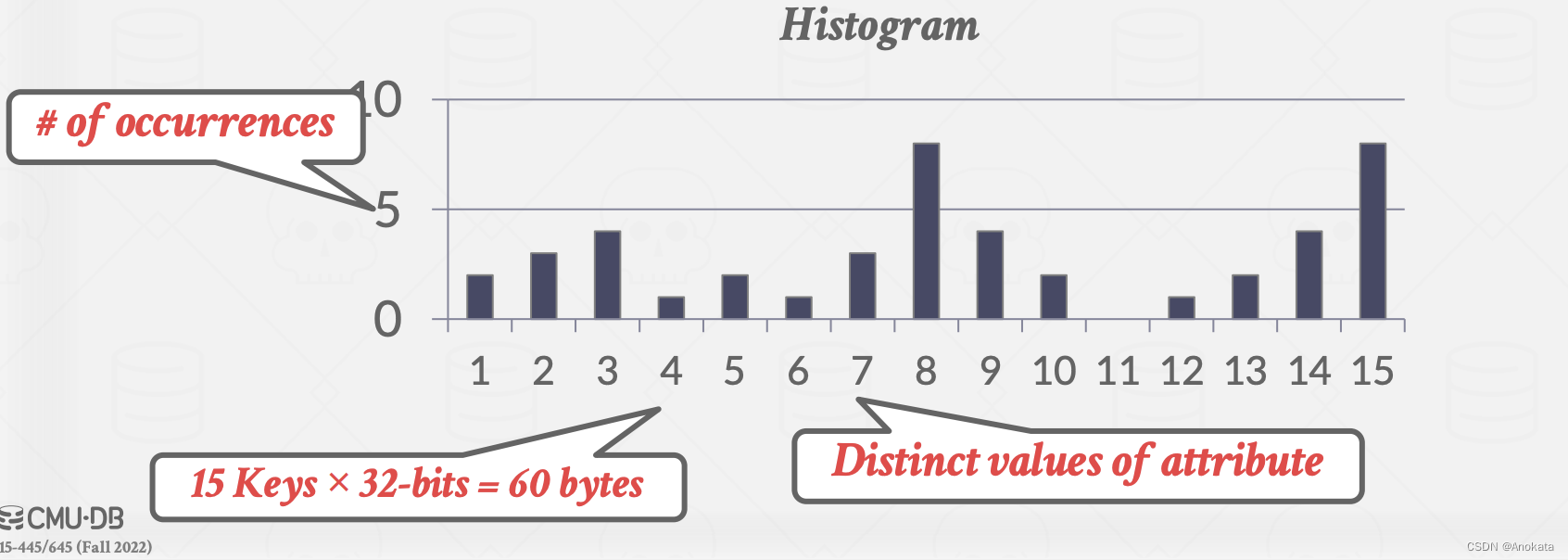
因此我们要做的是按照阈值(即桶大小)或者其他规则,将值域进行分桶,而我们纵坐标所存储的是桶中所有值的计数器。
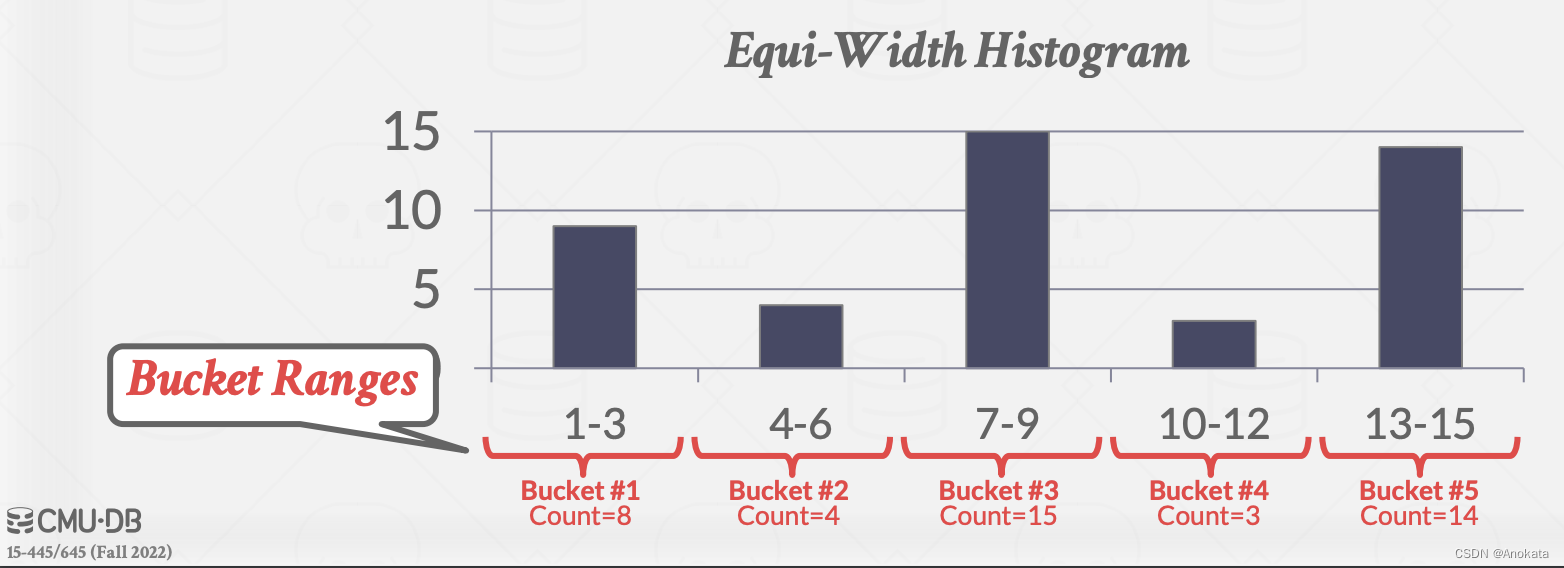
因此,我们得到了一个等宽直方图:维护一组值的计数,而不是每个唯一键的计数。所有的桶都有相同的宽度。
例如当我们要查询 key = 2 的 SQL 时,我们可以取其对应的桶的总计数,然后除以桶内的不同值的大小(3),即可以得到一个大概的统计。

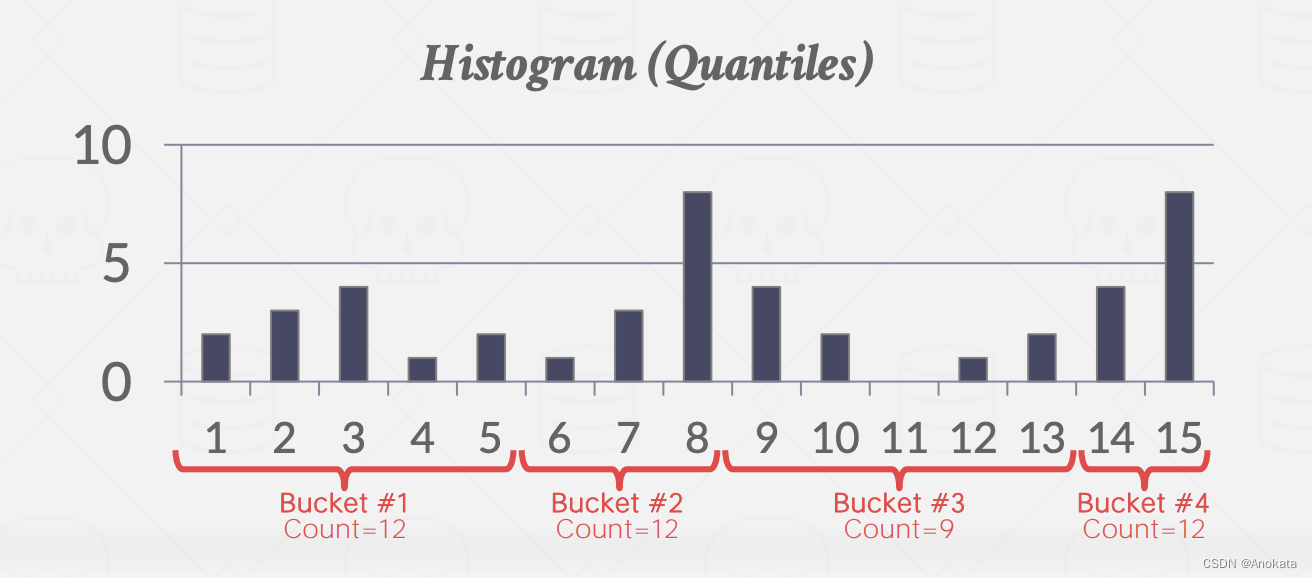
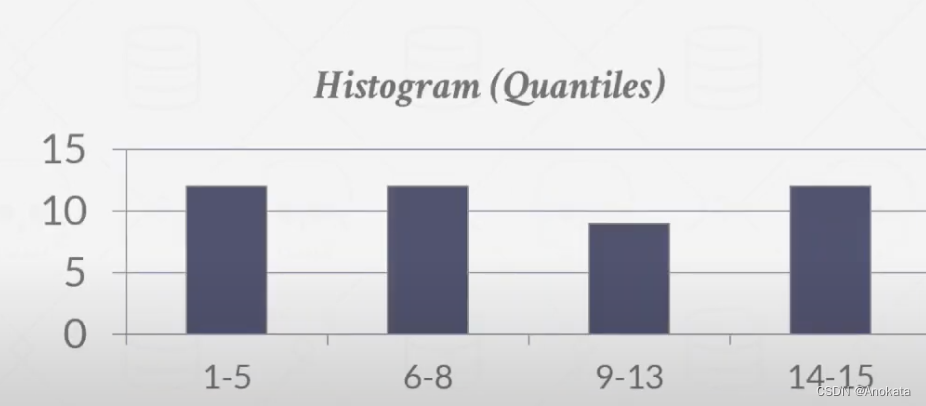
还有一种等深直方图,它改变桶的宽度,使每个桶中的总出现次数大致相同。
 4.4.4 草图【SKETCHES】
4.4.4 草图【SKETCHES】
草图优点像布隆过滤器,它是生成有关数据集的近似统计数据的概率数据结构。
成本模型可以用草图代替直方图,以提高其在选择性【sel】估计上的准确性。
最常见的例子:
- Count-Min Sketch (1988):集合中元素的近似频率计数。
- HyperLogLog (2007):近似集合中不同元素的数量。
4.4.5 采样【SAMPLING】
现代 DBMS 还可以从表中收集样本,以用来估计选择性【sel】,但是当基础表发生显著变化时需要更新样本集。
给定如下的 SQL 查询:

假设对应的表存在大量元组:

我们基于一定的算法,提取表中数据作为样本集,当我们计算某个谓词的选择性【sel】时,其实只是在该样本集上执行该谓词。

4.4.6 总结与思考
查询优化【Query optimization】对于数据库系统至关重要。
- SQL -> 逻辑计划-> 物理计划
- 在进入优化部分之前,需要对子查询做扁平化
•
• 。
表达式处理也很重要。
• QO 枚举可以是自下而上或自上而下的。
• 需要计算每个计划的成本,因此需要成本估算方法。
现在我们可以(粗略地)估计谓词的选择性【sel】,以及随后的查询计划【Query Plan】的成本,我们可以用它们做什么?
在对逻辑计划执行基于规则的重写后,DBMS 将枚举不同的查询计划并估计其成本。
- 单一关系【single relation】
- 多重关系【multi relation】
- 嵌套子查询【nNested sub-queries】其实子查询可以被重写,最终转换为单一关系或者多重关系
在用尽所有计划或超时后,它会为查询选择处最好的执行计划。
5. 查询规划【Query Planing】
5.1 单一关系查询规划
对与单表操作,我们的首要目标时选择最好的访问方法【Access Method】。
- 顺序扫描【Sequential Scan】
- 二叉查找(聚簇索引)【Binary Search (clustered indexes) 】
- 索引扫描【Index Scan】
然后,我们可能会对谓词求值做排序,因为你已经将其拆分开来了,你可以随意的移动它们。
通常而言,简单的启发式通常就足够了。
OLTP 的查询规划很容易,因为它们是 sargable(Search Argument Able 的缩写)。
- 通常只是选择最好的索引。
- 连接几乎总是在基数较小的外键关系上。
- 可以通过简单的启发式方法来实现。
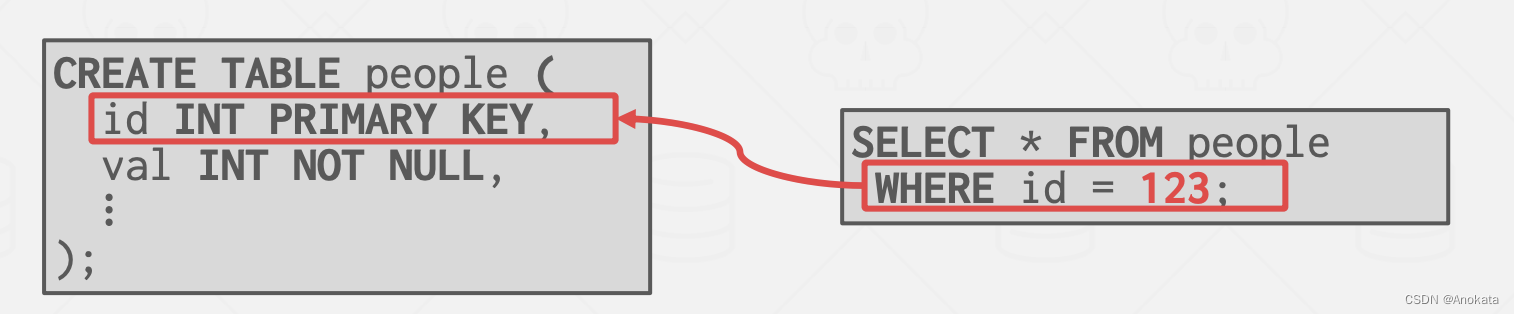
例如,对于下面这个简单的 SQL ,我们在就可以依赖主键的聚簇索引加速查询,即使该表上有其他列的索引。
5.2 多关系查询规划
选择1:自下而上的优化,从零开始,然后制定计划,达到你想要的结果
选择2:自上而下的优化,从您想要的结果开始,然后沿着树向下查找可实现该目标的最佳计划。
5.2.1 自下而上
使用静态规则【static rules】来执行初始优化。
然后使用动态规划【dynamic programming】通过分治搜索方法【divide-andconquer search method】确定表的最佳连接顺序。
示例:IBM System R、DB2、MySQL、Postgres,大多数开源 DBMS。
注: System R优化器是首个基于成本的优化器,后续的数据库实现基本都采纳这种方案。
System R 优化器
将查询分解为块【block】并为每个块【block】生成逻辑操作符。
对于每个逻辑操作符,生成一组实现它的物理操作符
- 即连接算法和访问路径的所有排列组合,基本上是根据启发式来选择它们
然后迭代地构建一个“左深【Left Deep】”连接树,最大限度地减少执行计划的估计工作量。
例子:
1️⃣ 基于我们之前使用过的表,我们执行如下 SQl

2️⃣ 第一步,选择每张表上的最佳访问路径【Access Path】
| ARTIST | 串行扫描【Sequential Scan】 |
| APPEARS | 串行扫描【Sequential Scan】 |
| ALBUM | NAME 属性上的索引查询【Index Lookup】 |
3️⃣ 第二步:枚举表的所有可能的连接顺序【Join Order】

4️⃣ 第三步:确定成本最低的连接顺序
因为我们是自下而上,在最底层,我们只有三张表,而在最顶层,则是按照页定数据连接起来的三个表
然后接下来,在第一步中,我们选择两种表进行连接,并为连接选择算法,很明显,此时我们可以连接的方式有:
- ARTIST & APPEARS
- ALBUM & APPEARS
- APPEARS & ALBUM
- 。。。等等
此处,进入到下一个逻辑运算符的路径上,将具有不同的物理运算符,这些物理操作符有:
- hash join
- sort-merge join
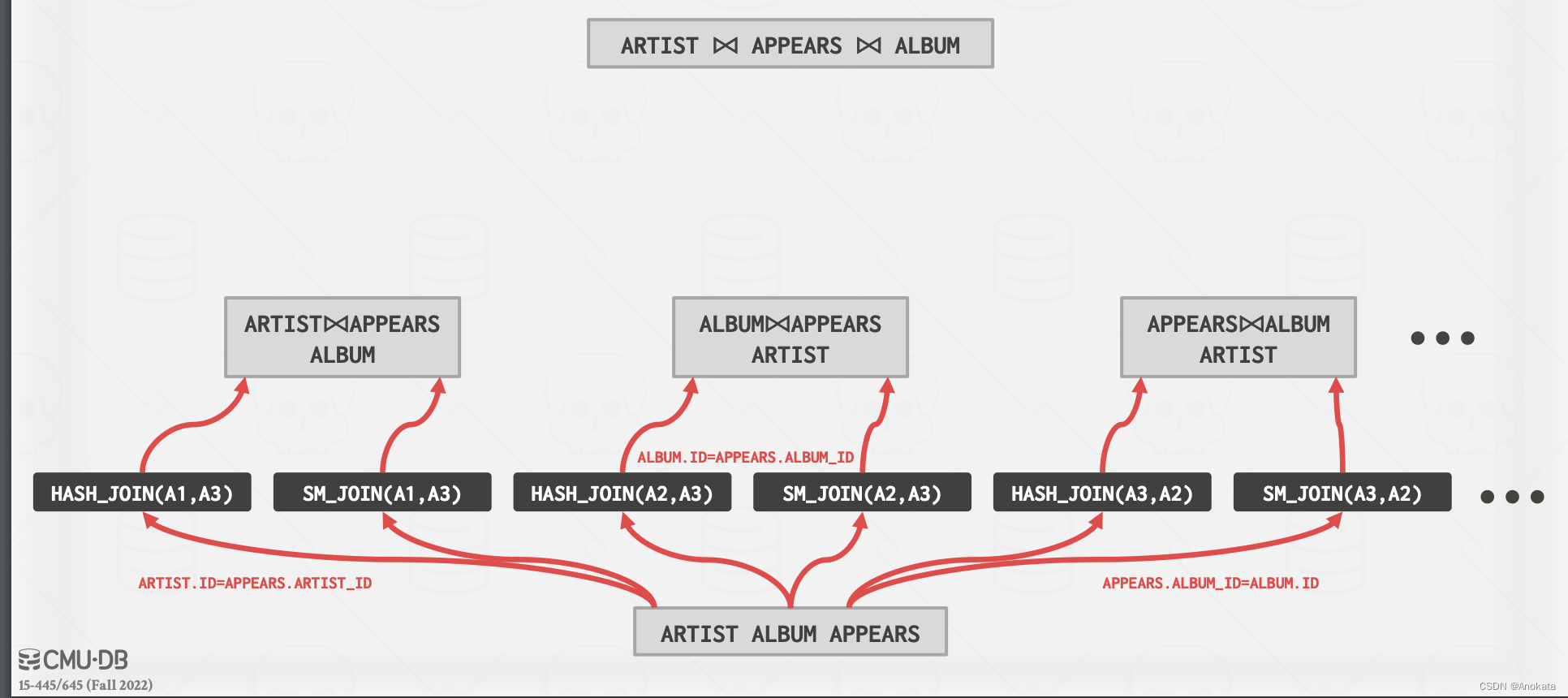
对于这些物理操作符,我们可以使用成本模型进行成本预估,剔除掉无效的选择。

接下来我们可以继续应用到后续的逻辑操作符上,以找到物理操作符,我们借来看最后的三路连接【three-way join】:
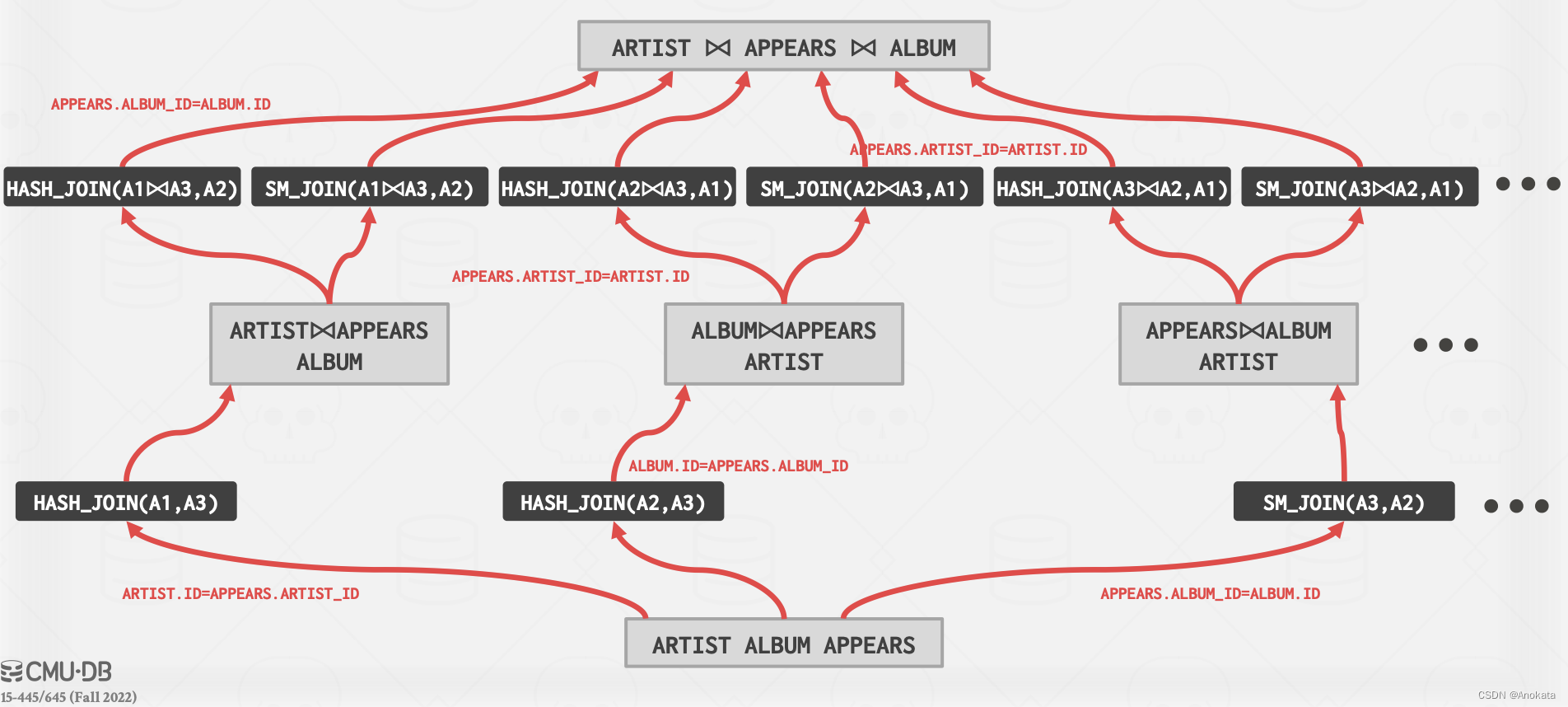
我们基于相同的办法,找出成本最低的物理操符:
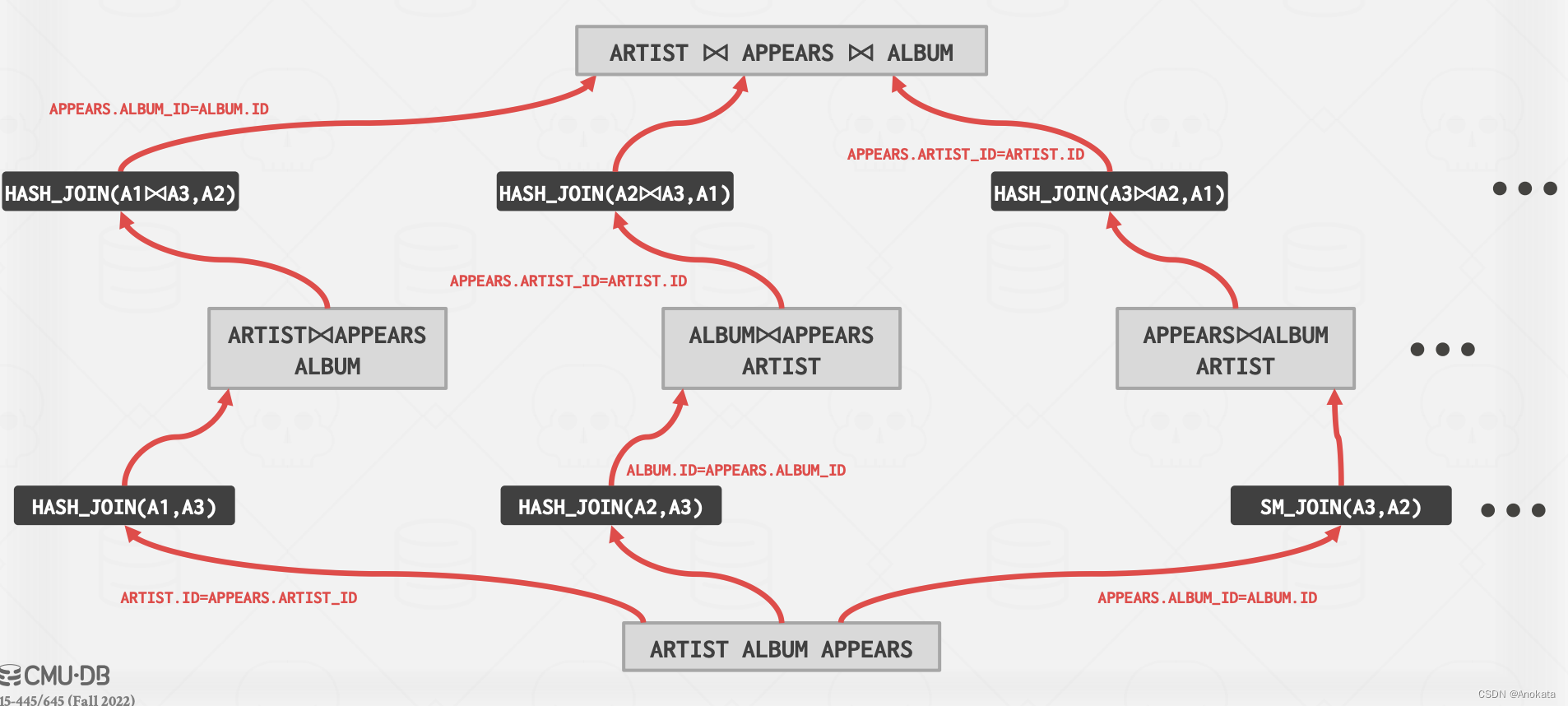 最终我,我们进行回溯,找到最佳执行路径:
最终我,我们进行回溯,找到最佳执行路径:

但是,在原始的R系统的实现中,它没有关于操作符生成的数据的逻辑或者物理属性的概念, 比如在查询中存在 ORDER ,但是在我们的查询计划中却并没有任何的体现。为此,我们必须再额外引入一个操作符,来实现我们的目的。
5.2.2 自上而下
从我们想要的查询的逻辑计划开始。 执行分支定界搜索【branch-and-bound search】,通过将逻辑操作符转换为物理操作符,来遍历计划树。
- 在搜索过程中跟踪全局最佳计划。
- 规划过程中将数据的物理属性视为头等实体【first-class】。
示例:MSSQL、Greenplum、CockroachDB
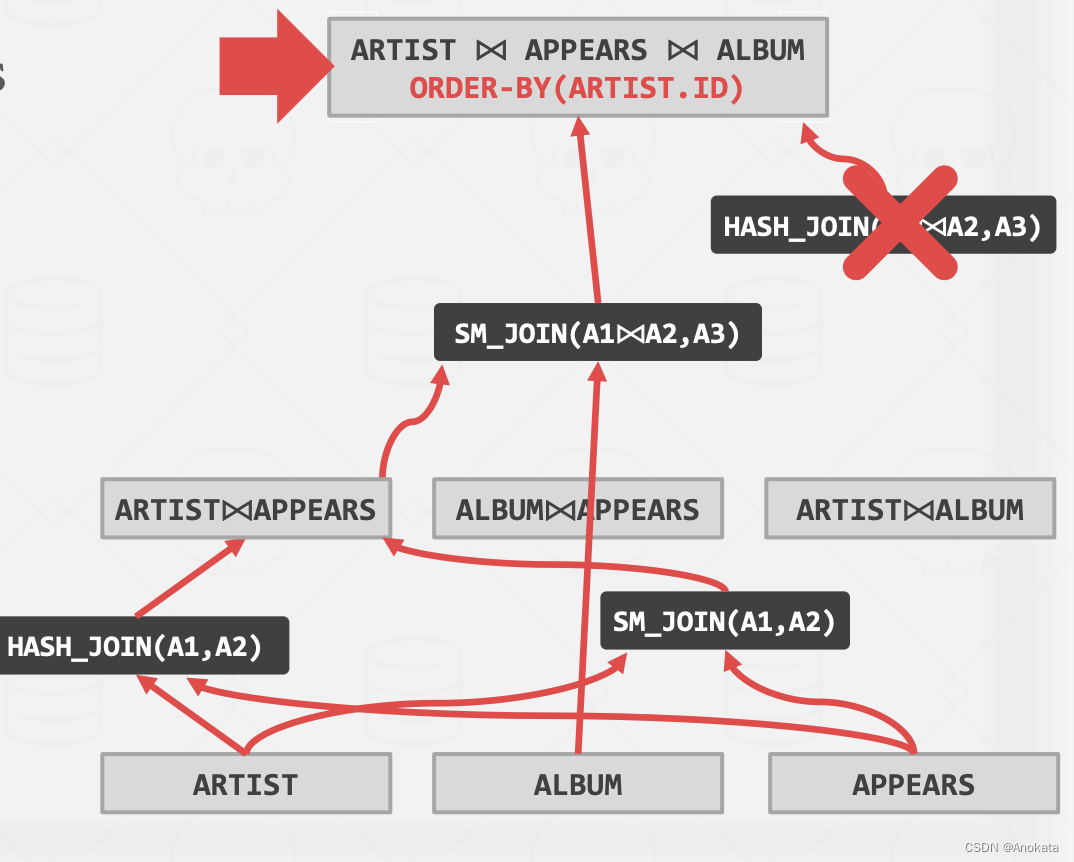
因为我们是自上而下,因此我们从顶部开始,即从我们希望得到的结果开始,或者说是我希望我的查询计划看起来是什么样子。同时,我们会添加一些属性信息,来说明我们期望的数据是什么样子,所以对于我们的例子而言,我们就需要加入 ORDER-BY(ARTIST.ID)

我们接下来要做的是转换的过程:
- Logical -> Logical (逻辑计划到逻辑计划):JOIN(A,B) to JOIN(B,A)
- Logical -> Physical(逻辑计划到物理计划):JOIN(A,B) to HASH_JOIN(A,B)
我们调用规则来创建节点【node】,将其枚举到我们的图中:

然后我们开始遍历树,我理解这个非常像深度优先算法 + 冒泡排序

当一条路径走到头之后,我们再回到开始,枚举新的路径:
需要注意的是,我们可以创建要求输入具有某些属性的“强制执行【enforcer】”规则,这样可以协助我们提前移除不可取的查询计划选择。
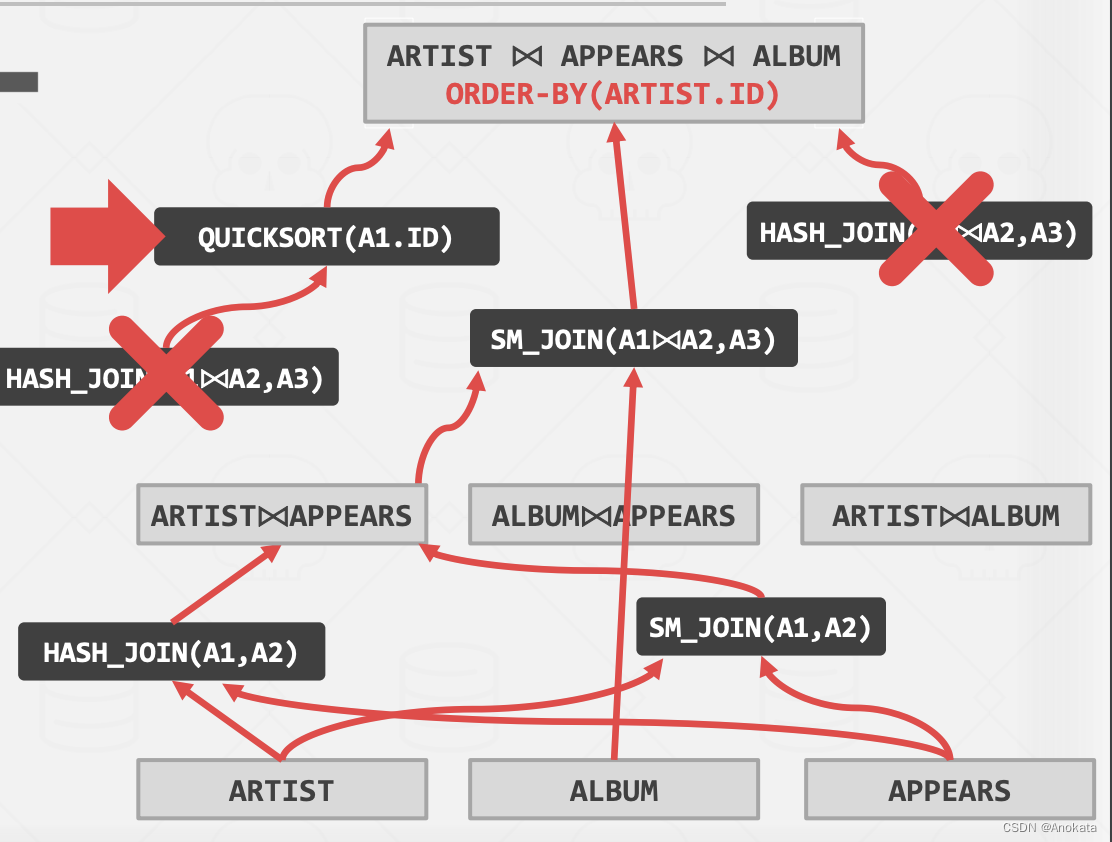
比如在这里,我们明确要求 ORDER BY,那么当我们重新从结果出发,选择讲哈希连接时,就可以直接被“强制执行【enforcer】”规则否定。
我们在前面讲过,逻辑操作符与物理操作符之间并不是 1 :1 的关系,因此我们可以使用归并排序+哈希连接,来实现 Join 逻辑操作符,但是,我们知道这种方式的成本非常高,它能比我们看到的计划要慢的多,因此我们知道无需继续向下执行了。
6 总结
我们使用静态规则和启发式方法来优化查询计划,而无需了解数据库的内容。
我们使用成本模型来帮助执行更高级的查询优化 。