对于一个搜索引擎来说,对检索出来的数据进行排序是非常重要的功能。全文本数据的检索通常无法用是否相等来的出结果,而是用相关性来决定最后的返回结果
相关性是值搜索内容和结果的相关性,是用来描述文档和查询语句的匹配程度的。通过计算相关性,可以得出一个相关性评分,然后根据评分对结果集进行排序,返回最符合的数据给用户。所以打分最终的目的是为了对结果进行排序,找出最匹配的结果集展示给用户。
那查询语句与文档的相关性该如何计算那?或者说用什么来作为相关性的依据呢?今天我们就来学习Lucene的相关性算分模型
设计我们自己的相关性算分模型
在不了解Lucene的相关性算分模型是如何实现之前,如果给你来设计相关性算分的模型,你有没有思路?
要找出与查询语句相关性最高的文档集合,是不是可以有这样的一种想法:把查询语句分词,如果某个词项在相关的文档中出现的频率越高,相关性就越高?然后把每个词项在文档的出现频率相加得到评分是不是可以作为相关性评分?如下表: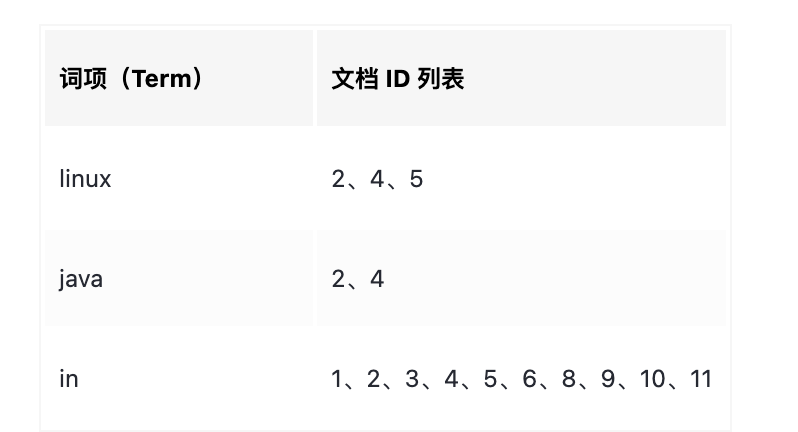
如果我们搜索“java in linux”的话,将这个查询语句分词后可以命中文档2,4,5。那么按照我们上述的步骤计算评分的话,操作如下:
- 求出linux、java这2个词项分别在2、4、5中出现的频率
- 将对应的频率进行相加,然后得出最终的评分如下:
sorce(doc 2) = F(java) + F(linux)
sorce(doc 4) = F(java) + F(linux)
sorce(doc 5) = F(java) + F(linux)
其中频率F(linux)的含义是:“linux”这个词在文档中出现的次数除以文档的总次数。需要注意的是,一些停顿词(the、in这些)本身没有意义,而且它们在文章中出现的频率非常高,所以它们的评分是不应该被考虑的!
在我们设计的算分模型中,数据的相关性有词项在文档中出现的频率高低来决定。而现实中,很多著名的算分模型就是基于概率统计的,例如:TF-IDF、BM25
TF-IDF算法模型
TF-IDF(Term Frequency-inverse Document Frequcency)是信息检索领域非常重要的发明,TF-IDF是一种关键词统计方法,用来反映一个词在一个文档集合或者资料库中的重要程度。其通常作为信息检索、文本挖掘、用户建模的加权因子。现在的搜索引擎很多依赖于TF-IDF,但都进行了微调和优化。
TF-IDF模型的思想其实都是说了这么一件事:如果一个词在一篇文章中出现的次数多,那么这个词对于这篇文章来说就越重要。但同时如果这个词在这个词库中出现的次数越多,那么其就不那么重要了,例如停用词就会在整个语料库中频繁出现,所以反而不那么重要了。这样做可以提高关键词与文章的相关性,并且减少常用词对结果的影响。换句话来说:一个词的重要程度跟它在一篇文中出现的频率成正比,跟它在语料库中出现的频率称反比
TF-IDF 中的概念:TF、DF、IDF
TF-IDF模型的公式中,主要包括:TF、DF、IDF三个概念,下面来看看这三个概念的定义和它们的计算过程
- TF(Term Frequency On Per Document):表示一个词在一篇文章中出现的概率。TF的计算公式为:

- DF(Document Frequency):表示词项在语料库中出现的频率。其计算公式为:

- IDF(Inverse Document Frequency):表示逆文档频率,其可以通过DF计算得到,可以简单的理解为DF的倒数。其计算公式为:

如上公式,词项的IDF=log(1/DF),可以忽略log,只看里面的(1/DF),那么如果词项的IDF越高,说明词项在语料库中越稀有,所以IDF表示词项在语料库中的稀有性
在熟知了TF、DF、IDF这三个概念后,我们来看看TF-IDF算分的公式:
tf-idf(termA) = TF(termA) * IDF(termA)
如上公式,可以得出tf-idf(termA)与TF(termA)正相关,与IDF(termA)正相关。说白了,就是一个词项在一篇文章中出现的越多,其对于这篇文档来说越重要,同时这个词项在整个语料库中的越少,其对于这个文档来说越重要。tf-idf 本质上是对 TF 进行了加权计算,而这个权重就是 IDF。
那回到 “java in linux” 这个查询,我们可以这样来计算每个匹配文档的得分:
sorce(D) = TF(java) * IDF(java) + TF(linux) * IDF(linux)
如上公式,其中D为某个匹配的文档,score(D)的值为各个词项的TF-IDF值的和
Lucene的TF-IDF算分公式

如上图所示的是Lucene的TF-IDF算分公式,公式中的各个项都容易理解,图中也做了注释,下面对几个项进行解析,其他不在赘述。
- norm(t,d):是文档长度的加权因子,在索引文档时候就确定了的参数,其由文档的长度(也就是字段的内容长度)来去定,它可以提高短文档的分数
- coord(q,d):将查询内容分词后,如果匹配的文档出现的分词后的词项越多,coord(q,d)越大
- queryNorm(q):是一个归一化因子,使得查询之间的分数具有可比性
- tf(t in d):Lucene中tf于标准的TF-IDF中的TF计算公式不一样,其值为t在文档d中出现次数的平方根
- Idf(t):Luence中逆文档频率与上面的IDF公式也有点不一样,idf(t) = 1+log【(文档总数+1)/(匹配的文档树+1)】
TF-IDF 在 Lucene 中的实现文档可以参考:Lucene-TFIDF
BM25 算分模型
BM是Best Matching(最佳匹配)的缩写。在信息检索的领域,OKapi BM25是搜索引擎用来评估文档相关性以进行排序的函数,这个方法是上世纪七八十年代在概率检索的框架下被提出的,Okapi是第一个使用这个方法的信息获取系统的名称
BM25是基于词频的,它不会考虑多个搜索词项在文档里靠不靠近,只考虑它们各自在文档中出现的次数。BM25是一系列的评分函数,它们彼此之间有形式和参数个数的差异。最常用的形式之一如下: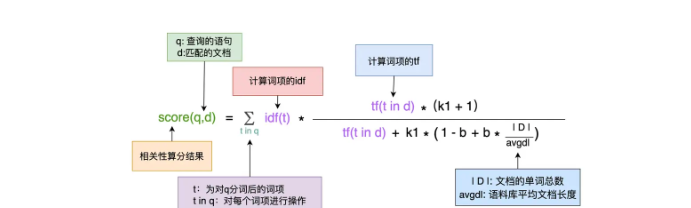
如上图,公式中的各项同样很容易理解,下面对比较特别的几项进行介绍:
- k1和b:它们是自由参数,k1的取值范围为[1.2, 2.0],k1默认是1.2,而b=0.75
- |D| / avgdl:文档越短的话,此值越小,所以当tf(t in d)相等的情况下,公式后半部分取值越高。其值反映了词项在匹配文档中的重要性,对短篇文档更有利
- idf(t):为词项t的逆文档频率,但其计算方式跟TF-IDF中介绍的公式有点不一样,普通版的计算公式为:

如上图所示,其中N为语料库中文档的总数,n(t)为包含词项t的文档个数,遗憾的是,当含有词项的文档数量大于语料库的一半时候,此公式的idf(t)为负。所以一般会对此公式优化:
通过进行加一的操作,可以避免对数后的结果出现负数的情况
下面来对比一下Lucene TF-IDF、BM25优化版、BM25版的IDF公式,语料库中共计100个文档,匹配的文档个数从1到100,图中横坐标为匹配的文档个数,纵坐标IDF公式计算出来的值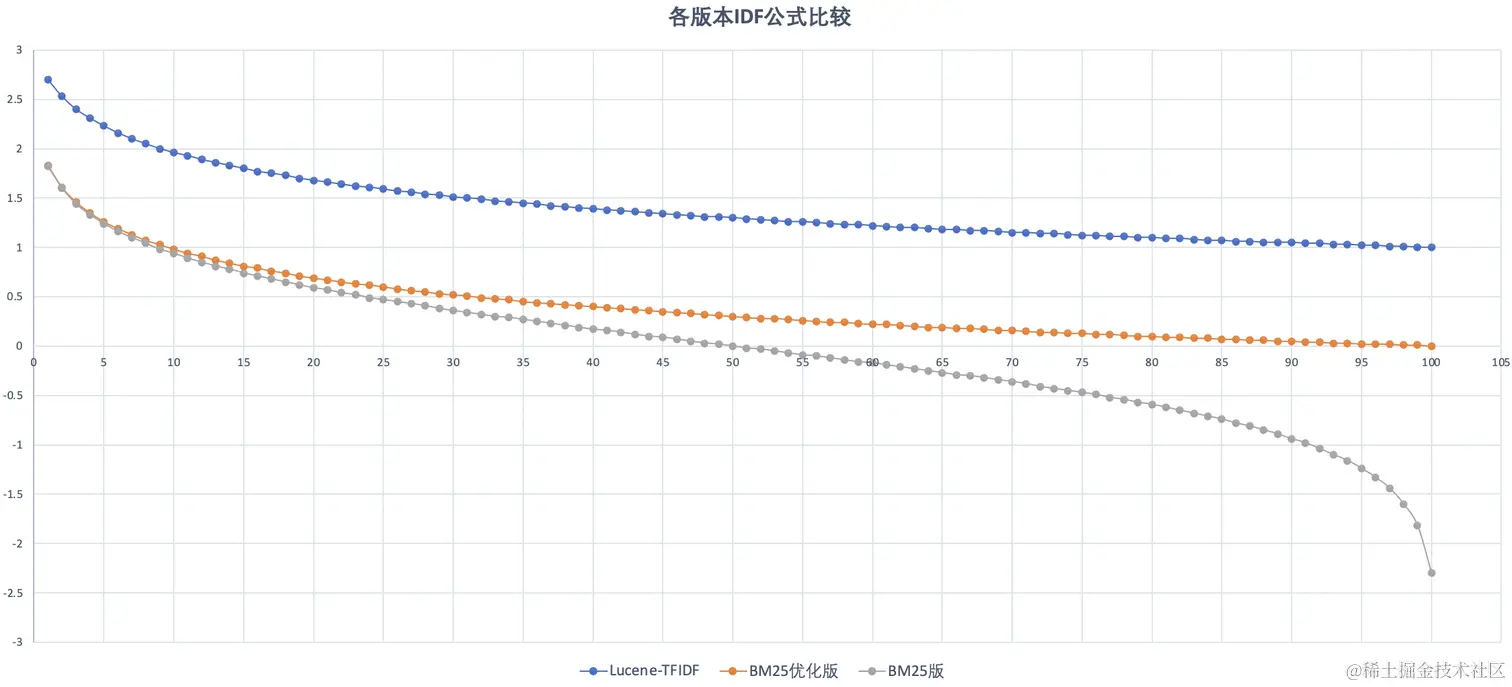
上面我们说过IDF的作用是代表了词项在语料库中的稀有性,也是一个词项的权重,所以这个权重不应该为负数,并且当所有文档出现了某个词项,那么这个词项在语料库中就不稀有了,其权限应无限接近于0才是合理的。相比之下,优化后的BM25中的IDF公式更符合我们的需求
TF- IDF与BM25的比较
相对于TF-IDF来说,BM25降低了TF对算分的影响力。当TF无限增加时,TF-IDF模型的算分也会无限增加,而BM25则会趋于一个值。如果不考虑文档长度的影响(|D|/avgdl = 1 了),BM25 的 TF 算分的公式为:(tf * (k1 + 1)/ (tf + k1)) ,参考BM25算分公式的后半部分
如上图,当TF无限大的时候,BM25的TF算分结果无限逼近于(k1+1),虽然TF越大意味着这个词项相关性更大,但很快其影响力就下降了,收益递减。而Lucene的TF-IDF中词频的相关性会一直增加,算分也一直增加。
经过这么一比较,其实可以发现,k1 的作用是用来调节词频的影响力的。如果 k1 = 0,那么公式的后半部分 (tf * (k1 + 1)/ (tf + k1))= 1,即不再考虑词频的影响了。而 k1 为较大值时,(tf * (k1 + 1)/ (tf + k1))会与 tf 保持线性增长。
回过头来看,我们似乎还不知道 b 这个参数的意义到底是什么。我们令 L = |D|/avgdl,那么公式的分母部分可以表示为:tf(t in d) + k1 * (1 - b + b * L),可以看到,b 控制了文档篇幅对于得分的影响程度,当 b = 0 的时候,文档长度将不影响算分,而当 b = 1 的时候,将不起调节作用。
而 k1 和 b 都是可以用户自己设定的,如下实例,可以在创建Mapping的时候指定一个 similarity 的k1 和 b 值,并应用到每个字段中:
PUT test_similarity_index
{
"settings": {
"index": {
"similarity": {
"my_similarity": {
"type": "BM25",
"k1": 1.3,
"b": 0.76
}
}
}
},
"mappings": {
"properties" : {
"title" : { "type" : "text", "similarity" : "my_similarity" }
}
}
}
总结
本文为你介绍了数据相关性的原理,我们从自己设计相关性算分模型出发,学习了经典的 TF-IDF 、BM25 算分模型。
TF-IDF 模型中主要有3个部分:
- TF 是词项在文档中出现的频率,代表了这个词项对文档的重要程度。其中 Lucene 的 TF 实现为 t 在文档 d 中出现次数的平方根。
- DF 词项在整个语料库中出现的频率,DF 越大词项的重要程度也就越低。
- IDF 也叫逆文档频率,代表了词项在语料库中的稀有程度,其在计算得分时作为 TF 的权重。
在 ES 5.0 的版本后,ES 默认使用了 BM25 的算分模型,相对 TF-IDF 来说,其优化点在于降低 TF 对算分结果的影响力,并且引入了可以自定义的参数:k1 和 b,其中 k1 用来调节词频的影响力的,而 b 则控制了文档篇幅对于得分的影响程度。
好了,在学习了 ES 的算分模型后,大家可以结合之前学习的数据操作、查询的 API 来做一些实践啦。
可以使用 explain API 来查看算分的过程:
POST your_index/_search
{
"explain": true, # 开启 explain
"query": .....
}