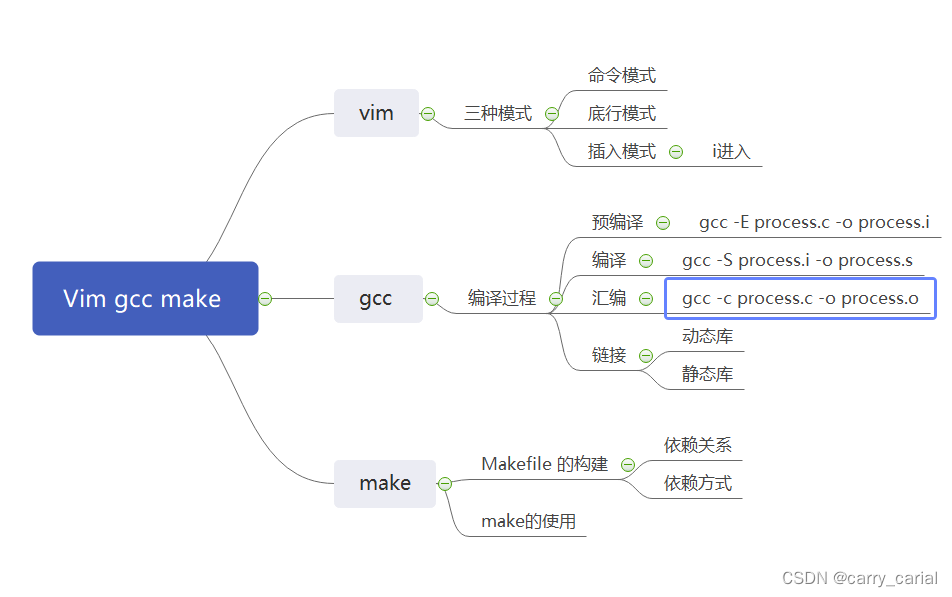
kafka的消费方式
pull(拉模式)
消费者采用从broker中主动拉去数据 kafka采用这种方式
push(推模式)
kafka没有采用这种方式,因为由broker决定消费发送速率。很难适应所有消费者
pull模式不足之处是,如果kafka没有数据。消费者还是会进行监听操作。
两者区别
由 broker 决定消息推送的速率,对于不同消费速率的 consumer 就不太好处理 了。消息系统都致力于让 consumer 以最大的速率最快速的消费消息,但不幸的是, push 模式下, 当broker 推送的速率远大于 consumer 消费的速率时,consumer 恐怕就要崩溃了 。最终 Kafka 还是选取了传统的 pull 模式。
Pull 模式的另外一个好处是 consumer 可以自主决定是否批量的从 broker 拉取数据 。 Push 模式必须在不知道下游 consumer 消费能力和消费策略的情况下决定是立即推送每条消息还是缓存之后批量推 送。如果为了避免 consumer 崩溃而采用较低的推送速率,将可能导致一次只推送较少的消息而造成浪 费。 Pull 模式下, consumer 就可以根据自己的消费能力去决定这些策略。
Pull 有个缺点 是, 如果 broker 没有可供消费的消息,将导致 consumer 不断在循环中轮询,直到新消息到达 。为了避免这点, Kafka 有个参数可以让 consumer 阻塞知道新消息到达 ( 当然也可以阻塞知道 消息的数量达到某个特定的量这样就可以批量发送 )
消费者工作流程
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pVVYs8PI-1673513915321)(./assets/bde38b7cf3a44abbaf979ef2117125af.png)]](https://img-blog.csdnimg.cn/b2430a8d949843aa9e573c55367f99b4.png)
- 生产者生产消息到kafka集群中。集群将产生的消息放入不同的kafka的broker 每一个broker表示一个kafka节点 对应的分区中
- kafka的分区存在副本,leader和follower,进行消息的安全性(丢失,重复,顺序)
- 每一个消费者都属于一个消费者组。即使只有一个消费者。默认也是存在一个消费者组
- 消费者组绑定一个Topic主题。Topic下的存在多个分区。
- 每一个分区的数据只能给一个消费者消费。因为如果一个分区数据同时给同一个消费者组的两个消费者消费会造成数据的重复
- 一个消费者可以同时消费多个Topic中的多个分区数据。
- 一个topic中的数据可以给多个消费者或消费者组消费。对相同的数据存在不同的业务操作
分区的分配规则
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eMR1mi1a-1673513915322)(./assets/df1fca36d8914e0b9bc0c43f62ff2dc6.png)]](https://img-blog.csdnimg.cn/6010e422045d464fb8f6169998498161.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-awMsEbtw-1673513915323)(./assets/b06c18cef2f4495985e303ebf279ef5b.png)]](https://img-blog.csdnimg.cn/92a28fb2f0ce4a1a9f86dd9f26545253.png)
代码展示消费者组下的消费者消费情况
生产者
public class KafkaProduce {
public static void main(String[] args) {
// 创建Kafka生产者配置对象
Properties props = new Properties();
// 给kafka配置对象添加配置信息
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "202.168.130.10:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
// 创建生产者 指定配置
Producer<String, String> producer = new KafkaProducer<>(props);
// 循环发送消息
for (int i = 0; i < 10; i++) {
ProducerRecord<String, String> record =
new ProducerRecord<>("KafkaStudy", "HelloWord" + i);
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if(e == null){
System.out.println("topic:"+metadata.topic()+"--patition:"+metadata.partition());
}
}
});
}
// 关闭生产者
producer.close();
}
}
消费者
@Component
public class KafkaConsumerGroup {
// 该kafka注解 指定Topic 等信息去监听kafka中的消息
// 这里进行指定 消费者组和Topic
// 当我们同时指定多个消费者 指定相同的消费者组。此时这些消费者就是同一个组下的
// 此时消费者就属于同一个消费组 每个消费者消费到不同分区的数据
@KafkaListener(groupId = "groupIdTest", topics = "kafkaStudy")
public void consumerOne(ConsumerRecord<String,String> record){
// 获取 分区 偏移量 值 等kafka信息
int partition = record.partition();
long offset = record.offset();
String value = record.value();
// 打印信息
System.out.println("consumerOne 分区:" + partition + " consumerOne 偏移量:" + offset + " consumerOne 值:" + value);
}
@KafkaListener(groupId = "groupIdTest", topics = "kafkaStudy")
public void consumerTwo(ConsumerRecord<String,String> record){
// 获取 分区 偏移量 值 等kafka信息
int partition = record.partition();
long offset = record.offset();
String value = record.value();
// 打印信息
System.out.println("consumerTwo 分区:" + partition + " consumerTwo 偏移量:" + offset + " consumerTwo 值:" + value);
}
@KafkaListener(groupId = "groupIdTest", topics = "kafkaStudy")
public void consumerThree(ConsumerRecord<String,String> record){
// 获取 分区 偏移量 值 等kafka信息
int partition = record.partition();
long offset = record.offset();
String value = record.value();
// 打印信息
System.out.println("consumerThree 分区:" + partition + " consumerThree 偏移量:" + offset + " consumerThree 值:" + value);
}
}
结果展示
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DHycZo0u-1673513915323)(./assets/image-20230112101223634.png)]](https://img-blog.csdnimg.cn/4ef08c2c61264bf69f04df8f0f744f4d.png)
消费者API操作
很多中间件在整合SpringBoot之后都会简化操作。
Kafka也是一样没整合之前的监听我们是需要通过手动创建监听,poll消息等操作
整合SpringBoot之后,提供了一个@KafkaListener注解
未使用@KafkaListener注解
public class CustomConsumer {
public static void main(String[] args) {
// 创建配置信息 这里与生产者一个意思
Properties props = new Properties();
props.put("bootstrap.servers", "192.168.182.143:9092");
props.put("group.id", "testGroup1");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// kafka生产者指定读取配置信息
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者订阅 指定的Topic 注意这里是可以订阅多个Topic的
consumer.subscribe(Arrays.asList("first"));
// 循环 拉去信息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
}
@KafkaListener注解
@KafkaListener的主要属性
-
id:监听器的id
-
groupId:消费组id
-
idIsGroup:是否用id作为groupId,如果置为false,并指定groupId时,消费组ID使用groupId;否则默认为true,会使用监听器的id作为groupId
-
topics:指定要监听哪些topic(与topicPattern、topicPartitions 三选一)
-
topicPattern: 匹配Topic进行监听(与topics、topicPartitions 三选一) 类似于表达式 通过表达式来匹配多个Topic
-
topicPartitions: 显式分区分配,可以为监听器配置明确的主题和分区(以及可选的初始偏移量)
常用操作
监听一个Topic
指定消费者组,指定监听Topic
/**
* 指定一个消费者组,一个主题主题。
* @param record
*/
@KafkaListener(topics = IPHONE_TOPIC,groupId = APPLE_GROUP)
public void simpleConsumer(ConsumerRecord<String, String> record) {
System.out.println("进入simpleConsumer方法");
System.out.printf(
"分区 = %d, 偏移量 = %d, key = %s, 内容 = %s,创建消息的时间戳 =%d%n",
record.partition(),
record.offset(),
record.key(),
record.value(),
record.timestamp()
);
}
监听多个主题(Topic)
/**
* 指定多个主题。
*
* @param record
*/
@KafkaListener(topics = {IPHONE_TOPIC,IPAD_TOPIC},groupId = APPLE_GROUP)
public void topics(ConsumerRecord<String, String> record) {
}
监听一个Topic,指定多个分区
/**
* 监听一个主题,且指定消费主题的哪些分区。
* 参数详解:消费者组=apple_group;监听主题=iphoneTopic;只消费的分区=1,2;消费者数量=2
* @param record
*/
@KafkaListener(
groupId = APPLE_GROUP,
topicPartitions = {
@TopicPartition(topic = IPHONE_TOPIC, partitions = {"1", "2"})
},
concurrency = "2"
)
public void consumeByPattern(ConsumerRecord<String, String> record) {
}
指定多个分区,指定起始偏移量消费消息
/**
* 指定多个分区从哪个偏移量开始消费。
*/
@KafkaListener(
groupId = APPLE_GROUP,
topicPartitions = {
@TopicPartition(
topic = IPAD_TOPIC,
partitions = {"0","1"},
partitionOffsets = {
@PartitionOffset(partition = "2", initialOffset = "10"),
@PartitionOffset(partition = "3", initialOffset = "0"),
}
)
},
concurrency = "10"
)
public void consumeByPartitionOffsets(ConsumerRecord<String, String> record) {
}
监听多个主题,指定多个分区,指定起始偏移量消费消息
/**
* 指定多个主题。参数详解如上面的方法。
* @param record
*/
@KafkaListener(
groupId = APPLE_GROUP,
topicPartitions = {
@TopicPartition(topic = IPHONE_TOPIC, partitions = {"1", "2"}),
@TopicPartition(topic = IPAD_TOPIC, partitions = "1",
partitionOffsets = @PartitionOffset(partition = "0", initialOffset = "5"))
},
concurrency = "4"
)
public void topics2(ConsumerRecord<String, String> record) {
}
指定多个kafka监听器
/**
* 指定多个消费者组。参数详解如上面的方法。
*
* @param record
*/
@KafkaListeners({
@KafkaListener(
groupId = APPLE_GROUP,
topicPartitions = {
@TopicPartition(topic = IPHONE_TOPIC, partitions = {"1", "2"}),
@TopicPartition(topic = IPAD_TOPIC, partitions = "1",
partitionOffsets = @PartitionOffset(partition = "0", initialOffset="5"))
},
concurrency = "3"
),
@KafkaListener(
groupId = XM_GROUP,
topicPartitions = {
@TopicPartition(topic = XMPHONE_TOPIC, partitions = {"1", "2"}),
@TopicPartition(topic = XMPAD_TOPIC, partitions = "1",
partitionOffsets = @PartitionOffset(partition = "0", initialOffset="5"))
},
concurrency = "3"
)
}
)
public void groupIds(ConsumerRecord<String, String> record) {
System.out.println("groupIds");
System.out.println("内容:" + record.value());
System.out.println("分区:" + record.partition());
System.out.println("偏移量:" + record.offset());
System.out.println("创建消息的时间戳:" + record.timestamp());
}
kafka偏移量
offset是指某一个分区的偏移量。
在Kafka0.9版本之前消费者保存的偏移量是在zookeeper中/consumers/GROUP.ID/offsets/TOPIC.NAME/PARTITION.ID。
新版消费者不在保存偏移量到zookeeper中,而是保存在Kafka的一个内部主题中“_consumer_offsets”
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ezkcjwtN-1673513915324)(./assets/image-20230112150315217.png)]](https://img-blog.csdnimg.cn/a9b0e09cc8404df38d2441a0cc3fc72f.png)
enable.auto.commit开启自动提交
Kafka 默认是定期帮你自动提交位移的(enable.auto.commit=true)。有时候,我们需要采用自己来管理位移提交,这时候需要设置 enable.auto.commit=false。
auto.commit.interval.ms 设置自动提交间隔 默认5s
auto.offset.reset
auto.offset.reset 值含义解释如下:
- earliest :当各分区下有已提交的 Offset 时,从“提交的 Offset”开始消费;无提交的Offset 时,从头开始消费;
- latest : 当各分区下有已提交的 Offset 时,从提交的 Offset 开始消费;无提交的 Offset时,消费新产生的该分区下的数
- none : Topic 各分区都存在已提交的 Offset 时,从 Offset 后开始消费;只要有一个分区不存在已提交的 Offset,则抛出异常。
手动提交
因为自动提交当还未进行下次提交的时候,程序出现问题。提交失败就会导致下次消费数据重复或丢失数据等问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yXQprP5j-1673513915324)(./assets/da8fd89cb9ed4155b89649a6c84371e0.png)]](https://img-blog.csdnimg.cn/f4c7c5dd35da4a5697b8cbb004aee135.png)
设置手动提交偏移量
/**
* 设置手动提交偏移量
*
* @param record
*/
@KafkaListener(
topics = IPHONE_TOPIC,
groupId = APPLE_GROUP,
//3个消费者
concurrency = "3"
)
public void setCommitType(ConsumerRecord<String, String> record, Acknowledgment ack) {
System.out.println("setCommitType");
System.out.println("内容:" + record.value());
System.out.println("分区:" + record.partition());
System.out.println("偏移量:" + record.offset());
System.out.println("创建消息的时间戳:" + record.timestamp());
// 手动提交 偏移量
ack.acknowledge();
}
注意
如果设置为自动 提交 enable.auto.commit=true
// 此时就不能在 方法中带入Acknowledgment 手动提交的类。
// 会抛出异常
public void setCommitType(ConsumerRecord<String, String> record, Acknowledgment ack) {}





![基于YOLOv5+C3CBAM+CBAM注意力的海底生物[海参、海胆、扇贝、海星]检测识别分析系统](https://img-blog.csdnimg.cn/img_convert/df21899986d75fb72e8d3291ac8b7a60.png)