坚持看完,结尾有思维导图总结
这里写目录标题
- vim
- vim的安装
- vim的配置
- vim 的使用
- vim 的三种模式
- 三种模式对应的命令
- 通用
- 命令模式
- 底行模式
- gcc 和 g++
- 编译和执行
- 预编译
- 编译
- 汇编
- 链接过程
- make
- 总结
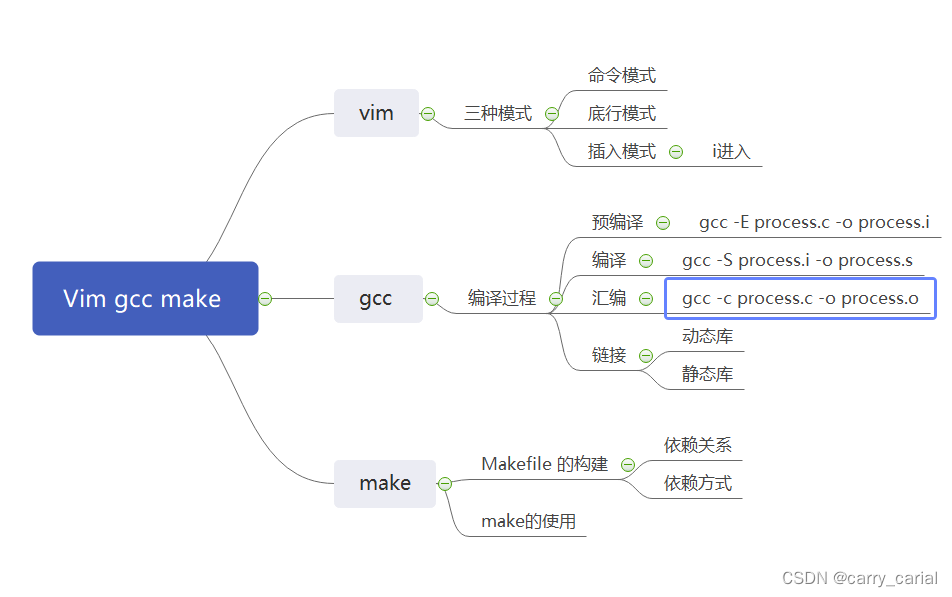
vim
Vim 是Linux 中使用的编辑器,一般的程序要经历一个过程才能运行,编辑,编译,链接,运行
vim 就是用来编辑的工具,编辑大白话就是用户用来写程序的
vim的安装
在 vim 中 可以用这个命令来安装 vim
yum -y install vim*
vim的配置
直接运行 vim .vimrc
在其中加入对应的命令即可
比如我的 vim 一开始是这样的
就是一个很普通的编辑器

然后写入

再打开对应 c 文件就出现了行号
所以在 .vimrc 中添加特定的语句,能够对 vim 的显示进行设置
可以设置字体大小,高亮颜色等等
vim 的使用
vim 的三种模式
Vim 常用的有五种模式,其中主要的有三种模式
命0令模式,底行模式,插入模式
命令模式,就是能够通过特定的命令,来实现如同修改,删除,复制粘贴之类的功能
底行模式,打开底行,来实现退出以及相关功能
插入模式,用来编写写程序
三种模式对应的命令
通用
第一个命令,esc(即退出)能够从其他模式切换到命令模式
命令模式
shift : 进入底行模式(冒号是要打上去的)
(n)yy 复制 n 行
(n)p 粘贴,或者相同的内容粘贴 n 遍
(n)dd 剪切,如果没有加p 就是删除
u 撤销命令
cltr r 对撤销命令进行撤销
shift g 光标定义到最后
n shift g 定位到某一行
gg 光标定位到第一行
shift 4 定位到该行结尾
shift 6 定位到该行结尾
w 以单词为单位右移
b 以单词为单位左移
shift ~ 将对应的大写单词连续切换成小写,或者将小写切换成大写
r m 将光标所在的字符替换成 m (m 只是代指摸个字符)
shift r 进入替换模式(替换模式下,直接输入是替换光标下的字符,删除是返回被替换之前的字符)
(n)x 从左向右删除
(n) shift x 从右向左删除
h j k l 光标左下上右移动
底行模式
从命令模式 shift : 直接进入底行模式
! Linux命令 在vim 中直接运行 LInux 的命令
%s/字符a /字符 b /g 将所有字符 a 换成字符 b
vs 分屏(编写程序时常用)
cltr w w 在分屏中将光标切换到不同的界面
q 退出
gcc 和 g++
在编辑器 vim 中 编写好程序后,就需要利用编译器来编译程序
稍微复习一下,编译的过程主要是 预编译 编译 汇编 链接的过程组成,
预编译是生成C 语言文件,将头文件,宏定义等进行替换
编译则是生成了汇编文件,得到汇编语言文件
汇编后则是将汇编语言的文件变为可重定位的二进制文件
最后通过链接生成可执行文件
sudo yum install lrzsz
可以安装 gcc 和 g++
编译和执行
比如我写了顺序表的程序,有 seq .c seq.h 和 process.c
其中 seq.c 和 seq.h 是关于顺序表的头文件和对应函数
process 是 main 函数
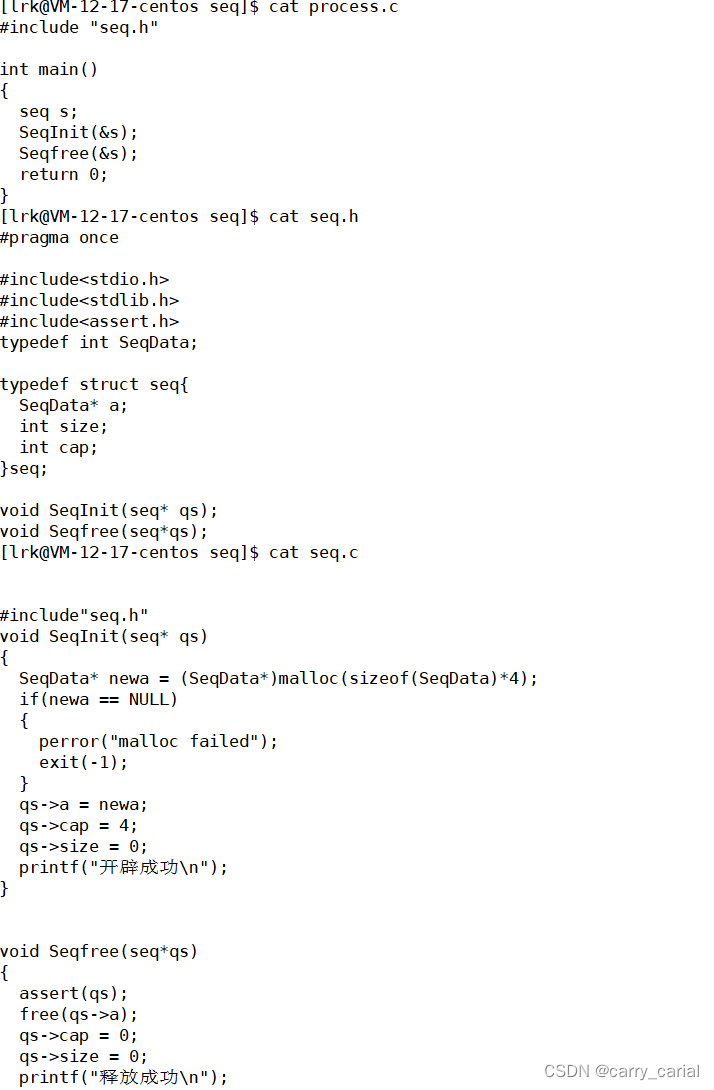
通过编译运行能够看到结果
gcc -o process process.c seq.c
编译必须要把源文件都加上
结果就是开辟了数组又释放了数组
执行可执行文件 ./process

我们可以用 Linux 看一下编译的过程
预编译
利用命令
gcc -E process.c -o process.i
能够得到对应的预编译后代码
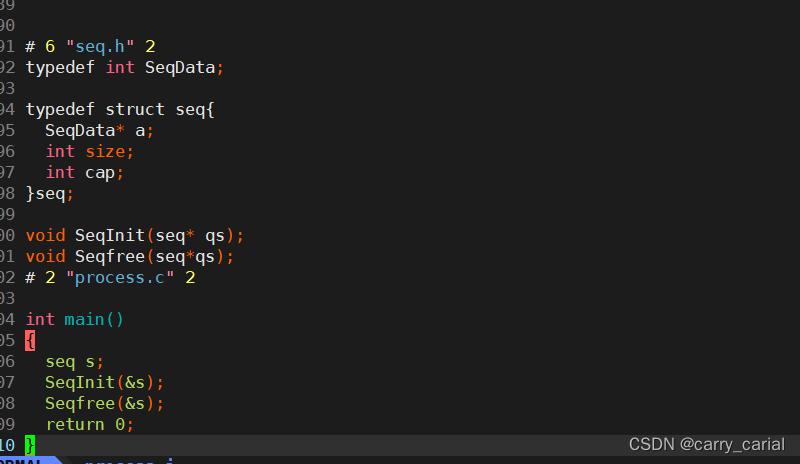
前面还有很多内容,可以看到 预编译把头文件和 .h 中的内容替换到源文件中了
编译
通过命令
gcc -S process.i -o process.s
记住 是要 .i 文件得到.s 文件
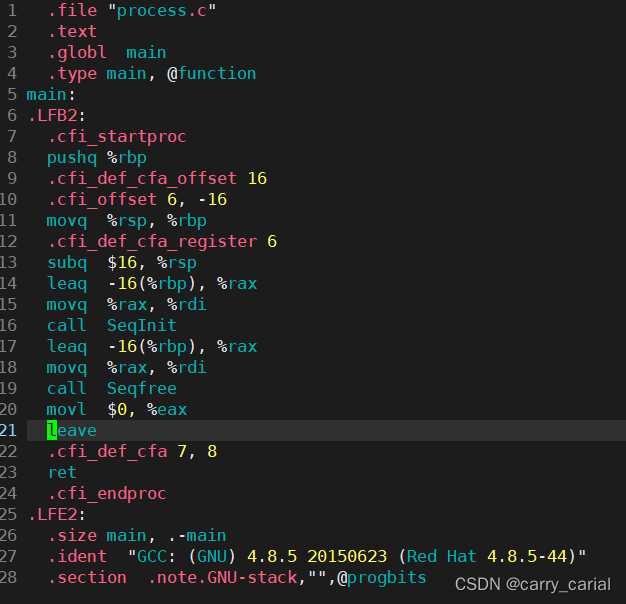
然后能够看到得到的是包含一堆标识符 (汇编语言) 的文件
汇编
汇编得到的是可重定位的二进制文件
通过命令
gcc -c process.c -o process.o
能够得到二进制文件
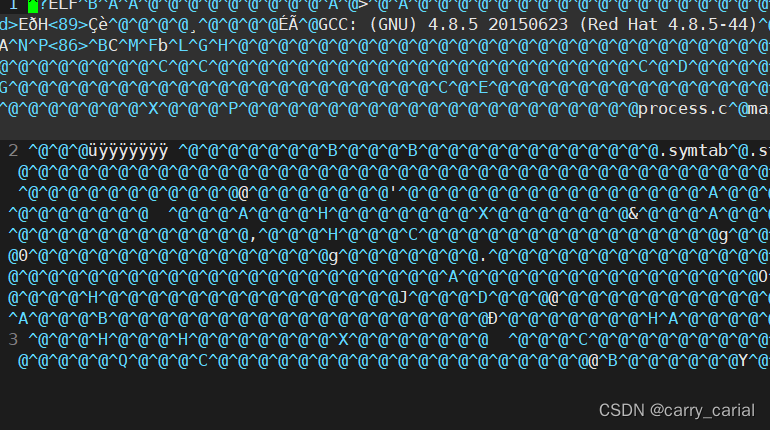
里面就是乱码了,因为是二进制文件
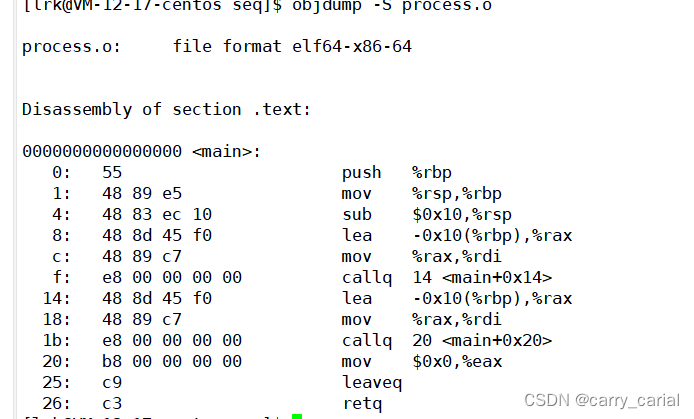
通过反汇编命令
objdump -S process.o
能够重新的到对应的汇编代码
链接过程
链接分为动态库的链接和静态库的链接
有一些函数是我们源文件就实现的函数,这个就直接使用就可以
但是像一些 printf 的函数,我们的头文件只有 stdio.h 的头文件,我们如何执行这个 printf 呢?
这个时候就需要链接来帮忙了
程序发现自己没有这个函数,但是有头文件,就会找编译器帮忙,编译器发现,这个是库函数,自己安装有(编译器安装的时候许多内容就是安装库),就去自己的默认文件夹寻找了(/usr/lib 这个是 Linux 下的文件夹)
同时编译器有两种方式帮助程序实现这个函数功能
一种是,把对应的库函数的地址交给程序,程序要运行的时候通过地址找到对应库的对应函数来实现功能
这种叫做动态库
还有一种,则是将整个要使用的库交给程序,程序运行时自己有库,就直接运行,这种叫做静态库

通过 ldd 这个命令,这个命令能列出动态库依赖关系
中间标红的就是 process 这个可执行文件依赖了 libc 这个 c标准库,同时 .so 表示是动态库
利用 file 命令

也能够看到是动态链接
make
由于我们经常可能输错命令,构建自动化编译的过程是很有必要的
自动化构建就是 用一个文档,将常用的命令集合起来,不用关心文件的依赖关系,利用简单的命令就能够完成文件的编译和删除
这个集合常放在 Makefile 中,这个 命令就是 make
现在文件只有这些

创建 Makefile 并且进入
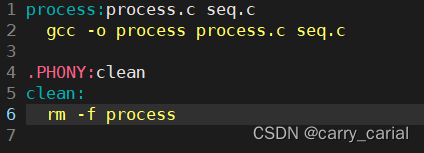
process:process.c seq.c
说明的是依赖关系, process 是可执行文件,来源于 process.c 和 seq.c
gcc -o 的命令是依赖方式,说明利用这个命令得到 process
.PHONY 是一个伪目标,说明这个命令(现在是 clean)总是执行
如果没有 .PHONY
比如在 process 前就没有 那么生成的 process 文件有修改时间,process.c 和 seq.c 都有修改时间
当 process 的时间比 process.c 的时间新,就不会执行这个命令
如果 process.c 的修改时间更新 就会执行
有了 .PHONY 就忽略时间总是执行
clean :
说明这个指令没有依赖文件,直接执行
结果
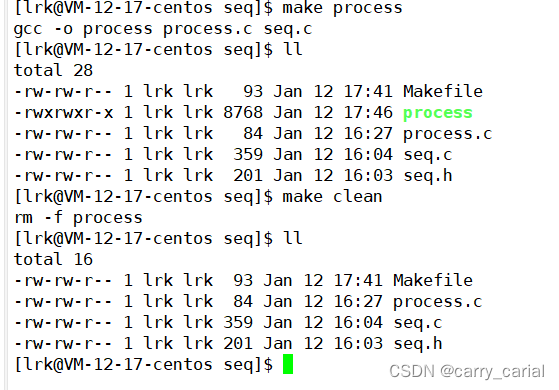
原来没有process (绿色)文件,现在 make process 后有了
make clean 后,这个文件又会消失,被清除了
可以看到我就不用那么长的代码,直接就自动编译了,爽死
总结
希望大家看完,能够有所收获
如果有错误,请指出我一定虚心改正
动动小手点赞
鼓励我输出更加优质的内容





![基于YOLOv5+C3CBAM+CBAM注意力的海底生物[海参、海胆、扇贝、海星]检测识别分析系统](https://img-blog.csdnimg.cn/img_convert/df21899986d75fb72e8d3291ac8b7a60.png)