在MYSQL数据库集文章中,仔细的学习了一些MYSQL数据库的知识。但是,随着我们的业务越来越好,那么我们不可能直接去操作MYSQL数据库。因为直接去操作MYSQL终究会有比较多的I/O操作,而使整个系统的性能最终受到数据库I/O的制约而无法承载。所以,我们一般会给服务器加入缓存,这样客户端的操作可以直接操作缓存,从而减轻数据库的压力。而NOSQL中的redis比较常用的场景就是作为缓存。
当我们引入缓存之后,怎么样去更新缓存和数据库的数据呢?
先更新数据库,再更新缓存
先更新缓存,再更新数据库
先删除缓存,再更新数据库
先更新数据库,再删除缓存
先更新数据库,再更新缓存
假如我们有「请求 A 」和「请求 B 」两个请求,同时更新「同一条」数据,则可能出现这样的顺序:
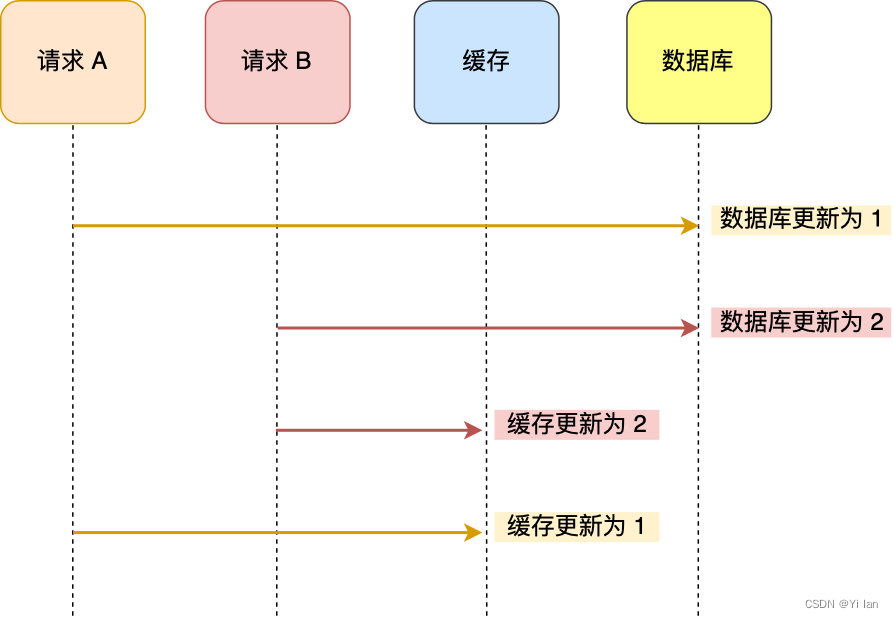
图解析说明:
「请求 A 」先把数据库的数据更新为1,然后在更新缓存之前,「请求 B 」再将数据库的数据更新为2,紧接着把缓存数据更新为2,然后「请求 A 」才更新缓存数据为1.
可以看出,这个时候数据库的数据是2,而缓存的数据是1,这就出现了数据库和缓存数据不一致现象。
先更新缓存,再更新数据库
和先更新数据库,再更新缓存同样的例子,但顺序不一样:
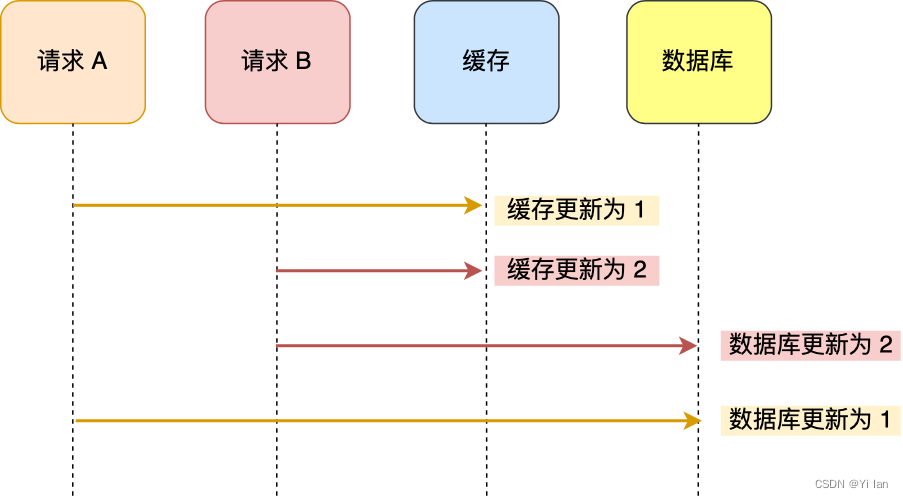
图解析说明:
「请求 A 」先将缓存的数据更新为 1,然后在更新数据库前,「请求 B 」将缓存的数据更新为 2,紧接着把数据库更新为 2,然后「请求 A 」才将数据库的数据为1.
可以看出,这个时候数据库的数据是1,而缓存的数据是2,这样也出现了数据库和缓存数据不一致现象。
所以,不管是「先更新数据库,再更新缓存」,还是「先更新缓存,再更新数据库」,这两个方案都存在并发问题。即当两个请求并发更新同一条数据的时候,可能会出现缓存和数据库中的数据不一致的现象。
先删除缓存,再更新数据库
假如我们有「请求 A 」和「请求 B 」两个请求,同时操作「同一条」数据,则可能出现这样的顺序:
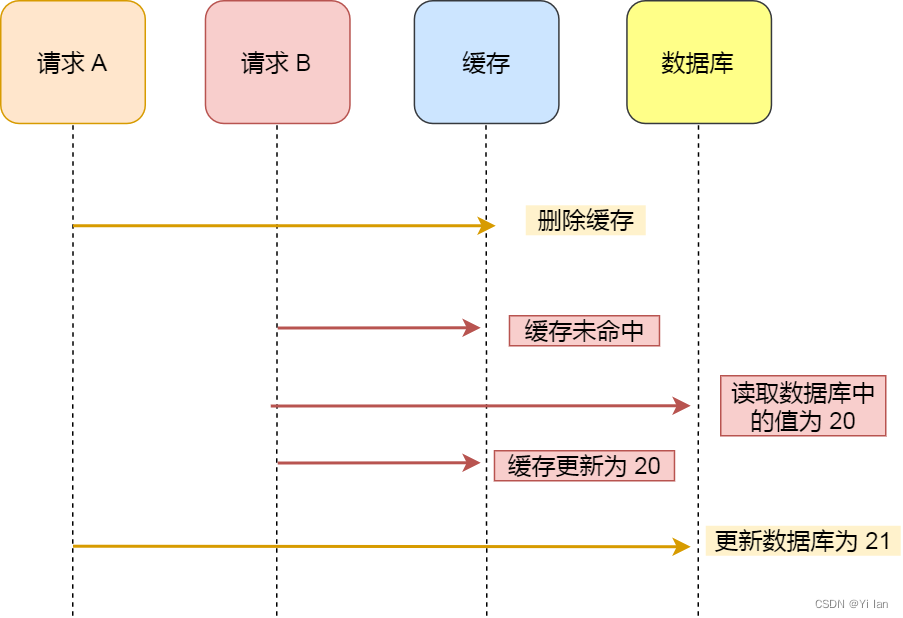
图解析说明:
「请求 A 」先将缓存的数据删除,然后在更新数据库前,「请求 B 」来读取数据,但是没有在缓存中命中,所以「请求 B 」会去数据库读取数据,并更新到缓存中去,然后「请求 A 」才将数据库的数据。
可以看出,这个时候数据库的数据是20(旧值),而缓存的数据是21(新值),这样也出现了数据库和缓存数据不一致现象。
所以,先删除缓存,再更新数据库,在「读 + 写」并发的时候,还是会出现缓存和数据库的数据不一致的问题。
先更新数据库,再删除缓存
和「先更新数据库,再更新缓存」同样的例子,但顺序不一样:
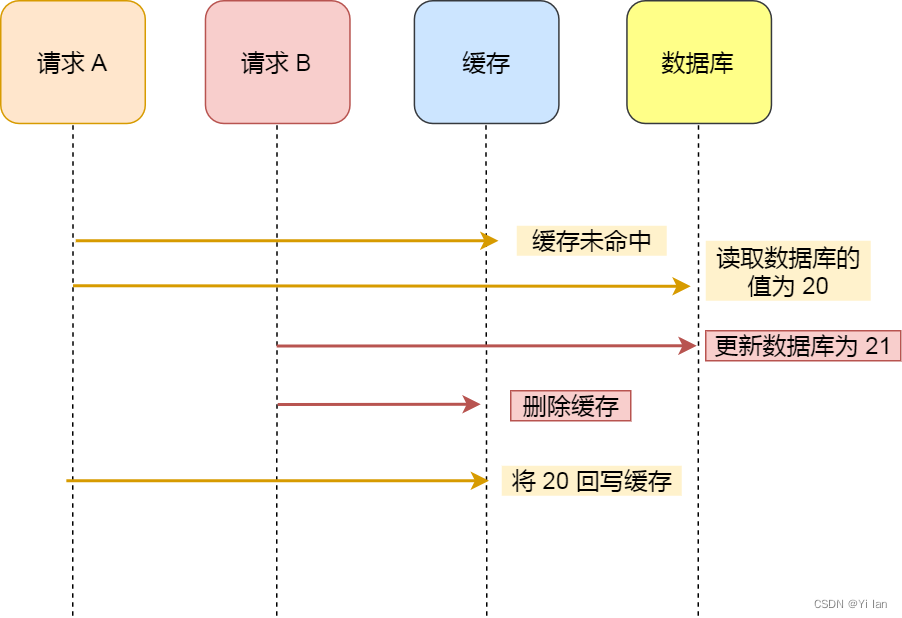
图解析说明:
「请求 A 」去读取数据,但是未在缓存中命中,去数据库读取数据,但是在数据库读取数据之后还没有更新缓存数据之前,「请求 B 」去更新数据库数据,然后删除缓存数据,然后「请求 A 」才更新缓存数据。
可以看出,这个时候数据库的数据是21(新值),而缓存的数据是20(旧值),这样也出现了数据库和缓存数据不一致现象。
从上面的理论上分析,先更新数据库,再删除缓存也是会出现数据不一致性的问题,但是在实际中,这个问题出现的概率并不高。因为缓存的写入通常要远远快于数据库的写入,所以在实际中很难出现请求 B 已经更新了数据库并且删除了缓存,请求 A 才更新完缓存的情况。所以,「先更新数据库 + 再删除缓存」的方案,是可以保证数据一致性的。
但是,为了确保万无一失,可以在缓存中加入过期时间,这样就算出现了缓存和数据库不一致问题,但最终是一致的。
从上面我们也知道「先更新数据库,再删除缓存」这属于两个操作,那么就会出现更新数据库成功,删除缓存失败的状态。如果出现这种状态,修改的数据是要过一段时间才生效,这个还是在我们加入过期时间的前提下。
那么怎么确保两个操作都能成功呢?
其实解决方案有两种,如下:
重试机制。
订阅 MySQL binlog,再操作缓存。
重试机制
我们可以引入消息队列,将第二个操作(删除缓存)要操作的数据加入到消息队列,由消费者来操作数据。
如果应用删除缓存失败,可以从消息队列中重新读取数据,然后再次删除缓存,这个就是重试机制。当然,如果重试超过的一定次数,还是没有成功,我们就需要向业务层发送报错信息了。
如果删除缓存成功,就要把数据从消息队列中移除,避免重复操作,否则就继续重试。
举个例子,来说明重试机制的过程。
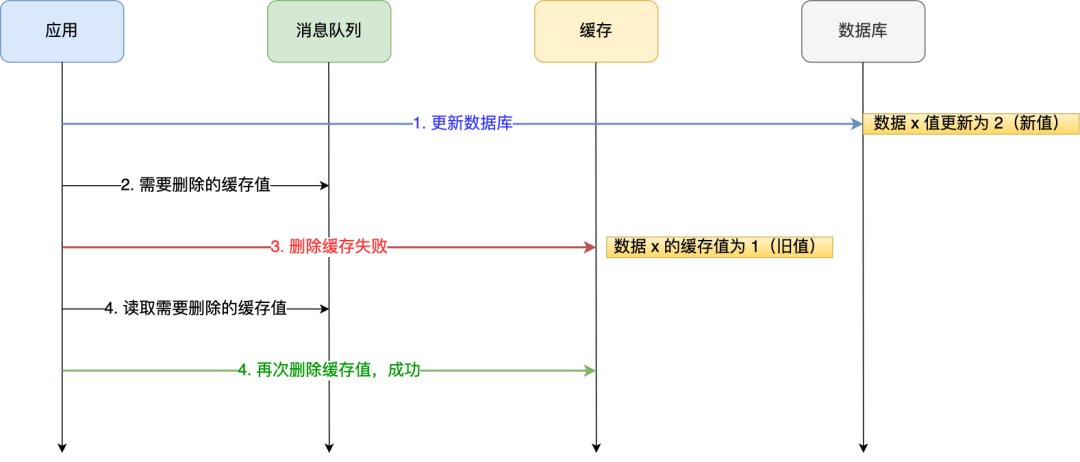
订阅 MySQL binlog,再操作缓存
「先更新数据库,再删缓存」的策略的第一步是更新数据库,那么更新数据库成功,就会产生一条变更日志,记录在 binlog 里。
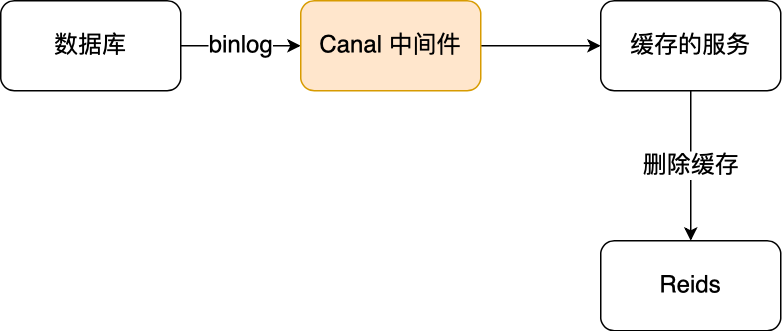
于是我们就可以通过订阅 binlog 日志,拿到具体要操作的数据,然后再执行缓存删除,阿里巴巴开源的 Canal 中间件就是基于这个实现的。
Canal 模拟 MySQL 主从复制的交互协议,把自己伪装成一个 MySQL 的从节点,向 MySQL 主节点发送 dump 请求,MySQL 收到请求后,就会开始推送 Binlog 给 Canal,Canal 解析 Binlog 字节流之后,转换为便于读取的结构化数据,供下游程序订阅使用。
下图是 Canal 的工作原理:
所以,如果要想保证「先更新数据库,再删缓存」策略第二个操作能执行成功,我们可以使用「消息队列来重试缓存的删除」,或者「订阅 MySQL binlog 再操作缓存」,这两种方法有一个共同的特点,都是采用异步操作缓存。
解决方案
在上面我们只知道「先更新数据库,再删缓存」的解决方案,那么其他的策略的问题能解决吗?
当然可以解决了
我们通过分析可以知道「先更新数据库,再更新缓存」和「先更新缓存,再更新数据库」(即两个更新)在并发的时候,出现数据不一致问题。主要是因为更新数据库和更新缓存这两个操作是独立的,而我们又没有对操作做任何并发控制,那么当两个线程并发更新它们的话,就会因为写入顺序的不同造成数据的不一致。所以,我们可以对这两个操作进行控制,方法如下:
在更新缓存前先加个分布式锁,保证同一时间只运行一个请求更新缓存,就会不会产生并发问题了,当然引入了锁后,对于写入的性能就会带来影响。
在更新完缓存时,给缓存加上较短的过期时间,这样即时出现缓存不一致的情况,缓存的数据也会很快过期,对业务还是能接受的。
对于「先删除缓存,再更新数据库」这种读 + 写」并发请求而造成缓存不一致的解决办法:
延迟双删
延迟双删实现的伪代码如下:
#删除缓存
redis.delKey(X)
#更新数据库
db.update(X)
#睡眠
Thread.sleep(N)
#再删除缓存
redis.delKey(X)
加了个睡眠时间,主要是为了确保请求 A 在睡眠的时候,请求 B 能够在这这一段时间完成「从数据库读取数据,再把缺失的缓存写入缓存」的操作,然后请求 A 睡眠完,再删除缓存。
所以,请求 A 的睡眠时间就需要大于请求 B 「从数据库读取数据 + 写入缓存」的时间。
但是睡眠多久这是一个玄学问题,很难估算出来。所以这个方案也只是尽可能保证一致性而已,极端情况下,依然也会出现缓存不一致的现象。
因此,还是比较建议用「先更新数据库,再删除缓存」的方案。




![基于YOLOv5+C3CBAM+CBAM注意力的海底生物[海参、海胆、扇贝、海星]检测识别分析系统](https://img-blog.csdnimg.cn/img_convert/df21899986d75fb72e8d3291ac8b7a60.png)