飞桨AI Studio星河社区-人工智能学习与实训社区
🥪图片爬取
import requests
import os
import urllib
class GetImage():
def __init__(self,keyword='大雁',paginator=1):
# self.url: 链接头
self.url = 'http://image.baidu.com/search/acjson?'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT\
10.0; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36'}
self.headers_image = {
'User-Agent': 'Mozilla/5.0 (Windows\
NT 10.0; WOW64) AppleWebKit/537.36 \
(KHTML, like Gecko) Chrome/69.0.\
3497.81 Safari/537.36',
'Referer': 'http://image.baidu.com/\
search/index?tn=baiduimage&ipn=r&\
ct=201326592&cl=2&lm=-1&st=-1&\
fm=result&fr=&sf=1&fmq=1557124645631_R&\
pv=&ic=&nc=1&z=&hd=1&latest=0©right\
=0&se=1&showtab=0&fb=0&width=&height=\
&face=0&istype=2&ie=utf-8&sid=&word=%\
E8%83%A1%E6%AD%8C'}
self.keyword = keyword # 定义关键词
self.paginator = paginator # 定义要爬取的页数
def get_param(self):
# 将中文关键词转换为符合规则的编码
keyword = urllib.parse.quote(self.keyword)
params = []
# 为爬取的每页链接定制参数
for i in range(1, self.paginator + 1):
params.append(
'tn=resultjson_com&ipn=rj&ct=201326592&is=&\
fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&o\
e=utf-8&adpicid=&st=-1&z=&ic=&hd=1&latest=0&\
copyright=0&word={}&s=&se=&tab=&width=&height\
=&face=0&istype=2&qc=&nc=1&fr=&expermode=&for\
ce=&cg=star&pn={}&rn=30&gsm=78&1557125391211\
='.format(keyword, keyword, 30 * i))
return params # 返回链接参数
def get_urls(self, params):
urls = []
for param in params:
# 拼接每页的链接
urls.append(self.url + param)
return urls # 返回每页链接
def get_image_url(self, urls):
image_url = []
for url in urls:
json_data = requests.get(url, headers=self.headers).json()
json_data = json_data.get('data')
for i in json_data:
if i:
image_url.append(i.get('thumbURL'))
return image_url
def get_image(self, image_url):
"""
根据图片url,在本地目录下新建一个以搜索关键字命名的文件夹,然后将每一个图片存入。
:param image_url:
:return:
"""
cwd = os.getcwd()
file_name = os.path.join(cwd, self.keyword)
if not os.path.exists(self.keyword):
os.mkdir(file_name)
for index, url in enumerate(image_url, start=1):
with open(file_name+'/{}_0.jpg'.format(index), 'wb') as f:
f.write(requests.get(url, headers=self.headers_image).content)
if index != 0 and index % 30 == 0:
print('第{}页下载完成'.format(index/30))
def __call__(self, *args, **kwargs):
params = self.get_param() # 获取链接参数
urls = self.get_urls(params)
image_url = self.get_image_url(urls)
self.get_image(image_url)
if __name__ == '__main__':
spider = GetImage('明星', 3)
spider()
# spider = GetImage('雕', 3)
# spider()-
初始化方法
__init__:-
设置了爬取图片的默认关键词为"大雁",默认页数为1
-
定义了百度图片搜索的请求头信息,其中包括了 User-Agent 和 Referer
-
-
get_param方法:-
将关键词转换为 URL 编码格式
-
构建每一页图片搜索结果的链接参数
-
-
get_urls方法:-
根据参数列表构建每一页图片搜索结果的完整链接
-
-
get_image_url方法:-
发送请求获取每一页的图片链接
-
解析 JSON 数据,提取每张图片的缩略图链
-
-
get_image方法:-
创建以搜索关键字命名的文件夹
-
下载图片并保存到本地文件夹中
-
-
__call__方法:-
调用上述方法实现图片下载功能
-

🥪图片爬取+图片保存
# 首先我们要导入相关的包
# request:提供爬虫相关的接口函数
# json:主要负责处理字典类型数据在字符串与字典之间进行转换
import requests
import json
import os
# 直接使用程序爬取网络数据会被网站识别出来,然后封禁该IP,导致数据爬
# 取中断,所以我们需要首先将程序访问页面伪装成浏览器访问页面
# User-Agent:定义一个真实浏览器的代理名称,表明自己的身份(是哪种浏览器),本demo为谷歌浏览器
# Accept:告诉WEB服务器自己接受什么介质类型,*/* 表示任何类型
# Referer:浏览器向WEB服务器表明自己是从哪个网页URL获得点击当前请求中的网址/URL
# Connection:表示是否需要持久连接
# Accept-Language:浏览器申明自己接收的语言
# Accept-Encoding:浏览器申明自己接收的编码方法,通常指定压缩方法,是
# 否支持压缩,支持什么压缩方法(gzip,deflate)
def getPicinfo(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36",
"Accept": "*/*",
"Referer": "https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&fenlei=256&rsv_pq=cf6f24c500067b9f&rsv_t=c2e724FZlGF9fJYeo9ZV1I0edbhV0Z04aYY%2Fn6U7qaUoH%2B0WbUiKdOr8JO4&rqlang=cn&rsv_dl=ib&rsv_enter=1&rsv_sug3=15&rsv_sug1=6&rsv_sug7=101",
"Host": "sp0.baidu.com",
"Connection": "keep-alive",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7,zh-TW;q=0.6",
"Accept-Encoding": "gzip, deflate"
}
# 根据url,使用get()方法获取页面内容,返回相应
response = requests.get(url,headers)
# 成功访问了页面
if response.status_code == 200:
return response.text
# 没有成功访问页面,返回None
return None
#图片存放地址
Download_dir='picture'
if os.path.exists(Download_dir)==False:
os.mkdir(Download_dir)
pn_num=1 # 爬取多少页
rn_num=10 # 每页多少个图片
for k in range(pn_num): # for循环,每次爬取一页
url="https://sp0.baidu.com/8aQDcjqpAAV3otqbppnN2DJv/api.php?resource_id=28266&from_mid=1&&format=json&ie=utf-8&oe=utf-8&query=%E4%B8%AD%E5%9B%BD%E8%89%BA%E4%BA%BA&sort_key=&sort_type=1&stat0=&stat1=&stat2=&stat3=&pn="+str(k)+"&rn="+str(rn_num)+"&_=1613785351574"
res = getPicinfo(url) # 调用函数,获取每一页内容
json_str=json.loads(res) # 将获取的文本格式转化为字典格式
figs=json_str['data'][0]['result']
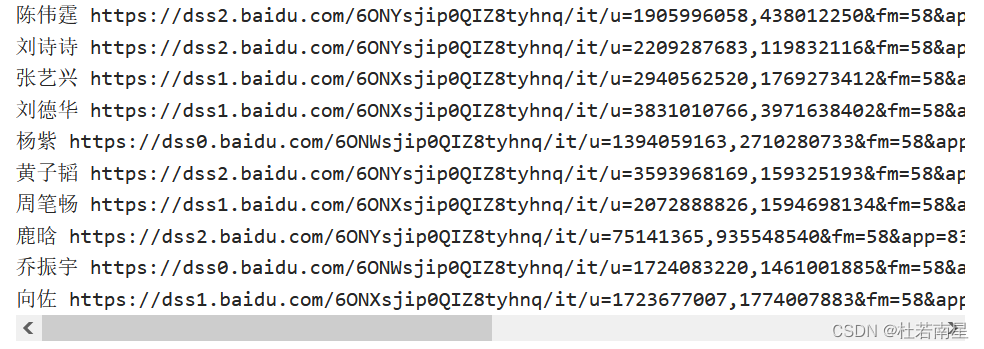
for i in figs: # for循环读取每一张图片的名字
name=i['ename']
img_url=i['pic_4n_78'] # img_url:图片地址
img_res=requests.get(img_url) # 读取图片所在页面内容
if img_res.status_code==200:
ext_str_splits=img_res.headers['Content-Type'].split('/')
ext=ext_str_splits[-1] # 索引-1指向列表倒数第一个元素
fname=name+"."+ext
# 保存图片
open(os.path.join(Download_dir,fname), 'wb' ).write(img_res.content)
print(name,img_url,"saved")-
首先定义了一个函数
getPicinfo(url),用于获取指定URL页面的内容。在请求头部添加了一些信息以伪装成浏览器访问页面,避免被网站封禁IP。通过requests.get(url, headers)方法发送GET请求,并返回响应的文本内容 -
创建一个目录
Download_dir用于存放下载的图片。如果目录不存在,则创建目录 -
设置要爬取的页数
pn_num和每页的图片数量rn_num -
使用for循环爬取每一页的图片。构造相应的URL,并调用
getPicinfo(url)函数获取每一页的内容 -
将获取的文本内容转化为字典格式
json_str=json.loads(res) -
提取每张图片的名称和地址,并使用
requests.get(img_url)方法获取图片所在页面的内容 -
如果成功获取到图片内容(状态码为200),则通过
open()函数将图片保存到指定的目录中 -
打印图片的名称、地址和保存成功的提示信息
🥗有问题我们评论区见~
⭐点赞收藏不迷路~