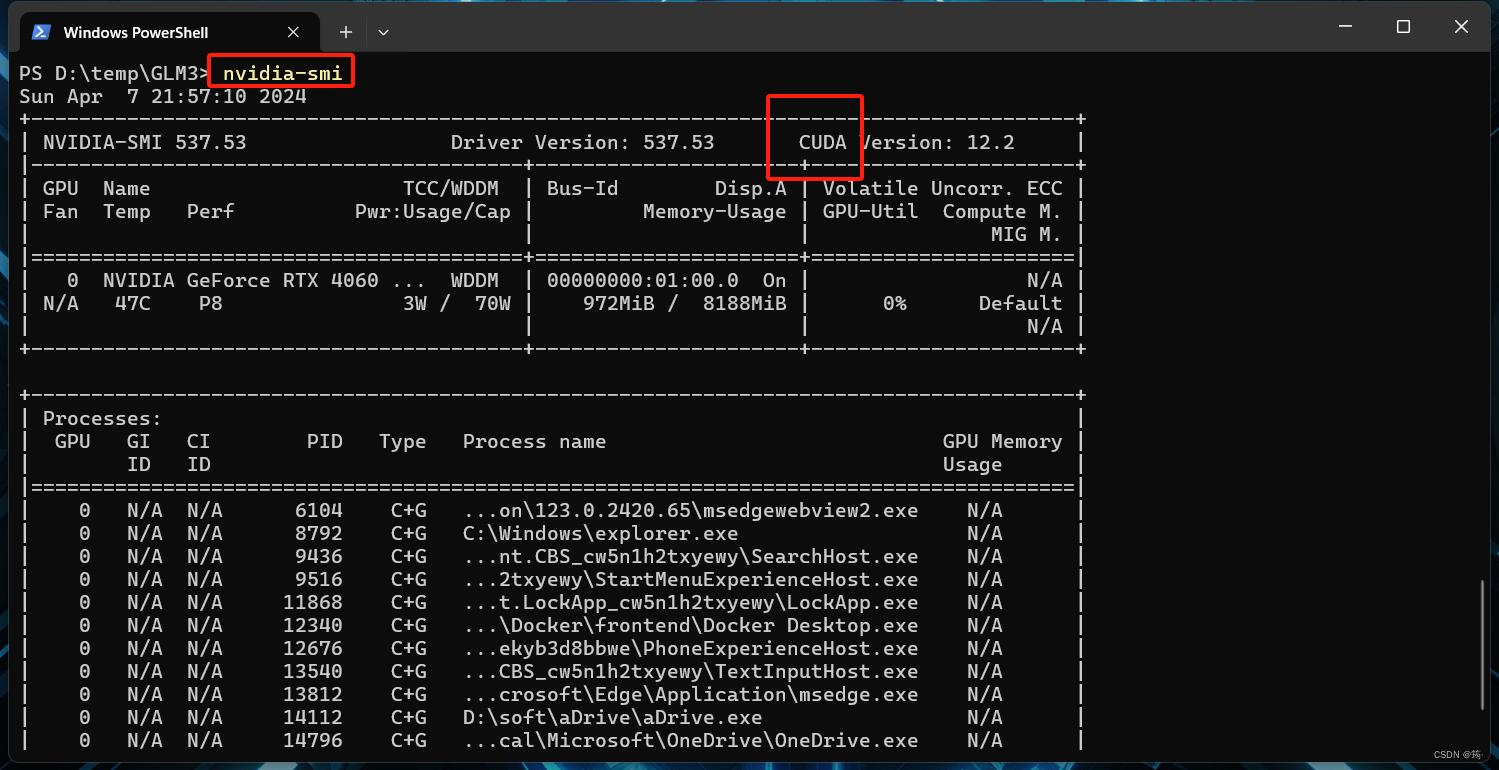
首先,检查一下自己的电脑有没有CUDA环境,没有的话,去安装一个。我的电脑是4060显卡,买回来就自带这些环境了。没有显卡的话,也不要紧,这个懒人安装包支持CPU运行,会自动识别没有GPU,就会以CPU运行,但是非常慢,毫无意义。
------------------------------------------------------懒人一键启动 start-----------------------------------------------------------------------------------------
1、下载一键安装包,解压后放到一个不带中文和特殊字符的路径
链接:https://pan.baidu.com/s/1ishHMyGpUkVjPVQk1GBGGA
提取码:Zh6L
2、直接运行脚本,就能启动成功了
3、到这里,可以不用往下看了。
但是,作为一名java程序员,怎能不使用docker部署一个。下面,是docker方式部署。
---------------------------------------------------------懒人一键启动end---------------------------------------------------------------------------------------------------
--------------------------------------------------------docker容器启动 start---------------------------------------------------------------------------------------------------
拉取镜像
拉取一个Nvidia官方docker镜像,免去在容器中手动安装cuda、cudnn的烦恼。
docker pull nvcr.io/nvidia/pytorch:23.05-py3运行容器
docker run --gpus all -itd --name chatglm3 -p 81:80 -p 6006:6006 -p 8888:8888 -p 7860:7860 -p 8501:8501 -p 8000:8000 --shm-size=32gb -v D:\temp\GLM3:/data nvcr.io/nvidia/pytorch:23.05-py3如果没有GPU,就把 --gpus all 参数去掉,--shm-size=32gb是计算机的内存,我的是32G。
D:\temp\ChatGLM3 是挂载目录,就是刚刚下载解压的安装包目录,改成你自己的目录就行。
进入容器内部
docker exec -it chatglm3 /bin/bash进入data目录
cd /data安装依赖
pip config set global.index-url https://mirrors.aliyun.com/pypi/simplepip config set install.trusted-host mirrors.aliyun.compip install -r requirements.txt进入目录
cd openai_api_demo/下载依赖
pip install -r requirements.txt返回上一层目录,进入ChatGLM3目录,执行启动脚本
cd ChatGLM3nohup sh 02startApi.sh &02startApi.sh脚本内容为:
#!/bin/bash
export HF_ENDPOINT=https://hf-mirror.com
export HF_HOME=../huggingface
export MODEL_PATH=../../models/THUDM_chatglm3-6b
cd openai_api_demo
python openai_api.py如果运行报错,就用idea或者其他工具,转换一下格式,转成linux格式。(鼠标选中文件,就有这个选项了)

不出意外的话,就启动成功了,使用postman等接口调用工具就可以调用接口了。
这是我的java调用代码
private static void chatglm3() {
Map<String, Object> params = new HashMap<>();
params.put("model", "chatglm3-6b");
List<Map<String, Object>> messages = new ArrayList<>();
Map<String, Object> prompt = new HashMap<>();
prompt.put("role", "user");
prompt.put("content", "给我讲一个笑话");
messages.add(prompt);
params.put("messages", messages);
params.put("stream", false);
params.put("max_tokens", 100);
// params.put("temperature", 0.8);
// params.put("top_p", 0.8);
String url = "http://127.0.0.1:8000/v1/chat/completions";
String result = post(url, JSONUtil.toJsonStr(params), new HashMap<>());
System.out.println(result);
}---------------------------------------------------------------docker 容器启动end------------------------------------------------------------------------
接下来,记录一下,将容器导出成镜像,并且把模型文件和代码文件一起打包到镜像中,方便以后在别的服务器上一键部署。
导出镜像命令:
docker commit [CONTAINER_ID_OR_NAME] [REPOSITORY_NAME]:[TAG]
-
[CONTAINER_ID_OR_NAME]是您的容器ID或名称。 -
[REPOSITORY_NAME]是您想要给新镜像起的名字。 -
[TAG]是镜像的标签,通常用于区分同一个镜像的不同版本,默认为latest。
最终命令是:
docker commit chatglm3 chatglm3-cwp:v1.0.1在懒人安装包解压目录下创建一个Dockerfile文件,文件内容为:
FROM chatglm3-cwp:v1.0.1
MAINTAINER cwp
COPY ChatGLM3 /data
COPY models /data
ENV TZ=Asia/Shanghai
EXPOSE 81
EXPOSE 8000
EXPOSE 7860
EXPOSE 8501
EXPOSE 8888
EXPOSE 6006
构建镜像
docker build -t chatglm3-gpu:1.0 .将镜像推送到自己的阿里云镜像仓库
阿里云镜像仓库访问地址 https://cr.console.aliyun.com/cn-hangzhou/instances
可以新建一个镜像仓库
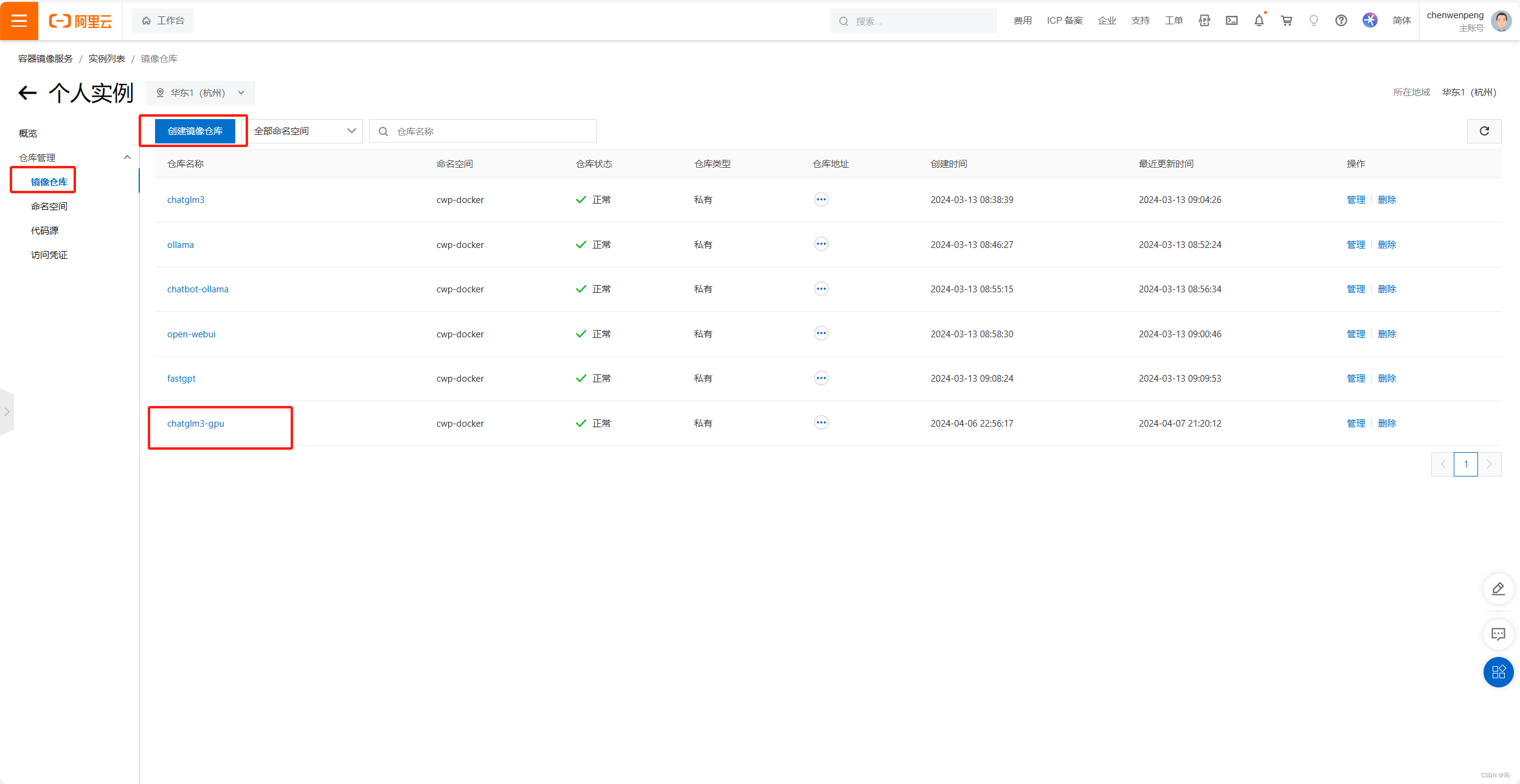
跟着操作指南一步步做,最后推送到镜像仓库。
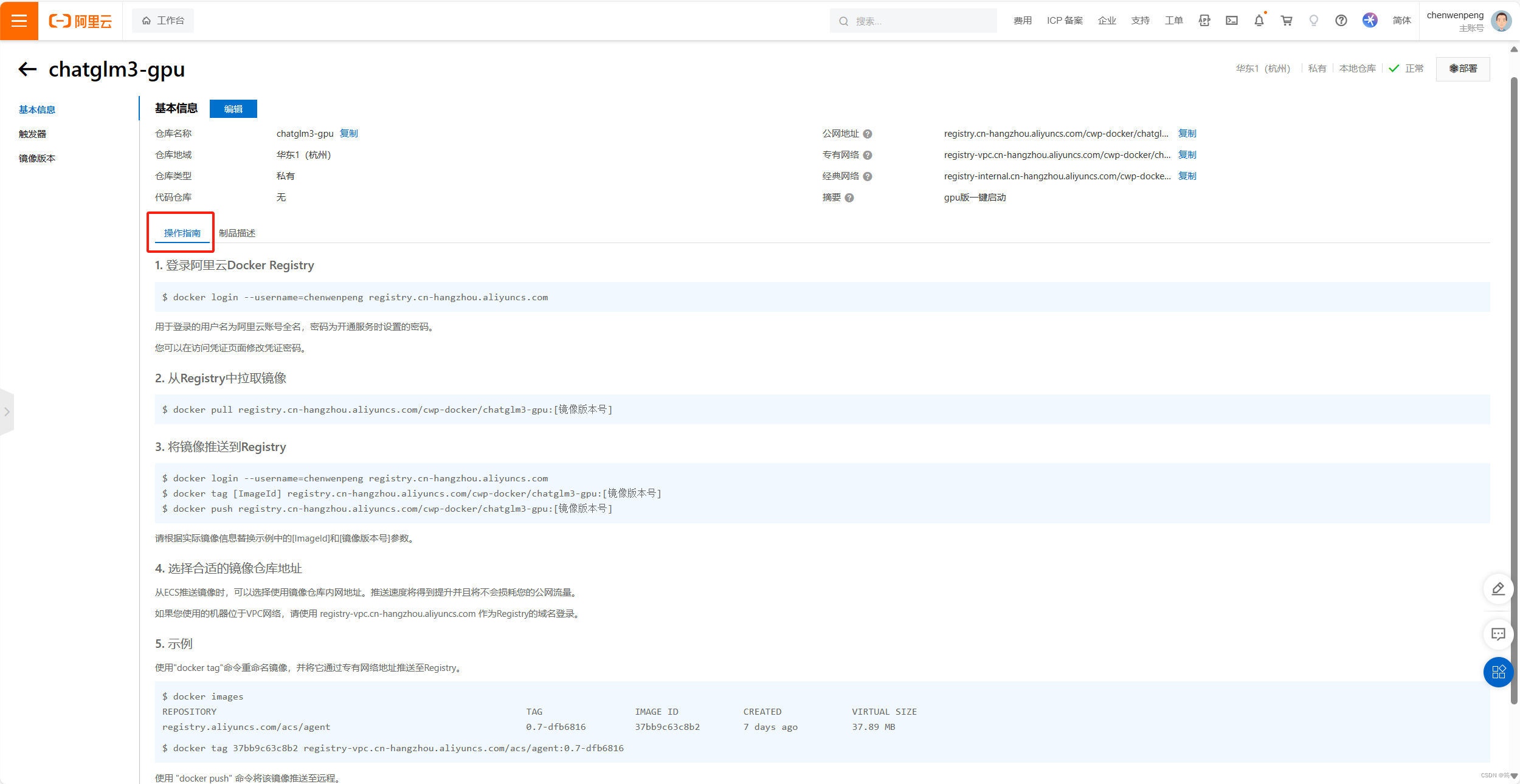
以后就可以拉取自己的阿里云镜像,运行容器,一键启动ChatGLM3。参照下一篇文章,轻轻松松搭建自己的GPT了。
docker一键部署GPU版ChatGLM3-CSDN博客