参考
【数据挖掘】基于XGBoost的垃圾短信分类与预测
【分类】使用XGBoost算法对信用卡交易进行诈骗预测
银行卡电信诈骗危险预测(LightGBM版本)
【数据挖掘】基于XGBoost的垃圾短信分类与预测
基于XGBoost的垃圾短信分类与预测
我分享了一个项目给你《【数据挖掘】基于XGBoost的垃圾短信分类与预测》,快来看看吧
1. 导入模块
import jieba,wordcloud,re,csv
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn import metrics
import xgboost as xgb
import warnings
warnings.filterwarnings('ignore')
from matplotlib import font_manager
font_path = "ZhuqueFangsong-Regular.ttf"
font_manager.fontManager.addfont(font_path)
prop = font_manager.FontProperties(fname=font_path)
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.sans-serif'] = prop.get_name()
plt.rcParams['axes.unicode_minus'] = False
2. 数据读取及预处理
df = pd.read_csv("/home/mw/input/spammessage3546/垃圾短信分类数据集.csv")
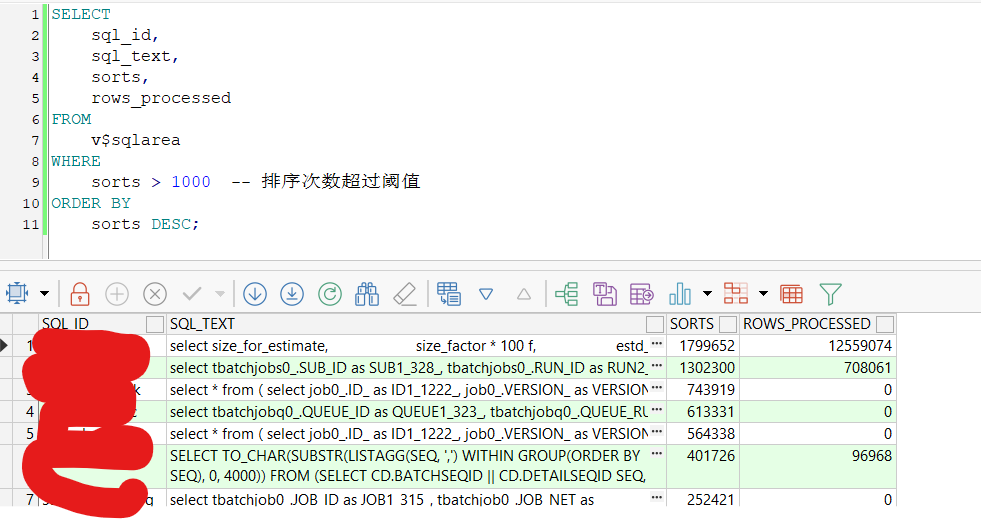
df.head()
输出如下:
df.info()
输出如下:

通过查看数据信息,发现
数据集的Text列存在缺失值,由于该列是记录短信内容,无法进行生成填充,所以在此处进行直接删除处理
数据集各列的类型合理,无需进行类型转换处理
## 删除缺失值
df.dropna(axis=0,inplace=True)
## 删除重复值
df.drop_duplicates(inplace=True)
##
df = df.reset_index(drop=True)
3. 数据可视化
3.1 观测值数量分布
## 查看观测值的分布情况
k,v = df["Label"].value_counts().index.tolist(), df["Label"].value_counts().values.tolist()
k = ["垃圾短信" if x==0 else "正常短信" for x in k]
print("k ",k)
print("v ",v)
输出如下

fig,ax = plt.subplots(1,1,figsize=(9,6),dpi=100)
ax.pie(v, labels=k,
autopct='%1.1f%%',
startangle=90,
textprops={'fontsize': 16},
wedgeprops = {'linewidth': 1, "width":.4, 'edgecolor':'#000'},
pctdistance = .8)
plt.show()
输出如下:
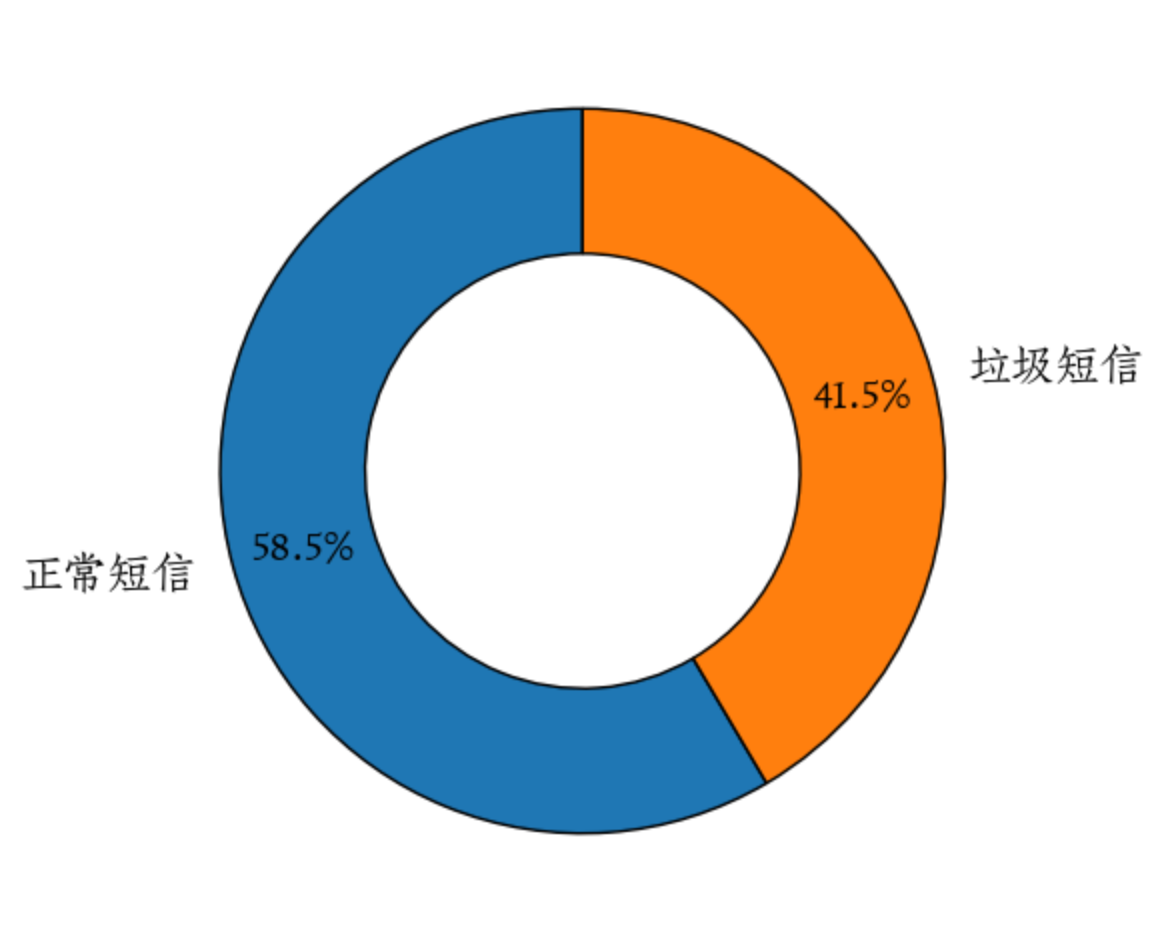
根据上述饼图所展示的内容:
数据集中正常短信的数量占比为58.5%,略高于垃圾短信的数量占比(41.5%)
正常短信与垃圾短信的数量比接近1:1
3.2 垃圾短信的词云图
## 读取停用词表
with open("/home/mw/input/stop6931/中文停用词库.txt","r",encoding="gbk") as f:
stopwords = f.read()
## Zero is Spam
def DrawWordcloud(tag):
words = []
def GetWordCounts(row):
row = "".join(re.findall(r'[\u4e00-\u9fff]+', row))
for r in jieba.lcut(row):
if len(r) > 1:
words.append(r.strip())
for i in df.query("Label == {}".format(tag))["Text"]:
GetWordCounts(i)
wc = wordcloud.WordCloud(
font_path="ZhuqueFangsong-Regular.ttf",
scale=4,
background_color='white',
stopwords=stopwords
)
wc.generate('/'.join(words))
fig = plt.figure(figsize=(10,8),dpi=120)
plt.imshow(wc)
plt.axis('off')
plt.show()
DrawWordcloud(0)
输出如下:

观察上述垃圾短信的词云图可以发现:
垃圾短信的内容主要集中在数据流量、招商证券等内容上,此外还出现有财富、收盘等字眼
初步概括,垃圾短信的内容主要与营销内容有关,更多的集中在营销推广这个方面
3.3 正常短信的词云图
DrawWordcloud(1)
输出如下:

与垃圾短信的内容相比,正常短信的内容有些许不同:
正常短信更多是由如中国移动、冲浪助手等相关机构发出的
此外还出现了一些关于社会新闻的短信内容
该类短信更具有社会实际意义
4. 分类建模预测
sw_l = stopwords.split("\n")
def CutCleanWord(text):
_ = "".join(re.findall(r'[\u4e00-\u9fff]+', text))
words = [word for word in jieba.cut(str(_).strip()) if word not in sw_l and word != ' ']
res = " ".join(words)
return res
## 分词
df["CutText"] = df["Text"].map(lambda x:CutCleanWord(x))
df["CutText"]
输出如下:

## 向量化
x_train,x_test,y_train,y_test = train_test_split(df["CutText"],df["Label"],test_size=.2,random_state=42)
vec = TfidfVectorizer(
max_features=80000,
ngram_range=(1, 2),
min_df=2,
max_df=0.96,
strip_accents='unicode',
norm='l2',
token_pattern=r"(?u)\b\w+\b")
vec.fit(df["CutText"])
x_train_ = vec.transform(x_train).toarray()
x_test_ = vec.transform(x_test).toarray()
# 原始数据
print("x_train[0:2] \n",x_train[0:2])
print("x_test[0:2] \n",x_test[0:2])
print("y_train[0:2] \n",y_train[0:2])
print("y_test[0:2] \n",y_test[0:2])
输出如下:

# 向量后的数据
print("x_train_[0:2] shape \n",x_train_.shape," \n x_train_[0:2] \n",x_train_[0:2])
print("x_test_[0:2] shape \n",x_test_[0:2].shape," \n x_test_[0:2] \n",x_test_[0:2])
for i in x_train_[0]:
print(i,end=' ')
输出如下:


## 构建xgboost分类模型
model = xgb.XGBClassifier(
objective = 'binary:logistic',
max_depth = 2,
learning_rate = 0.05,
n_estimators = 100,
silent = False,
random_state=42
)
model.fit(x_train_, y_train)
输出如下:
XGBClassifier
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, device=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=2, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
multi_strategy=None, n_estimators=100, n_jobs=None,
num_parallel_tree=None, random_state=42, …)
acc1 = metrics.accuracy_score(y_train, model.predict(x_train_))
print("模型在训练集上的预测准确率:{}%".format(round(acc1,4)*100))
输出如下:
模型在训练集上的预测准确率:81.36%
## 模型在测试集上的预测准确率
y_pred = model.predict(x_test_)
acc2 = metrics.accuracy_score(y_test, y_pred)
print("模型在测试集上的预测准确率:{}%".format(round(acc2,4)*100))
print("\n\n模型在训练集到测试集上的预测准确率变化了:{}%".format(round((acc2-acc1)*100,2)))
模型在测试集上的预测准确率:78.12%
模型在训练集到测试集上的预测准确率变化了:-3.24%
## 模型在测试集上的预测结果的分类
print(metrics.classification_report(y_test, y_pred))
输出如下:
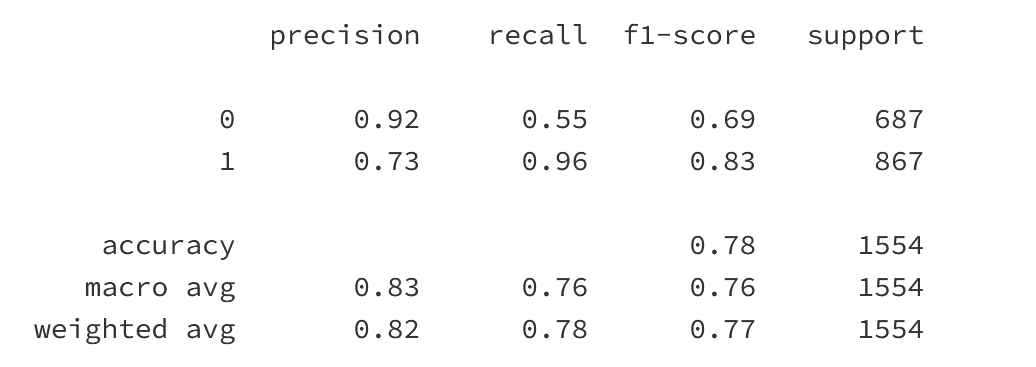
根据上述建模预测过程:
- 模型在训练集上的预测准确率为
81.36%,在测试集上的预测准确率为78.12% - 模型在训练集到测试集的预测准确率变化中呈下降结果,预测准确率降低了
3.24% - 在分类报告中,模型针对类别为
1即正常短信的预测F1得分为0.83,但在针对类别为0即垃圾短信的预测F1得分为0.69,这说明模型对类别为1的短信分类识别能力好于识别类别为0的能力
5. 拓展
针对上述模型预测出现的不足之处,可以有以下的优化:
- 使用更为高级的分类模型
- 对XGBoost分类模型进行超参数优化
- 使用交叉验证提高模型的泛化能力
项目使用数据集 👉👉 垃圾短信分类数据集
银行卡电信诈骗危险预测(LightGBM版本)
参考
我分享了一个项目给你《【竞赛学习】LightGBM+贝叶斯优化预测银行卡电信诈骗》,快来看看吧








![[Redis]redis-windows下载安装与使用](https://i-blog.csdnimg.cn/direct/bb21edd5ca0c45449fc21c8a80cd4804.png)