各位读者老爷好,鼠鼠又来了捏!鼠鼠上一篇博客介绍的堆,那么今天来浅谈以下堆的应用,那么好,我们先来看两个问题:
1.如果有一组乱序的数组数据,希望你将这组数组的数据排成升序或降序,该怎么排?
2.如果有1万个乱序的数据,希望你找出其中最大的前5个,该这么找到捏?

目录
1.堆排序
1.1.堆排序代码
1.2.向下调整建堆法
1.3.堆排序的优势
2.Top_K 问题
2.1.Top_K问题代码
2.2.办法3优势
3.ending
对于问题1,当然可以使用冒泡排序,但是冒泡排序的时间复杂度是O(N^2),显然不是一个很好的方法!鼠鼠我呀在这里介绍一个解决办法:堆排序!堆排序的时间复杂度是O(N*logN),相对于解决办法之冒泡排序好用的不是一星半点捏!
1.堆排序
要注意堆排序是对数组本身进行排序。上一篇博客中的运行结果似乎也将数据排好序了,但数组本身没有排好序,是额外开辟了空间取数组元素全部入堆后再循环取堆顶数据并删除堆顶数据而成的,这样子不是真正的堆排序。
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1. 建堆
升序:建大堆
降序:建小堆
2. 利用堆删除思想来进行排序
1.1.堆排序代码
这篇博客我们以排降序为例讲解堆排序:
本鼠先把堆排序(降序)的代码呈现如下,老爷们有兴趣看看啊:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
typedef int HeapDataType;
//交换
void Swap(HeapDataType* a, HeapDataType* b)
{
HeapDataType tmp = *a;
*a = *b;
*b = tmp;
}
//向上调整(小堆)
void AdjustUp(HeapDataType* a, int childcoordinate)
{
int parentcoordinate = (childcoordinate - 1) / 2;
while (childcoordinate > 0)
{
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
childcoordinate = parentcoordinate;
parentcoordinate = (parentcoordinate - 1) / 2;
}
else
{
break;
}
}
}
//向下调整(小堆)
void AdjustDown(HeapDataType* a, int parentcoordinate, int HeapSize)
{
int childcoordinate = parentcoordinate * 2 + 1;
while (childcoordinate < HeapSize)
{
if (a[childcoordinate] > a[childcoordinate + 1] && childcoordinate + 1 < HeapSize)
{
childcoordinate++;
}
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
parentcoordinate = childcoordinate;
childcoordinate = childcoordinate * 2 + 1;
}
else
{
break;
}
}
}
//堆排序排降序
void HeapSort(HeapDataType* a, int HeapSize)
{
int i = 0;
//排降序,建小堆(向上调整建堆法)
for (i = 1; i < HeapSize; i++)
{
AdjustUp(a, i);
}
int end = HeapSize - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, 0, end);
end--;
}
}
int main()
{
int a[] = { 90,80,60,20,40,70,60,30,30,110 };
int Size = sizeof(a) / sizeof(a[0]);
printf("堆排序前:");
for (int i = 0; i < Size; i++)
{
printf("%d ", a[i]);
}
printf("\n");
HeapSort(a, Size);
printf("堆排序后:");
for (int i = 0; i < Size; i++)
{
printf("%d ", a[i]);
}
return 0;
}也许各位老爷对于这些个代码有点懵懵的,没关系,鼠鼠我来一点点分析上面代码:
首先我们来看这几个函数:
//交换
void Swap(HeapDataType* a, HeapDataType* b)
{
HeapDataType tmp = *a;
*a = *b;
*b = tmp;
}
//向上调整(小堆)
void AdjustUp(HeapDataType* a, int childcoordinate)
{
int parentcoordinate = (childcoordinate - 1) / 2;
while (childcoordinate > 0)
{
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
childcoordinate = parentcoordinate;
parentcoordinate = (parentcoordinate - 1) / 2;
}
else
{
break;
}
}
}
//向下调整(小堆)
void AdjustDown(HeapDataType* a, int parentcoordinate, int HeapSize)
{
int childcoordinate = parentcoordinate * 2 + 1;
while (childcoordinate < HeapSize)
{
if (a[childcoordinate] > a[childcoordinate + 1] && childcoordinate + 1 < HeapSize)
{
childcoordinate++;
}
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
parentcoordinate = childcoordinate;
childcoordinate = childcoordinate * 2 + 1;
}
else
{
break;
}
}
}
这几个函数上一篇博客已经介绍过了,分别是交换函数、向上调整函数和向下调整函数。只不过这里的向上调整函数和向下调整函数是服务小堆,而上一篇博客的向上调整函数和向下调整函数是服务大堆的,但是基本思想是不变的,这里鼠鼠就不多说了!
我们再来看下一个函数:
//堆排序排降序
void HeapSort(HeapDataType* a, int HeapSize)
{
int i = 0;
//排降序,建小堆(向上调整建堆法)
for (i = 1; i < HeapSize; i++)
{
AdjustUp(a, i);
}
int end = HeapSize - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, 0, end);
end--;
}
}这个函数就是堆排序函数了,排的是降序。参数a是待排序数组的指针,HeapSize是待排序数组(以下简称数组)的数据个数。
堆排序是这样子的:
1.建堆。首先我们先将数组本身建成小堆。这里我们采用向上调整建堆法,用一个for循环调用向上调整函数将待排序数组本身变成小堆。这里本质模拟的是堆插入的过程建堆。
2.利用堆删除思想来进行排序。数组已经是小堆了,那么堆顶的数据一定是最小的数据,我们再将堆顶数据与数组尾部数据交换,这样子数组尾部数据就是最小的,再调用向下调整函数将数组前HeapSize-1个数据成小堆;然后我们再将由前HeapSize-1个数据构成的小堆的堆顶数据(这个数据是次小的)与由前HeapSize-1个数据构成的小堆的最后一个数据(也就是数组倒数第二个数据)交换,这样子数组倒数第二个数据就是次小的,然后我们再调用向下调整函数将数组前HeapSize-2个数据成小堆…………这样就可以将数组数据变成降序的。
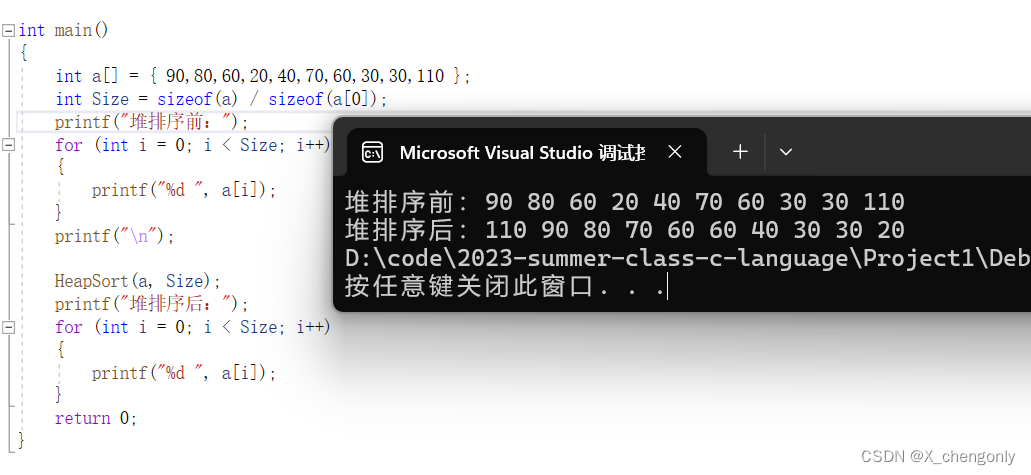
我们看运行结果确实是没问题的:
1.2.向下调整建堆法
上面堆排序的代码中我们第一步是将待排序数组建成小堆,我们用的是向上调整建堆法,其实我们还可以用向下调整建堆法。
就像这样:
//堆排序排降序
void HeapSort(HeapDataType* a, int HeapSize)
{
int i = 0;
//排降序,建小堆(向下调整建堆法)
for (i = (HeapSize-1-1)/2;i>=0;i--)
{
AdjustDown(a,i,HeapSize);
}
int end = HeapSize - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, 0, end);
end--;
}
}向下调整建堆法的思想就是先找到以数组尾部数据的父节点(这个父节点下标假设为n)为根的树,将这颗树用向下调整函数调成小堆,再将以下标为n-1的节点为跟的树用向下调整函数调成小堆,再将以下标为n-2的节点为跟的树用向下调整函数调成小堆……再将以下标为0的节点为跟的树用向下调整函数调成小堆那么整个数组数据就成了一个小堆。
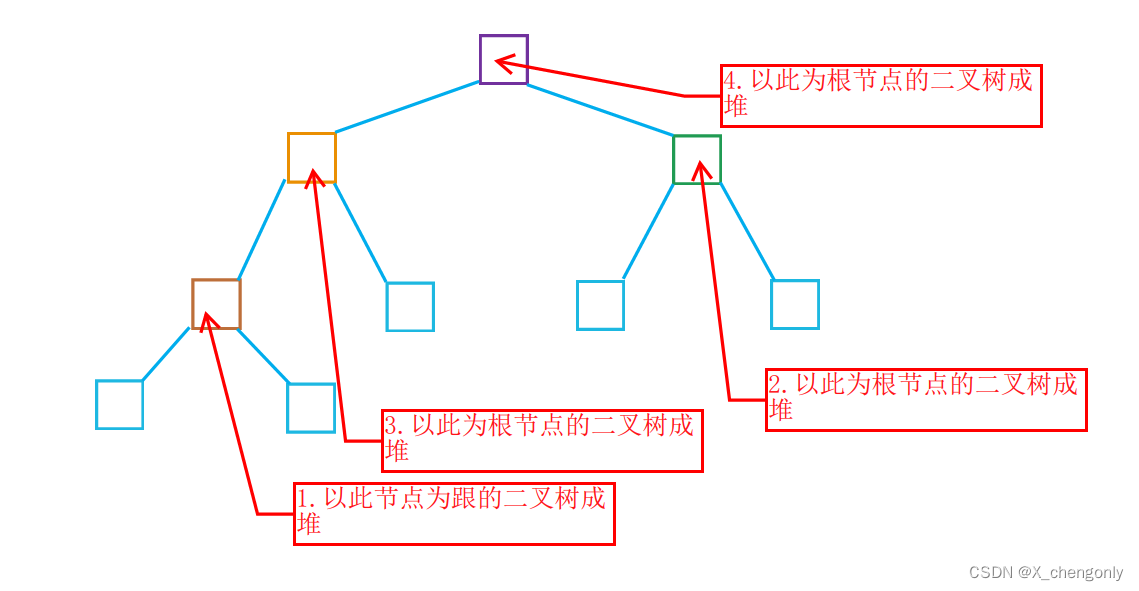
用向下调整建堆法的堆排序完整代码如下:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
typedef int HeapDataType;
//交换
void Swap(HeapDataType* a, HeapDataType* b)
{
HeapDataType tmp = *a;
*a = *b;
*b = tmp;
}
//向下调整(小堆)
void AdjustDown(HeapDataType* a, int parentcoordinate, int HeapSize)
{
int childcoordinate = parentcoordinate * 2 + 1;
while (childcoordinate < HeapSize)
{
if (a[childcoordinate] > a[childcoordinate + 1] && childcoordinate + 1 < HeapSize)
{
childcoordinate++;
}
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
parentcoordinate = childcoordinate;
childcoordinate = childcoordinate * 2 + 1;
}
else
{
break;
}
}
}
//堆排序排降序
void HeapSort(HeapDataType* a, int HeapSize)
{
int i = 0;
//排降序,建小堆(向下调整建堆法)
for (i = (HeapSize-1-1)/2;i>=0;i--)
{
AdjustDown(a,i,HeapSize);
}
int end = HeapSize - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, 0, end);
end--;
}
}
int main()
{
int a[] = { 90,80,60,20,40,70,60,30,30,110 };
int Size = sizeof(a) / sizeof(a[0]);
printf("堆排序前:");
for (int i = 0; i < Size; i++)
{
printf("%d ", a[i]);
}
printf("\n");
HeapSort(a, Size);
printf("堆排序后:");
for (int i = 0; i < Size; i++)
{
printf("%d ", a[i]);
}
return 0;
}运行结果是没问题的,跟上面用向上调整建堆法的堆排序结果一模一样。
这里用向下调整建堆法的堆排序是有以下优势的,所以我们写堆排序可以采用向下调整建堆法更佳:
1.堆排序的两个步骤都用向下调整函数即可,不必多写一个向上调整函数。
2.向上调整建堆法的时间复杂度是O(N*logN),而向下调整建堆法的时间复杂度是O(N),至于这些个复杂度为什么是这样子的鼠鼠就不证明了。
1.3.堆排序的优势
堆排序的时间复杂度是O(N*logN),为啥复杂度是这个,鼠鼠不证明了!如果有100万个乱序数据让我们排序的话,笼统的说,我们用堆排序要排2千万次,如果用冒泡排序的话我们要排1万亿次。
对于问题2,我们可以用以下方法解决:
1.利用上一篇博客实现的堆,将1万个数据依次插入堆中构成大堆,再循环5次操作:取堆顶数据并删除堆顶数据。这样子取出来的5个堆顶数据就是最大的前5个数据。这个方法的时间复杂度是O(N*logN),空间复杂度是O(N)。
2.读取1万个数据的前5个数据,将这5个数据本身建立成小堆,再依次取剩余的9千9百9十5个数据与小堆堆顶数据比较,如果大于堆顶数据就替换堆顶数据并再次利用向下调整函数再成堆,比较完剩余的9千9百9十5个数据后,小堆里面的数据就是最大的前5个数。这种方法就引出鼠鼠要介绍的堆的应用之Top_K问题。
2.Top_K 问题
TOP-K问题:即求数据集合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大(就是说从N个数据中求最大或最小的前K个数据,N远大于K)。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1.如果求最大的前K个数据:
取前k个元素,建小堆。用剩余的N-K个元素依次与堆顶元素来比较,如果大于堆顶元素替换堆顶元素并利用向下调整函数再成堆,剩余N-K个元素比较完后,堆中剩余的K个元素就是最大的前K个数。
2.如果求最小的前K个数据:
取前k个元素,建大堆。用剩余的N-K个元素依次与堆顶元素来比较,如果小于堆顶元素替换堆顶元素并利用向下调整函数再成堆,剩余N-K个元素比较完后,堆中剩余的K个元素就是最小的前K个数。
2.1.Top_K问题代码
思路我们解释完了,我们看一下代码:
鼠鼠用10万个随机数找出最大的前5个数为例子测试用堆来解决思路的可行性
#include<stdio.h>
#include<time.h>
#include<stdlib.h>
typedef int HeapDataType;
//交换
void Swap(HeapDataType* a, HeapDataType* b)
{
HeapDataType tmp = *a;
*a = *b;
*b = tmp;
}
//向上调整(小堆)
void AdjustUp(HeapDataType* a, int childcoordinate)
{
int parentcoordinate = (childcoordinate - 1) / 2;
while (childcoordinate > 0)
{
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
childcoordinate = parentcoordinate;
parentcoordinate = (parentcoordinate - 1) / 2;
}
else
{
break;
}
}
}
//向下调整(小堆)
void AdjustDown(HeapDataType* a, int parentcoordinate, int HeapSize)
{
int childcoordinate = parentcoordinate * 2 + 1;
while (childcoordinate < HeapSize)
{
if (a[childcoordinate] > a[childcoordinate + 1] && childcoordinate + 1 < HeapSize)
{
childcoordinate++;
}
if (a[parentcoordinate] > a[childcoordinate])
{
Swap(&a[parentcoordinate], &a[childcoordinate]);
parentcoordinate = childcoordinate;
childcoordinate = childcoordinate * 2 + 1;
}
else
{
break;
}
}
}
//找大的前K个数
void PrintfTop_K(HeapDataType* a, int Size, int K)
{
HeapDataType* minheap = (HeapDataType*)malloc(sizeof(HeapDataType) * K);
if (minheap == NULL)
{
perror("malloc fail");
exit(-1);
}
int i = 0;
//取a前K个数并建小堆
for (i = 0; i < K; i++)
{
minheap[i] = a[i];
AdjustUp(minheap, i);
}
int X = K;
for (X; X < Size; X++)
{
if (a[X] > minheap[0])
{
minheap[0] = a[X];
AdjustDown(minheap, 0, K);
}
}
for (i = 0; i < K; i++)
{
printf("%d ", minheap[i]);
}
free(minheap);
}
int main()
{
int Size = 100000;
HeapDataType* a = (HeapDataType*)malloc(sizeof(HeapDataType) * Size);
srand((unsigned int)time(0));
for (int i = 0; i < Size; i++)
{
a[i] = (rand() + i) % 100000;
}
//打入5个探子,将这5个探子的值更改成大于100000
a[9] = 110000;
a[99] = 111000;
a[999] = 111100;
a[9999] = 111110;
a[99999] = 11111111;
PrintfTop_K(a, Size, 5);
free(a);
a = NULL;
return 0;
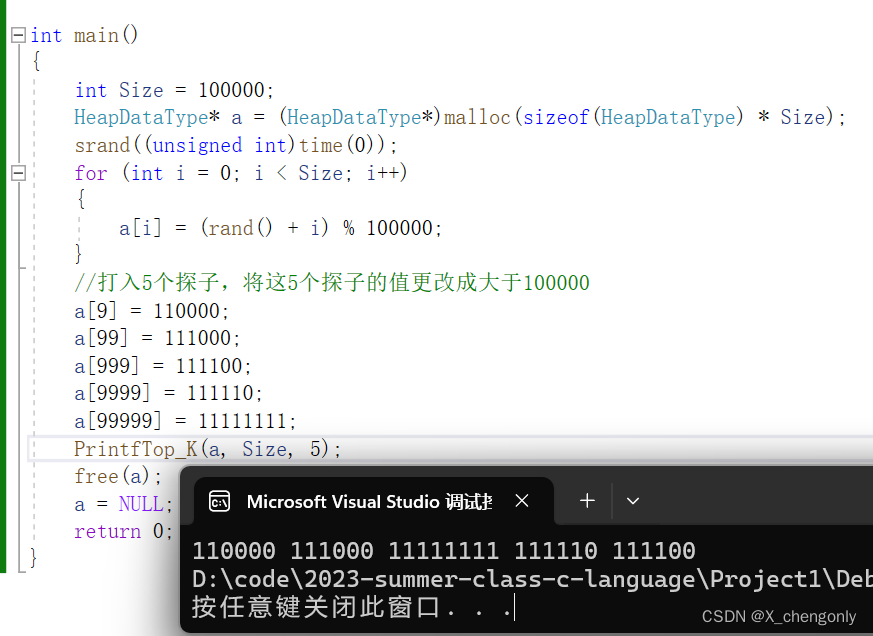
}看结果我们确实将5个探子找出来了,就是最大的前5个数:
2.2.办法3优势
我们再分析以下:
对于问题2的解决办法1来说,我们都需要将数据加载到内存中才行 ,如果加载的数据量太大的话,这个方法就行不通。比如有1百亿个int类型的数据要全部加载到内存的话差不多要40GB。而且这个办法的时间复杂度和空间复杂度都不如办法2。
对于问题2的解决办法2来说,是最好的解决办法,首先时间复杂度是O(N*logK),一般K都很小,那么时间复杂度就是O(N),空间复杂度很明显是O(1)。其次,一般不用担心内存不足的问题。
3.ending
鼠鼠我才疏学浅,上面的博客难免有错误,恳请读者老爷发现后指出,鼠鼠我很期待各位老爷的斧正呢!