urllib发送get请求
在目前网络获取数据的方式有多种方式:GET方式大部分被传输到浏览器的html,images,
js,css, … 都是通过GET
方法发出请求的。它是获取数据的主要方法
例如:www.baidu.com 搜索
Get请求的参数都是在Url中体现的,如果有中文,需要转码,这时我们可使用
urllib.parse. quote
from urllib.request import urlopen,Request
from urllib.parse import quote
args =input('请输入要搜索的内容:')
ua = UserAgent()
url = f'https://www.baidu.com/s?wd={quote(args)}'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT
10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/101.0.4951.64
Safari/537.36 Edg/101.0.1210.47'
}
req = Request(url,headers = headers)
resp = urlopen(req)
print(resp.read().decode())
urllib.parse.urlencode
from urllib.request import urlopen,Request
from urllib.parse import urlencode
args =input('请输入要搜索的内容:')
parms ={
'wd':args
}
url = f'http://www.baidu.com/s?ie=utf8&f=8&rsv_bp=1&tn=baidu&{urlencode(parms)}'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT
10.0; Win64; x64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/90.0.4430.212
Safari/537.36'
}
req = Request(url,headers = header)
resp = urlopen(req)
print(resp.read().decode())
实战-喜马拉雅网站
热门有声作品推荐_好听的音乐专辑在线收听 – 喜马拉雅 (ximalaya.com)![]() https://www.ximalaya.com/yinyue/
https://www.ximalaya.com/yinyue/
备注
了解如何分析URL地址,与构造URL参数的思路即可。使用别的
网站也可以测试,因为网站随时有可能会变
代码
from urllib.request import Request,urlopen
from time import sleep
def spider_music(_type,page):
# 构造URL地址
for num in range(1,page+1):
if num == 1:
url =
f'https://www.ximalaya.com/yinyue/{_type}'
else:
url =
f'https://www.ximalaya.com/yinyue/{_type}/p{num}/'
headers = {'User-Agent':'Mozilla/5.0
(Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/102.0.5005.63 Safari/537.36'}
# 构造请求对象
req = Request(url,headers=headers)
# 发送请求
resp = urlopen(req)
# 获取响应
print(resp.getcode())
print(resp.geturl())
# print(resp.read().decode()[:2000])
# 休眠
sleep(1)
if __name__ == '__main__':
spider_music('minyao',3)urllib发送post请求
在目前网络获取数据的方式有多种方式:POST
POST请求的参数需要放到Request请求对象中,data是一个字典,里面要匹配键值对
代码
from urllib.request import Request,urlopen
from urllib.parse import urlencode
url = 'https://www.kuaidaili.com/login/'
# 封装数据
data = {
'next': '/login/?next=%2F',
'login_type': '1',
'username': '398707160@qq.com',
'passwd': '111111111',
}
tru_data = urlencode(data).encode()
# 封装头信息
headers = {'User-Agent':'Mozilla/5.0
(Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko)
Chrome/102.0.5005.63 Safari/537.36'}
# 封装Request对象
req =
Request(url,data=tru_data,headers=headers)
# 发送请求
resp = urlopen(req)
# 打印结果
print(resp.read().decode())
动态页面获取数据
有时在访问了请求后,并不能获取想要的数据。很大的原因之一就是,当前的页面是动态的。目前
网络的页面分为2大类:
- 静态页面
特征:访问有UI页面URL,可以直接获取数据
- 动态页面(AJAX)
特征:访问有UI页面URL,不能获取数据。需要抓取新的请求获取数据
有些网页内容使用AJAX加载,而AJAX一般返回的是JSON,直接对AJAX地址进行post或get,就返
回JSON数据了
代码
from urllib.request import Request,urlopen
url ='https://www.hupu.com/home/v1/news?
pageNo=2&pageSize=50'
headers = {'User-Agent':'Mozilla/5.0(Windows NT 10.0; Win64; x64)
AppleWebKit/537.36 (KHTML, like Gecko)Chrome/90.0.4430.212 Safari/537.36'}
req = Request(url,headers = headers)
resp = urlopen(req)
print(resp.read().decode())
'''
静态
访问地址栏里的数据就可以获取到想要的数据。
动态
访问地址栏里的数据就可以获取不到想要的数据。
解决方案:抓包
打开浏览器的开发者工具-network-xhr,找到可
以获取到数据的url访问即可
'''
请求 SSL证书验证
现在随处可见 https 开头的网站,urllib可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,
如果网站的SSL证书是经过CA认证的,则能够正常访问,如:https://www.baidu.com/
如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问12306网战
如:https://www.12306.cn/mormhweb/ 的时候,会警告用户证书不受信任。(据说 12306 网站证
书是自己做的,没有通过CA认证)
import ssl
# 忽略SSL安全认证
context = ssl._create_unverified_context()
# 添加到context参数里
response = urlopen(request, context =
context)
伪装自己的爬虫-请求头
有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所
以为了完全模拟浏览器的工作
安装
pip install fake-useragent
代码
from urllib.request import urlopen
from urllib.request import Request
from fake_useragent import UserAgent
ua = UserAgent()
url = 'http://httpbin.org/get'
headers = {
'User-Agent':ua.chrome
}
req = Request(url,headers=headers)
resp = urlopen(req)
print(resp.read().decode())
注意
fake-useragent 在创建对象时,可能创建不了,多部分原因为服务器访问不到的原因
解决方案拷贝fake-useragent_version.json 的配置文件到用户目录
C:\Users\Feel\AppData\Local\Temp
urllib的底层原理
当你获取一个URL你使用一个opener(一个urllib.OpenerDirector的实例)。在前面,我们都是使用的
默认的opener,也就是urlopen。它是一个特殊的opener,可以理解成opener的一个特殊实例,传
入的参数仅仅是url,data,timeout。
如果我们需要用到Cookie,只用这个opener是不能达到目的的,所以我们需要创建更一般的
opener来实现对Cookie的设置
代码
from urllib.request import
Request,build_opener
from fake_useragent import UserAgent
url = 'http://httpbin.org/get'
headers = {'User-Agent':UserAgent().chrome}
req = Request(url,headers= headers)
opener = build_opener()
resp = opener.open(req)
print(resp.read().decode())
from urllib.request import
Request,build_opener
from fake_useragent import UserAgent
from urllib.request import HTTPHandler
url = 'http://httpbin.org/get'
headers = {'User-Agent':UserAgent().chrome}
req = Request(url,headers= headers)
handler = HTTPHandler(debuglevel=1)
opener = build_opener(handler)
resp = opener.open(req)
print(resp.read().decode())
伪装自己的爬虫-设置代理
爬虫设置代理就是让别的服务器或电脑代替自己的服务器去获取数据
爬虫代理原理
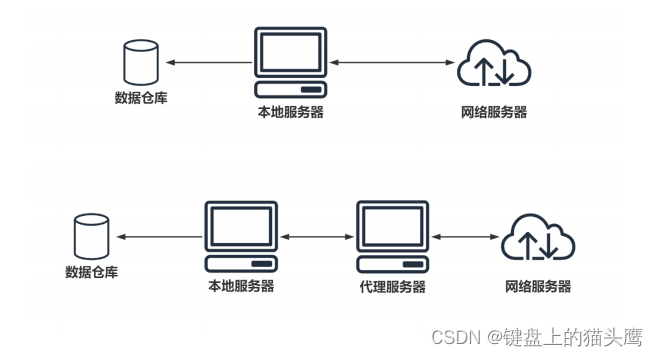
代理分类
- 透明代理:目标网站知道你使用了代理并且知道你的源IP地址,这种代理显然不符合我们这里使用
代理的初衷
- 匿名代理:匿名程度比较低,也就是网站知道你使用了代理,但是并不知道你的源IP地址
- 高匿代理:这是最保险的方式,目标网站既不知道你使用的代理更不知道你的源IP
代理网站
代理网站目前可用,但不一定稳定。
小象代理:https://www.xiaoxiangdaili.com/
快代理:https://www.kuaidaili.com
云代理:http://www.ip3366.net
66ip 代理:http://www.66ip.cn
站大爷:https://www.zdaye.com/
开心代理:http://ip.kxdaili.com/
讯代理:http://www.xdaili.cn/
注意
代理IP无论是免费,还是付费,都不能保证一定可用
- 可能此IP已被其他人使用爬取同样的目标网站而被封禁
- 代理服务器突然发生故障或网络繁忙
代码
from urllib.request import
build_opener,Request,ProxyHandler
from fake_useragent import UserAgent
url = 'http://httpbin.org/get'
header = {'User-Agent':UserAgent().chrome}
req = Request(url,headers=header)
# 构建一个可以使用代理的控制器
# ProxyHandler({'type':'ip:port'})
# handler =
ProxyHandler({'http':'122.9.101.6:8888'})
handler =
ProxyHandler({'http':'http://398707160:j8inh
g2g@162.14.117.8:16816'})
# 构建一个opener对象
opener = build_opener(handler)
# 发送请求
resp = opener.open(req)
# 打印结果
print(resp.read().decode())爬虫cookie的使用
网络部分信息或APP的信息,若是想获取数据时,需要提前做一些操作,往往是需要登录,或者题
前访问过某些页面才可以获取到!!
其实底层就是在网页里面增加了Cookie信息
代码
from urllib.request import
Request,build_opener
from fake_useragent import UserAgent
url
='https://www.kuaidaili.com/usercenter/overview'
headers = {
'User-Agent':UserAgent().chrome,
'Cookie':'channelid=0;
sid=1621786217815170;
_ga=GA1.2.301996636.1621786363;
_gid=GA1.2.699625050.1621786363;
Hm_lvt_7ed65b1cc4b810e9fd37959c9bb51b31=1621
786363,1621823311; _gat=1;
Hm_lpvt_7ed65b1cc4b810e9fd37959c9bb51b31=162
1823382;
sessionid=48cc80a5da3a451c2fa3ce682d29fde7'
}
req = Request(url,headers= headers)
opener = build_opener()
resp = opener.open(req)
print(resp.read().decode())代码登录-并保持登录状态
问题
不想手动复制cookie,太繁琐了!
解决方案
在再代码中执行登录操作,并保持Cookie不丢失
为了保持Cookie不丢失可以 urllib.request.HTTPCookieProcessor 来扩展opener的功能
代码
from urllib.request import
Request,build_opener
from fake_useragent import UserAgent
from urllib.parse import urlencode
from urllib.request import
HTTPCookieProcessor
login_url
='https://www.kuaidaili.com/login/'
args = {
'username':'398707160@qq.com',
'passwd':'123456abc'
}
headers = {
'User-Agent':UserAgent().chrome
}
req = Request(login_url,headers=
headers,data = urlencode(args).encode())
# 创建一个可以保存cookie的控制器对象
handler = HTTPCookieProcessor()
# 构造发送请求的对象
opener = build_opener(handler)
# 登录
resp = opener.open(req)
'''
-------------------------上面已经登录好--------
--------------------------
'''
index_url
='https://www.kuaidaili.com/usercenter/overv
iew'
index_req = Request(index_url,headers
=headers)
index_resp = opener.open(index_req)
print(index_resp.read().decode())爬虫保存与读取Cookie
原理

CookieJar
我们可以利用本模块的 http.cookiejar.CookieJar 类的对象来捕获cookie并在后续连接请求时重新发
送,比如可以实现模拟登录功能。该模块主要的对象有CookieJar、FileCookieJar,
MozillaCookieJar、LWPCookieJar
from urllib.request import
Request,build_opener,HTTPCookieProcessor
from fake_useragent import UserAgent
from urllib.parse import urlencode
from http.cookiejar import MozillaCookieJar
def get_cookie():
url = 'https://www.kuaidaili.com/login/'
args = {
'username':'398707160@qq.com',
'passwd':'123456abc'
}
headers = {'UserAgent':UserAgent().chrome}
req = Request(url,headers = headers,
data = urlencode(args).encode())
cookie_jar = MozillaCookieJar()
handler =
HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
resp = opener.open(req)
# print(resp.read().decode())
cookie_jar.save('cookie.txt',ignore_discard
=True,ignore_expires=True)
def use_cookie():
url =
'https://www.kuaidaili.com/usercenter/'
headers = {'UserAgent':UserAgent().chrome}
req = Request(url,headers = headers)
cookie_jar = MozillaCookieJar()
cookie_jar.load('cookie.txt',ignore_discard
=True,ignore_expires=True)
handler =
HTTPCookieProcessor(cookie_jar)
opener = build_opener(handler)
resp = opener.open(req)
print(resp.read().decode())
if __name__ == '__main__':
# get_cookie()
use_cookie()
urllib的异常处理
错误类型
- 服务器错误
- 资源错误
- 请求超时
#
代码
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
from urllib.error import URLError
url =
'http://www.sxtwerwf1jojhofsaf.cn/sadfa/sdfs
14'
headers = {'User-Agent':UserAgent().chrome}
req = Request(url,headers = headers)
try:
resp = urlopen(req)
print(resp.read().decode())
except URLError as e:
# print(e)
if e.args:
print(e.args[0].errno)
else:
print(e.code)
print('爬取完成')
requests模块-请求方式
这一节来简单介绍一下 requests 库的基本用法
安装
利用 pip 安装
pip install requests
基本请求
req = requests.get("http://www.baidu.com")
req = requests.post("http://www.baidu.com")
req = requests.put("http://www.baidu.com")
req = requests.delete("http://www.baidu.com")
req = requests.head("http://www.baidu.com")
req =requests.options("http://www.baidu.com")
get请求
参数是字典,我们也可以传递json类型的参数:
import requests
from fake_useragent import UserAgent
def test_get():
url = 'http://www.baidu.com/s'
headers = {'UserAgent':UserAgent().chrome}
# 构建传递的参数
params1 = {'wd':'python爬虫'}
# 发送请求
resp = requests.get(url,headers=
headers,params=params1)
# 打印结果
print(resp.text[:1500])
post请求
参数是字典,我们也可以传递json类型的参数:
import requests
from fake_useragent import UserAgent
def test_post():
url ='https://www.kuaidaili.com/login/'
headers = {'UserAgent':UserAgent().chrome}
# 构建传递的参数
data = {
'login_type': '1',
'username': '398707160@qq.com',
'passwd': '123456abc',
'next': '/'
}
# 发送请求
resp =
requests.post(url,headers=headers,data=data)
# 打印结果
print(resp.text[:1500])
requests伪装爬虫-详细使用
自定义请求头部
伪装请求头部是采集时经常用的,我们可以用这个方法来隐藏
爬虫身份
headers = {'User-Agent': 'python'}
r = requests.get('http://www.zhidaow.com',
headers = headers)
print(r.request.headers['User-Agent'])
代理访问
采集时为避免被封IP,经常会使用代理。requests也有相应的
proxies属性
import requests
proxies = {
"http": "http://10.10.1.10:3128",
"https": "https://10.10.1.10:1080",
}
requests.get("http://www.zhidaow.com",
proxies=proxies)
requests其他功能
设置超时时间
可以通过timeout属性设置超时时间,一旦超过这个时间还没获
得响应内容,就会提示错误
requests.get('http://github.com',
timeout=0.001)
session自动保存cookies
seesion的意思是保持一个会话,比如 登陆后继续操作(记录身
份信息) 而requests是单次请求的请求,身份信息不会被记录
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('http://httpbin.org/cookies/set/session
cookie/123456789')
ssl验证
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings()
resp = requests.get(url, verify=False,
headers=headers)
获取响应信息
| 代码 | 含义 |
|---|---|
| resp.json() | 获取响应内容(以json字符串) |
| resp.text | 获取响应内容 (以字符串) |
| resp.content | 获取响应内容(以字节的方式) |
| resp.headers | 获取响应头内容 |
| resp.url | 获取访问地址 |
| resp.encoding | 获取网页编码 |
| resp.request.headers | 请求头内容 |
| resp.cookie | 获取cookie |








![[StartingPoint][Tier1]Crocodile](https://img-blog.csdnimg.cn/img_convert/6a6e016ae303f164f5fb76e63ec0f07b.jpeg)