问题场景
Mysql数据处理类型分以下三种
com.mysql.cj.protocol.a.result.ResultsetRowsStatic:普通查询,将结果集一次性全部拉取到内存
com.mysql.cj.protocol.a.result.ResultsetRowsCursor:游标查询,将结果集分批拉取到内存,按照fetchSize大小拉取,会占用当前连接直到连接关闭。在mysql那边会建立一个临时表写入磁盘(查询结束后由mysql回收处理),会导致mysql server磁盘io飙升。
com.mysql.cj.protocol.a.result.ResultsetRowsStreaming:流式查询,将结果集一条一条的拉取进内存,比较依赖网络,可能会造成网络阻塞。占用当前mysql连接。
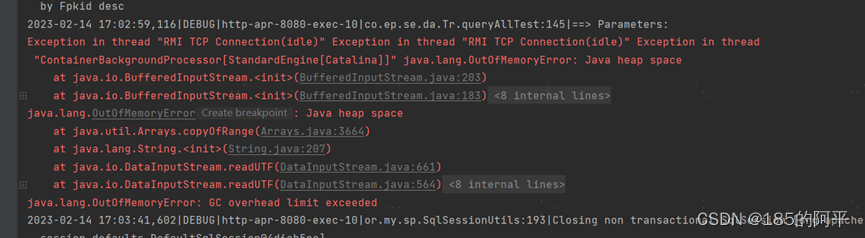
所以在普通查询大数据量时如果JVM内存不够用会出现OOM异常。如下测试方案
数据量20w,一条数据大概2K。
虚拟机参数 -Xmx256m -Xms256m
(1)普通查询,大概接近200多M就GC释放
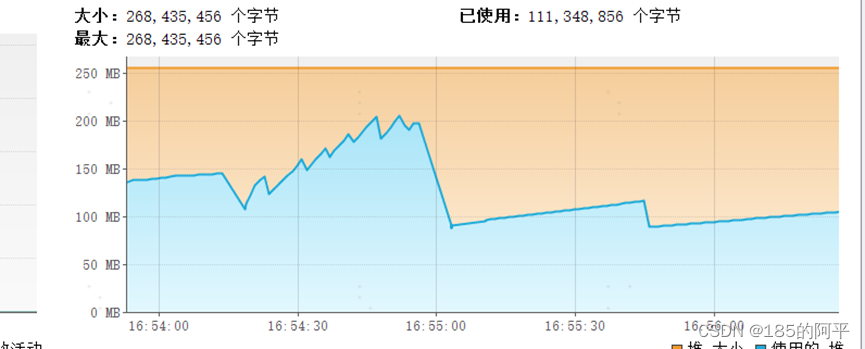
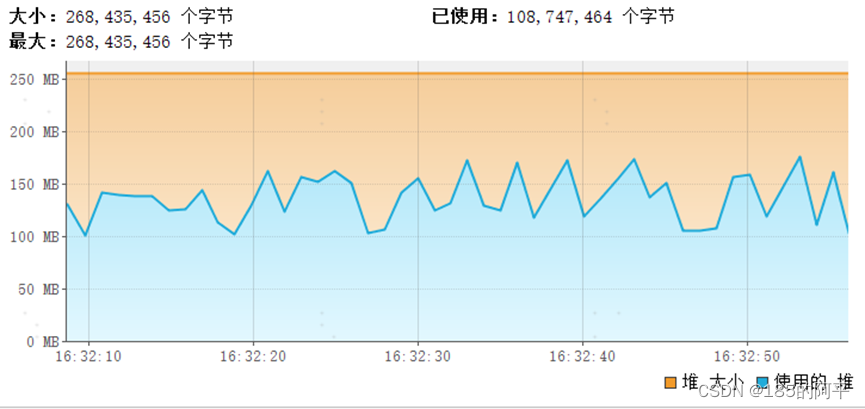
(2)流式查询,不会出现内存溢出
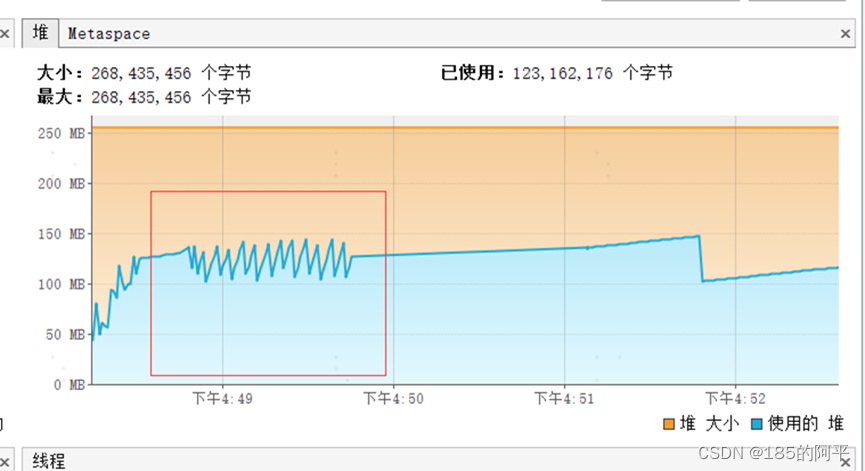
(3)游标查询,不会出现内存溢出
执行原理—分析
JDBC 与 MySQL 服务端的交互是通过 Socket 完成的,完整请求链路
JDBC 客户端 -> 客户端 Socket -> MySQL -> 检索数据返回 -> MySQL 内核 Socket 缓冲区 -> 网络 -> 客户端 Socket Buffer -> JDBC 客户端
普通查询的方式在查询大数据量时,所在 JVM 可能会凉凉,原因如下:
MySQL Server 会将检索出的 SQL 结果集通过输出流写入到内核对应的 Socket Buffer
内核缓冲区通过 JDBC 发起的 TCP 链路进行回传数据,此时数据会先进入 JDBC 客户端所在内核缓冲区
JDBC 发起 SQL 操作后,程序会被阻塞在输入流的 read 操作上,当缓冲区有数据时,程序会被唤醒进而将缓冲区数据读取到 JVM 内存中
MySQL Server 会不断发送数据,JDBC 不断读取缓冲区数据到 Java 内存中,虽然此时数据已到 JDBC 所在程序本地,但是 JDBC 还没有对 execute 方法调用处进行响应,因为需要等到对应数据读取完毕才会返回
弊端就显而易见了,如果查询数据量过大,会不断经历 GC,然后就是内存溢出
普通查询等待时间与游标查询等待时间原理上是不一致的,前者是一致在读取网络缓冲区的数据,没有响应到业务层面;后者是 MySQL 在准备临时数据空间,没有响应到 JDBC
游标查询消费完 fetchSize 行数据,就需要发起请求到服务端请求
流式查询
当客户端与 MySQL Server 端建立起连接并且交互查询时,MySQL Server 会通过输出流将 SQL 结果集返回输出,也就是 向本地的内核对应的 Socket Buffer 中写入数据,然后将内核中的数据通过 TCP 链路回传数据到 JDBC 对应的服务器内核缓冲区
JDBC 通过输入流 read 方法去读取内核缓冲区数据,因为开启了流式读取,每次业务程序接收到的数据只有一条
MySQL 服务端会向 JDBC 代表的客户端内核源源不断的输送数据,直到客户端请求 Socket 缓冲区满,这时的 MySQL 服务端会阻塞
对于 JDBC 客户端而言,数据每次读取都是从本机器的内核缓冲区,所以性能会更快一些,一般情况不必担心本机内核无数据消费(除非 MySQL 服务端传递来的数据,在客户端不做任何业务逻辑,拿到数据直接放弃,会发生客户端消费比服务端超前的情况)
代码实现—使用
依赖
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.4.1</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>1.3.0</version>
</dependency>
流式查询
Mapper接口—返回值为void,依靠ResultHandler进行结果处理
void queryAllTest(ResultHandler<TradeOrderDO> resultHandler);xml定义-----fetchSize为Integer.MIN_VALUE ,这个属性是JDBC每次去数据页获取的条数,设置最大就是由JDBC智能发挥。
<select id="queryAllTest" resultMap="TradeOrderOutput" resultSetType="FORWARD_ONLY" fetchSize="-2147483648">
select * from eppc_db.t_trade_order
</select>
以上也可以用注解实现,如下
// @ResultType(TradeOrderDO.class)
// @Select("select * from eppc_db.t_trade_order order by Fpkid desc")
//@Options(resultSetType = ResultSetType.FORWARD_ONLY,fetchSize = Integer.MIN_VALUE)
void queryAllTest(ResultHandler<TradeOrderDO> resultHandler);
Service层
@Override
public List<TradeOrderDO> queryList() {
List<TradeOrderDO> tradeOrderDOList = new ArrayList<>();
List<String> cardIds = new ArrayList<>();
AtomicInteger i = new AtomicInteger(0);
tradeinfoDAO.queryAllTest(resultHandler ->{
TradeOrderDO resultObject = resultHandler.getResultObject();
if (i.get() % 100000 == 0){//此处做业务处理
System.out.println(resultObject.getPkid());
// tradeOrderDOList.add(resultHandler.getResultObject());
}
i.getAndIncrement();
});
return tradeOrderDOList;
}
游标查询 2种方式
方式1
Mapper接口-----这种是在mapper层直接定义返回游标封装信息
//@Options(resultSetType = ResultSetType.FORWARD_ONLY,fetchSize = Integer.MIN_VALUE)
//@Select("select * from eppc_db.t_trade_order")
// @ResultType(TradeOrderDO.class)
Cursor<TradeOrderDO> getAllRecord();
方式2—需要在service层使用sqlSession调用
//@Options(resultSetType = ResultSetType.FORWARD_ONLY,fetchSize = Integer.MIN_VALUE)
//@Select("select * from eppc_db.t_trade_order")
// @ResultType(TradeOrderDO.class)
List<TradeOrderDO> getAllRecords();
Service层—需注意加上事务注解表示该service并不是在mapper结束时结束事务,而是等整个service结束才结束事务,不然会出现只能读取到第一段游标的结果集。
@Resource(name = "eppcSqlSessionFactory")
SqlSessionFactory sqlSessionFactory;
@Override
@Transactional(readOnly = true)
public List<TradeOrderDO> getAllRecord() {
List<TradeOrderDO> tradeOrderDOList = new ArrayList<>();
Cursor<TradeOrderDO> cursor = null;
SqlSession sqlSession = null;
try {
cursor = tradeinfoDAO.getAllRecord();//方式1调用
sqlSession = sqlSessionFactory.openSession();
cursor = sqlSession.selectCursor(TradeinfoDAO.class.getName() + ".getAllRecords");//方式2调用
int currentIndex = 0;
Iterator<TradeOrderDO> iterator = cursor.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next()+""+currentIndex);
/*if (currentIndex % 100000 == 0){
//一次业务处理
System.out.println("先写入一部分数据"+iterator.next()+currentIndex);
}*/
currentIndex ++;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (null != cursor) {
try {
cursor.close();
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
if (null != sqlSession) {
try {
sqlSession.close();
} catch (Exception e) {
log.error(e.getMessage(), e);
}
return tradeOrderDOList;
}
}
使用总结
当遇到大数据量查询时确实可以使用mybatis的游标或者游式查询,Mysql底层也支持。但这只是减缓了数据库服务器的读与传输的压力。到业务层面还是需要根据具体业务场景去分批处理,比如一条查300w数据,游式查询能支持,但也不能一起性放入java的list中,内存不够还是会溢出。这时可能就需要写一些条件一次处理多少数据,所以本质来说就是数据不一次性存储,但总有地方要把这些数据存着。不给JVM内存,那就会牺牲网络或者服务器的其它属性。