1. 数据库的约束
1.1 约束类型(一般发生于表的创建中)
- NOT NULL - 指示某列不能存储 NULL 值。
- UNIQUE - 保证某列的每行必须有唯一的值。
- DEFAULT - 规定没有给列赋值时的默认值。
- PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
- FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
- CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。(8之后的版本支持)
1.2 null约束
创建表的时候,可以指定某列不为空.
create table student (id int not null , sn int ,name varchar(5),qq_mail varchar(20));
创建一个学生表,规定id一列不可以为空.

1.3 unique约束
create table student (id int not null , sn int unique ,name varchar(5),qq_mail varchar(20));
创建一个学生表,规定sn一列为唯一的,不重复的.
1.4 default约束
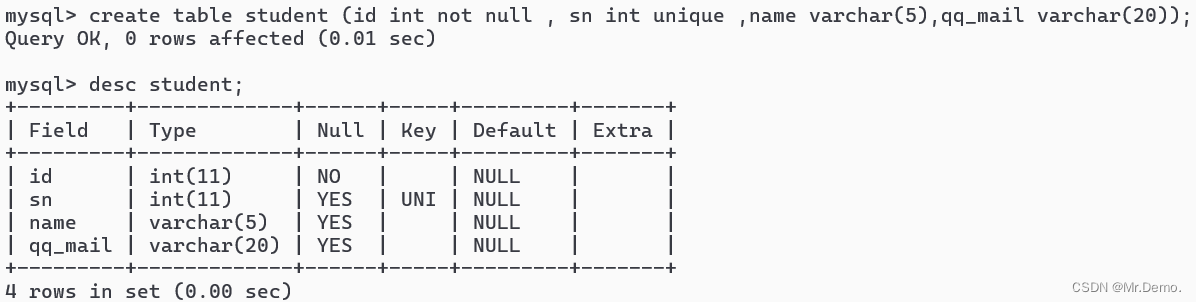
create table student (id int not null , sn int unique ,name varchar(10) default 'unknown' ,qq_mail varchar(20));
创建一个表,name一列默认为unknown;
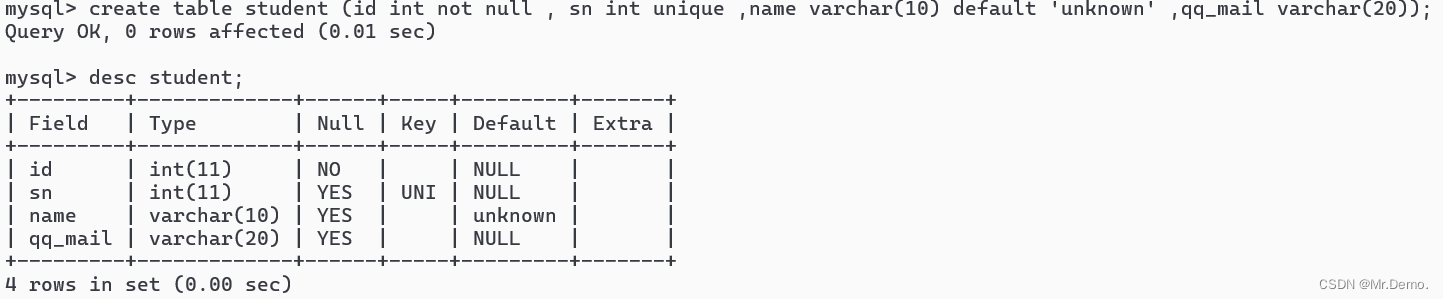
[注意]: 在默认值的上面要加上’ '表示字符串
1.5 primary key约束–>主键约束
create table student (id int primary key , sn int unique ,name varchar(10) default 'unknown' ,qq_mail varchar(20) );
指定id为主键

对于整数类型的主键,通常搭配自增长auto_increment来使用,插入对应数据对应字段不给值时(如给null),使用最大值+1.
create table student (id int primary key auto_increment , sn int unique ,name varchar(10) default 'unknown' ,qq_m ail varchar(20));

[注意] 每个表的主键只可以有一个.
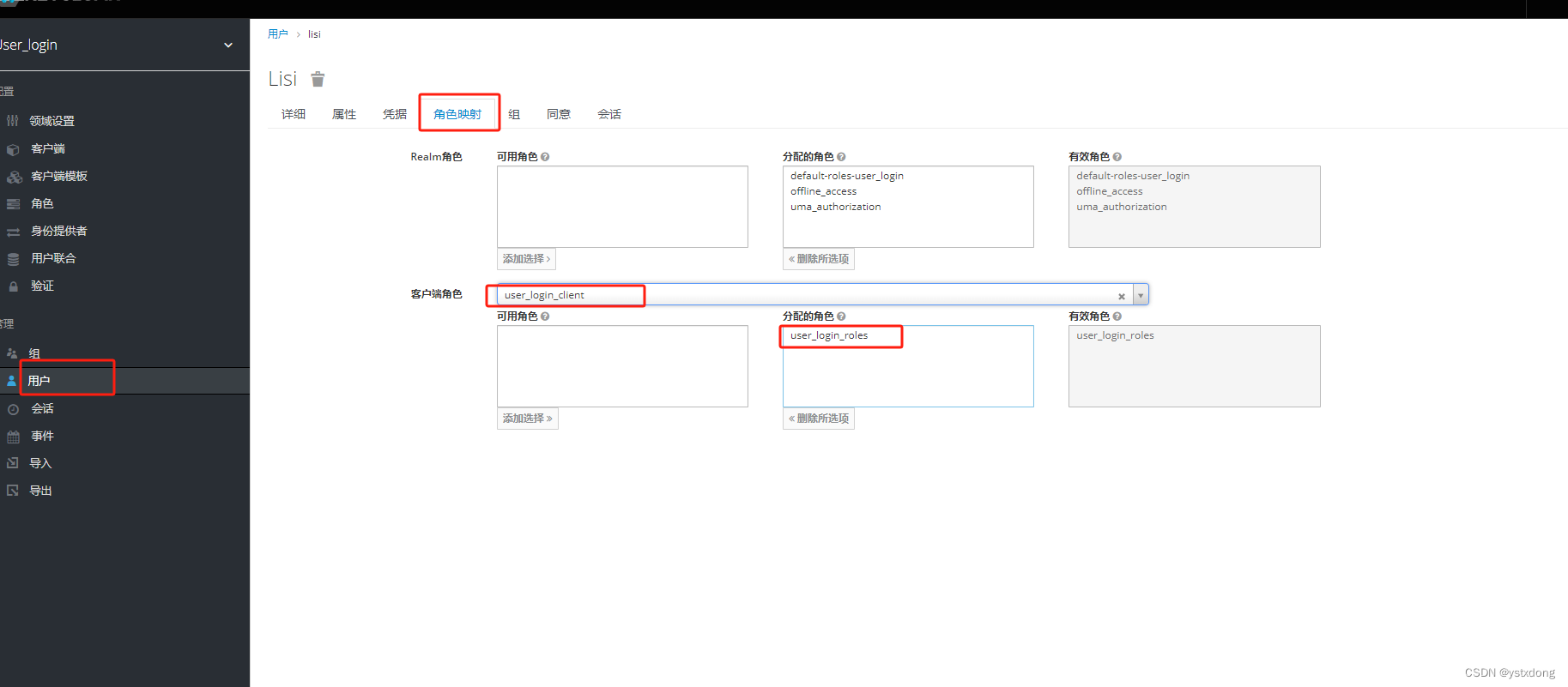
1.6 foreign key–>外键约束
外键用于关联其他表的主键或者是唯一键.(关联的必须是使用primary key修饰的列或者unique修饰的列)
语法:
foreign key (字段名) reference 主表(列)
案例:
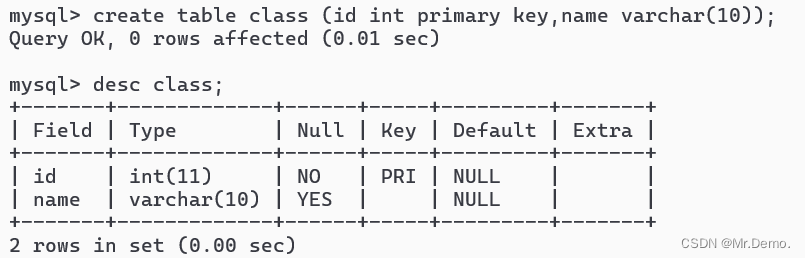
- 创建班级表,id为主键.
create table class (id int primary key,name varchar(10));
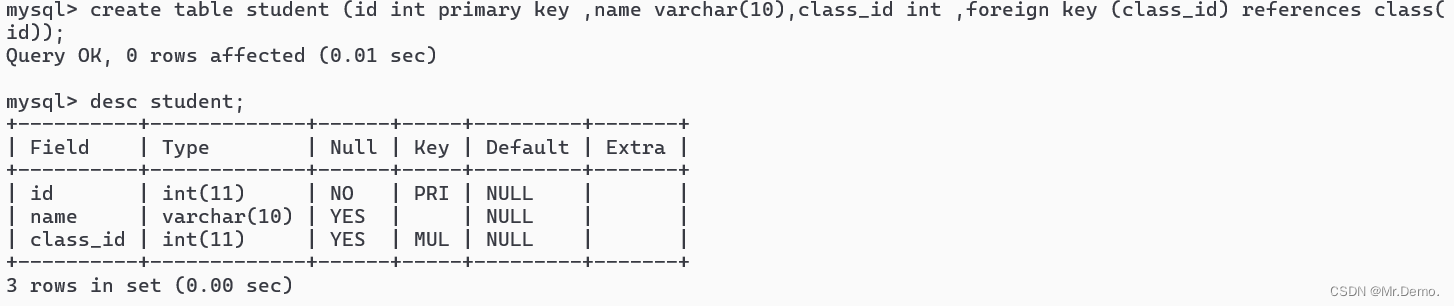
创建班级表student , 一个学生对应一个班级,一个班级对应多个学生,使用id为主键,class_id为外键,关联班级表id.
create table student (id int primary key ,name varchar(10),class_id int ,foreign key (class_id) references class( id));
[注意]
- 加外键的表称为子表,使用外键关联的表称为父表.
- 在创建外键的时候,和主键的创建方式不一样,它的创建在所有列的最后,且要指定子表中的列和父表和父表中的列.
- foreign拼写要正确,references注意不要少加s.
- 关联之后,父表会对子表产生约束作用,下面进行举例.
insert into class values(1, 'java 1');
insert into student values(1, '张三' ,2);

在这里,我们可以看到,我们指定student的班级id为2,但是班级id为2的班级在父表中不存在,所以插入不成功.
- 关联之后,子表也会对父表产生一定的制约,下面进行举例.
insert into student values(1,'张三',1);
insert into class values(2,'java 2');
delete from class where id=1;
delete from class where id=2;

在上图中我们看到在删除class表中id为1的行时候,删除失败,而删除id为2的时候删除成功,是因为子表student存在class_id为1的学生,所以不可以删除.
2. 表的设计
三大范式:
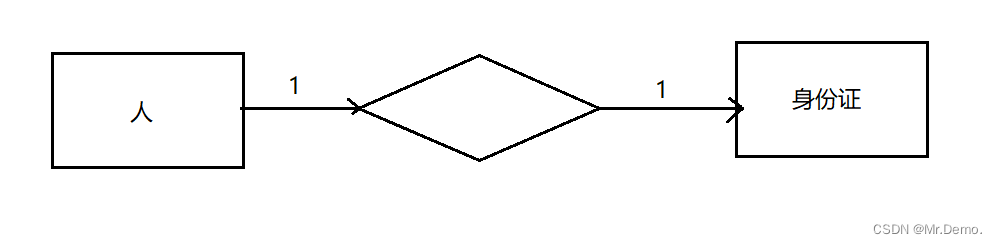
- 一对一
- 一对多
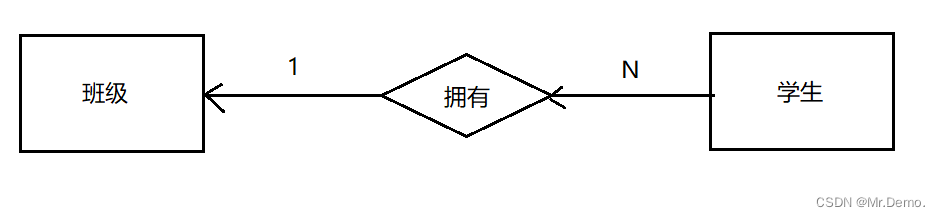
就像我们在上面展示外键案例的时候,学生和班级之间的关系就是一对多,一个学生只可以属于一个班级,但是一个班级中可以有多个学生. - 多对多
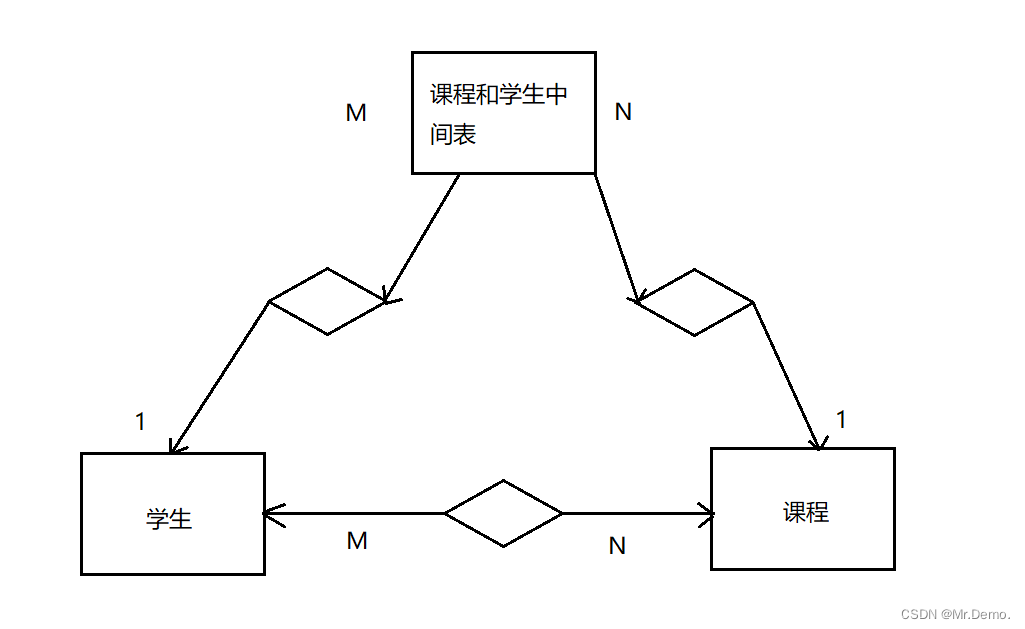
create table course (id int primary key,name varchar(10));
create table student_course (student_id int , course_id int ,foreign key (student_id) references student(id),foreign key (course_id) references course(id));
我们在课程表和学生表之间创建一个中间表,叫student_course表,把学生和课程关联起来,这个表插入的元素取决于一个课程都被哪些同学选择,或者是一个学生都选择哪些课程.
3. 新增–>insert
插入查询结果,也就是把另一个表中所查询到的数据复制过来.
语法:
insert into 表名 (列名) select …
案例:把student的id和name数据复制到新建的student2中
create table student2 (id int primary key , name varchar(10),class_id int);
insert into student2 (id,name) select id,name from student;
select * from student2;
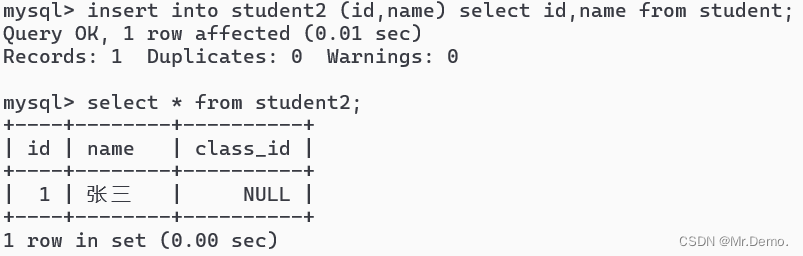
这里我们看到,student中的两列数据被成功地插入了student2这张表中.这里需要注意的一点是,前面insert插入操作的时候,列名要加括号,在后面select操作的时候,列名不需要加括号,还有插入表中的数据要和查询出来的数据类型相吻合.
4. 查询–>select
4.1 聚合查询
4.1.1 聚合函数
常见的统计总数,计算平均值等都可以用聚合函数来实现.常见的聚合函数如下:
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
案例:
- count
select count(*) from emp;

这里我们看到总共有八个人,count(*)返回的值就是8
当然也可以对查询加上限制条件:
select count(*) from emp where role='测试工程师';
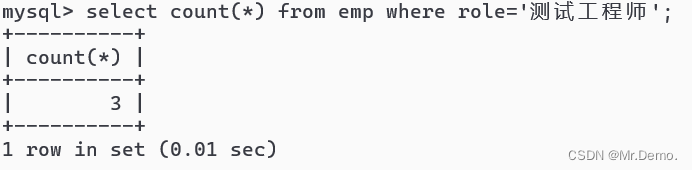
我们看到,测试工程师一共有三人. - sum
select sum(salary) from emp;
统计所有人的薪资总和.
也可以令别名
select sum(salary) as total from emp;
我们看到,表头被改为了total.
也可以加入限制条件.
select sum(salary) as total from emp where role='java工程师';
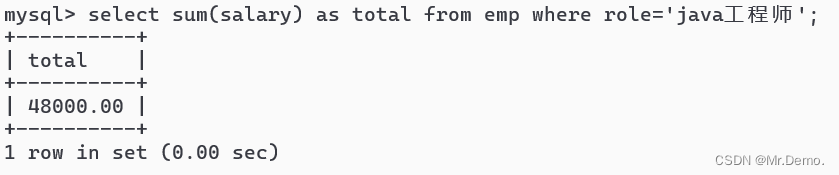
上述返回的就是所有java工程师的工资总和.
[注意]
sum中所包含的列一定是可加和的对象,如果说包含不可加和对象,则不会计入总和中.原理就是:在MySQL拿到一个不可直接运算的类型的时候,如字符串类型,sql会先尝试转化为double类型数据,若转换失败,则该数据不参与运算,并报出警告.
-
avg
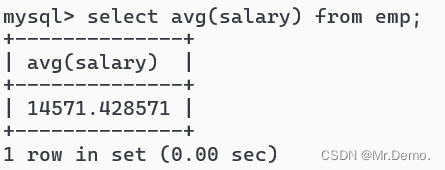
select avg(salary) from emp;
统计所有人工资的平均值.
-
max
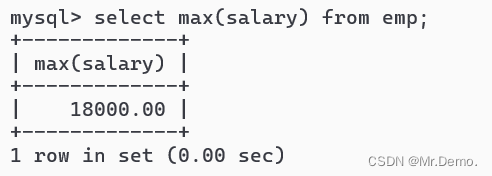
select max(salary) from emp;
返回工资最高的人.
-
min
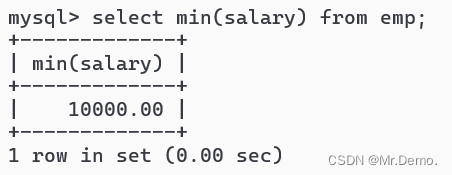
select min(salary) from emp;
返回工资最少的人
4.1.2 group by子句
select中使用group by子句可以对指定的列进行分组查询
语法:
select 列名,聚合函数(列名)… from table group by 列名
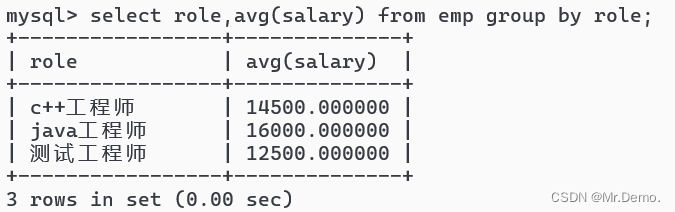
select role,avg(salary) from emp group by role;
计算各个岗位的平均工资.
这么看比较一整句话有些抽象,我们把这句话拆开来看,我们来分析它的执行逻辑:
- 先执行select role,salary from emp;查找出表中所有的结果.
- 再执行group by role,对查找出的结果进行分组.
- 再执行聚合函数,把avg(salary)带入每个分组进行计算.
可以再对薪资进行排序:
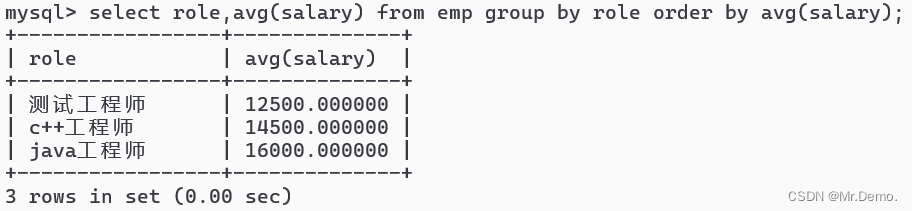
select role,avg(salary) from emp group by role order by avg(salary);
[注意]
select指定的字段必须为"分组的依据字段",其他字段要想出现在select语句中,必须使用聚合函数.否则返回的数据就是无意义的数据.
select name,role,avg(salary) from emp group by role;

这里我们看到,name一列返回的数据是没有任何规律的,是分组中随机的值.
4.1.3 having
group by 子句对结果进行分组之后,需要对分组之后的结果进行过滤,此时不可以使用where语句,要使用having语句.
select role,avg(salary) as avg from emp group by role having avg>=13000;
显示平均工资大于13000的岗位.

此时我们看到,大于13000的岗位有java和c++.
[辨析]使用having限制和使用where限制
在使用having限制的时候,是对分组之后的结果进行过滤,比如上面的例子,而使用where是对分组之前的结果进行遍历.下面来举一个where的例子.
select role,avg(salary) as avg from emp where name!= '张三' group by role;
计算各个岗位的平均工资,但是不包含张三.