有效感受野可视化
- 过程记录
- 创建环境
- 准备数据、脚本
- 脚本测试
- 其他参考
- 尝试运行
过程记录
创建环境
conda create -n ERF python=3.8 -y
conda activate ERF
pip3 install empy rospkg pyyaml catkin_pkg
conda install pytorch==2.1.0 torchvision==0.16.0 torchaudio==2.1.0 pytorch-cuda=11.8 -c pytorch -c nvidia
pip3 install numpy opencv-contrib-python
准备数据、脚本
创建ERF_VIS目录,管理项目,根目录下创建test_imgs目录管理测试图片。
根目录下创建脚本ERF_visualizetion.py(参考代码):
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
from torchvision.models.segmentation import deeplabv3_resnet50
import torch
from torchvision import transforms
import numpy as np
import torchvision
from PIL import Image
import cv2
import os
#这里随机拿100张测试集图像,放到一个文件夹中,img_dir是文件夹路径
img_dir = "./test_imgs"
images=os.listdir(img_dir)
model = deeplabv3_resnet50(pretrained=True, progress=False)
model = model.eval()
#定义输入图像的长宽,这里需要保证每张图像都要相同
input_H, input_W = 512, 512
#生成一个和输入图像大小相同的0矩阵,用于更新梯度
heatmap = np.zeros([input_H, input_W])
#打印一下模型,选择其中的一个层
print(model)
#这里选择骨干网络的最后一个模块
layer = model.backbone.layer4[-1]
print(layer)
def farward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
#为了简单,这里直接一张一张图来算,遍历文件夹中所有图像
for img in images:
read_img = os.path.join(img_dir,img)
image = Image.open(read_img)
#图像预处理,将图像缩放到固定分辨率,并进行标准化
image = image.resize((input_H, input_W))
image = np.float32(image) / 255
input_tensor = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485,0.456,0.406), (0.229,0.224,0.225))])(image)
#添加batch维度
input_tensor = input_tensor.unsqueeze(0)
if torch.cuda.is_available():
model = model.cuda()
input_tensor = input_tensor.cuda()
#输入张量需要计算梯度
input_tensor.requires_grad = True
fmap_block = list()
input_block = list()
#对指定层获取特征图
layer.register_forward_hook(farward_hook)
#进行一次正向传播
output = model(input_tensor)
#特征图的channel维度算均值且去掉batch维度,得到二维张量
feature_map = fmap_block[0].mean(dim=1,keepdim=False).squeeze()
#对二维张量中心点(标量)进行backward
feature_map[(feature_map.shape[0]//2-1)][(feature_map.shape[1]//2-1)].backward(retain_graph=True)
#对输入层的梯度求绝对值
grad = torch.abs(input_tensor.grad)
#梯度的channel维度算均值且去掉batch维度,得到二维张量,张量大小为输入图像大小
grad = grad.mean(dim=1,keepdim=False).squeeze()
#累加所有图像的梯度,由于后面要进行归一化,这里可以不算均值
heatmap = heatmap + grad.cpu().numpy()
cam = heatmap
#对累加的梯度进行归一化
cam = cam / cam.max()
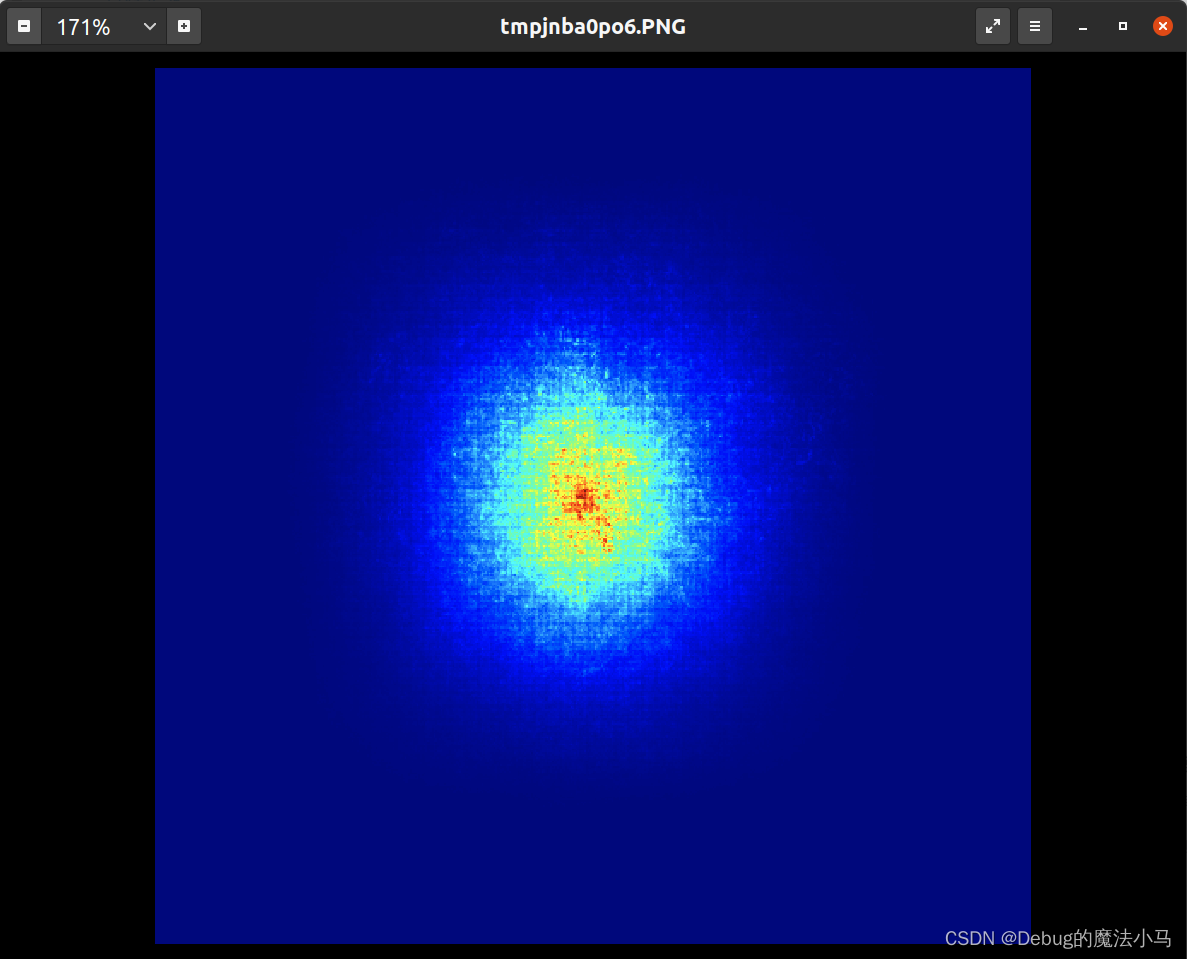
#可视化,蓝色值小,红色值大
cam = cv2.applyColorMap(np.uint8(cam*255), cv2.COLORMAP_JET)
cam = cv2.cvtColor(cam, cv2.COLOR_BGR2RGB)
map_image = Image.fromarray(cam)
map_image.show()
根目录下创建脚本Img_copy.py(从之前下载的ADE20K数据集的验证集中拷贝图片):
import os
import shutil
# 源文件夹路径
source_folder = '/media/lcy-magic/Dataset/Segment_Dataset/ade/ADEChallengeData2016/images/validation'
# 目标文件夹路径
destination_folder = '/home/lcy-magic/Segment_TEST/ERF_VIS/test_imgs'
# 获取源文件夹中所有的.png图片文件
png_files = [f for f in os.listdir(source_folder) if f.endswith('.jpg')]
# 确保目标文件夹存在
if not os.path.exists(destination_folder):
os.makedirs(destination_folder)
# 复制前100张图片到目标文件夹
for i, png_file in enumerate(png_files):
if i < 100:
source_file = os.path.join(source_folder, png_file)
destination_file = os.path.join(destination_folder, png_file)
shutil.copyfile(source_file, destination_file)
print(f'Copied {png_file} to {destination_folder}')
print('Copying completed.')
脚本测试
运行:
python ERF_visualizetion.py
运行结果为:
其他参考
尝试运行
发现一个这个项目做了可视化感受野参考博客,看看他是怎么怎么做的。
我先从github上下载了他的ERF代码:
先尝试运行visualize_erf.py。
看样子需要这几个参数:
- –model:先不传,用他默认的resnet101
- –weights:看后面代码:
model = resnet101(pretrained=args.weights is None),对于resnet101并不需要提供权重 - –data_path:看后面代码:
root = os.path.join(args.data_path, 'val'),会对其中val文件夹内所有图片进行操作;我自己做个val文件夹,内含10张图片 - –save_path:用npy文件保存ERF矩阵,指定地点;我先保存到根目录下新建result目录
- –num_images:处理多少张图片,默认是50,我改成10
运行:
python other/visualize_erf.py --data_path test_imgs --save_path result/ --num_images 10
报错:
ModuleNotFoundError: No module named 'timm'
安装就好:
pip3 install timm
报错:
ModuleNotFoundError: No module named 'erf'
把脚本的目录改名为erf,再添加环境变量,就能本地import了:
export PYTHONPATH=$PYTHONPATH:~/Segment_TEST/ERF_VIS

报错:
Traceback (most recent call last):
File "erf/visualize_erf.py", line 15, in <module>
from erf.resnet_for_erf import resnet101, resnet152
File "/home/lcy-magic/Segment_TEST/ERF_VIS/erf/resnet_for_erf.py", line 7, in <module>
from torchvision.models.resnet import ResNet, Bottleneck, BasicBlock, load_state_dict_from_url, model_urls
ImportError: cannot import name 'load_state_dict_from_url' from 'torchvision.models.resnet' (/home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages/torchvision/models/resnet.py)
参考参考博客改为:
from torchvision.models.resnet import ResNet, Bottleneck, BasicBlock, model_urls
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
解决。但报错:
ImportError: cannot import name 'model_urls' from 'torchvision.models.resnet' (/home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages/torchvision/models/resnet.py)
无法这样解决。应该是torchvision版本问题。查看我的版本是0.16.0:
pip show torchvision
Name: torchvision
Version: 0.16.0
Summary: image and video datasets and models for torch deep learning
Home-page: https://github.com/pytorch/vision
Author: PyTorch Core Team
Author-email: soumith@pytorch.org
License: BSD
Location: /home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages
Requires: numpy, pillow, requests, torch
Required-by: timm
我不想牵就作者的版本。于是查看pytorch关于torchvision的官方文档:官方文档 。然后搜索load_state_dict_from_url关键词,点击链接进入相关文档:

看起来和上一篇参考博客说的吻合,也就是从torch.hub下载。可能model_urls在torch.hub里也没有。搜索下这个关键词,结果并没有搜到。查看代码中使用model_urls的部分:
def _resnet(arch, block, layers, pretrained, progress, **kwargs):
model = ResNetForERF(block, layers, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict, strict=False)
return model
发现model_urls只是根据输入参数arch(网络架构),给load_state_dict_from_url提供输入参数。参考load_state_dict_from_url的官方说明:

这个参数就是URL.我看到这篇博客参考博客就没有import,直接给出的。那我也不import。只添加:
model_urls = {
'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth',
'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth',
}
果然成功了。
报错:
ModuleNotFoundError: No module named 'replknet'
发现这个replknet是那个论文自己的模型,我对这个没有兴趣。把所有用到他的地方都注释掉。
报错:
Traceback (most recent call last):
File "erf/visualize_erf.py", line 116, in <module>
main(args)
File "erf/visualize_erf.py", line 54, in main
dataset = datasets.ImageFolder(root, transform=transform)
File "/home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages/torchvision/datasets/folder.py", line 309, in __init__
super().__init__(
File "/home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages/torchvision/datasets/folder.py", line 144, in __init__
classes, class_to_idx = self.find_classes(self.root)
File "/home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages/torchvision/datasets/folder.py", line 218, in find_classes
return find_classes(directory)
File "/home/lcy-magic/anaconda3/envs/ERF/lib/python3.8/site-packages/torchvision/datasets/folder.py", line 42, in find_classes
raise FileNotFoundError(f"Couldn't find any class folder in {directory}.")
FileNotFoundError: Couldn't find any class folder in test_imgs/val.
原来他对数据集还有要求,得按照imagenet的格式来。我尝试改代码,但太麻烦了。又不想再下个数据集。就随便给我的图片归成dog和cat两类,但实际一点关系都没。
运行成功:

但发现result文件夹内没有结果,打印下保存文件的代码信息:
发现就是计数不对。改为:
if meter.count == args.num_images - 1:
np.save(args.save_path, meter.avg)
exit()
改了之后还是不对,发现这样不对,不应该-1。同时指定的保存地点应该是具体的npy文件。于是我给dog里加了一张图片。然后命令改为:
python erf/visualize_erf.py --data_path test_imgs --save_path result/ERF.npy --num_images 10
成功。
接下来可视化,应该是analyze_erf.py脚本,只有两个参数:
- –source:也就是刚生成的result/ERF.npy
- –heatmap_save:热力图地址
执行:
python erf/analyze_erf.py --source result/ERF.npy --heatmap_save result/heatmap.png
先后报错:
ModuleNotFoundError: No module named 'matplotlib'
pykitti 0.3.1 requires pandas, which is not installed.
ModuleNotFoundError: No module named 'seaborn'
安装就好:
pip3 install matplotlib
pip3 install pandas
pip3 install seaborn
报错:
ModuleNotFoundError: No module named 'mpl_toolkits.axes_grid1.colorbar'
搜了下,好像是把matplotlib升级下就行。我尝试了upgrade和用conda install,都不行。发现现在的matplotlib已经没这个东西了。我也没找到现在版本对应的实现是什么。算了退一下版本吧。发现seabon又必须让matplotlib在3.4以上。然后发现,seabon本来就可以绘制colorbar,代码注释里也写了,于是把color bar那个都注释掉,改用seabon:
def heatmap(data, camp='RdYlGn', figsize=(10, 10.75), ax=None, save_path=None):
plt.figure(figsize=figsize, dpi=40)
ax = sns.heatmap(data,
xticklabels=False,
yticklabels=False, cmap=camp,
center=0, annot=False, ax=ax, cbar=True, annot_kws={"size": 24}, fmt='.2f')
# =========================== Add a **nicer** colorbar on top of the figure. Works for matplotlib 3.3. For later versions, use matplotlib.colorbar
# =========================== or you may simply ignore these and set cbar=True in the heatmap function above.
from mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable
# from matplotlib_colorbar import colorbar
# from mpl_toolkits.axes_grid1.colorbar import colorbar
# ax_divider = make_axes_locatable(ax)
# cax = ax_divider.append_axes('top', size='5%', pad='2%')
# colorbar(ax.get_children()[0], cax=cax, orientation='horizontal')
# cax.xaxis.set_ticks_position('top')
# ================================================================
# ================================================================
plt.savefig(save_path)
运行成功:
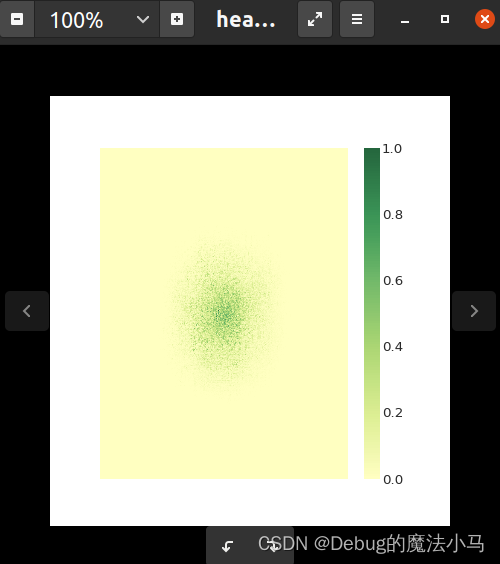
这个代码计算梯度的方法和之前的一致,没啥参考价值。主要是他中间有个保存梯度图为npy文件的过程和用seabon画更好看的图的想法不错,以及通过arg传参。借用下。