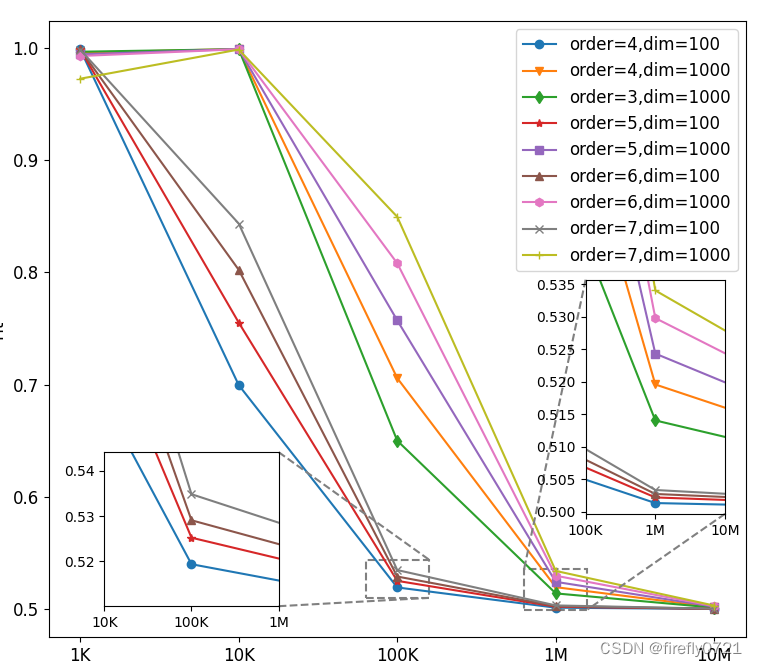
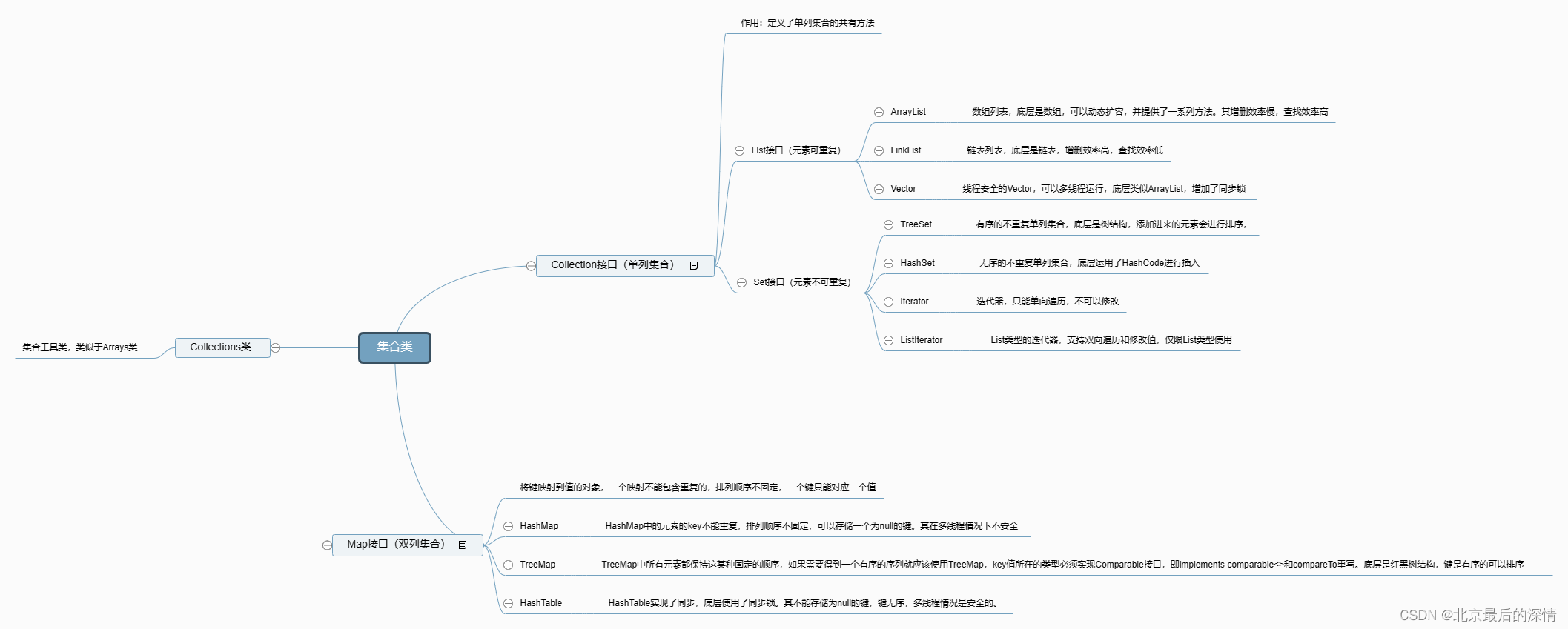
此程序主要特点:
1、使用python画实验结果图
2、想要对大图的局部进行放大
3、有两个子图
4、子图和原图的横坐标都使用标签而不是原始的数据
代码和注释如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import openpyxl as xl
from mpl_toolkits.axes_grid1.inset_locator import mark_inset
excel_file = xl.load_workbook('D:\Hnu\Project5 CP\实验结果\\baseline选择.xlsx')
sheet_name = 'Scalability' #对应的sheet的名称
sheet = excel_file[sheet_name] # 定位excel中具体的表单
data = pd.DataFrame(sheet.values)# 提取表单中的具体数据所在的行和列
selected_data = data.iloc[23:28,1:11]
print(selected_data)
fig, ax = plt.subplots(figsize=(9, 8))#用来控制图片的大小
#设定图片中文字和标签大小的参数
fontsize = 12
# 绘制柱状图,正常坐标,第一个参数是横坐标
# 第二参数,是纵坐标数据,注意11,12,13是列名,是从excel读来的绝对列名,不是selected_data的相对列数
ax.plot(selected_data.iloc[:,0], selected_data[2],marker='o', label='order=4,dim=100')
ax.plot(selected_data.iloc[:,0], selected_data[3],marker='v', label='order=4,dim=1000')
ax.plot(selected_data.iloc[:,0], selected_data[4],marker='d',label='order=3,dim=1000')
ax.plot(selected_data.iloc[:,0], selected_data[5],marker='*',label='order=5,dim=100')
ax.plot(selected_data.iloc[:,0], selected_data[6],marker='s',label='order=5,dim=1000')
ax.plot(selected_data.iloc[:,0], selected_data[7],marker='^',label='order=6,dim=100')
ax.plot(selected_data.iloc[:,0], selected_data[8],marker='h',label='order=6,dim=1000')
ax.plot(selected_data.iloc[:,0], selected_data[9],marker='x',label='order=7,dim=100')
ax.plot(selected_data.iloc[:,0], selected_data[10],marker='+',label='order=7,dim=1000')
#ax.plot(selected_data.iloc[:,1], selected_data[4],color='blue',marker='p',label='GTA')
#ax.plot(selected_data.iloc[:,0], selected_data[5],color='red',marker='*',label='CL_tucker')
#ax.set_yscale('log', basey=10)#设置柱子的纵坐标为对数刻度
#ax.set_yscale('log')#设置柱子的纵坐标为对数刻度
#plt.text(6+1.2,selected_data.iloc[4,5]-0.2, 'A ({:.1f}X)'.format(selected_data.iloc[4,5]), fontsize = 12,ha = 'center')
#plt.text(6+0.3,selected_data.iloc[4,2]+0.4, 'B({:.1f}X)'.format(selected_data.iloc[4,2]), fontsize = 12,ha = 'center')
#plt.text(3,selected_data.iloc[2,1]+0.5, '{:.1f}x'.format(selected_data.iloc[2,3]/selected_data.iloc[2,1]), fontsize = 7,ha = 'center')
#plt.text(4-0.1,selected_data.iloc[3,1]+2, '{:.1f}x'.format(selected_data.iloc[3,3]/selected_data.iloc[3,1]), fontsize = 7,ha = 'center')
#plt.text(5-0.1,selected_data.iloc[4,1]+10, '{:.1f}x'.format(selected_data.iloc[4,3]/selected_data.iloc[4,1]), fontsize = 7,ha = 'center')
# 设置图表标题和轴标题
#plt.title('N = 4 , I_n = 1000')
#plt.title('Enron',fontsize = 12)
plt.xlabel('The number of nonzeros of the input tensor',fontsize=12)
plt.ylabel('Fit',fontsize=12)
# 设置图例
plt.legend(loc='best', ncol=1,fontsize=12)#设置图例的位置和列数
#横坐标为作图数据的时候,设置横纵坐标的显示范围,和刻度间隔
#ax.set_xlim([0.08, 10.5]) #设置坐标显示范围
#xtick_interval = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]#设置刻度间隔
#ax.set_xticks(ticks=xtick_interval)
#ax.set_ylim([0.5, 1.4]) #设置坐标显示范围
#横坐标的刻度不显示作图所用的数据的时候,可以配合plt.xticks显示此处设置的标签
labels = ['1K','10K','100K','1M','10M']
positions = selected_data.iloc[:,0].tolist()
plt.xticks(positions , labels,fontsize = fontsize) #使得标签现实的是给定的文字标签
#plt.xticks(x, fontsize=12, rotation=45,loc='inside')#设置标签的文字大小和旋转方向
plt.yticks(fontsize= fontsize)
#以下代码是为了绘制局部放大图
#第一步,嵌入绘制局部放大图的坐标系
axins = ax.inset_axes((0.08, 0.05, 0.25, 0.25))
#上述代码的含义是:以父坐标系中的x0=0.2x,y0=0.2y为左下角起点,嵌入一个宽度为0.4x,高度为0.3y的子坐标系,其中x和y分别为父坐标系的坐标轴范围。
axins.plot(selected_data.iloc[:,0], selected_data[2],marker='o', label='order=4,dim=100')
axins.plot(selected_data.iloc[:,0], selected_data[3],marker='v', label='order=4,dim=1000')
axins.plot(selected_data.iloc[:,0], selected_data[4],marker='d',label='order=3,dim=1000')
axins.plot(selected_data.iloc[:,0], selected_data[5],marker='*',label='order=5,dim=100')
axins.plot(selected_data.iloc[:,0], selected_data[6],marker='s',label='order=5,dim=1000')
axins.plot(selected_data.iloc[:,0], selected_data[7],marker='^',label='order=6,dim=100')
axins.plot(selected_data.iloc[:,0], selected_data[8],marker='h',label='order=6,dim=1000')
axins.plot(selected_data.iloc[:,0], selected_data[9],marker='x',label='order=7,dim=100')
axins.plot(selected_data.iloc[:,0], selected_data[10],marker='+',label='order=7,dim=1000')
#设置局部放大后的显示范围
x_ratio = 0.3 # x轴显示范围的扩展比例
y_ratio = 0.6 # y轴显示范围的扩展比例
#设置x轴的显示范围
xlim0 = selected_data.iloc[:,0][25] - 0.2
xlim1 = selected_data.iloc[:,0][25] + 0.2
#这里的25来源于我们从excel种读取数据后,python人认为我们读取的是1到11列,23到28行
#而25行就是我们图中的横坐标方向上的第三个数据值(1K,10K,100K),就是我们想要放大的数据的横坐标的坐标值
#设置Y轴的显示范围
y = np.hstack((selected_data.iloc[2,1],selected_data.iloc[2,4],selected_data.iloc[2,6],selected_data.iloc[2,8]))
#我们想要放大的四个数据(原始数据的纵坐标值)的组成一个数组,找出其中最大的和最小的,进行纵坐标范围的确定
ylim0 = np.min(y) - (np.max(y) - np.min(y)) * y_ratio
ylim1 = np.max(y) + (np.max(y) - np.min(y)) * y_ratio
# 调整子坐标系的显示范围
axins.set_xlim(xlim0, xlim1)
axins.set_ylim(ylim0, ylim1)
# 建立父坐标系与子坐标系的连接线
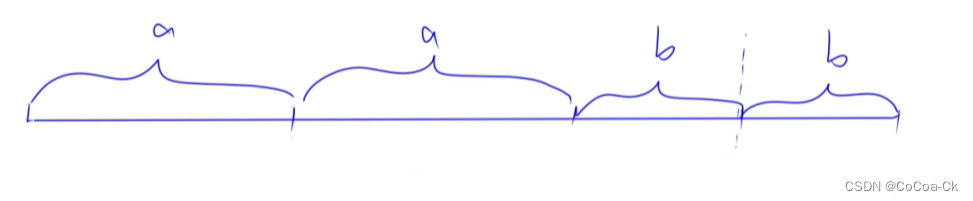
# loc1 loc2: 坐标系的四个角
# 1 (右上) 2 (左上) 3(左下) 4(右下)
mark_inset(ax, axins, loc1=4, loc2=1, fc="none", ec='gray', lw=1.5,linestyle='--')
axins_labels = ['10K','100K','1M']#设置刻度标签,不设置默认显示的是(xlim0, xlim1)之间的数字
axins.set_xticks([xlim0,(xlim0+xlim1)/2,xlim1]) # 设置刻度位置
axins.set_xticklabels(axins_labels) # 在对应的刻度位置上打上对应的标签
#画第二个子图
axins1 = ax.inset_axes((0.77, 0.2, 0.2, 0.38))
#上述代码的含义是:以父坐标系中的x0=0.2x,y0=0.2y为左下角起点,嵌入一个宽度为0.4x,高度为0.3y的子坐标系,其中x和y分别为父坐标系的坐标轴范围。
axins1.plot(selected_data.iloc[:,0], selected_data[2],marker='o', label='order=4,dim=100')
axins1.plot(selected_data.iloc[:,0], selected_data[3],marker='v', label='order=4,dim=1000')
axins1.plot(selected_data.iloc[:,0], selected_data[4],marker='d',label='order=3,dim=1000')
axins1.plot(selected_data.iloc[:,0], selected_data[5],marker='*',label='order=5,dim=100')
axins1.plot(selected_data.iloc[:,0], selected_data[6],marker='s',label='order=5,dim=1000')
axins1.plot(selected_data.iloc[:,0], selected_data[7],marker='^',label='order=6,dim=100')
axins1.plot(selected_data.iloc[:,0], selected_data[8],marker='h',label='order=6,dim=1000')
axins1.plot(selected_data.iloc[:,0], selected_data[9],marker='x',label='order=7,dim=100')
axins1.plot(selected_data.iloc[:,0], selected_data[10],marker='+',label='order=7,dim=1000')
#设置局部放大后的显示范围
x_ratio = 0.3 # x轴显示范围的扩展比例
y_ratio = 0.02 # y轴显示范围的扩展比例
#设置x轴的显示范围
xlim00 = selected_data.iloc[:,0][26] - 0.2
xlim10 = selected_data.iloc[:,0][26] + 0.2
#这里的25来源于我们从excel种读取数据后,python人认为我们读取的是1到11列,23到28行
#而25行就是我们图中的横坐标方向上的第四个数据值(1K,10K,100K,1M),就是我们想要放大的数据的横坐标的坐标值
#设置Y轴的显示范围
y1 = np.hstack((selected_data.iloc[3,1],selected_data.iloc[3,2],selected_data.iloc[3,3],selected_data.iloc[3,4],selected_data.iloc[3,5],selected_data.iloc[3,6],selected_data.iloc[3,7],selected_data.iloc[3,8],selected_data.iloc[3,9]))
#我们想要放大的四个数据(原始数据的纵坐标值)的组成一个数组,找出其中最大的和最小的,进行纵坐标范围的确定
ylim00 = np.min(y1) - (np.max(y1) - np.min(y1)) * y_ratio-0.001
ylim10 = np.max(y1) + (np.max(y1) - np.min(y1)) * y_ratio+0.001
# 调整子坐标系的显示范围
axins1.set_xlim(xlim00, xlim10)
axins1.set_ylim(ylim00, ylim10)
# 建立父坐标系与子坐标系的连接线
# loc1 loc2: 坐标系的四个角
# 1 (右上) 2 (左上) 3(左下) 4(右下)
mark_inset(ax, axins1, loc1=2, loc2=4, fc="none", ec='gray', lw=1.5,linestyle='--')
axins1_labels = ['100K','1M','10M']#设置刻度标签,不设置默认显示的是(xlim0, xlim1)之间的数字
axins1.set_xticks([xlim00,(xlim00+xlim10)/2,xlim10]) # 设置刻度位置
axins1.set_xticklabels(axins1_labels) # 在对应的刻度位置上打上对应的标签
#保存和显示图片,必须先保存,后显示图片
plt.savefig('Scalability_NNZ_Fit.png',dpi=300,bbox_inches='tight')
plt.show()
最终效果: