一、回顾上期
上一篇讲到在Java中,集合和容器是非常重要的概念,用于存储和操作数据。在集合中,有单列集合和双列集合两种类型。我们在上一篇将单列集合中的list类讲完了,这一篇将会将集合中剩余部分介绍完,话不多说,那就开始吧!
二、单列集合中的set集合
话说单列集合中,分为两类,一种是list类,一种是set类;两类都是实现了Collection接口,有着一些共同的方法,那既然有了list我们为何还要又单独定义一个set类呢
原来,list类的出现更加类似与数组这样线性的存储结构,而set的出现是为了方便操作,两者的实现目的不同,所以使用场景和底层逻辑也有所不同,正因如此,list允许集合中出现重复元素而set不允许。
set集合中共有两个子类,hashSet(无序)、TreeSet(有序)
(1)HashSet
hashSet是set集合的子类之一,具有如下特点
-
不允许重复元素:HashSet中不允许存储重复元素,每个元素在HashSet中只会出现一次。当尝试向HashSet中添加重复元素时,新元素不会被添加进集合。
-
无序性:HashSet中的元素没有固定的顺序,即不保证元素的顺序与插入顺序相同。这是因为HashSet内部使用哈希表来存储元素,元素的存储位置是根据元素的哈希码决定的。
-
高效的查找操作:由于HashSet基于哈希表实现,查找元素的效率很高。当需要判断某个元素是否存在于HashSet中时,HashSet会通过计算元素的哈希码来快速找到对应的存储位置,从而实现快速的查找操作。
-
添加、删除元素效率高:HashSet对于添加和删除元素的操作效率也很高,因为它们都可以通过哈希码快速定位到元素的存储位置。
hashSet主要的方法如下(成员方法,需要定义hashSet对象)
set.clear();//清空 set.contains();//判断是否包含某一元素 set.remove();//删除 set.iterator();//获取迭代器对象
hashSet的主要遍历方式
1、使用迭代器(Iterator)进行遍历:
Set<Object> hashSet = new HashSet<>();
// 添加元素到HashSet
hashSet.add("Apple");
hashSet.add("Banana");
hashSet.add("Orange");
Iterator<Object> iterator = hashSet.iterator();
while (iterator.hasNext()) {
Object element = iterator.next();
// 处理每个元素
System.out.println(element);
}
2、使用增强型for循环进行遍历:
Set<Object> hashSet = new HashSet<>();
// 添加元素到HashSet
hashSet.add("Apple");
hashSet.add("Banana");
hashSet.add("Orange");
for (Object element : hashSet) {
// 处理每个元素
System.out.println(element);
}
不知道大家看到这里会不会好奇,当set集合添加元素时如何判断元素重复的?
如果每次都使用equals效率很低,肯定不是hashSet底层所使用的。其实在底层使用的是hashCode();
Object的hashCode的方法是判断地址,而Set集合调用的是重写的hashCode方法,根据内容计算哈希值;遍历时会先使用哈希值比较是否相等,再使用equals,这既保证效率又保证安全。我们使用的基本数据类型包装类中都已经将hashCode()方法重写过,可以放心使用。但是当我们自定义一个数据类型时,就需要重写hashCode()方法,以确保HashSet集合可以很好的比较和排序
例如我们写一个学生类型,包括成员变量姓名、年龄;可以这样写
@Override
public int hashCode() {
int result = name != null ? name.hashCode() : 0;
result = 31 * result + age;
return result;
}
(2)TreeSet
TreeSet是Set接口的另一个常见实现类,它基于红黑树(Red-Black Tree)实现,具有以下特点:
-
自动排序:TreeSet中的元素会按照它们的自然顺序(natural ordering)或者通过Comparator接口指定的顺序进行排序。当元素被添加到TreeSet中时,它们会被自动排序,这使得TreeSet是一个有序的集合。
-
不允许重复元素:与HashSet类似,TreeSet中不允许存储重复元素,每个元素在TreeSet中只会出现一次。
-
高效的查找操作:由于TreeSet内部基于红黑树实现,查找、插入、删除元素的操作效率都很高。红黑树是一种自平衡的二叉搜索树,保证了元素的快速查找和操作。
-
提供有序性:TreeSet中的元素是有序的,可以根据元素的自然顺序或者指定的排序规则进行遍历。这使得TreeSet适合需要有序集合的场景。
话不多说,直接上方法
TreeSet<Integer> set =new TreeSet<>();
set.add(3);
set.add(4);
set.add(1);
set.add(2);
set.add(3);
System.out.println(set);//[1, 2, 3, 4]
set.clear();//清空
set.size();//长度
set.contains("");//是否包含某一元素
set.first();//删除并返回第一个元素
set.isEmpty();//判断是否为空
set.remove(1);//删除指定元素
set.pollLast();//删除并返回最后一个元素需要注意的是:TreeSet中的元素必须实现Comparable接口并且重写compareTo()方法,用于确定排序的规则,话不多说,上案例
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student o) {
return this.age-o.age;
}
}
三、双列集合
双列集合是一种数据结构,它包含一组成对的元素,每个元素都包含两部分:一个键和一个值。
在Java中,双列集合通常使用Map接口及其实现类来表示。Map接口表示一种键值对的映射关系,常用的实现类有HashMap、TreeMap、HashTable等。
1、hashMap--基于哈希表实现,可以提供快速的插入、查找和删除操作。
常用方法:
public static void main(String[] args) {
HashMap<String,String> map =new HashMap<>();
map.put("c","cc");//添加
map.put("x","xx");
map.put("z","zz");
map.put("a","aa");
map.put("c","CC");
map.put("h","hh");
System.out.println(map);
map.get("c");//输入key获取value
map.clear();//清空
map.remove("h");//输入key删除这个键值对并返回value
map.containsKey("k");//判断是否包含该键,返回布尔值
map.containsValue("aa");//判断是否包含这个值,返回布尔值
map.isEmpty();//判断是否为空返回布尔值
map.size();//返回键值对数量
map.values();//将所有的值存入单列集合 Collection类型对象接收
map.keySet();//将所有的key存入set集合 set类型对象接收
}遍历
public static void main(String[] args) {
HashMap<String,String> map =new HashMap<>();
map.put("c","cc");//添加
map.put("x","xx");
map.put("z","zz");
map.put("a","aa");
map.put("c","CC");
map.put("h","hh");
//方式1 同过map.set将所有key存入集合,通过map.get获取value
Set<String> keySet =map.keySet();
for(String key:keySet){
System.out.println(key+":"+map.get(key));
}
System.out.println();
//方式2:map.entrySet();返回一个Entry类的集合,Entry里包含键值对
//Entry包含相关方法
Set<Map.Entry<String,String>>entries=map.entrySet();
for(Map.Entry<String,String> entry:entries){
System.out.println(entry.getKey()+entry.getValue());
}
}put方法的底层逻辑
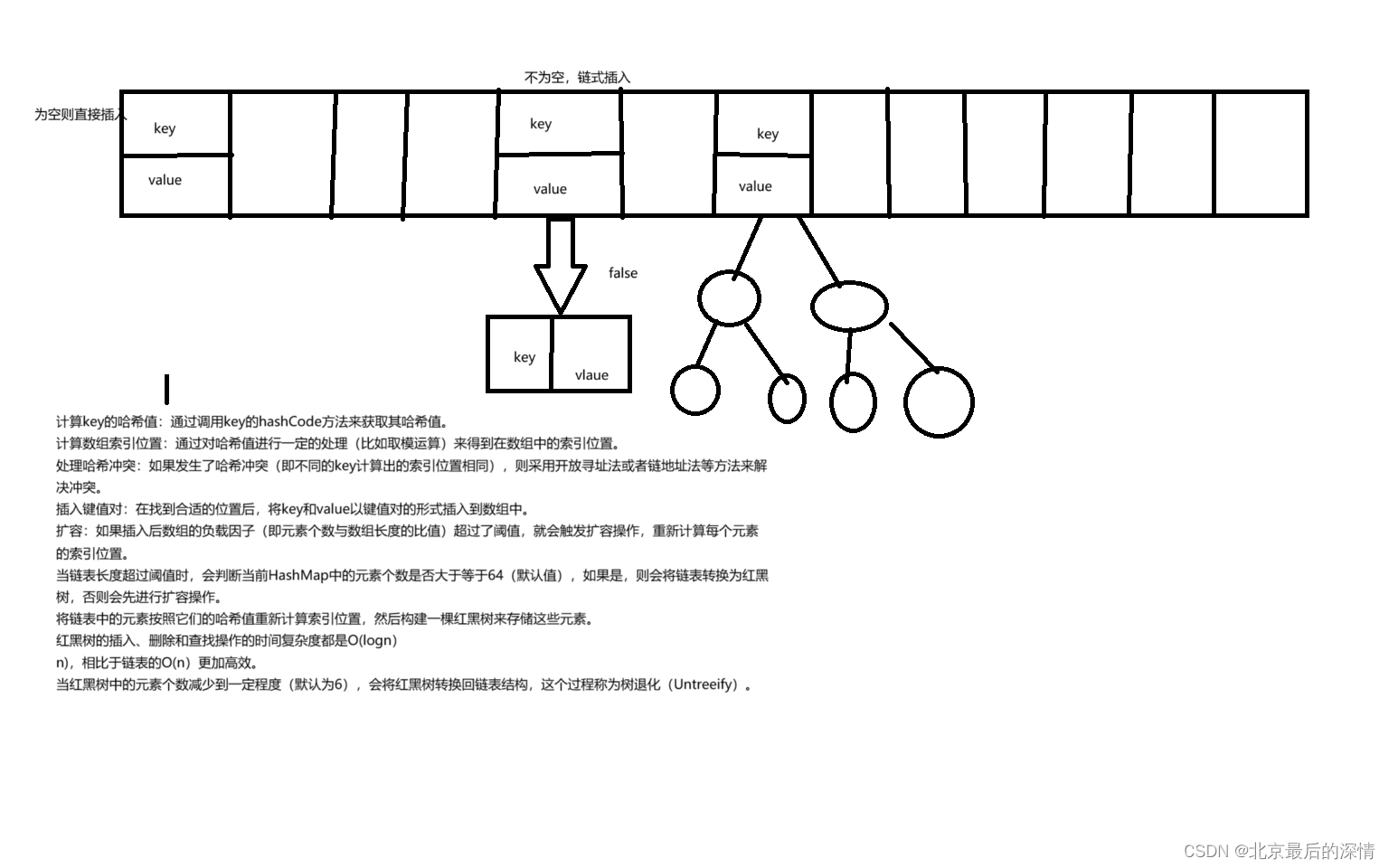
2、TreeMap--TreeMap是Java中另一个常用的双列集合,它基于红黑树实现,可以提供按照键的顺序进行遍历的特性。
package com.wbc.javaclllection.Map双列集合.TreeMap;
import java.util.TreeMap;
public class TreeMapDemo {
/*
map: 键值对 键不能重复 值可以重复
TreeMap:键可以排序 底层使用树结构 键的类型必须实现Comparable接口
*/
public static void main(String[] args) {
TreeMap<Integer,String> treeMap =new TreeMap<>();
treeMap.put(1,"a");
treeMap.put(2,"c");
treeMap.put(5,"d");
treeMap.put(4,"e");
treeMap.put(3,"a");
System.out.println(treeMap);
//方法与HashMap一致
}
}
3、HashTable--类似于HashMap,也是基于哈希表实现的。
HashTable底层与HashMap相同,但是HashTable是线程安全的 方法多了一个synchronized关键字 HashMap可以有一个键为null、值也可以为null,HashTable不能存储null,键值都不行
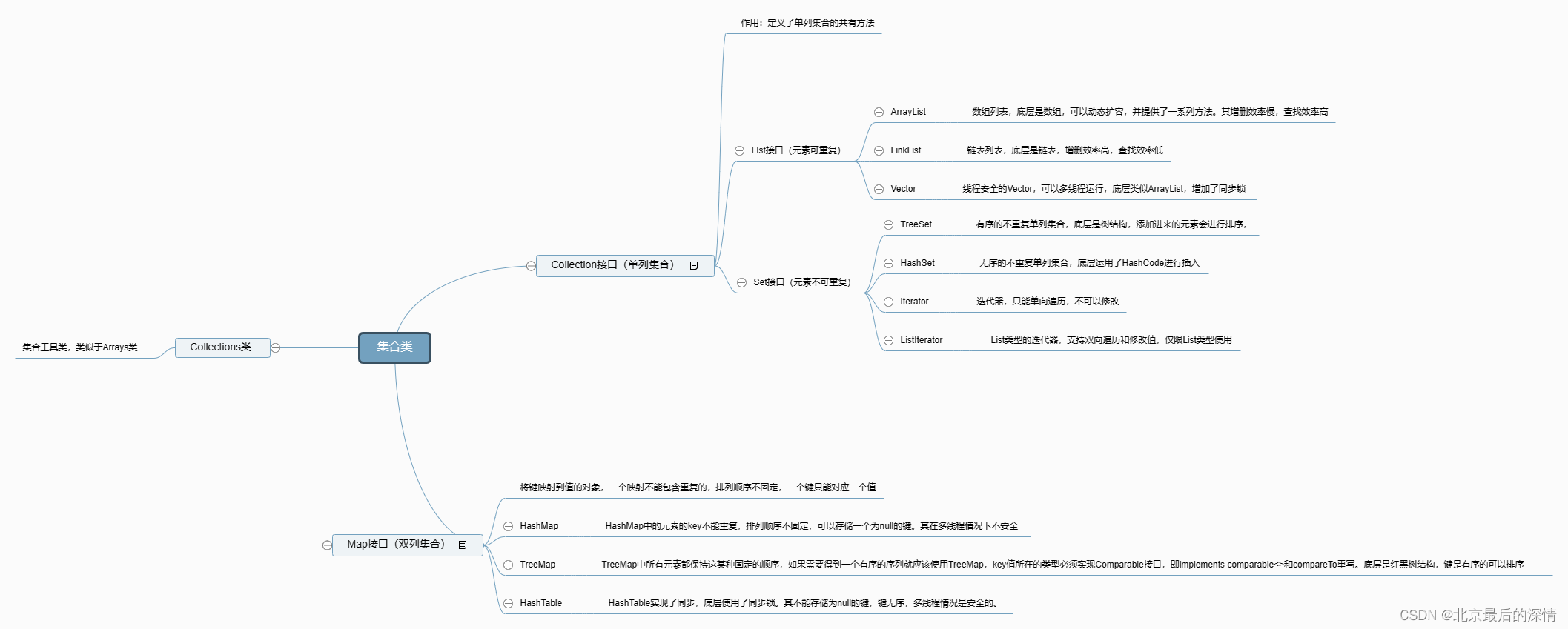
四、本章结构--思维导图