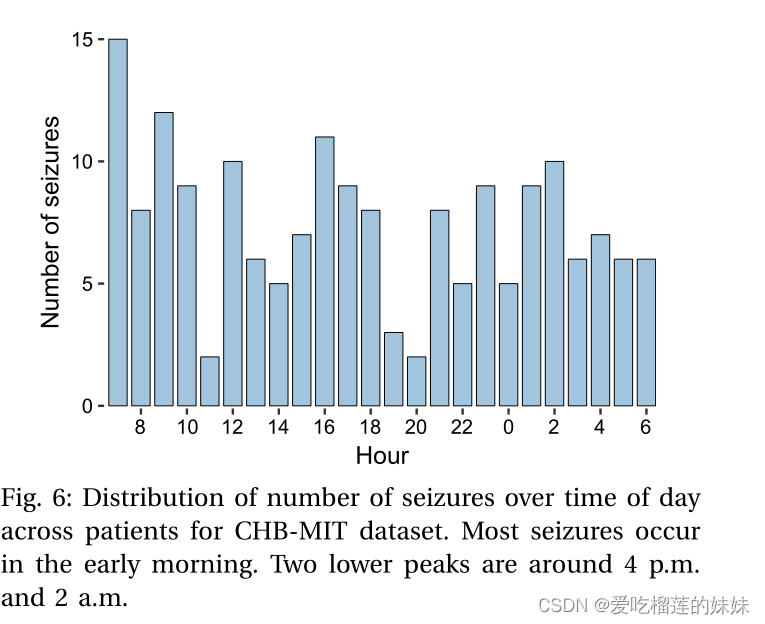
针对目前智能计算机及大规模数据的发展,依据大脑处理语音、图像数据方法的deep learning技术应运而生。deep learning技术是应用于音频信号识别,模仿大脑的语音信号学习、识别的模式。在音频信号处理的过程中,运用deep learning进行音频数据的特征提取和训练,将大幅度提高音频信号识别的准确性。
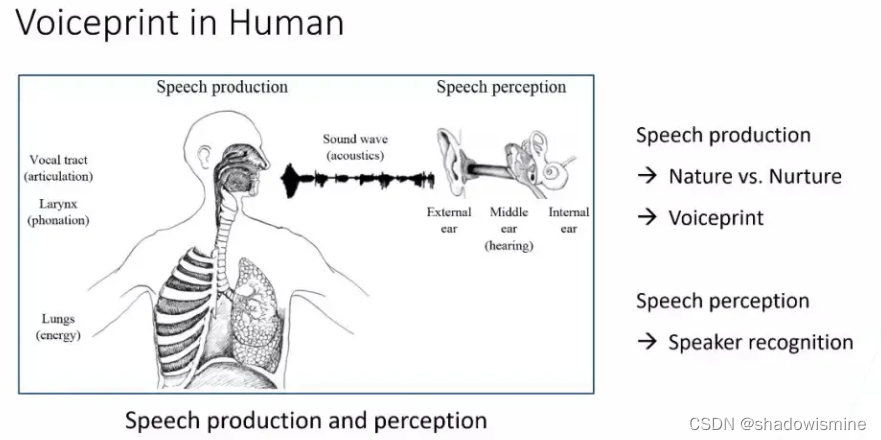
首先看下Speaker recognition声纹识别,声纹是由人类的“发音机理”所产生的,比如“肺”,“喉头”,“口腔”。大部分人在这些尺寸和形态上是千差万别的,这是先天的一些差异。再加上后天形成,比如“年龄性格”,“不同地域”,产生些后天的影响,使得我们每个人所产生的语音信号中,蕴含的个性信息是不同的,这种个性信息我们称它为叫“声纹”。通过这种信号为载体,传入到人耳中,通过“外耳”“中耳”“内耳”逐层滤波,然后将描述语音信号中描述说话人个性的信息,传入到大脑皮层中,进而实现“听音辨人”。
机器看到这些语音信号,那它如何去实现并且完成声纹识别呢?
对于机器而言,困难是存在的,比如语音信号在产生过程中,会交织着各种各样的混杂信息,在众多的信息中,把说话人信息单独的剥离或者分离出来,这是一个很困难的事情,
第二点是语音信号的不确定性,我们每个人的声纹会受我们所处的环境,我们的生理状况等影响从而产生一些不确定性的漂移,随着年龄的增长,我们的语音,我们的声纹也会发生一些变化,除此以外,我们的一些硬件设备,比如“麦克风”,“遥控器”,“声音设备”等,在信号传输过程中也会产生各种各样的畸变,都会使得语音信号带来各种各样的不确定性,对我们的声纹识别的性能产生很大的影响。
声纹识别发展的历程
主要分为三个阶段,第一个阶段是“特征设计或特征工程”。第二个阶段是“贝叶斯的模型”。第三个阶段是“Deep Embedding”。

首先了解“特征设计或特征工程”。“特征设计或特征工程”的目标非常简单,当我们拿到信号之后,从模式识别的角度上看,怎么样去提取对说话人特性描述性很强,或者很敏感的一种特点,如果找到这样一种有效简单的特点,后端匹配或者打分模型,就可以把复杂度降到很低。

“特征设计或特征工程”的目标就是发觉说话人敏感的特点。从语音信号中挖掘,借助人类的先验的知识,去设计各种各样的特征。有了特征之后,下一步就是“建模”,这样就进入第二阶段。
所谓“贝叶斯的模型”阶段,不得不提到“高斯混合模型”,这是特别经典的说话识别模型,是利用多个高斯概率分布的线性组合,拟合一个说话人的分布,具体是怎么做的,主要分为两个过程。
第一个过程是“构建UBM空间”,第二个过程是用改编的方法,去推断对应的说话者的高斯混合。“UBM”是用大量的,来自不同人的语音,然后去训练得到一个描述与说话人无关的发音空间。发音空间代表了不同人说话的共性,通过一些无监督聚类的方法,能够把整个声学发音空间聚成各种各样的小圈,利用说话人少量的语音信号或者对应的特征,在UBM的基础上进行改编,从而得到说话人的高斯混合模型。
这样一个模型,它有两个特点,第一个特点是“精细组织”,对于“UBM”到“GM”的过程中,通常会将每个组成部分的矩阵固定不动。第二个是把每个组件优先的位置固定住,只对平均矢量进行改编,所以只需少量的样本数据,就可以完成相应的改编。
2010年之后,随着深度学习的发展,其在图像自然语言处理,语音识别领域都取得了一系列非常显著的突破 ,从而引发研究思考,可否将这种深度学习的方法用到声纹识别的任务中,而后提出“deep embedding”的概念。(The ’embedding’ denotes the problem of learning a vector space where speakers are “embedded”)不同的embedding模型用于学习不同向量空间分布。
为什么大部分人会选用神经网络模型去做speech embedding?
首先是它的网络模型结构非常灵活,可以做各种各样的组合。神经网络模型“layer by layer”的结构,这种结构有非常强大表征能力。其次,hierarchical representation(层次化结构的表示),对于语音信号来说,之前是一些比较浅层信息,到达高层的话,可能就是一些更加抽象,更加重要的语言学信息。所以它是一种分层的表征形式,很利于从神经网络中去学习,或者分析语音信号中所蕴含的说话人的一些表征。第三点,研究者们提出了各种有效的学习方法,例如“SGD”等等,使得网络训练更加易于收敛,更具有概括的能力。对于语音信号而言,应该选择一个什么样的“network structure”,能够让我们比较愉快的学习语音信号中所蕴含的说话人的“vector”,或者说话人的“embedding”,这时还是需要重新回到对于信号的一些理解。
如何实现deep embedding?
语音信号有两个“property”,第一部分是“局部属性”,在时域和频率上具有一些非常稳定的局部的属性,第二部分是由于人类发音器官很难完成短时的畸变,所以人类在发音过程中是一个渐变的过程,是由人类发音机理所决定的。将这两个属性对应到说话人的特性,可以了解到,即便不同的说话人,它的一些局部属性具有很大的相似性,但是不同的人这种局部属性分布还是有很大的差别。
17年业内相关人士开展了关于的“deep embedding”的研究,提出从原始的“spectrum”,如何给比较符合人类感知机理的一个“structure”,最后能够去学习或解析出来“speaker”的“embedding”。

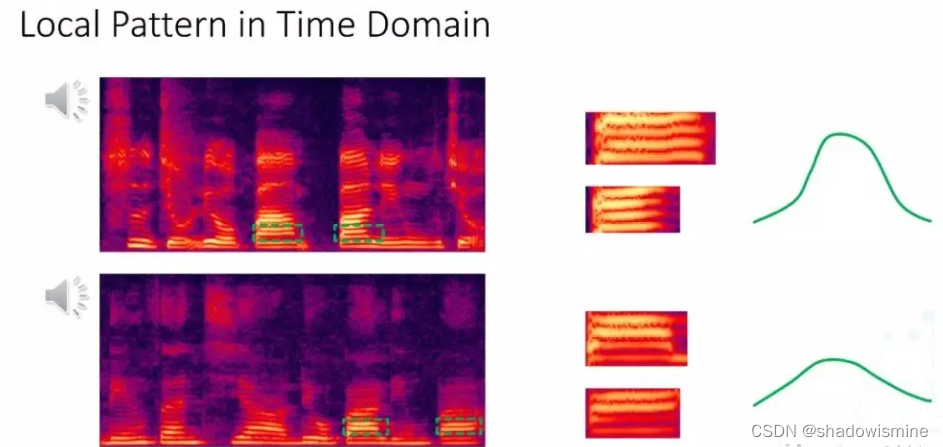
如图所示,上下两个“spectrum”来自两个不同的人,对于上面“spectrum”来讲,可以找到频带,对于下面的人,同样找到了与它对应的“logo pattern”,从平移的角度来看,不同说话人的“logo pattern”虽然具有相似性,但是它的“distribution”还是有差别的,这种现象在时域上也有同样的一些表现,所以既然语音信号中局部跟动态的属性能够体现出来说话人的特点,我们对于神经网络在设计的过程中,我们需要考虑到这些属性,能否将这些属性先验地加入到网络中,使得网络能够更好的提取说话人的特征表征。
专业人士提出了一个基于两层“convolution neural network”,加上四层“temporal neural network”一个“CT-DNN”的结构,然后利用“P-norm”加“batch normalization”的方法,实现对“vector”的规整。最后取得了非常不错的效果。
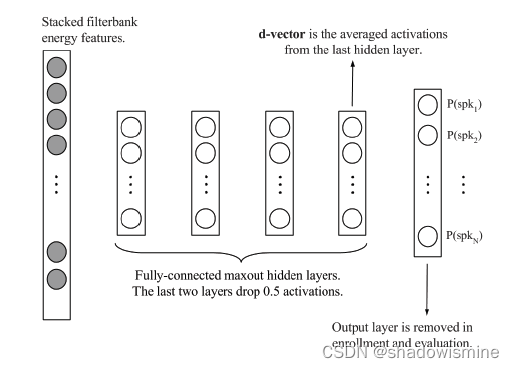

截止到18年出现了两个比较“the state of the art”的方法,第一个是基于一阶二阶“statistic”统计量的“pooling x-vector”,另一个是基于“flame level”的“d-vector”模型。
“x-vector”的模型通过在“pooling”层引入一阶二阶的统计信息,使得网络“training”不但是针对某一个“flame”去“training”,而是针对一个“distribution”去“training”。它学的是一个“distribution”一个“μ”一个“σ”,高斯的一个“distribution”。
对于“d-vector”模型来说,它是通过增加它们“delay”或者是“input context”,去尽可能的让网络学习上下文,“context”足够大“context”充足的一个“vector”,然后“vector training”完之后,可以从比较靠后的“hidden layer”里,去把“flame-level”的“embedding”获取出来。
Deep embedding的四个关键部分
在开创性工作d-vector和x-vector的推动下,许多deep embedding技术涌现出来,其中大部分由四个关键部分组成——网络输入、网络结构、时域池化和目标函数。这些部分包括但不限于以下内容:
网络输入和网络结构:网络输入可以分为两类——时域中的原始波信号和时频域中的声学特征,包括频谱图、梅尔滤波器组(F-bank)和MFCC。网络结构更加多样,但本质上都源自于DNN、RNN/LSTM、CNN。
时域池化:时域池化表示神经网络的转换层,将帧级embedding特征转换为段级embedding特征。时域池化策略由两类组成——统计池化和基于学习的池化。
目标函数(损失函数):目标函数对说话人识别的效果影响很大。d-vector和x-vector都采用softmax作为输出层,以最小化交叉熵为目标函数,但它可能不是最优的。最近,许多工作设计了多种目标函数以进一步提高性能。

可以看到,基于CNN的神经网络和f-bank/MFCC声学特征的研究相对较多,而一些二维卷积结构,例如ResNet,使用谱图作为输入特征。
声纹识别的研究方向
声纹识别主要有四个研究分支:声纹验证(speaker verification),声纹识别(speaker identification),语音分离( diarization)以及声纹识别加强算法(robust speaker recognition)。
声纹验证
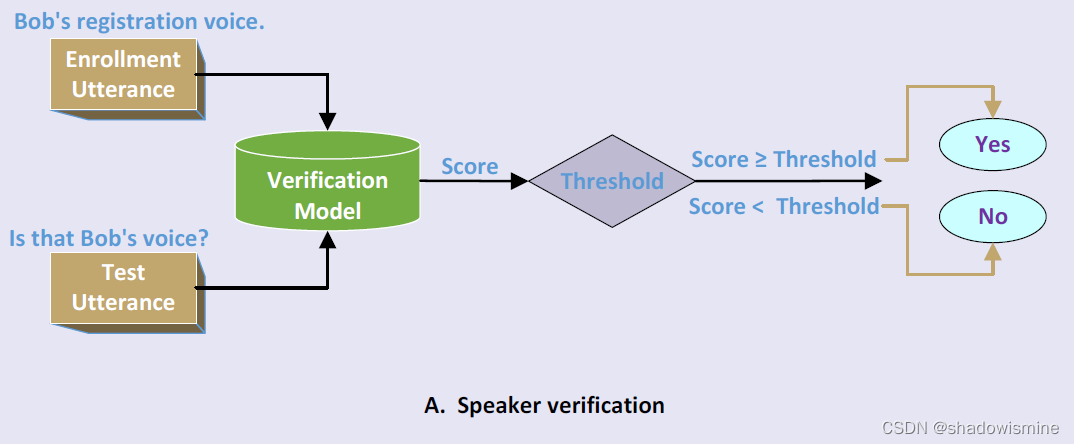
该任务是已知注册人时,给定一条测试音频,来判断当前音频是否由目标说话人发出,关注点是能否准确的给出是或否的判断,是最简单的一个任务。
声纹识别

该任务是再已经注册N个人的时候,给定一个音频,判断当前音频是由哪个人发出的,这个任务还可以根据说话人的识别范围划分为闭集和开集下的辨认,当确定说话人在注册声纹库里时,是一个N选一的有限范围选一个的闭集任务,当不确定当前音频是否在注册声纹库里时,是一个开集任务。
语音分离/声源分离

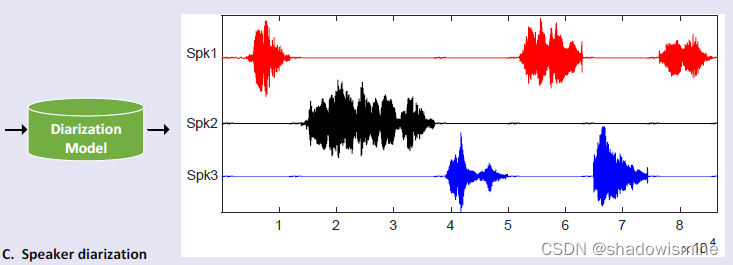
主要是在一段连续的语音中准确的切分出不同说话人对应的音频,解决谁在什么时候说话的问题(who spoke when)。例如客服系统或电话会议中的音频,能很明显的区分多个人的时间段,这个时候主要应用的是声纹识别技术,将每一个声音片段归类到对应的说话人上去。另一个主要的问题是鸡尾酒会的问题,就是我们的某一段音频中,不同人的说话会有重叠覆盖。
声纹识别加强算法
声纹识别中主要用到的领域自适应(Domin adaptation)、语音增强(Speech enhancement)技术以及数据增强技术(Data Augmentation),主要解决上面提到的不同信道和来源的识别问题,以及噪声等复杂场景下的准确率问题。
整体技术框架如下图所示:

参考文献:Deep Embedding for Speaker Recognition,Deep Embedding for Speaker Recognition - 知乎主讲嘉宾:李蓝天(贪心学院特邀讲座嘉宾) 清华大学语音和语言技术中心 博士后助理研究员,主要从事语音信号处理领域的相关研究,研究方向包括声纹识别、语音识别、语种识别、情感识别等。现已发表学术论文34篇,…![]() https://zhuanlan.zhihu.com/p/77728449
https://zhuanlan.zhihu.com/p/77728449
Speaker Recognition Based on Deep Learning: An Overview
基于深度学习的声纹识别概述(Speaker Recognition Based on Deep Learning: An Overview) - 知乎前言:做技术不能只见树木,不见森林,读综述类的论文,能很好的帮我们把握业界的前进方向。本文是2021年4月4日更新,由西工大张晓雷教授所作,全面的分析了说话人识别方向的几个关注点,本文及接下来的几篇文章会…![]() https://zhuanlan.zhihu.com/p/381526743
https://zhuanlan.zhihu.com/p/381526743