项目简述:
本项目采用H2O AutoML工具,针对加州房屋销售价格预测问题进行了深入研究与建模。项目以Kaggle提供的加州房屋
交易数据集为基础,通过数据清洗、特征工程、模型训练与评估等步骤,构建了一种基于集成学习策略的房价预测模型。该模型特别关注了异常值检测与处理、缺失值填充、数据类型转换、变量重要性筛选以及特征选择等多个关键环节,并运用统计学方法对数值型特征进行归一化处理,旨在提高模型泛化能力和预测精度。
步骤概述:
数据导入与初步探索:
首先导入所需库文件(如numpy、pandas等),加载训练集与测试集数据,并对原始数据的基本结构与大小进行检查。
数据清理:
离群点识别与剔除:
通过绘制“出售价格”与各相关特征(如“挂牌价”、“税估价值”、“年税收额”、“上次出售价格”)之间的散点图,发现并移除明显偏离正常分布的离群点。
特征处理:
对“卧室数”列进行特殊处理,将包含特定描述的条目转化为纯数字形式;同时将“邮编”列转换为字符串类型,以便后续分析。
缺失值处理:
统计并展示数据集中各列缺失值情况,依据缺失值数量与性质,分别采用零值填充、最大值填充、‘None’填充及众数填充等方法对缺失值进行有效填补。
数据转换与预处理:
目标变量调整:
对目标变量“出售价格”进行对数变换,以减小其偏斜程度,便于模型训练。
特征分布校正:
计算数值型特征的偏度,识别并记录高偏度特征。随后,对这些特征应用Box-Cox变换进行校正,降低其偏斜程度,提升模型性能。
异常值修正:
对于某些特征(如“车库车位数”、“总车位数”),设定阈值,确保其值大于零,避免引入不合理信息。
特征选择与模型训练:
特征筛选:
根据变量重要性指标,从所有特征中选取部分具有较高预测价值的特征用于模型构建。
模型搭建与训练:
利用H2O框架初始化并配置AutoML任务,指定最大模型数量、算法类型(仅限XGBoost)、最大运行时间、停止准则(RMSLE)及排序标准(RMSLE)。然后在预处理后的训练集上训练AutoML模型。
模型融合与预测:
集成预测:
鉴于单个模型可能存在过拟合现象,本项目采取前k个最优模型输出平均值的方式进行集成预测,以期降低方差、提高整体预测性能。
结果提交:
将集成预测结果保存至符合竞赛要求的CSV文件格式,准备提交至Kaggle平台进行评分。
实现代码
导入必要类库
import numpy as np # 用于线性代数的numpy库
import pandas as pd # 用于数据处理和CSV文件读写的pandas库
# 输入数据文件可用在只读的“../input/”目录中
# 例如,运行这行代码(通过点击运行或按Shift+Enter)将列出“input”目录下的所有文件
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename)) # 打印输入目录下所有文件的路径
# 您可以在当前目录(/kaggle/working/)中写入最多20GB的数据,这些数据在使用“Save & Run All”创建版本时将作为输出保留
# 您还可以将临时文件写入/kaggle/temp/,但它们不会在当前会话之外被保存
# 导入plotly的几个模块用于数据可视化
import plotly.express as px # plotly.express简化了创建交互式图表的过程
import plotly.graph_objects as go # plotly.graph_objects允许创建并自定义各种交互式图表
import plotly.figure_factory as ff # plotly.figure_factory提供了一些工具来创建自定义的图表
from plotly.subplots import make_subplots # plotly.subplots用于创建包含多个子图的图
# 导入matplotlib.pyplot用于对比或者结合matplotlib的特性进行可视化
import matplotlib.pyplot as plt
# 导入pandas_profiling用于数据探查和生成报告
from pandas_profiling import ProfileReport
# 导入seaborn用于美化matplotlib的图表以及更高级的统计可视化
import seaborn as sns
# 导入scikit-learn的metrics模块用于评估模型性能
from sklearn import metrics
# 导入scipy的stats模块用于统计分析
from scipy import stats
# 导入copy的deepcopy用于创建对象的深拷贝
from copy import deepcopy
# 导入h2o框架用于处理大规模数据以及建模
import h2o
这段代码主要目的是导入数据处理、可视化和建模所需的Python库。这些库包括Plotly用于交互式图表制作,PandasProfiling用于数据概况生成,Seaborn用于美观的统计图表,Scikit-Learn用于模型评估,Scipy用于统计分析,以及H2O用于大规模数据处理和建模。
1. 数据清洗
导入并观察数据
从指定路径读取加利福尼亚州房屋价格的训练集和测试集CSV文件。
train_df = pd.read_csv('/kaggle/input/california-house-prices/train.csv')
test_df = pd.read_csv('/kaggle/input/california-house-prices/test.csv')
# 输出训练集和测试集的数据形状
train_df.shape, test_df.shape
((47439, 41), (31626, 40))
根据以下散点图,删除离群点
从train_df数据框中删除指定的行索引
train_df=train_df.drop([3674,6055,32867,34876,43398,44091,44633])
将训练集中的‘Sold Price’(成交价格)和‘Listed Price’(挂牌价格)列合并,
并使用Plotly Express库绘制散点图。
data = pd.concat([train_df['Sold Price'], train_df['Listed Price']], axis=1) # 合并成交价格和挂牌价格列
# 使用Plotly Express绘制散点图,比较挂牌价格与成交价格
fig = px.scatter(data, x='Listed Price', y='Sold Price')
fig.show() # 展示散点图
将训练集中的“Sold Price”(成交价格)和“Tax assessed value”(税收评估值)两列合并,
并创建一个散点图来展示这两个变量之间的关系。
import pandas as pd
import plotly.express as px
# 合并两列数据
data = pd.concat([train_df['Sold Price'], train_df['Tax assessed value']], axis=1)
# 创建并显示散点图
fig = px.scatter(data, x='Tax assessed value', y='Sold Price')
fig.show()
将训练集中的“成交价格”和“年税金额”两列合并,并绘制散点图。
import pandas as pd
import plotly.express as px
# 合并数据列
data = pd.concat([train_df['Sold Price'], train_df['Annual tax amount']], axis=1)
# 绘制散点图
fig = px.scatter(data, x='Annual tax amount', y='Sold Price')
fig.show()
将训练集中的“成交价格”和“最近成交价格”列合并,并以散点图的形式展示这两个价格之间的关系。
import pandas as pd
import plotly.express as px
# 将“成交价格”和“最近成交价格”列合并为一个新的数据帧
data = pd.concat([train_df['Sold Price'], train_df['Last Sold Price']], axis=1)
# 创建并展示散点图
fig = px.scatter(data, x='Last Sold Price', y='Sold Price')
fig.show()
# 分割特征和标签
y = train_df['Sold Price'].reset_index(drop=True) # 提取标签(售出价格)并重置索引
train_features = train_df.drop('Sold Price', axis=1) # 从训练数据中删除标签列,获取训练特征
test_features = test_df.copy() # 复制测试数据的特征,不做任何修改
# 合并训练和测试特征,重置索引
features = pd.concat([train_features, test_features]).reset_index(drop=True)
features.shape # 输出特征的形状(维度)
初步处理数据
zip列应作为字符串 并对bedroom列作简单处理
处理卧室数量字段,将含有逗号分隔的多个值减少为一个整数表示卧室数量。
如果字段是NaN或只包含数字,则原样返回。
特别地,如果列表中包含’Walk-in Closet’,则在计算卧室数量时将其排除。
def proc_bedroom(x):
# 检查x是否不是NaN且不全为数字
if not pd.isna(x) and not x.isdigit():
temp = x.split(',') # 使用逗号分割x
n = len(x.split(',')) # 计算分割后的部分数量
if 'Walk-in Closet' in temp:
n -= 1 # 如果包含'Walk-in Closet',则减少计数
return n
else:
return x # 如果x是NaN或全为数字,则原样返回
# 应用proc_bedroom函数到features数据框的'Bedrooms'列
features['Bedrooms']=features['Bedrooms'].apply(lambda x: proc_bedroom(x))
# 将'Bedrooms'列转换为数值类型
features['Bedrooms'] = pd.to_numeric(features['Bedrooms'])
# 将'Zip'列转换为字符串类型
features['Zip'] = features['Zip'].astype('str')
缺省值填充
处理缺失数据
# 计算每个特征的缺失值数量并按降序排列
total = features.isnull().sum().sort_values(ascending=False)
# 计算每个特征的缺失值比例并按降序排列
percent = ((features.isnull().sum() / features.isnull().count()) * 100).sort_values(ascending=False)
# 将缺失值数量和比例合并到一个DataFrame中
missing_data = pd.concat([total, percent], axis=1, keys=['Total', 'Percent'])
# 重置索引,以便将特征名称作为行标签
missing_data = missing_data.reset_index()
# 重命名列,以便更直观地理解每个列的含义
missing_data.columns = ['Name', 'Total', 'Percent']
# 显示前10行数据
missing_data[:10]
处理缺失值:对不同的特征采用不同的填充策略
def handle_missing(features):
# 定义需要填充为0的特征列表
zero_fill=['Last Sold Price','Lot','Full bathrooms','Annual tax amount','Tax assessed value','Bathrooms',
'Bedrooms','Total interior livable area','Total spaces','Garage spaces']
# 定义需要填充为'None'的特征列表
none_fill=['Last Sold On','Middle School','Appliances included','Flooring','Laundry features','Cooling features',
'Cooling','Heating features','Heating','Elementary School','High School','Parking features','Parking','Summary']
# 定义需要填充为最大值的特征列表
max_fill=['Middle School Score','Middle School Distance','Elementary School Score','Elementary School Distance',
'High School Score','High School Distance']
# 定义需要填充为众数的特征列表
mode_fill=['Year built','Region']
# 分别对各列表中的特征进行缺失值填充
for c in zero_fill:
features[c]=features[c].fillna(0) # 填充为0
for c in max_fill:
features[c]=features[c].fillna(features[c].max()) # 填充为最大值
for c in none_fill:
features[c]=features[c].fillna('None') # 填充为'None'
for c in mode_fill:
features[c]=features[c].fillna(features[c].mode()[0]) # 填充为众数
return features
处理缺失值的函数。
def handle_missing(features):
# 根据具体实现,这里对features进行缺失值处理
return features
# 对处理后的特征数据进行形状检查,以确保处理过程符合预期
features = handle_missing(features)
features.shape
数据转换
绘制包含直方图、QQ图和箱线图的三维图表,用于数据的可视化分析。
def plotting_3_chart(df, feature):
## 导入必要的库
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
from scipy import stats
import matplotlib.style as style
style.use('fivethirtyeight')
## 创建自定义图表,并设置尺寸
fig = plt.figure(constrained_layout=True, figsize=(12,8))
## 创建一个3行3列的网格
grid = gridspec.GridSpec(ncols=3, nrows=3, figure=fig)
## 绘制直方图
ax1 = fig.add_subplot(grid[0, :2])
ax1.set_title('Histogram') # 设置标题
sns.distplot(df.loc[:,feature], norm_hist=True, ax = ax1) # 绘制直方图
## 绘制QQ图
ax2 = fig.add_subplot(grid[1, :2])
ax2.set_title('QQ_plot') # 设置标题
stats.probplot(df.loc[:,feature], plot = ax2) # 绘制QQ图
## 绘制箱线图
ax3 = fig.add_subplot(grid[:, 2])
ax3.set_title('Box Plot') # 设置标题
sns.boxplot(df.loc[:,feature], orient='v', ax = ax3); # 绘制箱线图
# 对目标变量进行对数变换
y = np.log1p(y)
# 绘制销售价格的图表
plotting_3_chart(pd.DataFrame(y), 'Sold Price')
这段代码中包含的两个主要操作是对目标变量y进行对数变换,然后使用plotting_3_chart函数绘制变量的图表。对数变换通常用于处理偏态分布的数据,以使得数据更加适合进行建模和可视化。plotting_3_chart函数的具体细节没有给出,但从调用方式来看,它应该是用于绘制某种基于数据集的图表,此处用于展示销售价格的数据分布。
寻找数值型列并计算偏度
numerical_columns = features.select_dtypes(include=['int64','float64']).columns # 选择DataFrame中的数值型列
# 计算各数值列的偏度,并按偏度降序排序
skewed_features = features[numerical_columns].apply(lambda x: stats.skew(x)).sort_values(ascending=False)
skewness = pd.DataFrame({'Skew value' :skewed_features}) # 将偏度值存储到DataFrame中
skewness.head(20) # 打印偏度值前20的特征
此函数接受一个数据框,并返回修正偏度的数据框。
def fix_skew(features):
## 导入必要的模块
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
## 获取所有非"object"类型的数据
numerical_columns = features.select_dtypes(include=['int64','float64']).columns
# 检查所有数值特征的偏度
skewed_features = features[numerical_columns].apply(lambda x: stats.skew(x)).sort_values(ascending=False)
high_skew = skewed_features[abs(skewed_features) > 0.5]
skewed_features = high_skew.index
# 执行Box-Cox转换
for column in skewed_features:
features[column] = boxcox1p(features[column], boxcox_normmax(features[column] + 1))
return features
将输入的数值x与0比较,如果小于0则返回0,否则返回x本身。
def reset_zero(x):
return max(x,0)
# 对'Garage spaces'和'Total spaces'两列特征应用reset_zero函数,确保这些特征值非负
features['Garage spaces']=features['Garage spaces'].apply(lambda x: reset_zero(x))
features['Total spaces']=features['Total spaces'].apply(lambda x: reset_zero(x))
# 对数据集中的偏斜特征进行修正,以提高数据分析的准确性
features = fix_skew(features)
# 查看修正后的数据集的前5行
features.head()
将features分离 根据Variable Importances进行挑选
根据给定的特征和目标数据,将特征数据集划分为训练集和测试集。
# 划分数据集为训练集和测试集
x = features.iloc[:len(y), :]
x_test = features.iloc[len(y):, :]
# 打印各数据集的形状
x.shape, y.shape, x_test.shape
# 选择数据集中的特定列
selected=['Listed Price','Tax assessed value','Annual tax amount','Listed On','Elementary School Distance','Last Sold On',
'Zip','Total interior livable area','Last Sold Price','Lot','Year built','Bathrooms','High School Distance',
'Elementary School Score','Full bathrooms','Middle School Distance','Heating features','Bedrooms',
'Elementary School','Laundry features','Region','Middle School Score','Type',
'Total spaces','High School Score','Parking']
# 根据selected列表中的列名,重新选取x和x_test的数据
x=x[selected]
x_test=x_test[selected+['Id']]
# 显示x数据集的前5行
x.head()
这段代码首先定义了一个列表selected,包含了需要在数据集中选取的列名。接下来,通过这个列表来重新定义x和x_test的数据范围,确保它们只包含所需列。最后,使用x.head()来查看x数据集的前5行,以便确认数据选取是否正确。
2.训练
import h2o
# 初始化H2O框架
h2o.init()
# 将数据x和y合并为一个H2OFrame对象
hf = h2o.H2OFrame(pd.concat([x, y], axis=1))
# 将测试数据x_test转换为H2OFrame对象
x_test_hf = h2o.H2OFrame(x_test)
定义预测变量和响应变量
# predictors: 所有可能的预测变量,不包括'Sold Price'
# response: 响应变量,即最终需要预测的目标变量
predictors = hf.drop('Sold Price').columns
response = 'Sold Price'
from h2o.automl import H2OAutoML
# 初始化H2OAutoML对象
# stopping_metric: 指定用于提前停止训练的指标。
aml = H2OAutoML(
max_models=50, # 最多训练的模型数量
include_algos=["XGBoost"], # 包含的算法列表
max_runtime_secs=7200, # 最大运行时间(秒)
stopping_metric='RMSLE', # 早停所使用的指标
sort_metric='RMSLE' # 用来排序模型的指标
)
aml.train(x=predictors,y=response,training_frame=hf)
# 获取排行榜
lb = aml.leaderboard; lb
| model_id | rmsle | mean_residual_deviance | rmse | mse | mae |
|---|---|---|---|---|---|
| XGBoost_grid__1_AutoML_20240403_065546_model_11 | 0.0131312 | 0.0360057 | 0.189752 | 0.0360057 | 0.0910524 |
| XGBoost_grid__1_AutoML_20240403_065546_model_37 | 0.0131671 | 0.0361108 | 0.190028 | 0.0361108 | 0.0925486 |
| XGBoost_grid__1_AutoML_20240403_065546_model_6 | 0.0131991 | 0.0364161 | 0.19083 | 0.0364161 | 0.0909256 |
| XGBoost_grid__1_AutoML_20240403_065546_model_27 | 0.0132673 | 0.0367788 | 0.191778 | 0.0367788 | 0.0922308 |
| XGBoost_grid__1_AutoML_20240403_065546_model_12 | 0.0132762 | 0.036862 | 0.191995 | 0.036862 | 0.0960698 |
| XGBoost_grid__1_AutoML_20240403_065546_model_1 | 0.013322 | 0.0369063 | 0.19211 | 0.0369063 | 0.0902104 |
| XGBoost_grid__1_AutoML_20240403_065546_model_5 | 0.0133373 | 0.0371585 | 0.192765 | 0.0371585 | 0.0938252 |
| XGBoost_grid__1_AutoML_20240403_065546_model_3 | 0.0133624 | 0.0373403 | 0.193236 | 0.0373403 | 0.0933323 |
| XGBoost_grid__1_AutoML_20240403_065546_model_34 | 0.0133976 | 0.0375766 | 0.193847 | 0.0375766 | 0.0946864 |
| XGBoost_grid__1_AutoML_20240403_065546_model_43 | 0.0134077 | 0.0374676 | 0.193566 | 0.0374676 | 0.0939568 |
3.预测
aml.leader
aml对象中的leader属性,此属性用于访问或设置aml对象的领导者信息。
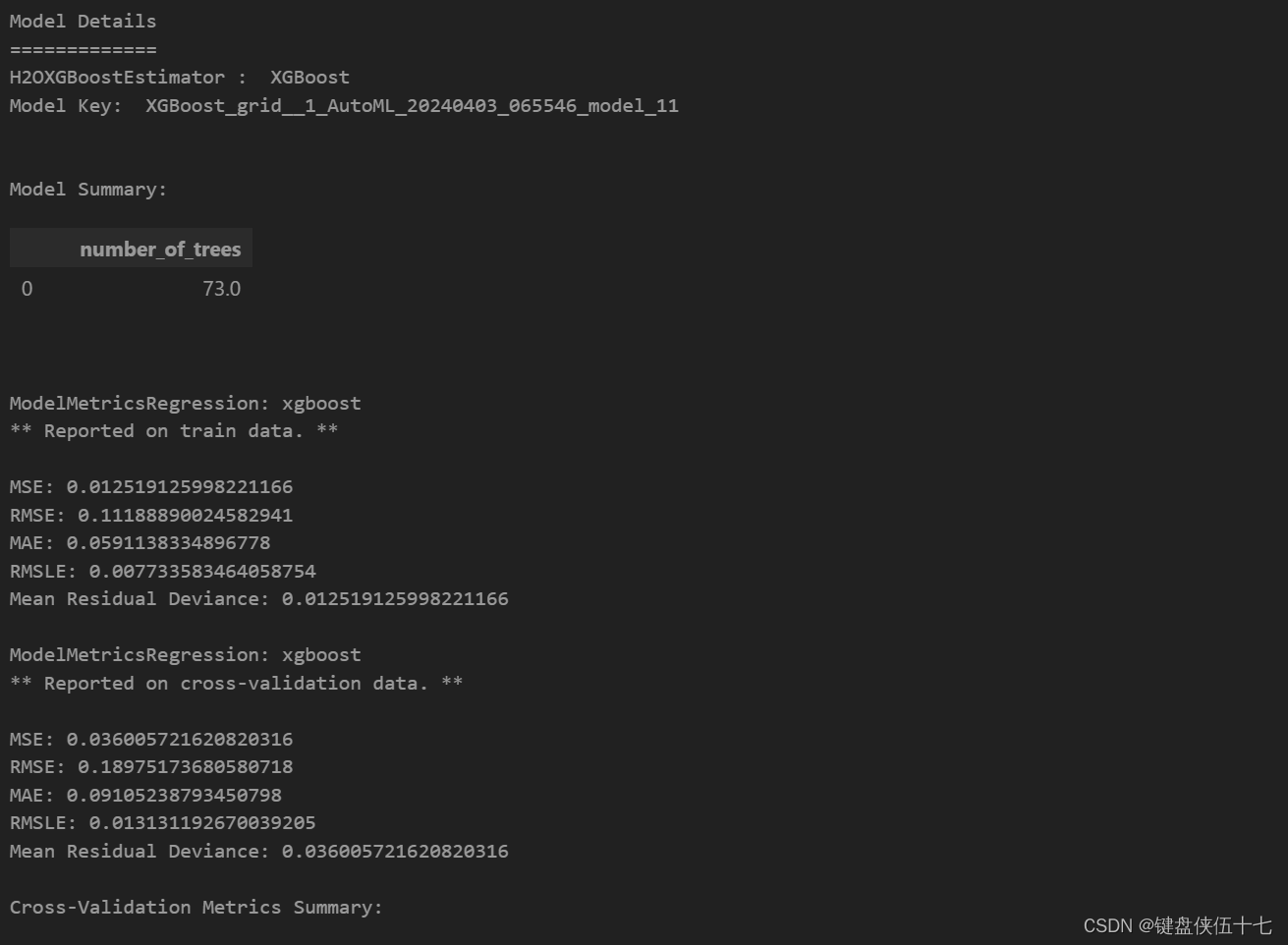
| mean | sd | cv_1_valid | cv_2_valid | cv_3_valid | cv_4_valid | cv_5_valid | ||
|---|---|---|---|---|---|---|---|---|
| 0 | mae | 0.09105241 | 0.0018464024 | 0.09151441 | 0.089231774 | 0.08987524 | 0.09066085 | 0.0939798 |
| 1 | mean_residual_deviance | 0.03600574 | 0.0023090248 | 0.03714205 | 0.033963777 | 0.0338829 | 0.035679717 | 0.039360262 |
| 2 | mse | 0.03600574 | 0.0023090248 | 0.03714205 | 0.033963777 | 0.0338829 | 0.035679717 | 0.039360262 |
| 3 | r2 | 0.94314605 | 0.0033282423 | 0.94309956 | 0.9471708 | 0.94415885 | 0.94335496 | 0.9379462 |
| 4 | residual_deviance | 0.03600574 | 0.0023090248 | 0.03714205 | 0.033963777 | 0.0338829 | 0.035679717 | 0.039360262 |
| 5 | rmse | 0.18967468 | 0.006047306 | 0.19272272 | 0.18429263 | 0.18407309 | 0.18889076 | 0.19839421 |
| 6 | rmsle | 0.013124975 | 4.5185105E-4 | 0.013394694 | 0.012686795 | 0.012756588 | 0.0130245425 | 0.013762259 |
Scoring History:
| timestamp | duration | number_of_trees | training_rmse | training_mae | training_deviance | ||
|---|---|---|---|---|---|---|---|
| 0 | 2024-04-03 07:13:02 | 14 min 52.336 sec | 0.0 | 13.262581 | 13.238679 | 175.896051 | |
| 1 | 2024-04-03 07:13:02 | 14 min 52.788 sec | 5.0 | 2.279532 | 2.248760 | 5.196266 | |
| 2 | 2024-04-03 07:13:02 | 14 min 53.141 sec | 10.0 | 0.460707 | 0.407728 | 0.212251 | |
| 3 | 2024-04-03 07:13:04 | 14 min 54.709 sec | 15.0 | 0.220807 | 0.125873 | 0.048756 | |
| 4 | 2024-04-03 07:13:07 | 14 min 57.227 sec | 20.0 | 0.186011 | 0.090261 | 0.034600 | |
| 5 | 2024-04-03 07:13:09 | 14 min 59.816 sec | 25.0 | 0.170262 | 0.080979 | 0.028989 | |
| 6 | 2024-04-03 07:13:12 | 15 min 2.250 sec | 30.0 | 0.159524 | 0.076530 | 0.025448 | |
| 7 | 2024-04-03 07:13:14 | 15 min 4.617 sec | 35.0 | 0.151118 | 0.073607 | 0.022837 | |
| 8 | 2024-04-03 07:13:17 | 15 min 7.209 sec | 40.0 | 0.143352 | 0.070679 | 0.020550 | |
| 9 | 2024-04-03 07:13:19 | 15 min 9.548 sec | 45.0 | 0.137237 | 0.068577 | 0.018834 | |
| 10 | 2024-04-03 07:13:21 | 15 min 11.999 sec | 50.0 | 0.132135 | 0.066895 | 0.017460 | |
| 11 | 2024-04-03 07:13:24 | 15 min 14.550 sec | 55.0 | 0.126746 | 0.064857 | 0.016064 | |
| 12 | 2024-04-03 07:13:27 | 15 min 17.267 sec | 60.0 | 0.121976 | 0.063122 | 0.014878 | |
| 13 | 2024-04-03 07:13:29 | 15 min 20.004 sec | 65.0 | 0.118179 | 0.061610 | 0.013966 | |
| 14 | 2024-04-03 07:13:32 | 15 min 22.702 sec | 70.0 | 0.114020 | 0.059885 | 0.013001 | |
| 15 | 2024-04-03 07:13:34 | 15 min 24.543 sec | 73.0 | 0.111889 | 0.059114 | 0.012519 |
Variable Importances:
| variable | relative_importance | scaled_importance | percentage | |
|---|---|---|---|---|
| 0 | Listed Price | 15757.291016 | 1.000000 | 0.868374 |
| 1 | Listed On | 426.460724 | 0.027064 | 0.023502 |
| 2 | Annual tax amount | 231.994064 | 0.014723 | 0.012785 |
| 3 | Zip | 210.913757 | 0.013385 | 0.011623 |
| 4 | Tax assessed value | 187.153488 | 0.011877 | 0.010314 |
| 5 | Last Sold On | 168.867004 | 0.010717 | 0.009306 |
| 6 | Lot | 160.065033 | 0.010158 | 0.008821 |
| 7 | Last Sold Price | 145.930344 | 0.009261 | 0.008042 |
| 8 | Total interior livable area | 130.409454 | 0.008276 | 0.007187 |
| 9 | Year built | 103.833466 | 0.006590 | 0.005722 |
| 10 | Elementary School Distance | 66.311447 | 0.004208 | 0.003654 |
| 11 | High School Distance | 66.152893 | 0.004198 | 0.003646 |
| 12 | Elementary School Score | 49.986599 | 0.003172 | 0.002755 |
| 13 | Middle School Distance | 47.662540 | 0.003025 | 0.002627 |
| 14 | Full bathrooms | 38.818577 | 0.002464 | 0.002139 |
| 15 | Heating features.Other | 36.017975 | 0.002286 | 0.001985 |
| 16 | High School Score | 32.651108 | 0.002072 | 0.001799 |
| 17 | Bedrooms | 29.388639 | 0.001865 | 0.001620 |
| 18 | Total spaces | 26.385807 | 0.001675 | 0.001454 |
| 19 | Bathrooms | 22.393549 | 0.001421 | 0.001234 |
See the whole table with table.as_data_frame()
发现过拟合现象比较严重,这里考虑使用前k个模型的输出取均值进行整合
Reported on train data.
RMSLE: 0.00745891154333034
Reported on cross-validation data.
RMSLE: 0.013097170958722777
根据 leaderboard 中的前k个模型的预测结果,计算它们的平均预测值作为最终预测结果。
# 从指定路径读取提交结果的CSV文件
submission_results = pd.read_csv("/kaggle/input/california-house-prices/sample_submission.csv")
def top_k_avg_predict(k,leaderboard):
lb=leaderboard.as_data_frame() # 将 leaderboard 转换为 Pandas 数据帧
ans=submission_results.iloc[:, 1] # 初始化答案为提交结果数据帧中的第2列
for i in range(k):
model=lb.loc[i]['model_id'] # 获取当前排名的模型ID
pred=h2o.get_model(model).predict(x_test_hf) # 使用该模型对测试集进行预测
pred=pred.as_data_frame() # 将预测结果转换为 Pandas 数据帧
ans+=np.expm1(pred['predict'])/k # 将当前模型的预测结果加权平均到答案中
return ans
# 使用前8个模型的平均预测值更新提交结果数据帧的第2列
submission_results.iloc[:, 1]=top_k_avg_predict(8,aml.leaderboard)
# 显示更新后的前5行数据
submission_results.head()
# 将更新后的提交结果数据帧保存为CSV文件
submission_results.to_csv('submission.csv', index=False)
submission_results.head()
| Id | Sold Price | |
|---|---|---|
| 0 | 47439 | 8.252913e+05 |
| 1 | 47440 | 6.162160e+05 |
| 2 | 47441 | 8.452799e+05 |
| 3 | 47442 | 8.266464e+05 |
| 4 | 47443 | 1.130490e+06 |
优化建议:
更精细的离群点检测:
可尝试采用更为复杂或自适应的离群点检测算法(如Isolation Forest、Local Outlier Factor等),替代当前基于可视化判断的离群点剔除方式,提高离群点识别的准确性和鲁棒性。
深度特征工程:
进一步探索高级特征工程技术,如交互项构造、特征分桶、地理编码等,以挖掘潜在的非线性关系和地域效应,增强模型捕捉复杂模式的能力。
超参数调优:
虽然已限制AutoML只使用XGBoost算法,但对其内部超参数未做细致调整。可通过网格搜索、随机搜索或贝叶斯优化等方法,对选定算法的超参数进行精细化调优,有望进一步提升单个模型性能。
集成方法改进:
目前采用的是简单平均法进行模型集成,未来可尝试其他更先进的集成策略,如加权平均、Stacking、Bagging、Boosting等,以期获得更好的集成效果。
交叉验证与模型选择:
在模型训练阶段,可以结合交叉验证策略,评估不同模型在多个折叠上的平均性能,从而更加稳健地选择集成模型中的个体模型,避免单一验证集可能导致的过拟合风险。