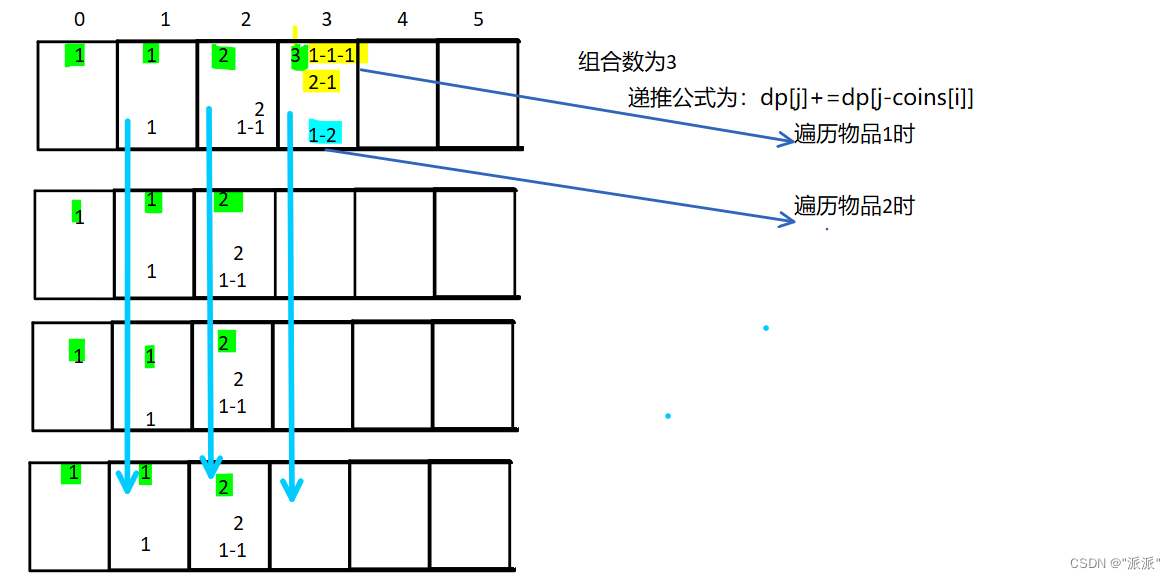
数据源
数据源作为机器学习的数据输入,以供给Spark进行机器学习,Spark技术框架除了支持Parquet、CSV、JSON以及JDBC这些常用的数据源,还提供一些特殊数据源的支持,例如,图像或者LIBSVM。
Parquet数据源
该数据源是apache parquet技术框架提供的数据存储格式,是面向列式存储结构,其设计的目标是提供高效以及高性能的数据存储、数据获取、数据压缩以及数据编码。
图像数据源
图像数据源是用于从目录中加载图像,Spark技术框架使用ImageIO的类库加载压缩的图像(jpeg、png等等格式)进行合法的展示,其加载的数据框架(DataFrame)的数据结构类型(StructType)对应的列是image,该图像数据结构存储图像数据,其包含的图像属性如下所示:
|

如上所示,是Spark的技术框架对应的ImageDataSource类从指定文件夹中加载图像列表,形成一个DataFrame类型数据集合。
LIBSVM数据源
提供加载libsvm类型数据源的支持,该类型数据源的数据框架(DataFrame)包括两列,label列包括double类型的标签列表,features列包括特征集合,其数据框架描述如下所示:
|

如上所示,从指定文件夹中加载libsvm的数据源,并显示数据框架的列表,其中,LIBSVM是支持向量机的类库以及对应的数据集,应用于分类以及回归的机器学习领域。
(未完待续)