一、从官网下载最新的yolov5代码
二、新建VOCData文件夹
三、VOCData文件夹结构
新建Annotations文件夹,存放标签
简单的xml文件,应该长这样

复杂的xml文件,应该长这个样子

新建images文件夹,存放图片数据
注意:需要观察自己的图片文件的后缀名,后面需要用到,不然可能出现程序找不到图片的情况
3、新建split_train_val.py,用来划分训练集与验证集
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
#xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path')
#数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 0.7 # 训练集和验证集所占比例。 这里没有划分测试集
train_percent = 0.5 # 训练集所占比例,可自己进行调整
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行之后,会发现VOCData文件夹里面多了ImageSets文件夹
里面包括四个txt文件
txt文件存储了图片的序号
4、新建xml_to_yolo.py,用于将xml格式的标签转化为yolo格式的标签
对于简单的xml文件,用下列代码
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["ship"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('D:/Project/yolov5Project/yolov5/VOCData/Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('D:/Project/yolov5Project/yolov5/VOCData/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
# difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('D:/Project/yolov5Project/yolov5/VOCData/labels/'):
os.makedirs('D:/Project/yolov5Project/yolov5/VOCData/labels/')
image_ids = open('D:/Project/yolov5Project/yolov5/VOCData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('D:/Project/yolov5Project/yolov5/VOCData/dataSet_path/'):
os.makedirs('D:/Project/yolov5Project/yolov5/VOCData/dataSet_path/')
list_file = open('dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
list_file.write('D:/Project/yolov5Project/yolov5/VOCData/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
对于复杂的xml文件,用下列代码。
该程序的功能:将Class_ID属于aircraft_carrier列表的物体标记为类别0,将Class_ID属于warcraft列表的物体标记为类别1,将Class_ID属于aircraft_carrier列表的物体标记为类别2,将Class_ID属于merchant_ship列表的物体标记为类别3。然后转化为yolo格式标签。
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
Class_1_num = 0
Class_2_num = 0
Class_3_num = 0
Class_4_num = 0
sets = ['train','test','val']
classes = ["ship"] # 改成自己的类别
abs_path = os.getcwd()
print(abs_path)
aircraft_carrier = [100000005,100000006,100000012,100000013,100000031,100000032,100000033]
warcraft = [100000007,100000008,100000009,100000010,100000011,100000014,100000015,100000016,100000017,100000019,100000003,100000029]
merchant_ship = [100000018,100000022,100000024,100000018,100000025,100000026,100000030]
Submarine = [100000027]
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
global Class_1_num,Class_2_num,Class_3_num,Class_4_num
in_file = open('./Annotations/%s.xml' % (image_id), encoding='UTF-8')
out_file = open('./labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
HRSC_Objects = root.find('HRSC_Objects')
HRSC_Object = HRSC_Objects.find('HRSC_Object')
if HRSC_Object!=None:
for HRSC_Object in HRSC_Objects.iter('HRSC_Object'):
Class_ID = int(HRSC_Object.find('Class_ID').text)
if Class_ID in aircraft_carrier or Class_ID in warcraft or Class_ID in merchant_ship or Class_ID in Submarine:
w = int(root.find('Img_SizeWidth').text)
h = int(root.find('Img_SizeHeight').text)
b = (float(HRSC_Object.find('box_xmin').text),float(HRSC_Object.find('box_xmax').text),float(HRSC_Object.find('box_ymin').text),float(HRSC_Object.find('box_ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
if Class_ID in aircraft_carrier:
Class_1_num = Class_1_num+1
Class = 0
if Class_ID in warcraft:
Class_2_num = Class_2_num+1
Class = 1
if Class_ID in merchant_ship:
Class_3_num = Class_3_num+1
Class = 2
if Class_ID in Submarine:
Class_4_num = Class_4_num+1
Class = 3
out_file.write(str(Class) + " " + " ".join([str(a) for a in bb]) + '\n')
else:
print('do not caculate'+str(Class_ID))
continue
wd = getcwd()
for image_set in sets:
if not os.path.exists('./labels/'):
os.makedirs('./labels/')
image_ids = open('./ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
if not os.path.exists('./dataSet_path/'):
os.makedirs('./dataSet_path/')
list_file = open('./dataSet_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image_id in image_ids:
print('目前的图片id为:'+image_id)
list_file.write('D:/Project/yolov5Project/yolov5_three_classifications/VOCData/images/%s.bmp\n' % (image_id))
convert_annotation(image_id)
list_file.close()
print(Class_1_num)
print(Class_2_num)
print(Class_3_num)
print(Class_4_num)
运行后,会发现多了两个文件
dataSet_path文件中存储了训练集、测试集、验证集的绝对路径
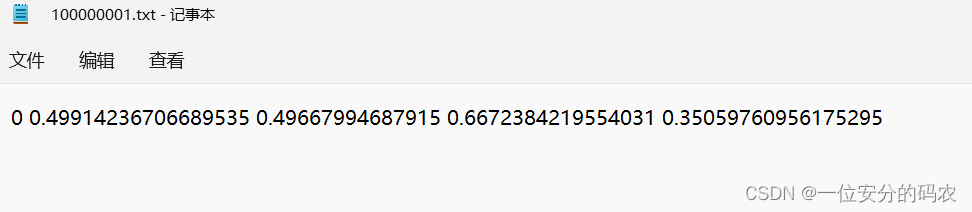
labels存储了yolo格式的标签
5、进入data文件夹,新建mycov.yaml
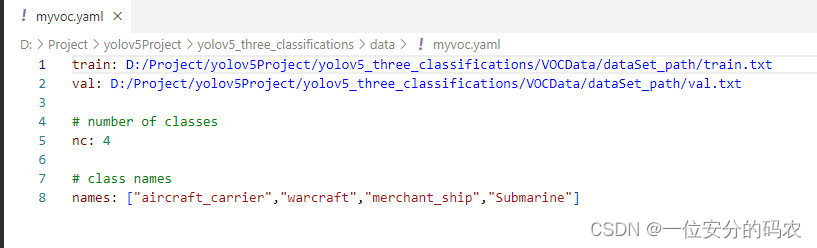
myvoc.yaml的内容,其中,train与val为训练集与验证集列表的绝对路径
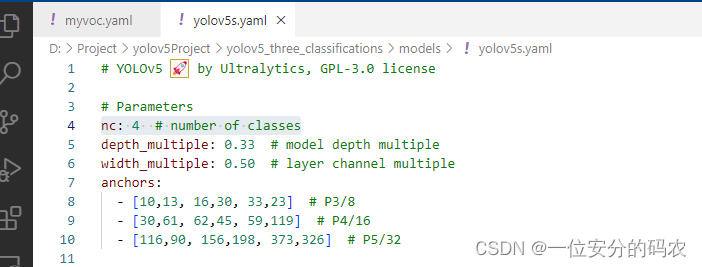
修改权重文件yolov5s.yaml
把类别改为我们设置的类别数量
7、开始训练
(1)训练
python train.py --weights weights/yolov5s.pt --cfg models/yolov5s.yaml --data data/myvoc.yaml --epoch 100 --batch-size 16 --img 640 --device 0
2)训练过程可视化
tensorboard --logdir=./runs(3)测试训练出的网络模型
python detect.py --source data/images/000026.jpg --weights runs/train/exp10/weights/best.pt
1
一些常用命令:
(1)指定下载镜像源
pip install onnx -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
1
(2)制作数据集教程
(3)mAP说明