基于wordcloud、matplotlib等对某东评论数据情感分析
文章目录
- 基于wordcloud、matplotlib等对某东评论数据情感分析
- 1 数据导入及预处理
- 1.1 数据导入
- 1.2 数据描述
- 1.3 数据预处理
- 2 情感分析
- 2.1 情感分析
- 2.2 情感分直方图
- 2.3 词云图
- 2.4 关键词提取
- 3 积极评论与消极评论
- 3.1 积极评论与消极评论占比
- 3.2 消极评论分析
1 数据导入及预处理
1.1 数据导入
import pandas as pd
data = pd.read_csv('./京东评论数据.csv')
data.head(2)
1.2 数据描述
data.describe()
1.3 数据预处理
#取出sku_id','content'字段
data1 = data[['sku_id','content']]
data1.head(10)
2 情感分析
2.1 情感分析
#安装snownlp包
!pip install snownlp -i https://pypi.tuna.tsinghua.edu.cn/simple
from snownlp import SnowNLP
data1['emotion'] = data1['content'].apply(lambda x:SnowNLP(x).sentiments)
data1.head(10)

data1.describe()
-
sku_id emotion 3637.000 3637.000 7.936312e+09 0.746161 1.165137e+10 0.354481 1.592994e+06 0.000000 5.920651e+06 0.562240 7.651903e+06 0.962449 2.034912e+10 0.999123 3.032369e+10 1.000000 -
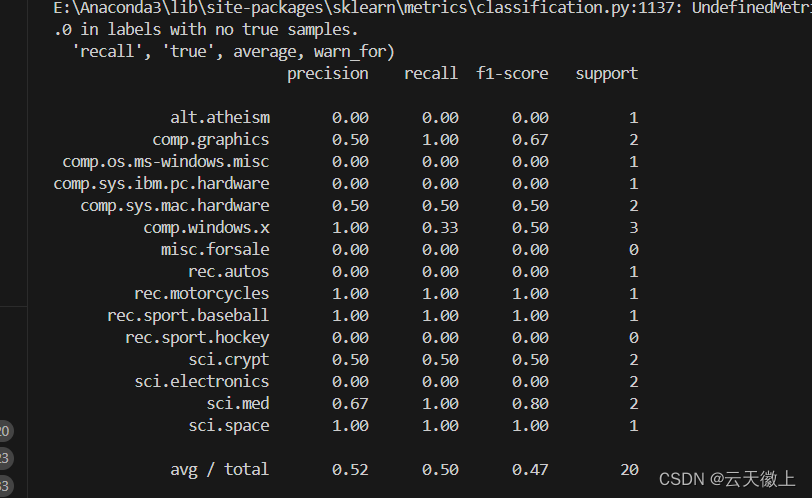
emotion平均值为0.74,中位数为0.96,25%分位数为0.56,可见不到25%的数据造成了整体均值的较大下移。
2.2 情感分直方图
#情感分直方图
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
bins=np.arange(0,1.1,0.1)
plt.hist(data1['emotion'],bins,color='#4F94CD',alpha=0.9)
plt.xlim(0,1)
plt.xlabel('情感分')
plt.ylabel('数量')
plt.title('情感分直方图')
plt.show()

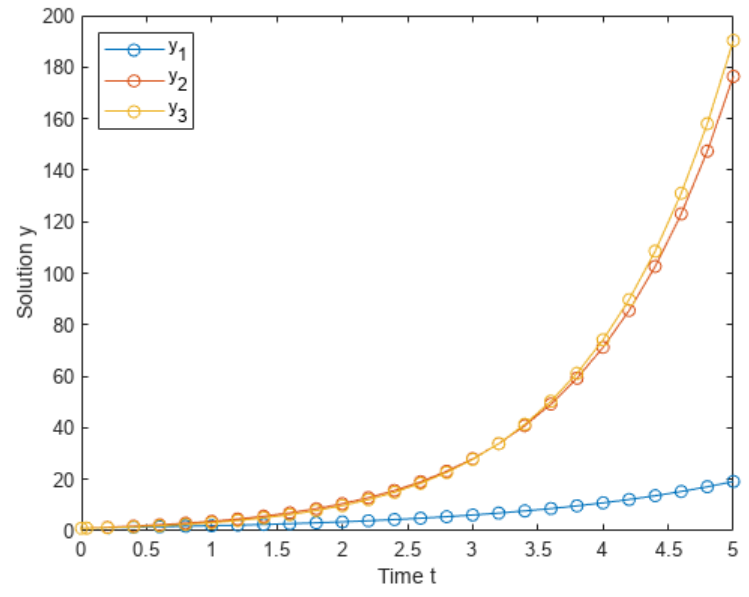
- 由直方图可见,评论内容两级分化较为严重;
- 3637条评论中有约2200条评论情感分在[0.9,1]区间内;同时,有约500条评论情感分在[0,0.1]区间内。
2.3 词云图
from wordcloud import WordCloud
import jieba
w = WordCloud()
text = ''
for s in data['content']:
text += s
data_cut = ' '.join(jieba.lcut(text))
w = WordCloud(font_path="./SimHei.ttf",
stopwords=['的','我','了','是','和','都','就','用'], # 去掉停用词
#max_words=100,
width=2000,
height=1200).generate(data_cut)
# 保存词云
w.to_file('词云图.png')
# 显示词云文件
plt.imshow(w)
plt.axis("off")
plt.show()

2.4 关键词提取
#关键词top10
from jieba import analyse
key_words = jieba.analyse.extract_tags(sentence=text, topK=10, withWeight=True, allowPOS=())
key_words
| 关键词 | 权重 |
|---|---|
| 手机 | 0.209 |
| 不错 | 0.105 |
| 京东 | 0.094 |
| 屏幕 | 0.055 |
| 华为 | 0.051 |
| 小米 | 0.047 |
| 拍照 | 0.046 |
| 非常 | 0.044 |
| 手感 | 0.043 |
| 感觉 | 0.040 |
- 以上关键词显示,消费者比较在意手机的“屏幕”“拍照”“手感”等特性,“华为”“小米”是出现频次最高的两个手机品牌。
3 积极评论与消极评论
3.1 积极评论与消极评论占比
#计算积极评论与消极评论各自的数目
pos = 0
neg = 0
for i in data1['emotion']:
if i >= 0.5:
pos += 1
else:
neg += 1
print('积极评论,消极评论数目分别为:',pos,neg)
积极评论,消极评论数目分别为: 2791 846
# 积极评论占比
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
pie_labels='postive','negative'
plt.pie([pos,neg],labels=pie_labels,autopct='%1.1f%%',shadow=True)
plt.show()

3.2 消极评论分析
#获取消极评论数据
data2=data1[data1['emotion']<0.5]
data2.head(10)
#消极评论词云图
text2 = ''
for s in data2['content']:
text2 += s
data_cut2 = ' '.join(jieba.lcut(text2))
w.generate(data_cut2)
image = w.to_file('消极评论词云.png')
# 显示词云文件
plt.imshow(w)
plt.axis("off")
plt.show()

#消极评论关键词top10
key_words = jieba.analyse.extract_tags(sentence=text2, topK=10, withWeight=True, allowPOS=())
key_words
[('手机', 0.19237764869875004),
('京东', 0.08930157104159077),
('未填写', 0.08087213276666493),
('评价', 0.06602737843353074),
('屏幕', 0.05285184715212572),
('快递', 0.050103021155518554),
('用户', 0.05005720904465942),
('充电', 0.04605195695403029),
('收到', 0.038929704221495554),
('没有', 0.03758001077768642)]
- 消极评论关键词显示,“屏幕”“快递”“充电”是造成用户体验不佳的几个重要因素;屏幕和充电问题有可能是手机不良品率过高或快递压迫;
- 因此平台应注重提高手机品控,降低不良品率;另外应设法提升发货,配送,派件的效率和质量。
本文使用jieba,snownlp,wordcloud,matplotlib等模块对文本数据进行了简要的情感分析及可视化,旨在了解用户使用体验,以此对平台运营提出优化建议。