一、引言
1.1 K-近邻算法(KNN)的基本概念
K-近邻算法(K-Nearest Neighbors,简称KNN)是一种基于实例的学习算法,它利用训练数据集中与待分类样本最相似的K个样本的类别来判断待分类样本所属的类别。KNN算法的核心思想是:如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。
KNN算法的实现相对简单直观,它不需要建立复杂的模型或进行参数估计。在分类时,算法只需计算待分类样本与训练集中每个样本之间的距离(通常使用欧氏距离或曼哈顿距离等),然后选取距离最小的K个样本,根据这些样本的类别进行投票,将待分类样本归类到票数最多的类别中。
1.2 KNN算法在机器学习中的重要性
KNN算法在机器学习领域具有重要地位,主要体现在以下几个方面:
-
KNN算法是一种简单易懂且易于实现的算法。它的工作原理直观明了,不需要复杂的数学知识和高级编程技能,使得初学者也能够快速上手。
-
KNN算法具有很好的分类性能。由于它基于实例进行学习,能够充分利用训练数据中的信息,因此在很多数据集上都能取得不错的分类效果。
-
KNN算法对数据的预处理要求相对较低。它不需要对数据进行复杂的特征提取或降维操作,只需计算样本之间的距离即可进行分类。这使得KNN算法在处理高维数据或复杂数据集时具有一定的优势。
-
KNN算法具有很强的通用性。它可以应用于各种类型的数据和场景,包括文本、图像、声音等不同类型的数据,以及分类、回归等不同类型的问题。这使得KNN算法在实际应用中具有广泛的适用性。
二、KNN算法原理
2.1 KNN算法工作原理概述
KNN算法的工作原理基于这样一个假设:相似的对象在特征空间中距离相近。具体来说,对于待分类的样本,KNN算法首先计算它与训练集中每个样本之间的距离。然后,算法选取距离最小的K个样本,这些样本被称为“邻居”。最后,根据这些邻居的类别标签,通过投票或加权平均等方式,确定待分类样本的类别。
KNN算法的核心在于距离度量,它决定了样本之间的相似度。通过选择合适的距离度量方法,KNN算法能够准确地找出与待分类样本最相似的邻居,从而进行准确的分类。
2.2 距离度量方法(如欧氏距离、曼哈顿距离等)
在KNN算法中,距离度量方法的选择至关重要。常用的距离度量方法包括欧氏距离和曼哈顿距离。
欧氏距离是最常用的距离度量方法之一,它衡量的是多维空间中两点之间的直线距离。对于二维空间中的两个点A(x1, y1)和B(x2, y2),它们的欧氏距离可以通过以下公式计算:
d ( A , B ) = [ ( x 1 − x 2 ) 2 + ( y 1 − y 2 ) 2 ] d(A, B) = \sqrt{[(x1 - x2)² + (y1 - y2)²]} d(A,B)=[(x1−x2)2+(y1−y2)2]
曼哈顿距离也称为城市街区距离,它衡量的是两点在标准坐标系上的绝对轴距总和。在二维空间中,曼哈顿距离可以通过以下公式计算:
d
(
A
,
B
)
=
∣
x
1
−
x
2
∣
+
∣
y
1
−
y
2
∣
d(A, B) = |x1 - x2| + |y1 - y2|
d(A,B)=∣x1−x2∣+∣y1−y2∣
除了欧氏距离和曼哈顿距离,还有其他一些距离度量方法,如切比雪夫距离、闵可夫斯基距离等。这些距离度量方法在不同的应用场景下可能具有不同的优势和适用性。
2.3 如何确定K值
在KNN算法中,K值的选择对分类结果具有重要影响。K值太小可能导致过拟合,即算法对训练数据的噪声过于敏感;而K值太大则可能导致欠拟合,即算法忽略了训练数据中的有用信息。
确定K值的常用方法包括交叉验证和网格搜索。交叉验证是一种评估模型性能的方法,它将数据集划分为多个子集,通过多次训练和测试来选择最优的K值。网格搜索则是一种参数调优方法,它通过在一定的参数范围内进行穷举搜索,找到使得模型性能最优的K值。
在实际应用中,可以根据问题的具体需求和数据集的特性来选择合适的K值。通常,可以通过实验和比较不同K值下的分类性能来确定最优的K值。
2.4 分类与回归的区别
KNN算法既可以用于分类问题,也可以用于回归问题。分类问题的目标是预测离散型变量,即样本的类别标签;而回归问题的目标是预测连续型变量,即样本的具体数值。
2.4.1 KNN分类
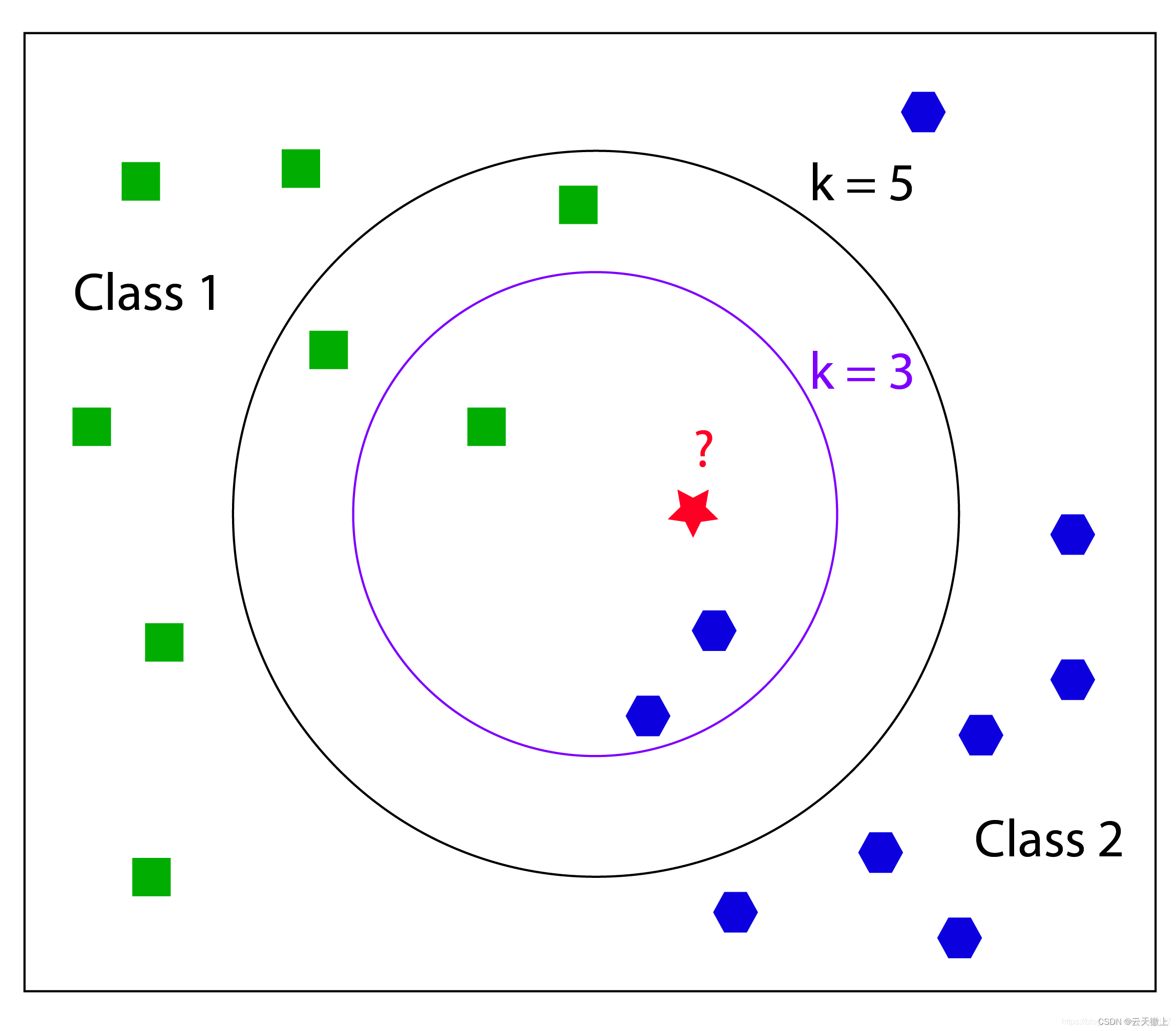
如上图所示,图中的正方形和五边形是打好了label的数据,分别代表不同的标签,那个绿色的圆形是我们待分类的数据。
如果选K=3,那么离绿色点最近K个点中有2个五边形和1个正方形,这3个点投票,五边形的比例占2/3,于是这个待分类点属于五边形类别。
如果选K=5,那么离绿色点最近K个点中有2个五边形形和3个正方形,这5个点投票,绿色的比例占3/5,于是这个待分类点属于正方形类别。
2.4.2 KNN回归
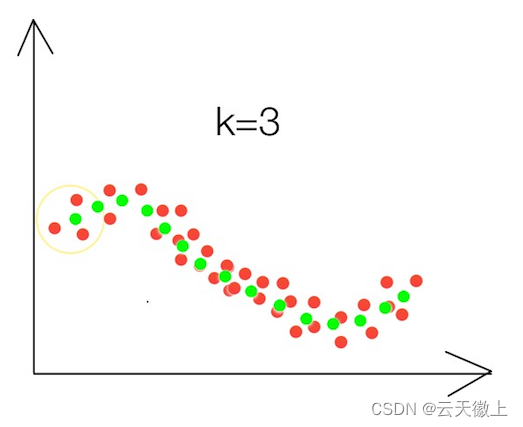
要预测的点的值通过求与它距离最近的K个点的值的平均值得到,这里的“距离最近”可以是欧氏距离,也可以是其他距离,具体的效果依数据而定,思路一样。如下图,x轴是一个特征,y是该特征得到的值,红色点是已知点,要预测第一个点的位置,则计算离它最近的三个点(黄色线框里的三个红点)的平均值,得出第一个绿色点,依次类推,就得到了绿色的线,可以看出,这样预测的值明显比直线准。
在分类问题中,KNN算法通过投票机制来确定待分类样本的类别。具体来说,算法计算待分类样本与邻居之间的距离,并根据邻居的类别标签进行投票,将待分类样本归类到票数最多的类别中。
在回归问题中,KNN算法则通过计算邻居的加权平均值来预测待分类样本的具体数值。具体来说,算法根据待分类样本与邻居之间的距离赋予不同的权重,然后将邻居的数值进行加权平均,得到待分类样本的预测值。
需要注意的是,KNN算法在分类问题中的应用更为广泛和常见,而在回归问题中的应用相对较少。这是因为回归问题通常需要更复杂的模型来处理连续型变量的预测问题。然而,在某些特定场景下,KNN算法仍然可以用于回归问题,并取得较好的预测效果。
三、KNN算法的优点与局限性
3.1 KNN算法的优点
KNN算法具有多个显著优点,使得它在机器学习领域得到广泛应用。
-
KNN算法简单易懂。它的工作原理直观明了,基于实例进行学习,无需建立复杂的模型或进行参数估计。这使得初学者能够轻松理解并应用该算法,同时也便于专业人员快速实现和调试。
-
KNN算法无需参数估计。与传统的参数化模型相比,KNN算法不需要进行复杂的参数训练和优化过程。它直接利用训练数据集中的实例进行分类或回归,从而简化了算法的实现和调试过程。
-
KNN算法适合多分类问题。无论是二分类还是多分类问题,KNN算法都能有效地处理。它通过投票机制确定待分类样本的类别,能够处理具有多个类别的数据集,这使得KNN算法在实际应用中具有广泛的适用性。
3.2 KNN算法的局限性
尽管KNN算法具有诸多优点,但也存在一些局限性。
-
KNN算法的计算量较大,尤其在处理大数据集时。由于KNN算法需要计算待分类样本与训练集中每个样本之间的距离,当数据集规模较大时,计算复杂度会急剧增加,导致算法运行时间较长。因此,在处理大规模数据集时,KNN算法可能不是最佳选择。
-
KNN算法对特征值敏感。算法的性能很大程度上取决于特征值的准确性和完整性。如果特征值存在噪声、缺失或异常值,可能会对KNN算法的分类结果产生负面影响。因此,在应用KNN算法之前,需要对数据进行适当的预处理和特征工程,以提高算法的准确性和稳定性。
-
KNN算法需要选择合适的K值和距离度量方法。K值的选择对算法性能具有重要影响,过小的K值可能导致过拟合,而过大的K值可能导致欠拟合。此外,不同的距离度量方法可能会对分类结果产生不同的影响。因此,在实际应用中,需要通过实验和比较不同K值和距离度量方法下的分类性能,选择最优的参数设置。
四、KNN算法的应用场景
KNN算法在机器学习中具有广泛的应用,其基于实例的学习机制使得它适用于多种类型的数据和问题。下面将详细介绍KNN算法在文本分类、图像识别、推荐系统、手势识别以及金融风险评估等场景中的应用。
4.1 文本分类
文本分类是KNN算法的一个重要应用领域。在文本分类任务中,KNN算法可以将文本数据表示为向量形式,并利用训练数据中的文本向量来分类新的文本数据。例如,在新闻分类中,KNN算法可以根据新闻内容的相似性将其归类到不同的类别(如政治、经济、体育等)。通过选择合适的特征提取方法和距离度量方式,KNN算法能够有效地处理文本数据中的高维性和稀疏性问题,实现准确的文本分类。
4.2 图像识别
在图像识别领域,KNN算法同样具有广泛的应用。图像数据可以通过提取特征(如颜色、纹理、形状等)转化为向量形式,然后利用KNN算法进行分类或识别。例如,在人脸识别系统中,KNN算法可以根据人脸图像的特征向量来识别不同的人脸。此外,KNN算法还可以应用于手写数字识别、物体检测等任务中。通过优化特征提取方法和调整K值等参数,KNN算法可以在图像识别任务中取得较好的性能。
4.3 推荐系统
推荐系统是KNN算法另一个重要的应用领域。在推荐系统中,KNN算法可以根据用户的历史行为或偏好数据来预测用户可能感兴趣的内容或产品。例如,在电商网站的推荐系统中,KNN算法可以根据用户的购买历史和浏览行为来推荐相似的商品或服务。通过计算用户之间的相似度,KNN算法可以找到与目标用户相似的其他用户,并基于这些相似用户的行为来生成推荐。这种方法简单有效,能够为用户提供个性化的推荐体验。
4.4 手势识别
手势识别是计算机视觉领域的一个重要任务,KNN算法也可以在此领域发挥作用。在手势识别中,KNN算法可以通过提取手势图像的特征向量来识别不同的手势动作。例如,在智能交互系统中,KNN算法可以根据用户的手势动作来执行相应的命令或操作。通过选择合适的特征提取方法和优化算法参数,KNN算法可以实现对手势的准确识别,提高人机交互的便捷性和自然性。
4.5 金融风险评估
在金融领域,KNN算法可用于风险评估和信用评分等任务。通过对历史数据的学习,KNN算法可以预测借款人的违约风险或客户的信用等级。例如,在贷款审批过程中,KNN算法可以根据借款人的财务状况、信用记录等特征来评估其还款能力,从而帮助金融机构做出更明智的决策。此外,KNN算法还可以应用于股票价格预测、欺诈检测等金融场景中,为金融机构提供有效的风险管理和决策支持。
五、KNN算法的实现与优化
KNN算法的实现涉及多个关键步骤,包括数据预处理、特征缩放、缺失值处理、降维技术、K值的选择策略以及性能优化方法等。下面将对这些内容进行详细的描述。
- 数据预处理
数据预处理是KNN算法实现中至关重要的一步。它涉及对原始数据的清洗、转换和标准化,以消除噪声、异常值和不一致性,并使得数据更适合算法的处理。数据预处理可以提高算法的准确性和稳定性,减少过拟合的风险。
- 特征缩放
特征缩放是将不同特征的数据范围调整到相同或相近的尺度上,以确保它们在算法中具有相同的权重。常用的特征缩放方法包括最小-最大缩放和标准化。最小-最大缩放将特征值缩放到一个指定的范围(如0到1),而标准化则是将特征值转换为均值为0、标准差为1的分布。特征缩放可以提高KNN算法的性能,因为距离度量方法对数据的尺度敏感。
- 缺失值处理
在实际应用中,数据集中常常存在缺失值。对于KNN算法来说,缺失值可能导致距离计算不准确,从而影响分类结果。因此,需要对缺失值进行处理。常见的缺失值处理方法包括填充法(如均值填充、中位数填充等)和删除法(删除含有缺失值的样本)。选择合适的方法取决于缺失值的数量和分布,以及数据集的特性。
- 降维技术
降维技术可以帮助减少数据的维度,简化模型的复杂性,并提高计算效率。对于KNN算法来说,降维技术尤为重要,因为高维数据会导致计算复杂度急剧增加。常用的降维技术包括主成分分析(PCA)和线性判别分析(LDA)。这些技术可以通过提取数据中的主要特征或变换数据空间来降低维度,同时保留对分类任务有用的信息。
- K值的选择策略
K值是KNN算法中的一个关键参数,它决定了算法中考虑的邻居数量。选择合适的K值对于算法的性能至关重要。常用的K值选择策略包括交叉验证和网格搜索。交叉验证通过将数据集划分为多个子集来评估不同K值下的模型性能,从而选择最优的K值。网格搜索则是一种参数调优方法,它通过在一定范围内穷举搜索不同的K值组合,找到使得模型性能最优的K值。
- 性能优化方法
为了进一步提高KNN算法的性能,可以采用一些优化方法。其中,使用KD树或球树加速搜索是一种常见的优化手段。KD树和球树是空间划分树结构,它们能够将数据空间划分为多个区域,并在搜索过程中快速排除不相关的区域,从而加速邻居的查找过程。此外,还可以考虑调整权重来提高算法对不同特征的重视程度,进一步优化分类结果。
六、案例分析:KNN算法在文本分类中的应用
在本节中,我们将通过一个具体的案例——文本分类,来展示KNN算法在机器学习中的应用。我们将介绍所使用的数据集、算法实现步骤,并对实验结果进行分析。
6.1 数据集介绍
为了演示KNN算法在文本分类中的应用,我们选择了一个公开的文本分类数据集,如20 Newsgroups数据集。该数据集包含了大约20,000篇新闻文章,分为20个不同的类别。每篇文章都经过预处理,去除了停用词、标点符号等,并转换为词频向量形式。数据集被划分为训练集和测试集,以便我们评估模型的性能。
6.2 算法实现步骤
- 数据加载与预处理
首先,我们需要加载数据集,并进行必要的预处理。这包括读取文本文件、分词、去除停用词、构建词汇表等。然后,我们将文本数据转换为数值型向量,通常使用词袋模型或TF-IDF等方法来表示文本。
- 特征缩放
由于文本数据通常具有高维性和稀疏性,我们需要对特征进行缩放,以确保KNN算法中的距离度量方法能够正确工作。常用的特征缩放方法包括L2归一化,它将每个样本的特征向量缩放到单位长度。
-
K值选择
通过交叉验证或网格搜索等方法,我们选择一个合适的K值。这个值将决定在分类过程中考虑的邻居数量。对于文本分类任务,K值的选择通常需要考虑到文本数据的特性和分类任务的复杂性。 -
模型训练与预测
使用训练集数据,我们训练KNN分类器。在训练过程中,算法会存储训练样本及其标签。然后,我们使用训练好的模型对测试集进行预测,并计算分类准确率、精确率、召回率等指标来评估模型的性能。
- 实验结果与分析
在实验中,我们使用了不同的K值进行模型训练,并记录了相应的性能指标。通过对比不同K值下的实验结果,我们可以发现K值的选择对模型性能具有显著影响。当K值较小时,模型可能过于敏感于噪声数据,导致过拟合;而当K值较大时,模型可能过于平滑,忽略了数据的局部结构,导致欠拟合。因此,选择合适的K值是至关重要的。
以下是KNN算法在文本分类中的Python代码示例,我们将使用scikit-learn库中的KNeighborsClassifier来实现KNN算法,并使用TF-IDF(词频-逆文档频率)作为文本特征提取方法。我们将使用20 Newsgroups数据集作为例子。
首先,确保你已经安装了必要的库,如scikit-learn和nltk。如果没有安装,你可以使用以下命令安装:
pip install scikit-learn nltk
然后,我们可以编写代码:
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
from sklearn.datasets import fetch_20newsgroups
from nltk.corpus import stopwords
import nltk
# 下载nltk的停用词集
nltk.download('stopwords')
# 加载20 Newsgroups数据集
newsgroups = fetch_20newsgroups(subset='all')
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(newsgroups.data, newsgroups.target, test_size=0.2, random_state=42)
# 初始化TF-IDF向量化器,并设置停用词
tfidf_vectorizer = TfidfVectorizer(stop_words=stopwords.words('english'))
# 使用TF-IDF向量化器转换训练集数据
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
# 初始化KNN分类器
knn = KNeighborsClassifier()
# 定义K值的搜索范围
k_range = list(range(1, 31))
# 创建参数网格
param_grid = dict(n_neighbors=k_range)
# 初始化GridSearchCV对象
grid = GridSearchCV(knn, param_grid, cv=5, scoring='accuracy') # 使用5折交叉验证和准确率作为评分指标
# 在训练数据上进行网格搜索
grid.fit(X_train_tfidf.toarray(), y_train)
# 输出最佳K值
print("Best K: %d" % grid.best_params_['n_neighbors'])
# 使用最佳K值重新训练KNN分类器
best_knn = grid.best_estimator_
# 使用训练好的KNN分类器对测试集进行预测
y_pred = best_knn.predict(X_test_tfidf.toarray())
# 输出分类报告
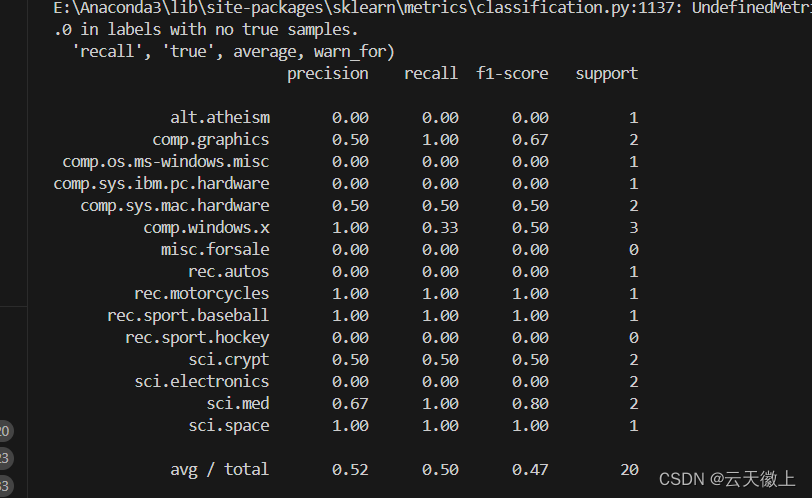
print(classification_report(y_test, y_pred, target_names=newsgroups.target_names))
在这段代码中,我们定义了一个K值的搜索范围k_range,然后使用GridSearchCV进行网格搜索,通过交叉验证(cv=5表示5折交叉验证)找到最佳K值。评分指标是准确率(‘accuracy’)。
请注意,GridSearchCV会在内部使用KNN分类器对训练数据进行交叉验证,并根据指定的评分指标选择最佳参数。一旦找到最佳参数,我们可以使用best_estimator_属性获取最佳模型,并用它来预测测试集。
本案列中的我为了加速计算只是取了部分数据集,测试的分类报告结果如下。
### 截取的部分数据集合
X_train, X_test, y_train, y_test = X_train[:2000], X_test[:20], y_train[:2000], y_test[:20]
七、结论与展望
7.1 KNN算法在机器学习中的价值
KNN算法作为机器学习领域中的一种基础且经典的分类算法,其简单直观、易于实现的特点使其在实际应用中得到了广泛的关注和应用。通过对训练样本的学习,KNN算法能够有效地利用样本间的相似性进行未知样本的分类,具有较好的分类性能。
在文本分类、图像识别、推荐系统等多个领域,KNN算法都展现出了其独特的优势。特别是在文本分类任务中,KNN算法能够处理高维、稀疏的文本数据,并通过计算文本之间的相似度来进行分类。这使得KNN算法在处理大规模文本数据集时具有较高的效率和准确性。
此外,KNN算法还具有较好的灵活性和可扩展性。通过调整K值、选择合适的距离度量方法以及优化特征提取技术,我们可以进一步提高KNN算法的分类性能。同时,KNN算法还可以与其他机器学习算法进行结合,形成更强大的分类器,以应对更复杂的分类任务。
7.2 未来研究方向与趋势
随着机器学习技术的不断发展,KNN算法也面临着新的挑战和机遇。未来,KNN算法的研究将主要围绕以下几个方面展开:
-
算法优化与性能提升:针对KNN算法在计算效率和分类性能上的不足,未来的研究将致力于优化算法结构、改进距离度量方法以及探索更高效的邻居搜索策略,以提高算法的性能和效率。
-
特征提取与选择:特征提取和选择对于KNN算法的性能具有重要影响。未来的研究将关注于开发更先进的特征提取技术,以提取出更具代表性、区分度的特征;同时,研究如何自动选择最优的特征组合,以进一步提高分类准确性。
-
处理大规模数据集:随着大数据时代的到来,处理大规模数据集成为了机器学习领域的一个重要挑战。未来的KNN算法研究将关注于如何高效地处理大规模数据集,包括利用分布式计算、并行计算等技术来提高算法的可扩展性和处理速度。
-
与其他算法的结合:KNN算法可以与其他机器学习算法进行结合,形成混合模型或集成学习模型。未来的研究将探索如何将KNN算法与其他算法进行有效结合,以充分利用各自的优点,提高分类性能。
-
理论分析与证明:虽然KNN算法在实际应用中取得了很好的效果,但其理论基础和性能界限仍有待进一步研究和证明。未来的研究将关注于对KNN算法的理论分析,包括收敛性、泛化能力等方面的研究,以进一步推动KNN算法的发展和应用。