一、既有范式
-
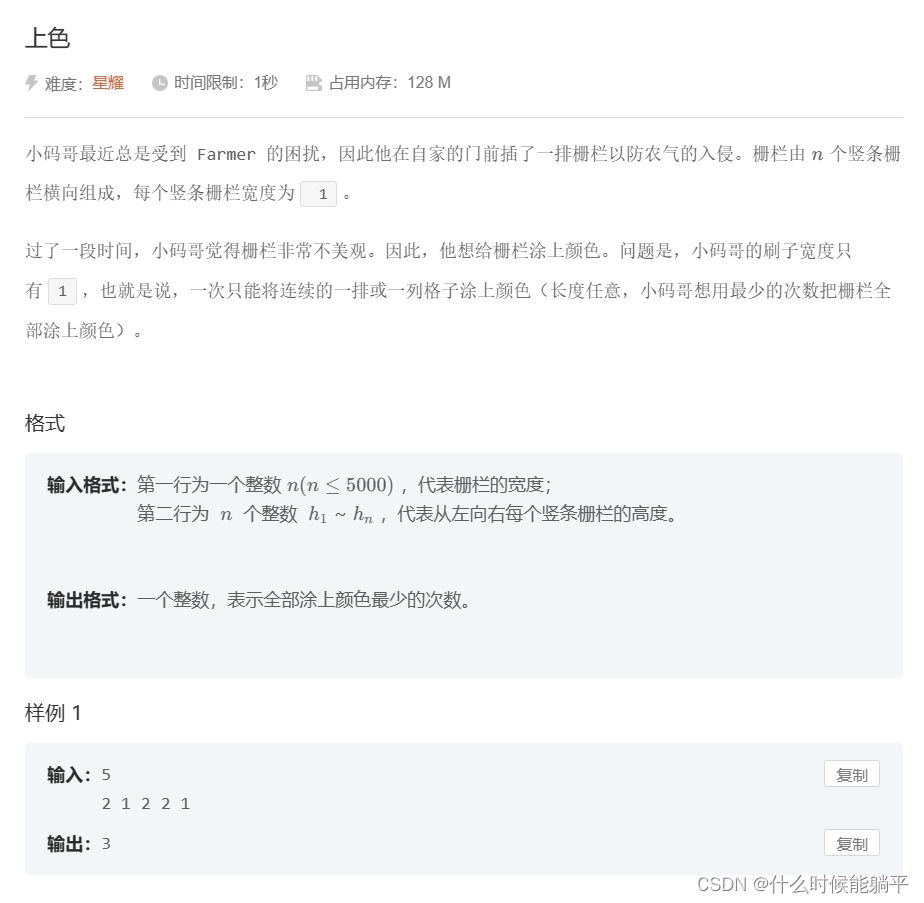
词向量的语言学特性:这部分主要通过一些具体的指标来评估词向量是否能捕捉到语言的内在规律,包括:
- 相似度评价指标:检查词向量空间中距离近的词是否与人类直觉一致,例如,利用余弦相似度来评估词之间的相似性。
- 类比问题:例如使用“king - queen = man - woman”这类关系来测试模型是否能够理解词之间的复杂关系。Baroni等人的文章介绍了8种这类指标,可以用于详细评估词向量模型的语义捕捉能力。
-
对实际NLP任务的贡献:这部分考虑的是将词向量应用到具体的自然语言处理(NLP)任务中去,看它们是否能带来性能的提升,具体方法包括:
- 对于使用传统方法的任务,将词向量直接作为特征输入,观察性能的变化。
- 在基于神经网络的模型中,将词向量作为词层的初始化参数。如果选取的初始化参数能显著提高模型性能,则可以认为这些词向量具有较好的表征能力。
二、MTEB
Massive Text Embedding Benchmark
是一个以任务为导向的向量模型评测平台。
mteb
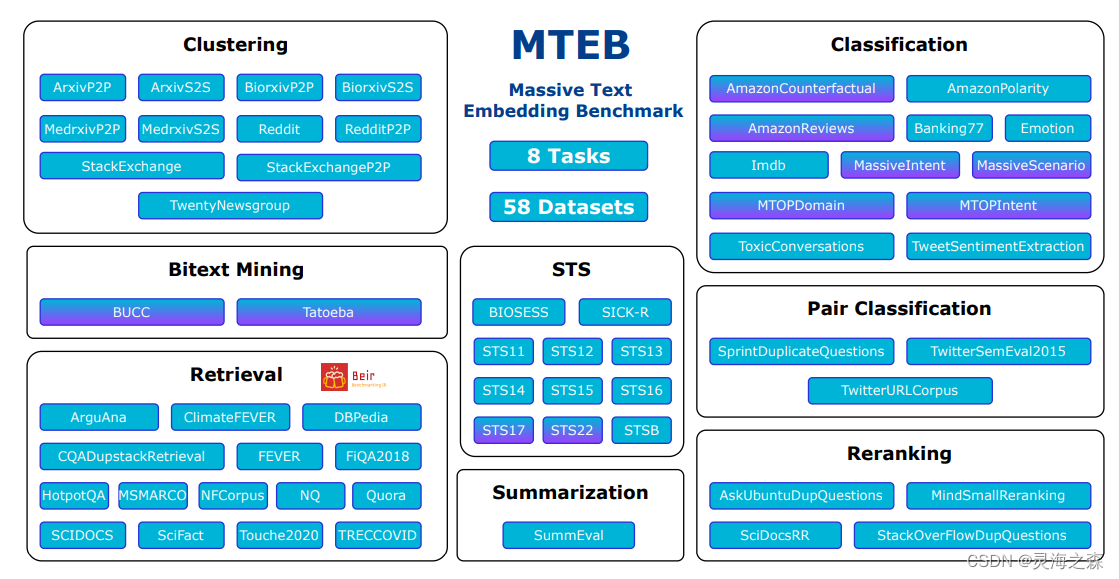
这八项嵌入任务代表了自然语言处理(NLP)中的核心问题,旨在评估模型在复杂语言环境中的表征和理解能力。
-
双语文本挖掘(Bitext Mining):
此任务涉及跨语言的信息检索,其中目标是在双语语料库中识别语义等价的句子对。具体地,给定源语言和目标语言的句子集合,任务是利用模型生成的句子嵌入和余弦相似度等度量,为源语言中的每个句子找到其在目标语言中的最佳匹配项,通常是其翻译等效物。 -
分类(Classification):
该任务要求模型对文本实例进行类别标注,基于提供的模型生成文本嵌入,并使用这些嵌入作为特征来训练分类器(例如逻辑回归)。这种任务通常用于情感分析、主题分类等应用,评估模型在理解文本主旨和情感倾向方面的能力。 -
聚类(Clustering):
在此任务中,模型需将文本集合分组至一个或多个类别中,而这些类别事先并不定义。通过分析模型生成的嵌入,利用算法(如K-means)在高维空间中识别自然聚类,旨在评估模型捕获文本语义相似性的能力。 -
句子对分类(Pair Classification):
该任务要求模型对一对文本进行分析,判断它们之间是否存在特定的关系,如语义等价或对立。模型需生成每个文本的嵌入表示,进而通过计算嵌入间的相似度(使用余弦相似度等度量),为文本对分配适当的标签。 -
重新排序(Reranking):
在重新排序任务中,给定一个查询和一组候选文本,目标是根据它们与查询的相关性对这些文本进行排序。模型通过生成查询和文本的嵌入,并计算它们之间的相似度(如余弦相似度),来评估其在信息检索和问答系统中的应用效果。 -
检索(Retrieval):
此任务关注于从大规模语料库中检索与查询最相关的文档。通过为查询和语料库文档生成嵌入表示,并计算它们之间的相似度分数,模型需要正确地将查询映射到相关文档上。性能通过nDCG@k、MRR@k等信息检索指标进行评估。 -
语义文本相似度(Semantic Textual Similarity, STS):
在STS任务中,模型需评估给定句子对在语义上的相似度程度。该任务通过比较模型生成的句子嵌入,并使用诸如余弦相似度之类的度量来计算它们之间的相似性。性能通常通过Pearson和Spearman相关系数来衡量,与人类评估的相似度得分进行对比。 -
摘要(Summarization):
此任务涉及评估机器生成摘要的质量。模型需要生成摘要的嵌入表示,并计算它与一组参考人类摘要嵌入之间的距离。通过选择与人类摘要最相似(例如,通过余弦相似度)的机器生成摘要评分,来衡量生成摘要的质量。
同时也提供了自定义评估的开源库。后续将尝试。