Mybatis+多数据源
这个是对shardingjdbc应用的一个升级,如果对于shardingjdbc的整合还没看过之前的文章的,可以先看看文章https://blog.csdn.net/Think_and_work/article/details/137174049?spm=1001.2014.3001.5501
整合步骤
1、依赖
和全新项目的单数据源依赖的一样
2、mybatis使用数据源配置有两种方式
- 一种是使用注解的方式
- 一种是指定xml使用某个数据源
我们这里使用注解的方式进行配置
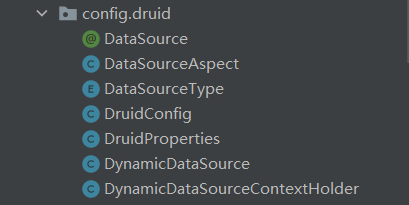
相关的类主要如下:
注解类DataSource
package com.walker.mybatissharding.config.druid;
import java.lang.annotation.*;
/**
* 自定义多数据源切换注解
* <p>
* 优先级:先方法,后类,如果方法覆盖了类上的数据源类型,以方法的为准,否则以类上的为准
*
* @author
*/
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
public @interface DataSource {
/**
* 切换数据源名称
*/
DataSourceType value() default DataSourceType.MASTER;
}
枚举DataSourceType
package com.walker.mybatissharding.config.druid;
/**
* 数据源
*
* @author
*/
public enum DataSourceType {
/**
* 主库
*/
MASTER,
/**
* 分表
*/
SHARDING,
}
连接池配置信息
package com.walker.mybatissharding.config.druid;
import com.alibaba.druid.pool.DruidDataSource;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
/**
* druid 配置属性
*
* @author
*/
@Configuration
public class DruidProperties
{
@Value("${spring.datasource.initialSize}")
private int initialSize;
@Value("${spring.datasource.minIdle}")
private int minIdle;
@Value("${spring.datasource.maxActive}")
private int maxActive;
@Value("${spring.datasource.maxWait}")
private int maxWait;
@Value("${spring.datasource.timeBetweenEvictionRunsMillis}")
private int timeBetweenEvictionRunsMillis;
@Value("${spring.datasource.minEvictableIdleTimeMillis}")
private int minEvictableIdleTimeMillis;
@Value("${spring.datasource.maxEvictableIdleTimeMillis}")
private int maxEvictableIdleTimeMillis;
@Value("${spring.datasource.validationQuery}")
private String validationQuery;
@Value("${spring.datasource.testWhileIdle}")
private boolean testWhileIdle;
@Value("${spring.datasource.testOnBorrow}")
private boolean testOnBorrow;
@Value("${spring.datasource.testOnReturn}")
private boolean testOnReturn;
public DruidDataSource dataSource(DruidDataSource datasource)
{
/** 配置初始化大小、最小、最大 */
datasource.setInitialSize(initialSize);
datasource.setMaxActive(maxActive);
datasource.setMinIdle(minIdle);
/** 配置获取连接等待超时的时间 */
datasource.setMaxWait(maxWait);
/** 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 */
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
/** 配置一个连接在池中最小、最大生存的时间,单位是毫秒 */
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setMaxEvictableIdleTimeMillis(maxEvictableIdleTimeMillis);
/**
* 用来检测连接是否有效的sql,要求是一个查询语句,常用select 'x'。如果validationQuery为null,testOnBorrow、testOnReturn、testWhileIdle都不会起作用。
*/
datasource.setValidationQuery(validationQuery);
/** 建议配置为true,不影响性能,并且保证安全性。申请连接的时候检测,如果空闲时间大于timeBetweenEvictionRunsMillis,执行validationQuery检测连接是否有效。 */
datasource.setTestWhileIdle(testWhileIdle);
/** 申请连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 */
datasource.setTestOnBorrow(testOnBorrow);
/** 归还连接时执行validationQuery检测连接是否有效,做了这个配置会降低性能。 */
datasource.setTestOnReturn(testOnReturn);
return datasource;
}
}
使用ThreadLocal存储数据源变量
package com.walker.mybatissharding.config.druid;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 数据源切换处理
*
* @author
*/
public class DynamicDataSourceContextHolder
{
public static final Logger log = LoggerFactory.getLogger(DynamicDataSourceContextHolder.class);
/**
* 使用ThreadLocal维护变量,ThreadLocal为每个使用该变量的线程提供独立的变量副本,
* 所以每一个线程都可以独立地改变自己的副本,而不会影响其它线程所对应的副本。
*/
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 设置数据源的变量
*/
public static void setDataSourceType(String dsType)
{
log.info("切换到{}数据源", dsType);
CONTEXT_HOLDER.set(dsType);
}
/**
* 获得数据源的变量
*/
public static String getDataSourceType()
{
return CONTEXT_HOLDER.get();
}
/**
* 清空数据源变量
*/
public static void clearDataSourceType()
{
CONTEXT_HOLDER.remove();
}
}
继承AbstractRoutingDataSource
package com.walker.mybatissharding.config.druid;
import org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource;
import javax.sql.DataSource;
import java.util.Map;
/**
* 动态数据源
*
* @author
*/
// 继承AbstractRoutingDataSource
public class DynamicDataSource extends AbstractRoutingDataSource
{
public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources)
{
// 设置默认数据源
super.setDefaultTargetDataSource(defaultTargetDataSource);
// 设置目标数据源 Map
super.setTargetDataSources(targetDataSources);
//
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey()
{
return DynamicDataSourceContextHolder.getDataSourceType();
}
}
切面类 DataSourceAspect
package com.walker.mybatissharding.config.druid;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.core.annotation.AnnotationUtils;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import java.util.Objects;
/**
* 多数据源处理
*
* @author
*/
@Aspect
@Order(1)
@Component
public class DataSourceAspect {
protected Logger logger = LoggerFactory.getLogger(getClass());
@Pointcut("@annotation(com.walker.mybatissharding.config.druid.DataSource)"
+ "|| @within(com.walker.mybatissharding.config.druid.DataSource)")
public void dsPointCut() {
}
@Around("dsPointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
DataSource dataSource = getDataSource(point);
if (dataSource != null) {
DynamicDataSourceContextHolder.setDataSourceType(dataSource.value().name());
}
try {
return point.proceed();
} finally {
// 销毁数据源 在执行方法之后
DynamicDataSourceContextHolder.clearDataSourceType();
}
}
/**
* 获取需要切换的数据源
*/
public DataSource getDataSource(ProceedingJoinPoint point) {
MethodSignature signature = (MethodSignature) point.getSignature();
DataSource dataSource = AnnotationUtils.findAnnotation(signature.getMethod(), DataSource.class);
if (Objects.nonNull(dataSource)) {
return dataSource;
}
return AnnotationUtils.findAnnotation(signature.getDeclaringType(), DataSource.class);
}
}
DruidConfig 配置类
package com.walker.mybatissharding.config.druid;
import cn.hutool.extra.spring.SpringUtil;
import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;
import com.alibaba.druid.spring.boot.autoconfigure.properties.DruidStatProperties;
import com.alibaba.druid.util.Utils;
import lombok.extern.slf4j.Slf4j;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import javax.servlet.*;
import javax.sql.DataSource;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
/**
* druid 配置多数据源
*
* @author
*/
@Slf4j
@Configuration
public class DruidConfig
{
// 主库数据源
@Bean
@ConfigurationProperties("spring.datasource.master")
public DataSource masterDataSource(DruidProperties druidProperties)
{
DruidDataSource dataSource = DruidDataSourceBuilder.create().build();
return druidProperties.dataSource(dataSource);
}
// 动态数据源
@Bean(name = "dynamicDataSource")
@Primary
public DynamicDataSource dataSource(DataSource masterDataSource)
{
Map<Object, Object> targetDataSources = new HashMap<>();
// 将master加入
targetDataSources.put(DataSourceType.MASTER.name(), masterDataSource);
// 将sharding数据源加入
setDataSource(targetDataSources, DataSourceType.SHARDING.name(), "shardingSphereDataSource");
// 默认走master
return new DynamicDataSource(masterDataSource, targetDataSources);
}
/**
* 设置数据源
*
* @param targetDataSources 备选数据源集合
* @param sourceName 数据源名称
* @param beanName bean名称
*/
public void setDataSource(Map<Object, Object> targetDataSources, String sourceName, String beanName)
{
try
{
DataSource dataSource = SpringUtil.getBean(beanName);
targetDataSources.put(sourceName, dataSource);
}
catch (Exception e)
{
log.error("设置数据源失败",e);
}
}
/**
* 去除监控页面底部的广告
*/
@SuppressWarnings({ "rawtypes", "unchecked" })
@Bean
@ConditionalOnProperty(name = "spring.datasource.druid.statViewServlet.enabled", havingValue = "true")
public FilterRegistrationBean removeDruidFilterRegistrationBean(DruidStatProperties properties)
{
// 获取web监控页面的参数
DruidStatProperties.StatViewServlet config = properties.getStatViewServlet();
// 提取common.js的配置路径
String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*";
String commonJsPattern = pattern.replaceAll("\\*", "js/common.js");
final String filePath = "support/http/resources/js/common.js";
// 创建filter进行过滤
Filter filter = new Filter()
{
@Override
public void init(javax.servlet.FilterConfig filterConfig) throws ServletException
{
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException
{
chain.doFilter(request, response);
// 重置缓冲区,响应头不会被重置
response.resetBuffer();
// 获取common.js
String text = Utils.readFromResource(filePath);
// // 正则替换banner, 除去底部的广告信息
// text = text.replaceAll("<a.*?banner\"></a><br/>", "");
// text = text.replaceAll("powered.*?shrek.wang</a>", "");
response.getWriter().write(text);
}
@Override
public void destroy()
{
}
};
FilterRegistrationBean registrationBean = new FilterRegistrationBean();
registrationBean.setFilter(filter);
registrationBean.addUrlPatterns(commonJsPattern);
return registrationBean;
}
}
3、application配置
server:
port: 11001
spring:
autoconfigure: # 排除druid 否则报错
exclude: com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure
# mybatis配置
datasource:
master:
url: jdbc:mysql://localhost:3306/table_sharding?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
# 初始连接数
initialSize: 5
# 最小连接池数量
minIdle: 10
# 最大连接池数量
maxActive: 20
# 配置获取连接等待超时的时间
maxWait: 60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
minEvictableIdleTimeMillis: 300000
# 配置一个连接在池中最大生存的时间,单位是毫秒
maxEvictableIdleTimeMillis: 900000
# 配置检测连接是否有效
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
#
shardingsphere:
# 开启sql打印
enabled: true
props:
# 是否显示sql
sql-show: true
datasource:
# 数据源名称
names: sharding
# 数据源实例:
sharding:
type: com.alibaba.druid.pool.DruidDataSource
driver-class: com.mysql.cj.jdbc.Driver
# 使用Druid,不能使用jdbc-url 得使用url
url: jdbc:mysql://localhost:3306/table_sharding?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=Asia/Shanghai
username: root
password: 123456
# 分片规则
rules:
sharding:
# 对表进行分片
tables:
# 逻辑表名,代表的是需要分表的名称
order_info:
# 实际节点:这里代表的是 会使用sharding数据源中 order_info表 细分为0~3 4个表
actual-data-nodes: sharding.order_info_$->{0..3}
# 表策略
table-strategy:
# 标准表策略
standard:
# 分表的列
sharding-column: id
# 分片算法名称: 来源于下面的sharding-algorithms
sharding-algorithm-name: alg_hash_mod
key-generate-strategy: # 主键生成策略
column: id # 主键列
key-generator-name: snowflake # 策略算法名称(推荐使用雪花算法)
# 主键生成规则,SNOWFLAKE 雪花算法
key-generators:
snowflake:
type: SNOWFLAKE
# 分片算法
sharding-algorithms:
alg_hash_mod:
# 类型:hash取余 类似于获取一个列的数,假如是3 3%4=0 数据就会进入第0个表
type: HASH_MOD
# 分片的数量,因为是4个表,所以是4
props:
sharding-count: 4
mybatis:
# 映射文件 配置之后,mybatis会去扫描该路径下的xml文件,才会与Mapper对应起来
mapper-locations: classpath:mapper/*.xml
# 别名类(实体类)所在包
type-aliases-package: com.walker.mybatissharding.entity
configuration:
# 打印日志
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
# 驼峰转换
map-underscore-to-camel-case: true
4、测试类
- entity类
package com.walker.mybatissharding.entity;
import lombok.Data;
import java.util.Date;
/**
* @Author: WalkerShen
* @DATE: 2022/3/29
* @Description:
**/
@Data
public class OrderInfo {
private Long id;
private String name;
private Integer num;
private Date createTime;
}
- Mapper
package com.walker.mybatissharding.mapper;
import com.walker.mybatissharding.config.druid.DataSource;
import com.walker.mybatissharding.config.druid.DataSourceType;
import com.walker.mybatissharding.entity.OrderInfo;
import org.apache.ibatis.annotations.Mapper;
import java.util.List;
/**
* @Author: WalkerShen
* @DATE: 2022/3/29
* @Description: 创建mapper接口,
**/
//使用@Mapper,注入容器
@Mapper
public interface OrderInfoMapper {
List<OrderInfo> list();
// 使用指定的数据源,则使用注解标注,否则就走主数据源
@DataSource(value = DataSourceType.SHARDING)
List<OrderInfo> listSharding();
}
mapper.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!--namespace:命名空间,用来映射对应的mapper
相当于将mapper和mapper.xml连接起来,这一步很重要-->
<mapper namespace="com.walker.mybatissharding.mapper.OrderInfoMapper">
<select id="list" resultType="com.walker.mybatissharding.entity.OrderInfo">
select * from order_info
</select>
<select id="listSharding" resultType="com.walker.mybatissharding.entity.OrderInfo">
select * from order_info
</select>
</mapper>
测试类
package com.walker.mybatissharding;
import com.walker.mybatissharding.entity.OrderInfo;
import com.walker.mybatissharding.mapper.OrderInfoMapper;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@Slf4j
@SpringBootTest
class MybatisShardingApplicationTests {
@Autowired
private OrderInfoMapper orderInfoMapper;
// 查 列表
@Test
void list() {
List<OrderInfo> list = orderInfoMapper.list();
System.out.println("返回结果:"+list);
}
@Test
void listSharding() {
List<OrderInfo> list = orderInfoMapper.listSharding();
System.out.println("返回结果:"+list);
}
}
执行测试方法:
执行list方法:

可以看到,是直接查询order_info的,没有走分表的策略
执行listSharding
从分表中获取数据

总结
这里是对sharding整合Mybatis的流程进行一个整合,在实际场景上应该是用的比较多的,大部分公司其实还只是mybatis,当然对于Mybatisplus的整合也是不少的。所以后续的文章会继续出相关的内容,希望对你有帮助。
项目地址
https://gitee.com/shen-chuhao/walker_open_java/blob/master/sharding_learn/pom.xml






![【算法每日一练]-数论(保姆级教程 篇1 埃氏筛,欧拉筛)](https://img-blog.csdnimg.cn/direct/8a9af66bfbe84cfeadaf29083185b7c9.png)