目录
简述
开始
操作系统环境下的程序运行
裸机环境下的程序运行
程序入口main()函数分析
BSS段的小提示
政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
收录专栏: 嵌入式智能产品开发实战
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
程序的运行分两种情况:
一种是在有操作系统的环境下执行一个应用程序;
另一种是在无操作系统的环境下执行一个裸机程序。
简述
ARM-Linux中C语言程序的运行环境可以简单地分为以下几个部分:
-
ARM架构:ARM-Linux是在ARM架构上运行的操作系统,所以C语言程序需要在ARM架构下编译和运行。
-
Linux操作系统:ARM-Linux是基于Linux内核的操作系统,它提供了一系列的系统调用(system calls)和库函数(library functions),C语言程序可以通过这些接口与操作系统进行交互,例如文件操作、进程管理、网络通信等。
-
C语言编译器:在ARM-Linux中,常用的C语言编译器有GCC(GNU Compiler Collection),它可以将C语言源代码编译成对应的ARM机器码。编译器还提供了一些特定的标志和选项,用于控制编译过程,例如优化等级、目标平台等。
-
C运行时库:C语言程序在运行时需要依赖一些运行时库,这些库包含了一些常用的函数和数据结构。在ARM-Linux中,标准的C运行时库是GNU C Library(glibc),它提供了丰富的接口和功能,可以方便地进行内存管理、字符串处理、数学运算等。
-
虚拟内存管理:ARM-Linux支持虚拟内存管理,它通过将程序的地址空间划分为多个虚拟页面,实现了对内存的隔离和保护。C语言程序可以通过内存管理接口(如malloc和free函数)进行动态内存分配和释放。
总之,ARM-Linux中的C语言程序在ARM架构、Linux操作系统、C语言编译器、C运行时库和虚拟内存管理的支持下,可以在ARM-Linux系统上编译和运行。这些组成部分提供了丰富的功能和接口,使得开发者可以方便地编写、编译和运行C语言程序。
开始
在不同的环境下执行程序,文件的格式一般也会不一样,如在Linux环境下,可执行文件是ELF格式,而在裸机环境下执行的程序一般是BIN/HEX格式。
BIN/HEX文件是纯指令文件,没有其他杂七杂八的辅助信息,而ELF文件除了基本的代码段、数据段,还有文件头、符号表、program header table等用来辅助程序运行的信息。
两种程序虽然运行环境不同,文件格式也有所差异,但原理是相通的:都要将指令加载到内存中的指定位置。
而这个指定位置往往又与可执行文件链接时的链接地址有关。
操作系统环境下的程序运行
一个装有操作系统的计算机系统,当执行一个应用程序时,首先会运行一个叫作加载器的程序。
加载器会根据软件的安装路径信息,将可执行文件从ROM中加载到内存,然后进行一些与初始化、动态库重定位相关的操作,最后才跳转到程序的入口运行。
在不同的操作系统下,可以由不同的程序充当“加载器”的角色,如在Linux命令行模式下运行一个应用程序,类似sh、bash这样的Shell终端程序就充当加载器的角色:它们会把程序加载到内存,封装成进程,参与操作系统的调度和运行。
一个可执行文件由不同的section组成,分为代码段、数据段、BSS段等。加载器在加载程序运行时,会将这些代码段、数据段分别加载到内存中的不同位置。
可执行文件的文件头提供了文件类型、运行平台、程序的入口地址等基本信息,加载器在加载程序之前会首先根据文件头的信息做一些判断,如果发现程序的运行平台和当前的环境不符,则会报出错处理。
(可执行文件和可重定位目标文件)
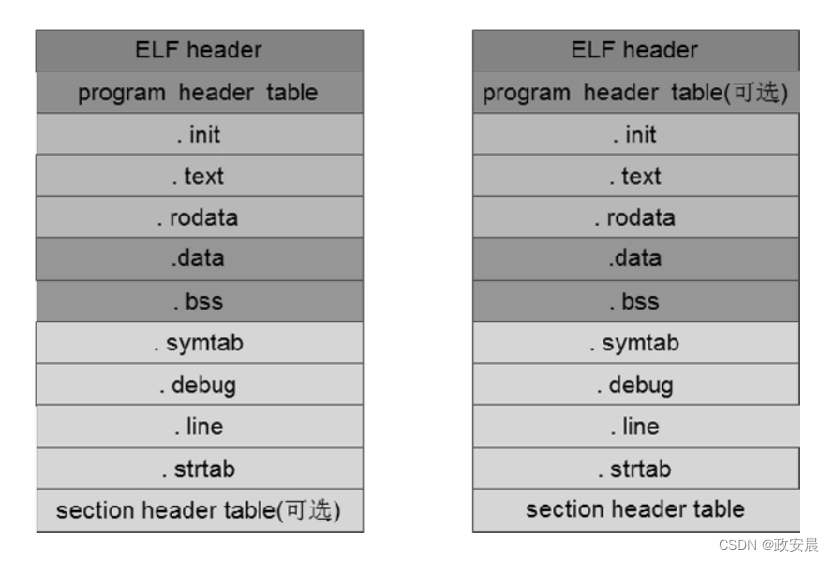
除此之外,可执行文件中还有一个叫作program header table的section,翻译成中文时,不同的资料可能叫法不同,我们可以暂称其为段头表。
段头表中记录的是如何将可执行文件加载到内存的相关信息,包括可执行文件中要加载到内存中的段、入口地址等信息。
如下图所示,可重定位目标文件因为是不可执行的,不需要加载到内存中,所以段头表这个section在目标文件中不是必须存在的,是可选的。而在一个可执行文件中,加载器要加载程序到内存,要依赖段头表提供的信息,因此段头表是必需的。我们可以使用readelf命令查看可执行文件的段头表。
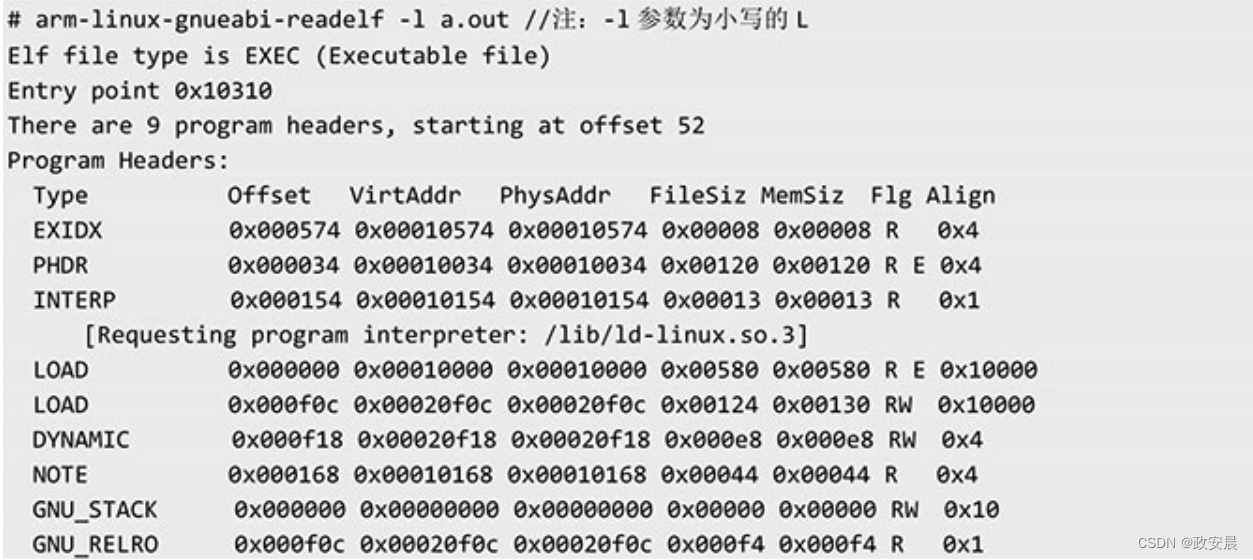
在Linux环境下运行的程序一般都会被封装成进程,参与操作系统的统一调度和运行。
在Shell环境下运行一个程序,Shell终端程序一般会先fork一个子进程,创建一个独立的虚拟进程地址空间,接着调用execve函数将要运行的程序加载到进程空间:通过可执行文件的文件头,找到程序的入口地址,建立进程虚拟地址空间与可执行文件的映射关系,将PC指针设置为可执行文件的入口地址,即可启动运行。
一段C程序、编译生成的可执行文件、可执行文件运行时的进程之间的对应关系如下图所示:
(C程序、可执行文件和进程)
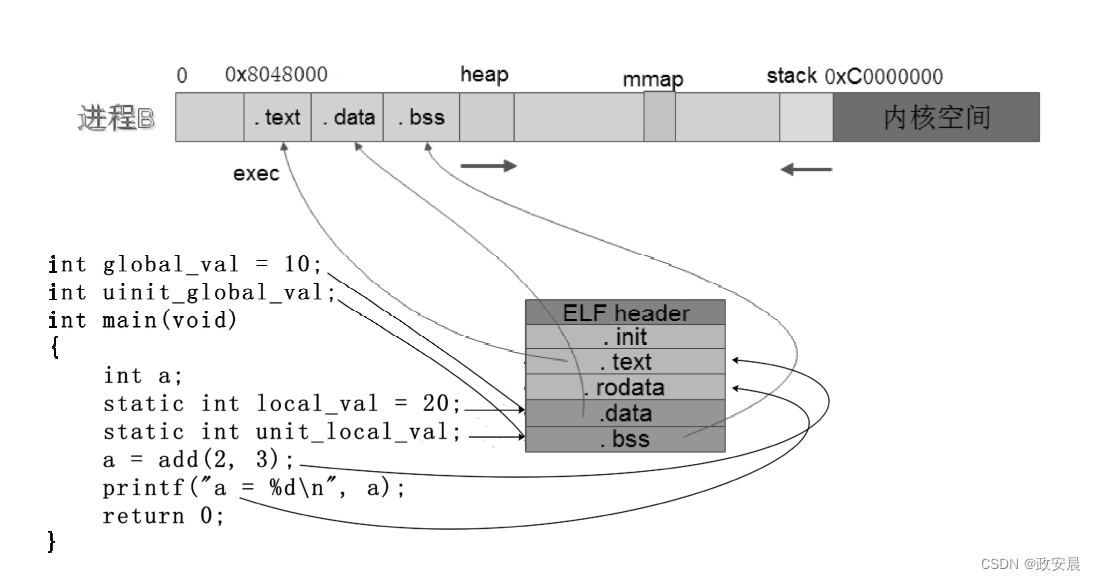
一般情况下,程序的入口地址可通过下面的计算公式得到:程序的入口地址=编译时的链接地址+一定偏移(程序头等会占用一部分空间)
不同的编译器有不同的链接起始地址。在Linux环境下,GCC链接时一般以0x08040000为起始地址开始存放代码段,而ARM GCC交叉编译器一般以0x10000为链接起始地址。
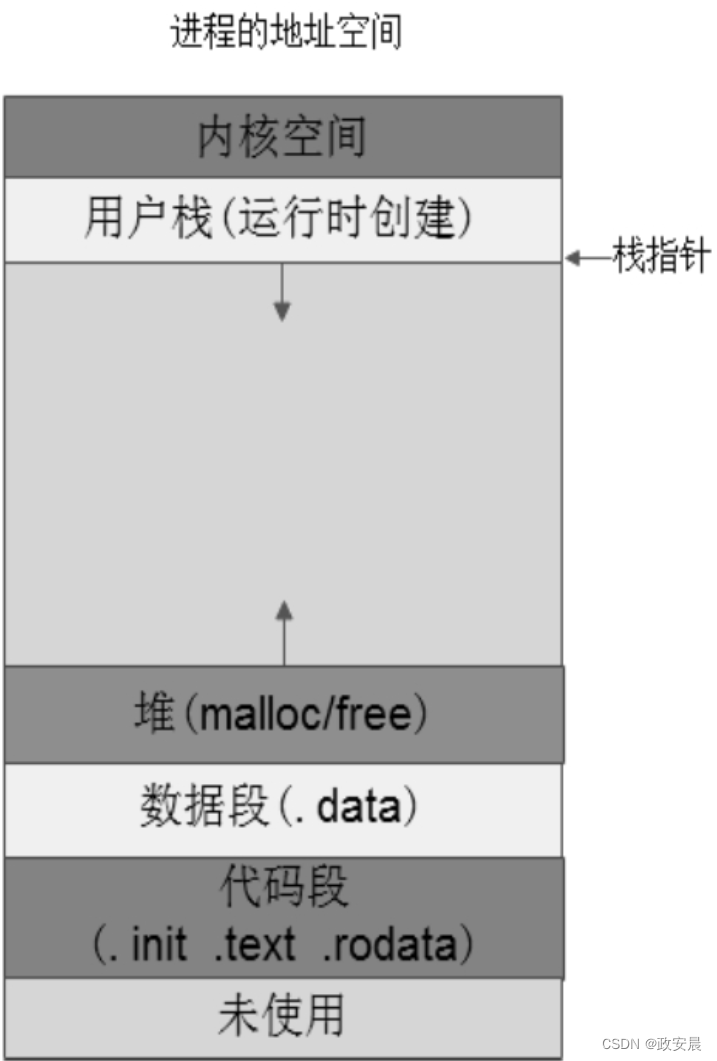
紧挨着代码段,从一个4KB边界对齐的地址处开始存放数据段。紧挨着数据段,就是BSS段。BSS段后面的第一个4KB地址对齐处,就是我们在程序中使用malloc()/free()申请的堆空间。一个可执行文件加载到内存中执行,它在内存中的地址空间分布如下图所示:
看到这里,集才华和机智于一身的你,心中一个小小的疑惑可能就产生了:在一台计算机上通常会运行多个进程,而每个进程的指令代码在编译时都是采用同一个链接地址的,在运行时它们会被加载到内存中的同一个地址吗?会不会产生地址冲突?
放心吧,不会冲突的。你能想到的问题,计算机专家自然也会想到并且早就解决了:程序链接时的链接地址其实都是虚拟地址。
如下图所示:
(虚拟地址到物理地址的转换,程序在内存中的地址分布)
(虚拟地址到物理地址的转换)
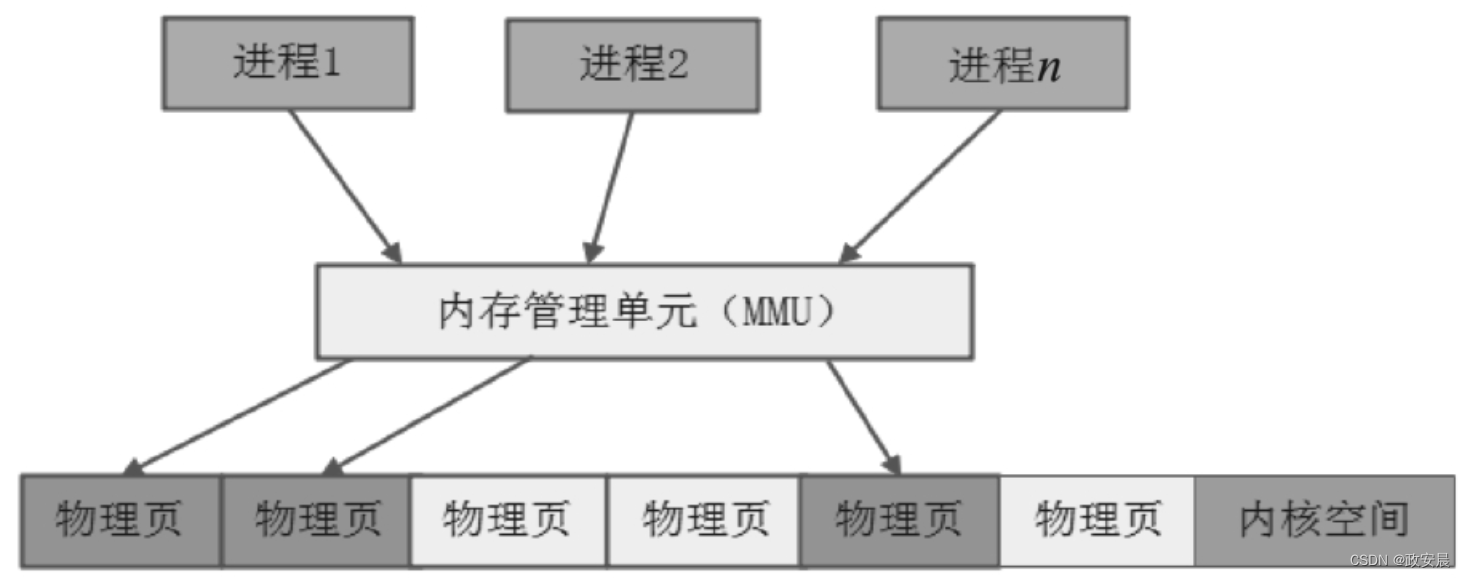
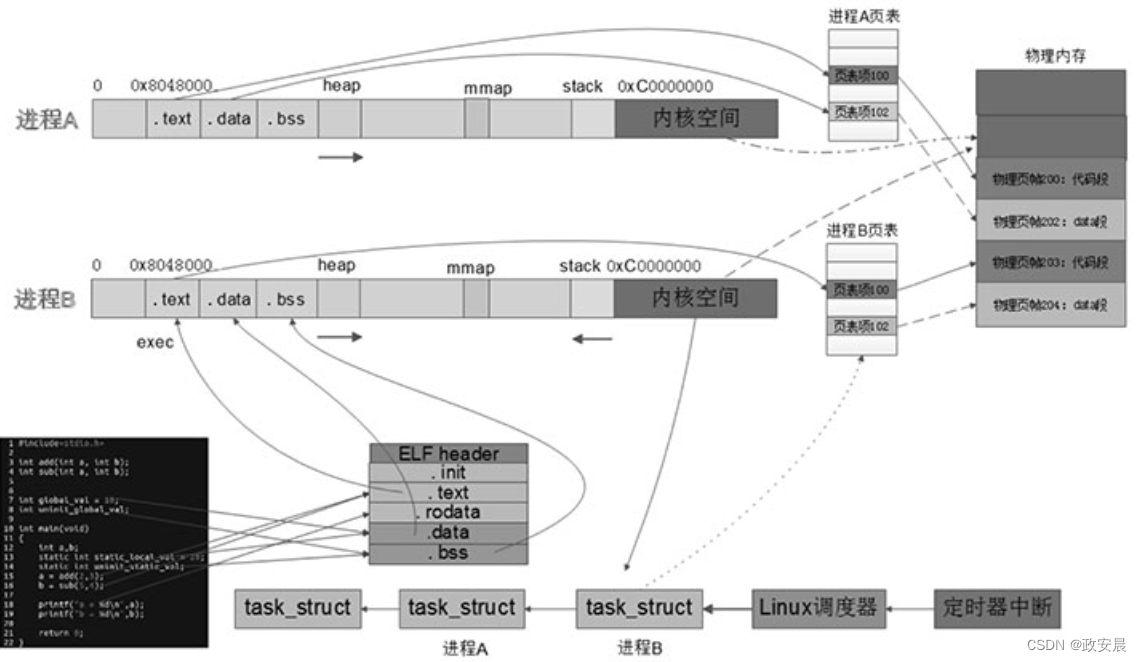
程序运行时,虽然每个进程的地址空间都是一样的,但是每个进程都有自己的页表,页表里的每一个条目叫页表项,页表项里存储的是虚拟地址和物理地址之间的映射关系,相同的虚拟地址经过MMU硬件转换后,会分别映射到物理内存的不同区域,彼此相互隔离和独立,一点也不会起冲突。
对于每一个运行的进程,Linux内核都会使用一个task_struct结构体来表示,多个结构体通过指针构成链表。操作系统基于该链表就可以对这些进程进行管理、调度和运行。不同进程的代码段和数据段分别存储在物理内存不同的物理页上,进程间彼此独立,通过上下文切换,轮流占用CPU去执行自己的指令。
当Linux环境下有多个进程并发运行时,C源程序、可执行文件、进程和物理内存之间的对应关系如下图所示:
裸机环境下的程序运行
在操作系统环境下,我们可以通过加载器将程序的指令加载到内存中,然后CPU到内存中取指运行。在一个裸机平台下,系统上电后,没有程序运行的环境,我们需要借助第三方工具将程序加载到内存,然后才能正常运行。
很多集成开发环境如ADS1.2、Keil、RVDS等IDE,不仅提供了程序编辑、编译的功能,同时支持程序的运行、调试、烧写。以ADS1.2集成开发环境为例。
如下图所示:
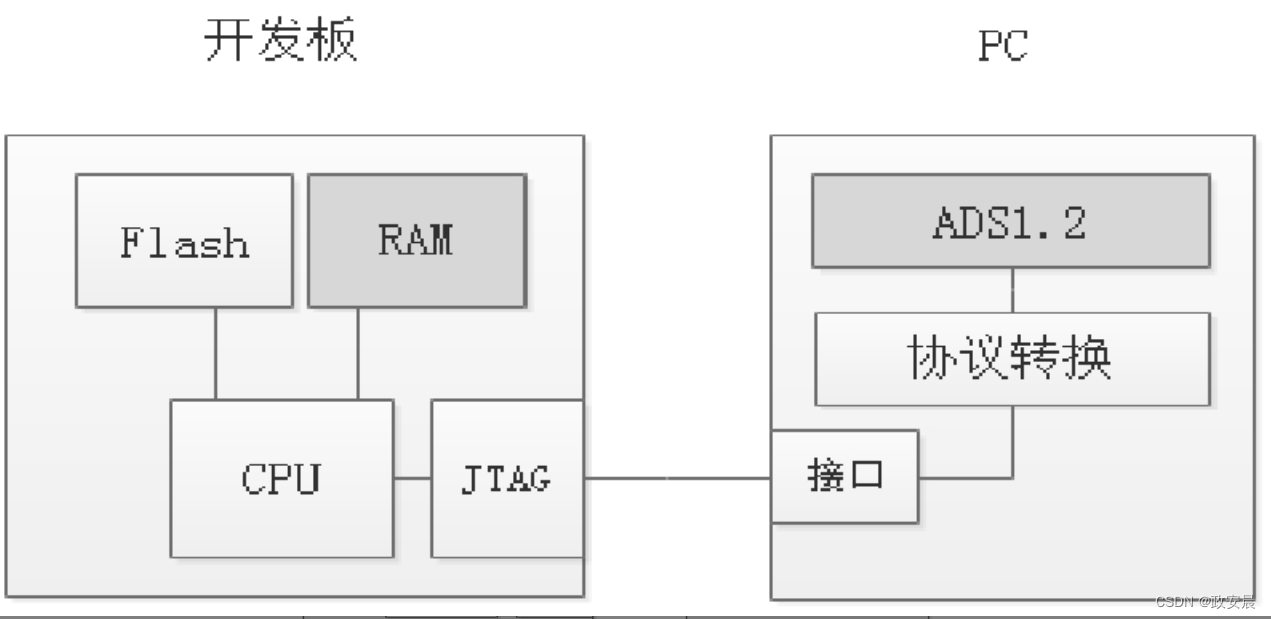
它可以通过JTAG接口和开发板通信,将我们在PC上编译好的BIN/HEX格式的ARM可执行文件下载到开发板的内存中运行。要下载到内存的哪里呢?我们可以根据开发板的实际RAM物理地址,在编译程序时通过ADS1.2集成开发环境提供的Debug Setting设置选项来设置。
在一个嵌入式Linux系统中,Linux内核镜像的运行其实就是裸机环境下的程序运行。
Linux内核镜像一般会借助U-boot这个加载工具将其从Flash存储分区加载到内存中运行,U-boot在Linux启动过程中扮演了“加载器”的角色。当然U-boot的功能绝不仅限于此,现在的U-boot功能已经很强大了,实现了各种各样的功能,这里不再赘述。
U-boot自身的启动,其实也挺值得研究的。
U-boot在Linux启动过程中,充当了“加载器”的角色,但是其自身也和Linux内核镜像一样,存储在NAND/NOR分区上。
在U-boot启动过程中,不仅要完成本身代码的“自复制”:将自身代码从存储分区复制到内存中,还要完成自身代码的重定位,一般具备这种功能的代码我们称之为“自举”。关于U-boot的自我重定位是怎么实现的,在后面章节咱们会展开分析,本文中就暂不展开了。
程序入口main()函数分析
加载器将指令加载到内存后,接着就要运行程序了,从哪里开始执行呢?
这里就要分析程序的入口:main()函数了。
在分析之前,我们先做一个小实验。

在上面的程序中,我们定义多个main()函数,程序编译时会报重定义错误。修改函数名,只保留其中一个main()函数,你会发现,保留哪个函数名为main,程序便会执行哪个函数。是不是很神奇?这也说明了在一个项目中,main()函数是所有程序的入口函数。
但事实可能不是这样。
编译器在编译一个工程时,默认的程序入口是_start符号,而不是main。符号main是一个约定符号,它用来告诉编译器在一个项目中哪里是程序的入口点。程序员在开发一个项目时,也会遵守这个约定,使用main()函数作为项目的入口函数。
兵马未动,粮草先行。其实在main()函数运行之前,已经有“先头部队”代码提前运行了:它们主要完成运行main()函数之前的一些初始化工作,如初始化堆栈指针等。
栈是C语言运行的必备环境,C语言函数调用过程中的参数传递、函数内部的局部变量都是保存在栈中的,没有栈C语言就无法运行,因此在运行main()函数之前必须先运行一段汇编代码来初始化堆栈环境。
设置好堆栈指针后,这部分代码还要继续初始化一些环境,如初始化data段的内容,初始化static静态变量和global全局变量,并给BSS段的变量赋初值:未初始化的全局变量中,int类型的全部初始化为0,布尔型的变量初始化为FALSE,指针型的变量初始化为NULL。完成初始化环境后,这部分代码还会将用户传入的参数传递给main,最后才跳入main()函数运行。
这部分初始化代码是在程序编译阶段,由编译器自动添加到可执行文件中的。这部分代码属于C运行库(C Running Time,CRT)中的代码,编译器厂商在开发编译器时,除了实现C语言标准中规定的printf、fopen、fread等标准函数,还会实现这部分初始化代码,完成进入main()函数之前的一系列初始化操作。
● C语言运行的基本堆栈环境、进程环境。
● 动态库的加载、释放、初始化、清理等工作。
● 向main()函数传参argc、argv,调用main()函数执行。
● 在main()函数退出后,调用exit()函数,结束进程的运行。
在ARM交叉编译器安装路径下的lib目录下,你会看到一个叫作crt1.o的目标文件,这个文件其实就是由汇编初始化代码编译生成的,是CRT的一部分。在链接过程中,链接器会将crt1.o这个目标文件和项目中的目标文件组装在一起,生成最终的可执行文件。
我们可以使用objdump命令来反汇编这个目标文件。
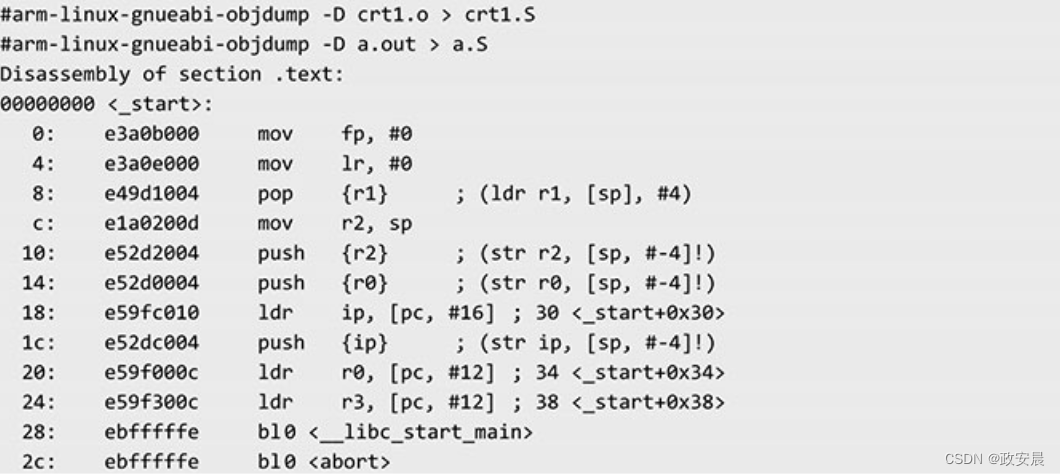
分别反汇编可执行文件a.out和crt1.o,对比两者的_start汇编代码,你会发现两者是一样的:a.out中的这段汇编代码是由crt1.o组装而来的。
接下来分析这段汇编代码,从程序入口地址_start开始的一段汇编代码,其核心工作就是初始化C语言运行依赖的栈环境,并设置栈指针。
这段代码在不同的环境下可能不太一样,在嵌入式系统裸机环境下,系统上电后要初始化时钟、内存,然后设置堆栈指针,而在普通的操作系统环境下,内存等各种硬件设备已经工作,堆栈环境也已经初始化完毕,不需要做这一部分工作了,保存一些上下文环境后就可以直接跳到第一个C语言入口函数:__libc_start_main。这个函数在C标准库中定义,以glibc-2.30为例,定义在libc-start.c文件中。

__libc_start_main函数的代码很长,我们简化分析后的大致流程如下:首先设置程序运行的进程环境,加载共享库,解析用户输入的参数,将参数传递给main()函数,最后调用main()函数运行。main()函数运行结束后,再调用exit函数结束整个进程。
不同的编译器,C标准库的实现略有差异,和程序员约定的项目入口地址可能也不一样。
如Windows win32窗口程序约定的入口函数是WinMain;Visual Studio和VC++6.0的C++编译器约定的项目入口函数是_tmain;QT、Eclipse等大多数IDE约定的入口函数一般也是main()函数。
main只是编译器和程序员约定好的默认入口点,并不是一成不变的,程序员也可以自定义程序入口。如果我们想改变一个项目的入口地址,其实很简单。

在上面的程序中,我们定义了mymain()函数,并打算将其设置为我们程序的入口,通过下面的命令就可完成。

编译参数-nostartfiles表示不链接art1.o文件。通过这种显式指定函数入口编译生成的可执行程序,也可以正常运行,只是有一个细节需要注意一下,函数退出时不能再使用return,而要使用exit退出,否则就会报段错误。这是因为可执行文件没有链接初始化代码crt1.o,无法再处理mymain()函数退出后的扫尾清理工作,我们在mymain()函数内直接调用exit结束进程就可以了。
通过本文,相信大家已经对程序的真正入口函数_start、工程项目的约定入口main()函数有了更深入的理解。至此,一个源程序经过编译、链接、安装、加载运行,并跳入我们自己编写的项目入口main()函数运行,整个流程已经分析完毕。
BSS段的小提示
通过上面的学习,我们已经对程序编译运行的整个流程有了一个基本了解。但还遗漏了一点内容,那就是关于BSS段的加载与运行。
对于未初始化的全局变量和静态局部变量,编译器将其放置在BSS段中。BSS段是不占用可执行文件存储空间的,早期的计算机存储资源昂贵而且比较紧张,设置BSS段的目的主要就是减少可执行文件的体积,节省磁盘空间。
虽然BBS段在可执行文件中不占用存储空间,但是当程序加载到内存运行时,加载器会在内存中给BSS段开辟一段存储空间。在section header table中会记录BSS段的大小,在符号表中会记录每个变量的地址和大小。
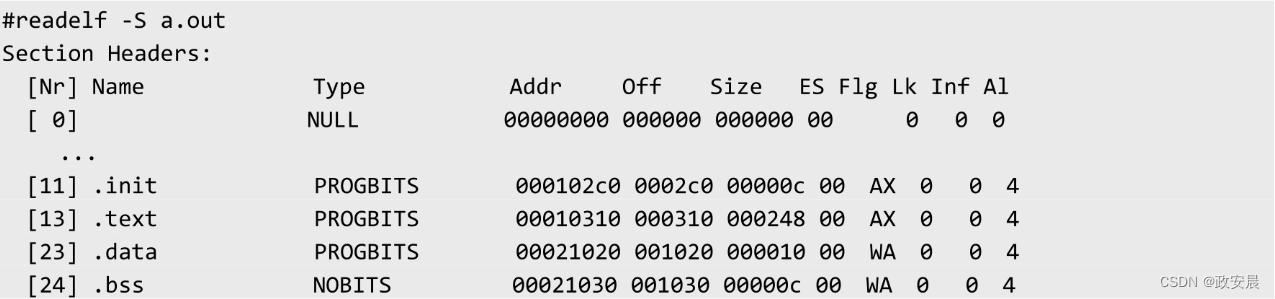
加载器会根据这些信息,在数据段的后面分配指定大小的内存空间并清零,根据符号表中各个变量的地址,在这片内存中给各个未初始化的全局变量、静态变量分配存储空间。到了这一步,一个程序被加载到内存后,它在内存中的分布如下图所示。
(可执行文件和进程虚拟地址空间)
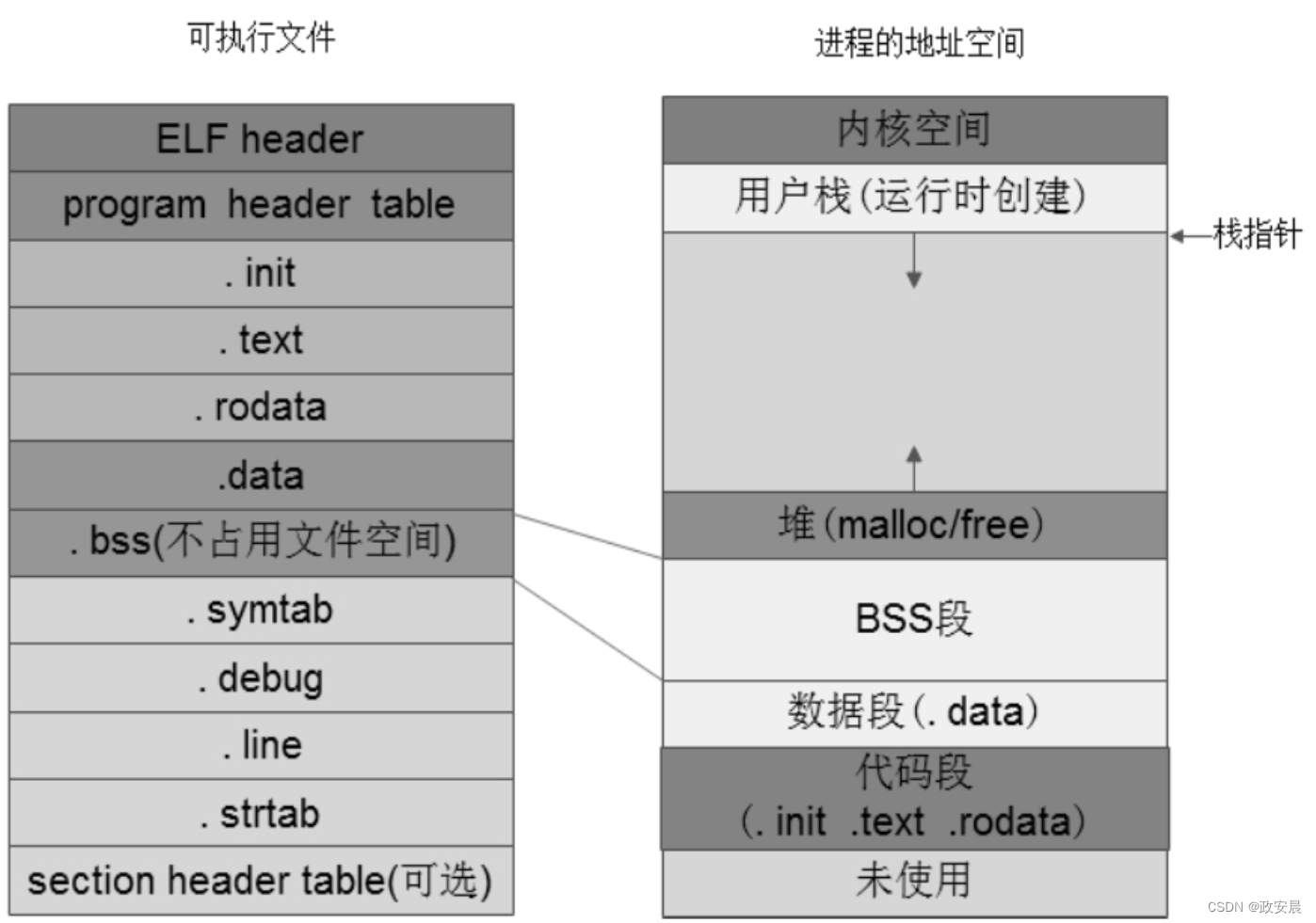
最后我们对BSS段做一个小结:BSS段设计的初衷就是为了减少文件体积,节省磁盘资源。编译器对数据段和BSS段符号的处理流程是相同的,唯一的差异在于:在可执行文件内不给BSS段分配存储空间,在程序运行内存时再分配存储空间和地址。