本文是LLM系列文章,针对《Video Understanding with Large Language Models: A Survey》的翻译。
论文链接:https://arxiv.org/pdf/2312.17432v2.pdf
代码链接:https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding
大型语言模型下的视频理解研究综述
- 摘要
- 1 引言
- 2 基础
-
- 2.1 与LLM的视觉集成
- 2.2 语言在视频理解中的角色
- 2.3 其他模态
- 2.4 训练策略
- 3 VID-LLMs:模型
-
- 3.1 基于LLM的视频代理
- 3.2 Vid-LLM预训练
- 3.3 Vid-LLM指令调整
-
- 3.3.1 连接适配器微调
- 3.3.2 插入式适配器微调
- 3.3.3 混合适配器微调
- 3.4 混合方法
- 4 任务、数据集、基线
-
- 4.1 识别和预测
-
- 4.1.1 数据集概述
- 4.1.2 评估标准
- 4.2 标注和描述
-
- 4.2.1 数据集概述
- 4.2.2 评估标准
- 4.3 基线和检索
-
- 4.3.1 数据集概述
- 4.3.2 评估标准
- 4.4 问答
-
- 4.1.1 数据集概述
- 4.1.2 评估标准
- 4.5 视频指令调整
-
- 4.5.1 数据集概述
- 4.5.2 评估标准
- 5 应用
-
- 5.1 媒体和娱乐
- 5.2 交互式和以用户为中心的技术
- 5.3 医疗保健和安全应用
- 6 未来方向与应用
-
- 6.1 局限和未来工作
- 6.2 结论
摘要.
随着在线视频平台的蓬勃发展和视频内容量的急剧增长,对高效视频理解工具的需求显著增强。鉴于大型语言模型(LLMs)在语言和多模态任务中展现出的强大功能,本综述详细梳理了利用LLMs进行视频理解领域研究的最新进展,特别是在视频理解大型语言模型(Vid-LLMs)方面的突破。Vid-LLMs展现出的新兴能力极为先进,特别是其结合常识知识进行开放性时空推理的能力,预示着未来视频理解的一个极具潜力的发展路径。我们考察了Vid-LLMs的独特特性和能力,将其方法论归纳为四大类型:基于LLMs的视频代理、Vid-LLMs预训练、Vid-LLMs指令调优和混合方法。此外,本综述还对Vid-LLMs涉及的任务、数据集和评估方法进行了全面研究,并探讨了Vid-LLMs在各个领域的广泛应用,突显了其在现实世界视频理解挑战中表现出的强大可扩展性和多功能性。最后,本综述总结了现有Vid-LLMs的局限性,并指出了未来研究的方向。更多详情请访问GitHub仓库:https://github.com/yunlong10/Awesome-LLMs-for-Video-Understanding。
1 引言
我们生活在一个多模态世界中,视频已成为主导形式的媒体。随着在线视频平台的迅速扩张以及监控、娱乐和自动驾驶领域摄像头的日益普及,视频内容已成为一种高度引人入胜且丰富的媒介,凭借其深度和吸引力,超越了传统的文本和图像-文本组合。这一进步推动了视频制作的指数级增长,每天创作数百万个视频。然而,手动处理如此庞大量的视频内容被证明既费力又耗时。因此,人们对能够有效管理、分析和处理这些大量视频内容的工具需求日益增长。为了满足这一需求,视频理解方法和分析技术应运而生,利用智能分析技术自动识别和解释视频内容,从而显著减轻人类操作员的工作负担。此外,这些方法的持续进步正在增强它们的任务解决能力,使其能够以日益娴熟的方式处理各种视频理解任务。
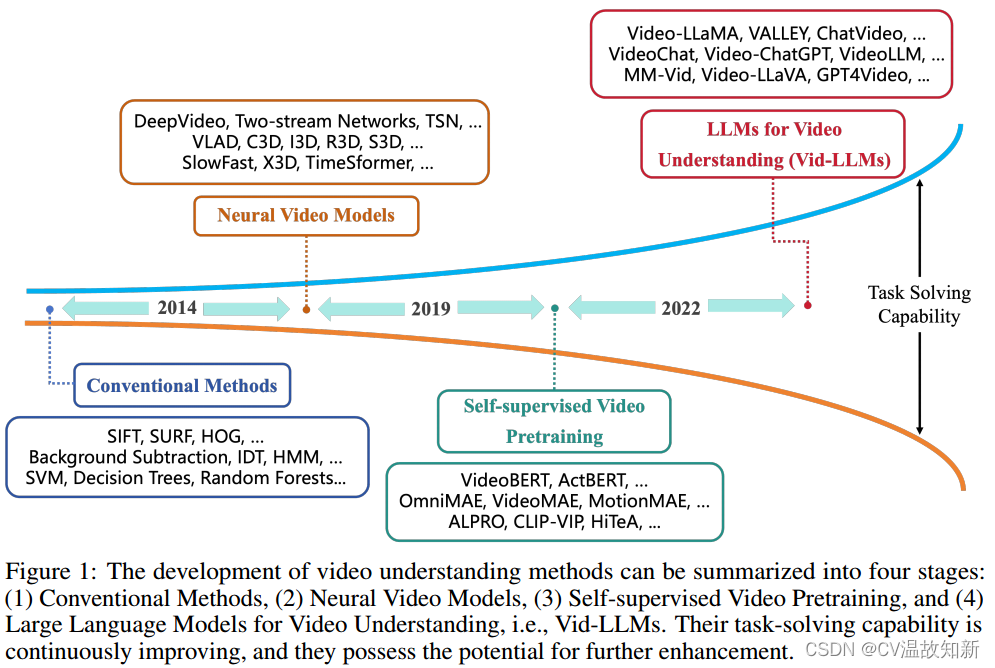
如图1所示,视频理解方法的演变可以分为四个阶段:
1. 传统方法
在视频理解的早期阶段,手工特征提取技术如尺度不变特征变换(SIFT)[1]、加速稳健特征(SURF)[2]和梯度直方图(HOG)[3]被用于捕捉视频中的关键信息。背景减除[4]、光流方法[5]和改进的密集轨迹(IDT)[6, 7]被用于建模用于跟踪的运动信息。由于视频可以被视为时间序列数据,时间序列分析技术如隐马尔可夫模型(HMM)[8]也被用于理解视频内容。在深度学习流行之前,基本的机器学习算法如支持向量机(SVM)[9]、决策树[10]和随机森林也被用于视频分类和识别任务。用于对视频段进行聚类分析的聚类分析[11],或用于数据降维的主成分分析(PCA)[12, 13]也是视频分析中常用的方法。
2. 神经视频模型
与传统方法相比,用于视频理解的深度学习方法具有更强大的任务解决能力。DeepVideo [14]是最早引入深度神经网络,特别是卷积神经网络(CNN),用于视频理解的方法。然而,由于对运动信息的不充分利用,其性能并不优于最佳的手工特征方法。双流网络[15]结合了CNN和IDT来捕捉运动信息以提高性能,验证了深度神经网络在视频理解方面的能力。为了处理长格式视频理解,采用了长短期记忆(LSTM)。时序段网络(TSN)也被设计用于长格式视频理解,通过分析视频段并将它们聚合。基于TSN,引入了Fisher向量编码、双线性编码和局部聚合描述符向量编码。这些方法提高了在UCF-101和HMDB51数据集上的性能。不同于双流网络,3D网络通过引入3D卷积神经网络到视频理解(C3D)开启了另一个分支。膨胀的3D ConvNets(I3D)利用了2D卷积神经网络Inception的初始化和架构,在UCF-101和HMDB51数据集上取得了巨大的改进。随后,人们开始使用Kinetics-400和Something-Something数据集来评估模型在更具挑战性场景下的性能。ResNet、ResNeXt和SENet也从2D转向3D,出现了R3D、MFNet和STC。为了提高效率,3D网络在各种研究中被分解为2D和1D网络。LTC、T3D、Non-local和V4D专注于长格式时间建模,而CSN、SlowFast和X3D倾向于实现高效率。引入Vision Transformers促进了一系列杰出的模型。
3. 自监督视频预训练
自监督预训练模型在视频理解中的可转移性允许它们在最小额外标记的情况下横跨多样任务进行泛化,克服了早期深度学习模型对大量任务特定数据的需求。VideoBERT是对视频预训练的早期尝试。基于双向语言模型BERT,设计了自监督学习的相关任务。它使用分层k均值对视频特征进行标记。预训练模型可以微调以处理多个下游任务,包括动作分类和视频字幕。许多研究探索了用于视频理解的预训练模型,尤其是视频语言模型。它们使用不同的架构或预训练和微调策略。
4. 大语言模型用于视频理解
最近,大语言模型迅速发展。在广泛数据集上预训练的大语言模型的出现引入了一种新的上下文学习能力。这使它们能够使用提示来处理各种任务,而无需微调。ChatGPT是建立在这一基础上的第一个突破性应用。这包括生成代码和调用其他模型的工具或API的能力。许多研究正在探索使用大语言模型像ChatGPT调用视觉模型API来解决计算机视觉领域的问题。指导微调的出现进一步增强了这些模型对用户请求的有效响应和执行特定任务的能力。集成视频理解能力的大语言模型提供了更复杂的多模态理解优势,使其能够处理和解释视觉和文本数据之间的复杂交互。类似于它们在自然语言处理中的影响,这些模型作为更通用的任务解决者,擅长利用其广泛的知识库和从大量多模态数据中获得的上下文理解来处理更广泛的任务。这使它们不仅能理解视觉内容,还能以更符合人类理解的方式推理。许多作品还探索了在视频理解任务中使用大语言模型,即Vid-LLMs。
之前的论文要么研究视频理解领域中的特定子任务,要么关注超越视频理解范畴的方法论。例如,[76]研究了用于一般视觉-语言任务的多模态基础模型,其中包括图像和视频应用。[77]和[78]分别专注于研究视频字幕生成和视频动作识别任务。其他视频理解任务,如视频问答和定位,未被考虑。此外,[79]和[80]研究了视频相关的方法论 - 视频扩散模型和LLMs,但缺乏对视频理解的关注。之前的研究论文在基于大型语言模型的一般视频理解任务研究中存在空白,本文通过对使用大型语言模型进行视频理解任务的全面调研来填补这一空白。
本论文结构如下:
第2节提供了全面的概述,强调利用LLMs能力的方法,并详细说明这些方法解决的具体任务和数据集。
第3节深入探讨了最近利用LLMs进行视频理解的研究细节,展示它们在领域中的独特方法和影响。
第4节提供了各种任务、相关数据集和评估指标的详细总结和分析。
第5节探讨了Video-LLMs在多个重要领域中的应用。
第6节总结,概括了关键发现,并确定了未解决的挑战和未来研究的潜在领域。
除了这项调查外,我们建立了一个GitHub存储库,汇总了各种支持视频理解与大型语言模型(Vid-LLMs)的资源:GitHub - yunlong10/Awesome-LLMs-for-Video-Understanding: 🔥🔥🔥Latest Papers, Codes and Datasets on Vid-LLMs.
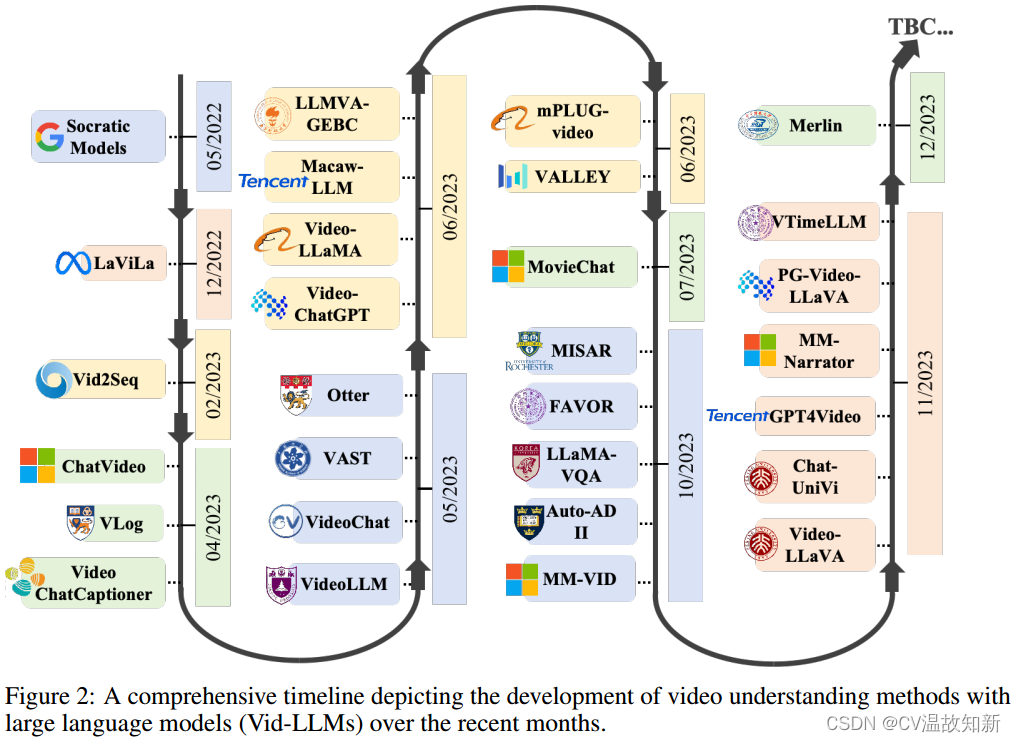
2 基础
视频理解是一个挑战,激发了许多创新任务的创建,以增强模型的视频解释能力。该领域已经从基础任务,如视频分类和动作识别,演变为涵盖更复杂任务的范围。这些任务包括为视频加上详细描述和回答有关视频内容的问题。后者不仅需要理解视频,还涉及与逻辑和常识知识推理。随着领域的发展,任务变得越来越复杂和具有挑战性,需要具有接近人类水平的视频解释能力的模型。我们总结视频理解的主要任务有以下4种:
1. 识别和预测(Recognition and Anticipation):这些任务在视频理解中紧密相关,着重于视频内的时间连续性和进展。
2. 描述和摘要(Captioning and Summarization):这些任务侧重于更精细的细节,涉及为每个时刻创建准确和具体的文本描述,提炼视频的本质,从而概括其主题和关键叙述。它们为视频内容提供了详细和广泛的视角。
3. 定位和检索(Grounding and Retrieval):将视觉内容与文本上下文无缝链接,属于这一类别的任务要求模型识别与提供的文本描述准确对应的具体视频或片段。
4. 问答(Question Answering):这些任务强调模型在理解视频的视觉和听觉组成部分方面的熟练








![【算法每日一练]-数论(保姆级教程 篇1 埃氏筛,欧拉筛)](https://img-blog.csdnimg.cn/direct/8a9af66bfbe84cfeadaf29083185b7c9.png)