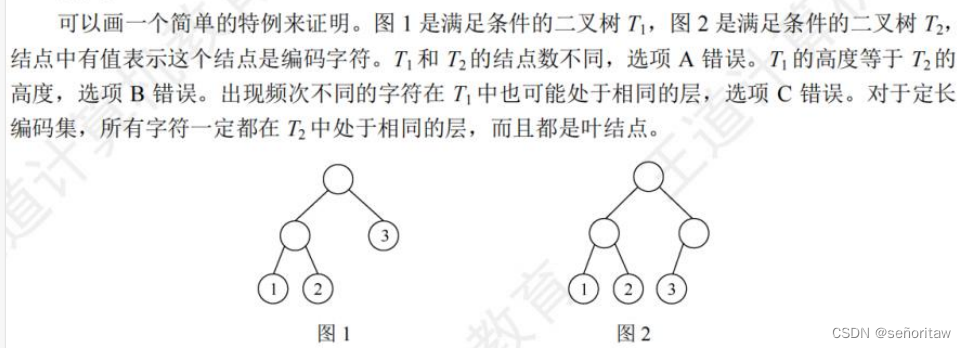
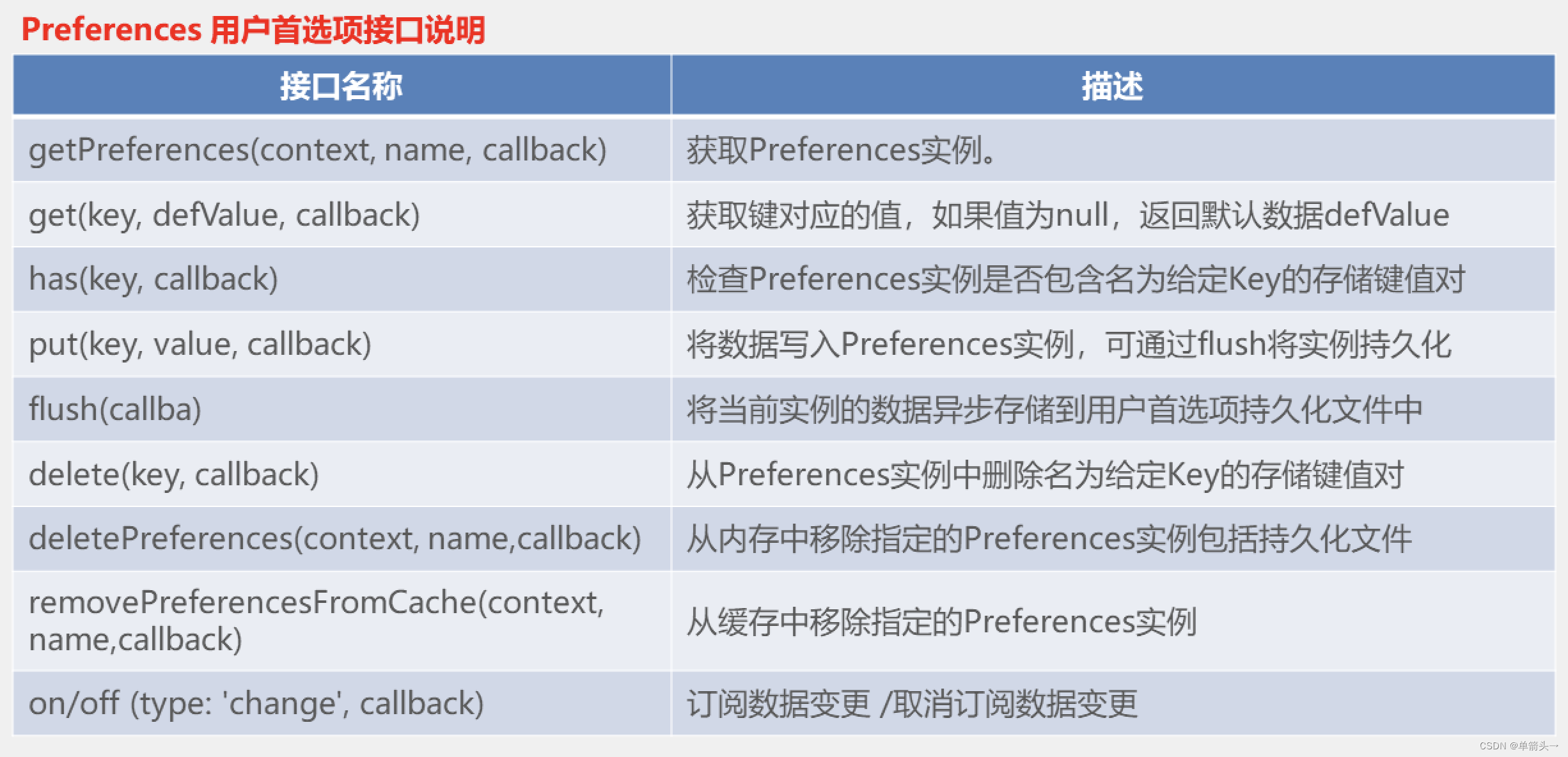
目录
- 一、基本概念
- 二、Aggregate 和 Unique 模型中的 ROLLUP
- 三、Duplicate 模型中的 ROLLUP
- 四、ROLLUP 调整前缀索引
- 五、ROLLUP使用说明
- 六、查询
- 6.1 索引
- 6.2 聚合数据
一、基本概念
ROLLUP 在多维分析中是“上卷”的意思,即将数据按某种指定的粒度进行进一步聚合。
在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table)。Base 表中保存着按用户建表语句指定的方式存储的基础数据。
在 Base 表之上,我们可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。
ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据。
下面我们用示例详细说明在不同数据模型中的 ROLLUP 表及其作用。
二、Aggregate 和 Unique 模型中的 ROLLUP
因为 Unique 只是 Aggregate 模型的一个特例,所以这里我们不加以区别。
示例1:获得每个用户的总消费
接 数据模型Aggregate 模型小节的示例2,Base 表结构如下:
ColumnName Type AggregationType Comment
user_id LARGEINT 用户id
date DATE 数据灌入日期
timestamp DATETIME 数据灌入时间,精确到秒
city VARCHAR(20) 用户所在城市
age SMALLINT 用户年龄
sex TINYINT 用户性别
last_visit_date DATETIME REPLACE 用户最后一次访问时间
cost BIGINT SUM 用户总消费
max_dwell_time INT MAX 用户最大停留时间
min_dwell_time INT MIN 用户最小停留时间
存储的数据如下:
user_id date timestamp city age sex last_visit_date cost max_dwell_time min_dwell_time
10000 2017-10-01 2017-10-01 08:00:05 北京 20 0 2017-10-01 06:00:00 20 10 10
10000 2017-10-01 2017-10-01 09:00:05 北京 20 0 2017-10-01 07:00:00 15 2 2
10001 2017-10-01 2017-10-01 18:12:10 北京 30 1 2017-10-01 17:05:45 2 22 22
10002 2017-10-02 2017-10-02 13:10:00 上海 20 1 2017-10-02 12:59:12 200 5 5
10003 2017-10-02 2017-10-02 13:15:00 广州 32 0 2017-10-02 11:20:00 30 11 11
10004 2017-10-01 2017-10-01 12:12:48 深圳 35 0 2017-10-01 10:00:15 100 3 3
10004 2017-10-03 2017-10-03 12:38:20 深圳 35 0 2017-10-03 10:20:22 11 6 6
在此基础上,我们创建一个 ROLLUP:
ColumnName
user_id
cost
该 ROLLUP 只包含两列:user_id 和 cost。则创建完成后,该 ROLLUP 中存储的数据如下:
user_id cost
10000 35
10001 2
10002 200
10003 30
10004 111
可以看到,ROLLUP 中仅保留了每个 user_id,在 cost 列上的 SUM 的结果。那么当我们进行如下查询时:
SELECT user_id, sum(cost) FROM table GROUP BY user_id;
Doris 会自动命中这个 ROLLUP 表,从而只需扫描极少的数据量,即可完成这次聚合查询。
示例2:获得不同城市,不同年龄段用户的总消费、最长和最短页面驻留时间
紧接示例1。我们在 Base 表基础之上,再创建一个 ROLLUP:
ColumnName Type AggregationType Comment
city VARCHAR(20) 用户所在城市
age SMALLINT 用户年龄
cost BIGINT SUM 用户总消费
max_dwell_time INT MAX 用户最大停留时间
min_dwell_time INT MIN 用户最小停留时间
则创建完成后,该 ROLLUP 中存储的数据如下:
city age cost max_dwell_time min_dwell_time
北京 20 35 10 2
北京 30 2 22 22
上海 20 200 5 5
广州 32 30 11 11
深圳 35 111 6 3
当我们进行如下这些查询时:
mysql> SELECT city, age, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city, age;
mysql> SELECT city, sum(cost), max(max_dwell_time), min(min_dwell_time) FROM table GROUP BY city;
mysql> SELECT city, age, sum(cost), min(min_dwell_time) FROM table GROUP BY city, age;
Doris 执行这些sql时会自动命中这个 ROLLUP 表。
三、Duplicate 模型中的 ROLLUP
因为 Duplicate 模型没有聚合的语意。所以该模型中的 ROLLUP,已经失去了“上卷”这一层含义。而仅仅是作为调整列顺序,以命中前缀索引的作用。我们将在前缀索引详细介绍前缀索引,以及如何使用ROLLUP改变前缀索引,以获得更好的查询效率。
四、ROLLUP 调整前缀索引
因为建表时已经指定了列顺序,所以一个表只有一种前缀索引。这对于使用其他不能命中前缀索引的列作为条件进行的查询来说,效率上可能无法满足需求。因此,我们可以通过创建 ROLLUP 来人为的调整列顺序。举例说明:
Base 表结构如下:
ColumnName Type
user_id BIGINT
age INT
message VARCHAR(100)
max_dwell_time DATETIME
min_dwell_time DATETIME
我们可以在此基础上创建一个 ROLLUP 表:
ColumnName Type
age INT
user_id BIGINT
message VARCHAR(100)
max_dwell_time DATETIME
min_dwell_time DATETIME
可以看到,ROLLUP 和 Base 表的列完全一样,只是将 user_id 和 age 的顺序调换了。那么当我们进行如下查询时:
mysql> SELECT * FROM table where age=20 and message LIKE "%error%";
会优先选择 ROLLUP 表,因为 ROLLUP 的前缀索引匹配度更高。
五、ROLLUP使用说明
- ROLLUP 最根本的作用是提高某些查询的查询效率(无论是通过聚合来减少数据量,还是修改列顺序以匹配前缀索引)。因此 ROLLUP 的含义已经超出了 “上卷” 的范围。这也是为什么我们在源代码中,将其命名为 Materialized Index(物化索引)的原因。
- ROLLUP 是附属于 Base 表的,可以看做是 Base 表的一种辅助数据结构。用户可以在 Base 表的基础上,创建或删除 ROLLUP,但是不能在查询中显式的指定查询某 ROLLUP。是否命中 ROLLUP 完全由 Doris 系统自动决定。
- ROLLUP 的数据是独立物理存储的。因此,创建的 ROLLUP 越多,占用的磁盘空间也就越大。同时对导入速度也会有影响(导入的ETL阶段会自动产生所有 ROLLUP 的数据),但是不会降低查询效率(只会更好)。
- ROLLUP 的数据更新与 Base 表是完全同步的。用户无需关心这个问题。
- ROLLUP 中列的聚合方式,与 Base 表完全相同。在创建 ROLLUP 无需指定,也不能修改。
查询能否命中 ROLLUP 的一个必要条件(非充分条件)是,查询所涉及的所有列(包括 select list 和 where 中的查询条件列等)都存在于该 ROLLUP 的列中。否则,查询只能命中 Base 表。 - 某些类型的查询(如 count(*))在任何条件下,都无法命中 ROLLUP。
- 可以通过 EXPLAIN your_sql; 命令获得查询执行计划,在执行计划中,查看是否命中 ROLLUP。
- 可以通过 DESC tbl_name ALL; 语句显示 Base 表和所有已创建完成的 ROLLUP。
六、查询
在 Doris 里 Rollup 作为一份聚合物化视图,其在查询中可以起到两个作用:
- 索引
- 聚合数据(仅用于聚合模型,即aggregate key)
但是为了命中 Rollup 需要满足一定的条件,并且可以通过执行计划中 ScanNode 节点的 PreAggregation 的值来判断是否可以命中 Rollup,以及 Rollup 字段来判断命中的是哪一张 Rollup 表。
6.1 索引
前面的前缀索引中已经介绍过 Doris 的前缀索引,即 Doris 会把 Base/Rollup 表中的前 36 个字节(有 varchar 类型则可能导致前缀索引不满 36 个字节,varchar 会截断前缀索引,并且最多使用 varchar 的 20 个字节)在底层存储引擎单独生成一份排序的稀疏索引数据(数据也是排序的,用索引定位,然后在数据中做二分查找),然后在查询的时候会根据查询中的条件来匹配每个 Base/Rollup 的前缀索引,并且选择出匹配前缀索引最长的一个 Base/Rollup。
-----> 从左到右匹配
+----+----+----+----+----+----+
| c1 | c2 | c3 | c4 | c5 |... |
如上图,取查询中 where 以及 on 上下推到 ScanNode 的条件,从前缀索引的第一列开始匹配,检查条件中是否有这些列,有则累计匹配的长度,直到匹配不上或者36字节结束(varchar类型的列只能匹配20个字节,并且会匹配不足36个字节截断前缀索引),然后选择出匹配长度最长的一个 Base/Rollup,下面举例说明,创建了一张Base表以及四张rollup:
+---------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+---------------+-------+--------------+------+-------+---------+-------+
| test | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index1 | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index2 | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index3 | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup_index4 | k4 | BIGINT | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
+---------------+-------+--------------+------+-------+---------+-------+
这五张表的前缀索引分别为
Base(k1 ,k2, k3, k4, k5, k6, k7)
rollup_index1(k9)
rollup_index2(k9)
rollup_index3(k4, k5, k6, k1, k2, k3, k7)
rollup_index4(k4, k6, k5, k1, k2, k3, k7)
能用的上前缀索引的列上的条件需要是 = < > <= >= in between 这些并且这些条件是并列的且关系使用 and 连接,对于or、!= 等这些不能命中,然后看以下查询:
SELECT * FROM test WHERE k1 = 1 AND k2 > 3;
有 k1 以及 k2 上的条件,检查只有 Base 的第一列含有条件里的 k1,所以匹配最长的前缀索引即 test,explain一下:
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k1` = 1, `k2` > 3
| partitions=1/1
| rollup: test
| buckets=1/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
再看以下查询:
SELECT * FROM test WHERE k4 = 1 AND k5 > 3;
有 k4 以及 k5 的条件,检查 rollup_index3、rollup_index4 的第一列含有 k4,但是 rollup_index3 的第二列含有k5,所以匹配的前缀索引最长。
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k4` = 1, `k5` > 3
| partitions=1/1
| rollup: rollup_index3
| buckets=10/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
现在我们尝试匹配含有 varchar 列上的条件,如下:
SELECT * FROM test WHERE k9 IN ("xxx", "yyyy") AND k1 = 10;
有 k9 以及 k1 两个条件,rollup_index1 以及 rollup_index2 的第一列都含有 k9,按理说这里选择这两个 rollup 都可以命中前缀索引并且效果是一样的随机选择一个即可(因为这里 varchar 刚好20个字节,前缀索引不足36个字节被截断),但是当前策略这里还会继续匹配 k1,因为 rollup_index1 的第二列为 k1,所以选择了 rollup_index1,其实后面的 k1 条件并不会起到加速的作用。(如果对于前缀索引外的条件需要其可以起到加速查询的目的,可以通过建立 Bloom Filter 过滤器加速。一般对于字符串类型建立即可,因为 Doris 针对列存在 Block 级别对于整型、日期已经有 Min/Max 索引) 以下是 explain 的结果。
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k9` IN ('xxx', 'yyyy'), `k1` = 10
| partitions=1/1
| rollup: rollup_index1
| buckets=1/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
最后看一个多张Rollup都可以命中的查询:
SELECT * FROM test WHERE k4 < 1000 AND k5 = 80 AND k6 >= 10000;
有 k4,k5,k6 三个条件,rollup_index3 以及 rollup_index4 的前3列分别含有这三列,所以两者匹配的前缀索引长度一致,选取两者都可以,当前默认的策略为选取了比较早创建的一张 rollup,这里为 rollup_index3。
| 0:OlapScanNode
| TABLE: test
| PREAGGREGATION: OFF. Reason: No AggregateInfo
| PREDICATES: `k4` < 1000, `k5` = 80, `k6` >= 10000.0
| partitions=1/1
| rollup: rollup_index3
| buckets=10/10
| cardinality=-1
| avgRowSize=0.0
| numNodes=0
| tuple ids: 0
如果稍微修改上面的查询为:
SELECT * FROM test WHERE k4 < 1000 AND k5 = 80 OR k6 >= 10000;
则这里的查询不能命中前缀索引。(甚至 Doris 存储引擎内的任何 Min/Max,BloomFilter 索引都不能起作用)
6.2 聚合数据
当然一般的聚合物化视图其聚合数据的功能是必不可少的,这类物化视图对于聚合类查询或报表类查询都有非常大的帮助,要命中聚合物化视图需要下面一些前提:
查询或者子查询中涉及的所有列都存在一张独立的 Rollup 中。
如果查询或者子查询中有 Join,则 Join 的类型需要是 Inner join。
以下是可以命中Rollup的一些聚合查询的种类,
列类型 查询类型 Sum Distinct/Count Distinct Min Max APPROX_COUNT_DISTINCT
Key false true true true true
Value(Sum) true false false false false
Value(Replace) false false false false false
Value(Min) false false true false false
Value(Max) false false false true false
如果符合上述条件,则针对聚合模型在判断命中 Rollup 的时候会有两个阶段:
首先通过条件匹配出命中前缀索引索引最长的 Rollup 表,见上述索引策略。
然后比较 Rollup 的行数,选择最小的一张 Rollup。
如下 Base 表以及 Rollup:
+-------------+-------+--------------+------+-------+---------+-------+
| IndexName | Field | Type | Null | Key | Default | Extra |
+-------------+-------+--------------+------+-------+---------+-------+
| test_rollup | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k6 | CHAR(5) | Yes | true | N/A | |
| | k7 | DATE | Yes | true | N/A | |
| | k8 | DATETIME | Yes | true | N/A | |
| | k9 | VARCHAR(20) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup2 | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
| | | | | | | |
| rollup1 | k1 | TINYINT | Yes | true | N/A | |
| | k2 | SMALLINT | Yes | true | N/A | |
| | k3 | INT | Yes | true | N/A | |
| | k4 | BIGINT | Yes | true | N/A | |
| | k5 | DECIMAL(9,3) | Yes | true | N/A | |
| | k10 | DOUBLE | Yes | false | N/A | MAX |
| | k11 | FLOAT | Yes | false | N/A | SUM |
+-------------+-------+--------------+------+-------+---------+-------+
看以下查询:
SELECT SUM(k11) FROM test_rollup WHERE k1 = 10 AND k2 > 200 AND k3 in (1,2,3);
首先判断查询是否可以命中聚合的 Rollup表,经过查上面的图是可以的,然后条件中含有 k1,k2,k3 三个条件,这三个条件 test_rollup、rollup1、rollup2 的前三列都含有,所以前缀索引长度一致,然后比较行数显然 rollup2 的聚合程度最高行数最少所以选取 rollup2。
| 0:OlapScanNode |
| TABLE: test_rollup |
| PREAGGREGATION: ON |
| PREDICATES: `k1` = 10, `k2` > 200, `k3` IN (1, 2, 3) |
| partitions=1/1 |
| rollup: rollup2 |
| buckets=1/10 |
| cardinality=-1 |
| avgRowSize=0.0 |
| numNodes=0 |
| tuple ids: 0 |
【参考】: doris官网
术因分享而日新,每获新知,喜溢心扉。
诚邀关注公众号 『码到三十五』 ,共享更多技术资料。