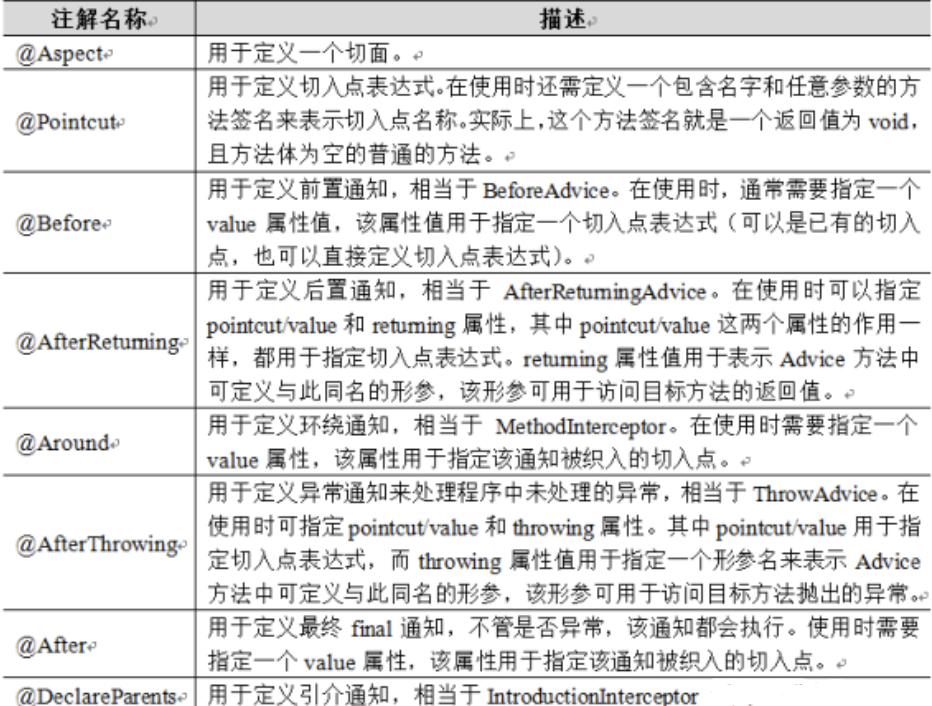
在写完《长字符串处理》以后,好长时间也没想到写什么内容好,前几天发现好像没有介绍过指针,那么今天我们的教程重点是介绍CODESYS中指针的使用。指针可以说算是C语言的精髓之一,有很多的优点和方便之处,但是同时也是个超级大坑(优点和缺点从来都是一体两面的~~)。在绝大部分时候,指针属于那种完全可以不用的类型,但是了解一下总是好的(就是喜欢学一些奇奇怪怪的用不着的知识😊)。本次教程对指针的基本概念、类型及使用方式,还有CODESYS的绝对地址映射做一下简单的介绍。
一、什么是指针
指针就是存储对象的内存地址的变量。内存地址就是内存的编号。如果把内存空间比喻成一家酒店,那么内存地址就是房间号。数据是存储在内存中的,住酒店的客人是住在一个个房间里面一样。取数据的指针就是取数据的地址,也就是酒店的房间号。
在CODESYS里面是地址是可以用类似%MWx(x=0~n)来表示。例如:
%MW10 := 123;
数据123存储在内存地址%MW10处,10就是地址。如果定义一个指针指向10,那么就可以理解为这个指针的值就是10。W表示的WORD类型,就是指针指向的地址的空间大小,类似与酒店房间的不同类型,如标准间、大床房、总体套房等等。
指针和数组一样,也是一种变量类型,因此需要先定义后使用。在CODESYS中,指针的定义方式如下:
pa : POINTER TO INT;
a : INT := 1;
pa:=ADR(a);
变量pa 定义了一个指向 INT类型的指针。POINTER TO 是定义指针的关键字,INT是指向的数据类型。

二、指针的类型及定义
1. Pointer to
指针的声明格式如下:
<pointer name>: POINTER TO <data type | data unit type | function block>;
在CODESYS中,指针是一个DWORD类型的值(不区分32位还是64位平台)。
取值操作符^:获取指针指向对象的内容。如上图中,P1为变量D1的地址,而P1^为D1的值。
注意:由于I/O的具有访问限制,因此定义指向I/O的指针以后,在代码生成时编译器会提示“<pointer name >不是一个有效的赋值目标”。如果需要对I/O值进行操作,可以先将I/O值拷贝到自己定义的变量中,再进行指针操作。
2.指针的索引访问
CODESYS允许通过索引操作符[]来访问指针指向的变量类型,例如以前教程中提到的字符串STRING类型可以通过[]访问字符串中的单个字符。
指针所指向的变量类型决定了操作符[]的索引移动长度,例如
pInt : ARRAY[0..10] OF INT;
pInt[i]实际上是地址(pInt+ i * SIZEOF(INT))指向的值。
即索引i改变时,地址偏移的长度与数据类型INT长度相关。
对于STRING类型,由于单个字符的存储类型是BYTE,因此通过指针索引访问时返回的值是一个SINT类型,即字符的ASCII码。
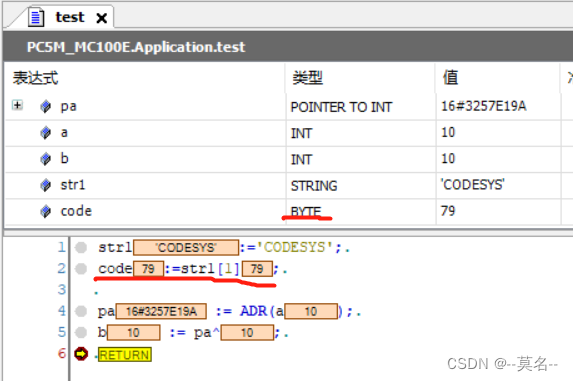
str : STRING:=’CODESYS’;
str[1]的值为79,即字符’C’的ASCII码。
对于WSTRING类型,其单个字符类型为WORD,因此通过指针索引访问时返回的值是一个INT类型,即字符的UNICODE码。
3.取地址操作符ADR
ADR()用于获取变量的地址。
与CoDeSys V2.3不同,您可以将ADR运算符与函数名称、程序名称、函数块名称和方法名称一起使用。因此,ADR取代了INDEXOF运算符。
使用函数指针时,可以将函数指针传递给外部库,但不能从CODESYS中调用函数指针。若要启用系统调用(运行时系统),必须为函数对象设置相应的对象属性(“构建”选项卡)。这句话的意思是函数指针是给CODESYS调用外部实现的函数功能的,在CODESYS内部不能使用函数指针调用内部函数。另外在使用系统调用功能调用外部命令时,需要预先设置调用对象的属性(我的理解大概是这样,忍不住要吐槽一下CODESYS的帮助文档,看不懂啊看不懂~~~☹)。
注意:
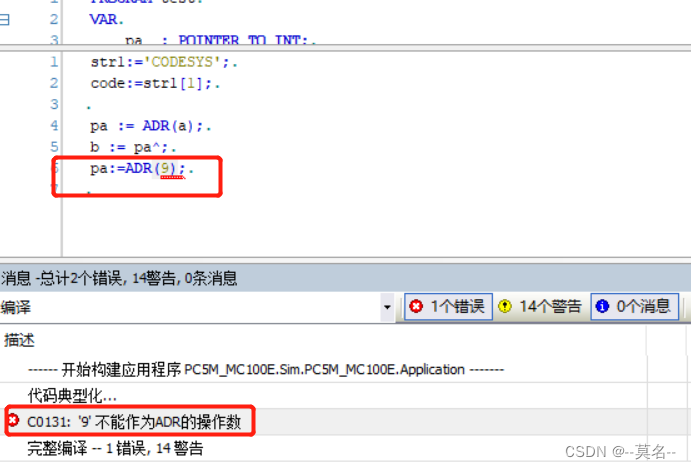
(1)不能用于给常量取地址。例如,ADR(9)会报C0131错误。
(2)使用在线更改时,地址的内容可能会发生变化。因此,指针变量可能指向无效的内存区域。为了避免出现问题,应该确保指针的值在每个周期中都会更新。
(3)不要将函数和方法的指针变量返回给调用者,也不要将它们分配给全局变量。函数和方法内部的变量是不会保存的,每次调用是会初始化为0,调用完成后应该是不存在了,因此将其内部变量返回是没有意义的。
4.Runtime指针监视函数CheckPointer()
用于在运行模式下监视指针的内存访问。该函数实际上是给用户提供了一个指针的监视接口,用户可以根据自己的需求实现对所用指针的检查。函数的模板如下:
// 声明部分,请勿修改
FUNCTION CheckPointer : POINTER TO BYTE
VAR_INPUT
ptToTest : POINTER TO BYTE;
iSize : DINT;
iGran : DINT;
bWrite: BOOL;
END_VAR
// 实现部分,请用户自行添加代码
CheckPointer := ptToTest;
该函数的输入参数含义如下:
ptToTest:指针的目标地址。
iSize:引用变量的大小,INT型。iSize的数据类型必须覆盖变量的维度范围。
iGran:参考尺寸的粒度,INT型。这是引用变量中包含的最大非结构化数据类型??。
bWrite:访问类型,BOOL型,TRUE为写入,FALSE为读取。
CheckPointer函数通常应该检查以下情况:
(1)检查返回的指针是否引用了有效的内存地址。
(2)监视引用内存范围是否与指针引用的变量类型匹配。
如果这两个条件都满足,则返回指针。否则需要在函数中进行错误处理。
注意:
(1)为了保证监视功能正常运行,不要修改声明部分,但用户可以添加局部变量。
(2)THIS和SUPER指针不会触发Checkpoint()函数调用。
(3)对于3.5.7.40及以上的编译器版本,对于REFERENCE变量也可以使用Checkpoint()函数进行检查。
说实话,这个功能我也没用过。主要是在CODESYS里面使用ST开发大部分时候不需要用指针。必须要用的时候,一定是确保用法是正确的,所以一般是不做这个检查的。必须要做这个检查的使用环境,目前还没遇到过,所以这里就不举例了(讲这么多,其实就是懒,没别的原因~~😊)。
5.引用Reference to
引用是对象的假名,实际上是指针,可以指向各种类型的数据(bit除外)、结构体、功能块、函数和程序。
定义方式如下:
<identifier> : REFERENCE TO <data type>;
引用赋值:
<identifier> REF = <variable>;
引用变量可以直接访问引用对象的值,不必使用^操作符。
对于引用类型,编译器会进行类型安全检查,即检查两个类型是否一致,不一致会报错。而指针这不进行这种检查,需要用户自己确保使用正确。在运行时,指针的内存访问可以通过隐式监视函数CheckPointer()进行检查。
引用作为函数或功能块参数时,不需要ADR()来进行参数传递。
注意:
(1)对于3.3.0.40及以上的编译器版本,引用变量会初始化为0。
(2)对输入设备定义引用时,由于没有写访问权限,编译器会显示警告。正确的方式与指针类似,定义一个中间变量与输入设备关联,然后对该中间变量定义引用。
(3)可以使用__ISVALIDREF()检查引用是否指向有效值(非0值为有效)。
(4)与指针一样,对常量定义引用是无效的。
三、指针的使用
1.结构体或数组指针
aa : ARRAY[0..9] OF INT:=[1,2,3,7(100)];
pa : POINTER TO INT;
pa := ADR(aa);
b:=pa[2];
c:=pa^;
//c:=(pa+1)^; //报错
pa:=pa+SIZEOF(INT);
d:=pa^;
pa:=pa+1;
e:=pa^;
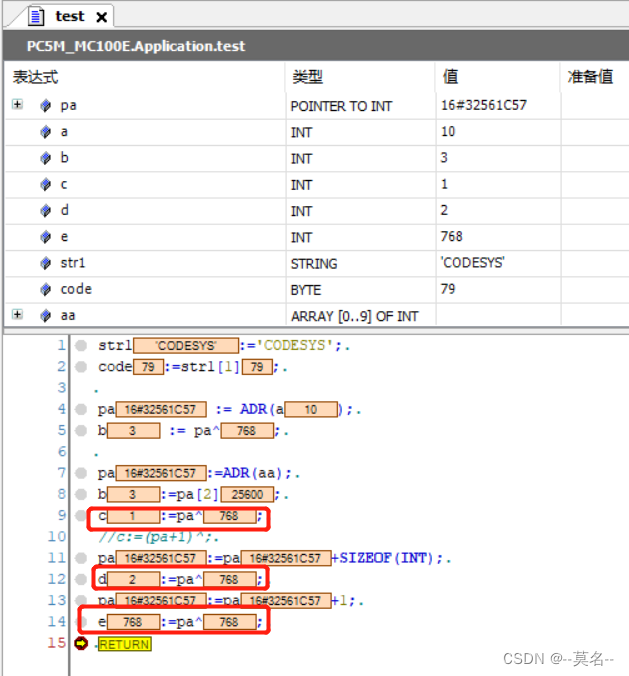
指针pa实际上指向数组aa的首地址,pa^实际就是pa[0],数组序号默认是从0开始。需要注意的是,直接对指针进行加减操作时会导致结果不可预知。上图中c的值为1,即p[0]。将pa的值加上一个INT类型长度后,d的值变为2,即p[1]。但是在pa上加1以后,e的值变为768。另外(p+1)^这种操作是不合法的,编译器会报错。
2.二级指针
二级指针是指向指针变量的地址。
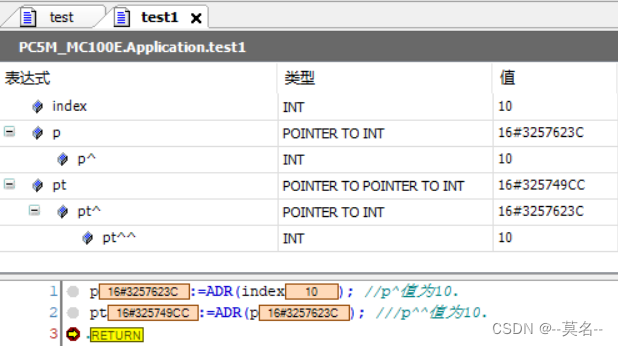
index : INT:=10;
p : POINTER TO INT;
pt : POINTER TO POINTER TO INT;
p:=ADR(index); //p^值为10
pt:=ADR(p); ///p^^值为10
四、动态内存分配
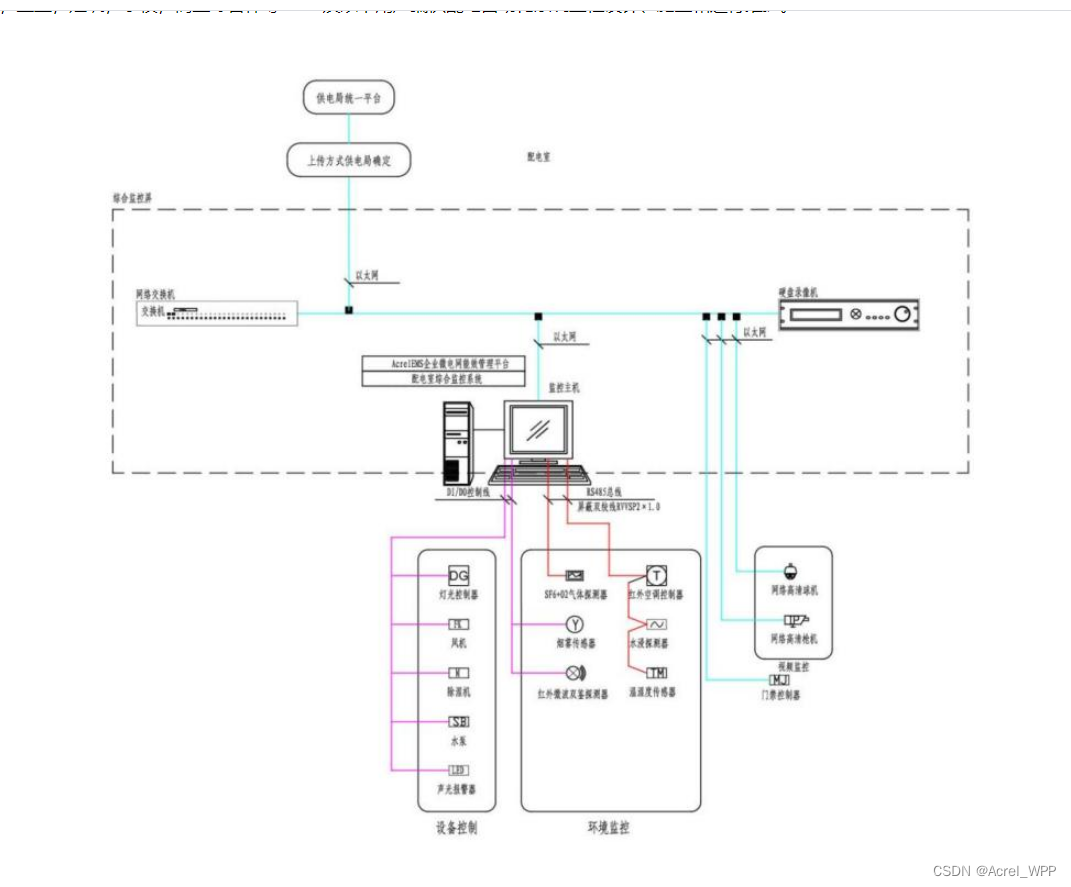
要使用动态内存分配功能需要在Application里面开启。如下图:
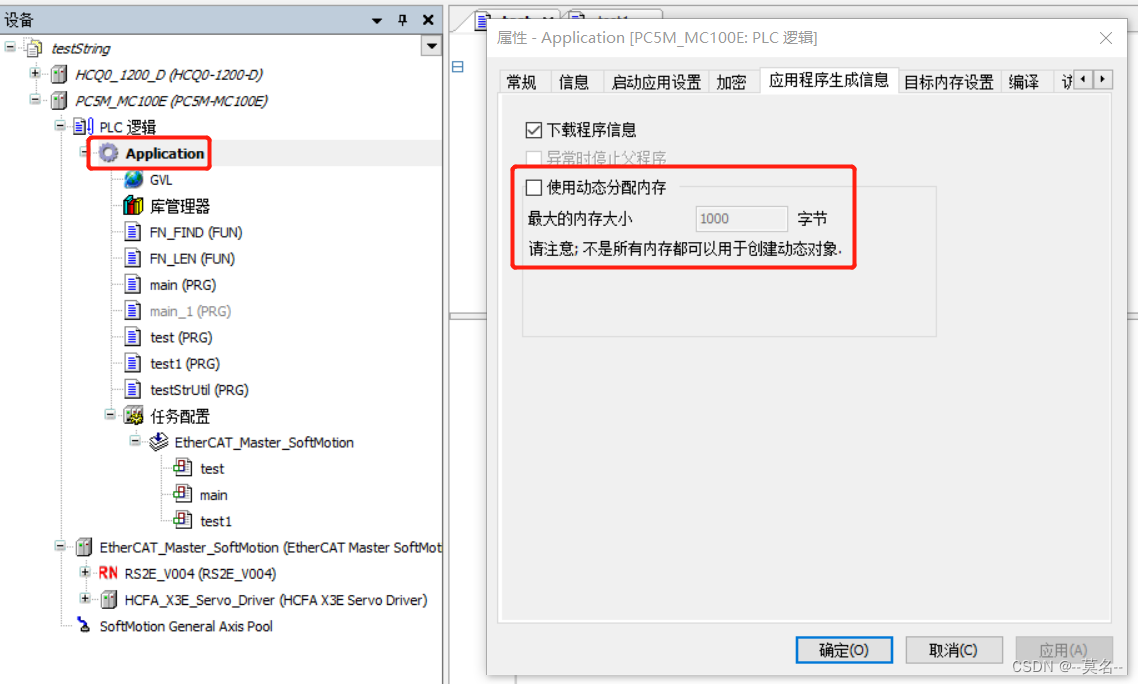
相关操作函数
__NEW:为功能块或数组分配内存,成功后会返回指向相应对象的指针,失败则返回0。使用的时候应避免在两个任务中同时调用,要么只在一个任务中调用该操作,也可以使用信号量SysSemEnter()来避免__NEW的同时调用(可能会导致任务周期出现大的抖动)。
__DELETE:释放__NEW分配的内存。该操作没有返回值,内存释放后对应的指针被设为0。对于指向功能块的指针,CODESYS会在指针设为0之前调用功能块的FB_EXIT方法。
五、地址映射
在使用内存动态分配或指针的时候,地址本身的内容在实时运行时可能会改变。CODESYS提供了一套用于定义内存绝对地址的方式。形式如下:
%<memory range prefix><size prefix><number|.number|.number....>
主要用于表示从指定的地址开始取,具体使用多少个字节,由定义的数据类型决定。
(1)内存区域memory range prefix
I:输入内存,指输入设备或传感器,常用的如数字输入。
Q:输出内存,指输出设备或执行器,常用的如数字输出
M:控制器内存。??
(2)数据类型size prefix
X:位
NONE:位
B:BYTE,8位
W:WORD,16位
D:DWORD,32位
(3)示例
%QX7.5 //输出内存位置7.5,类型为BIT
%IW215 //输入内存位置215,类型为WORD
%MD48 //内存位置48,类型DWORD
iWr AT %IW0: WORD; //为变量指定地址
例如给%MD0赋值为10:
%MD0:=10;
现在有指针P指向%MD0,那么P的值就是%MD0。然后取指针P的值赋给%MD1,就是把指针P 指向的%MD0的值取出来,赋给%MD1,此时%MD1的值也为10。
地址的类型和范围受当前控制器的配置和设置影响。寻址位置与设备类型无关,只与所用数据类型有关,即字5总是用%IW5寻址,字节5总是用%IB5寻址。采用不同数据类型的寻址实际上是在操作同一片内存,只是计数的长度不同。不同数据类型的对应关系如下表所示:
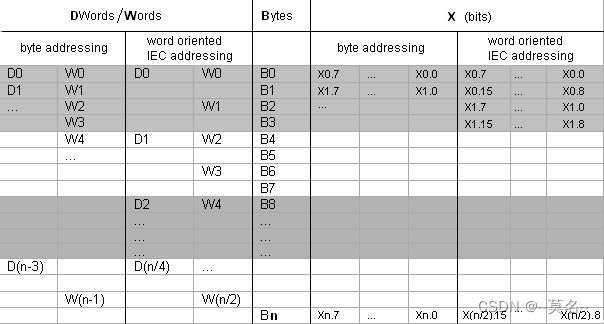
从上表可以看到,D0包含B0-B3,W0包含B0和B1。修改%QW0的值会影响到QX0.0~QX0.7的值,因此使用时应避免出现重叠。
五、总结
指针虽然方便,但是CODESYS因为自身的原因,对指针的支持有限。像内存的动态分配,早期版本是不支持的,现在的版本虽然支持但也是有限制的,所以真正需要用到的时候又不太方便。大家要是问我对于指针有什么经验,那我只能说对于小白来说,能不用就别用。实在是要用,要高度警惕类型匹配和指针越界问题,因为实在是太容易出错了,而且错了也不容易察觉(高手当然是随便怎么玩都好~~~)。
------------------
原创不易,感兴趣的多支持!