本资料是NLP核心知识点的ppt!!!【文章较长,建议收藏】
本节课我们学习预训练模型。
前言

我们在学习词向量的时候,应该知道了多个产生词向量的方法,包括基于矩阵(词-词共现矩阵)分解的方法、基于语言模型(word2vec)的方法、以及结合二者优点的Glove模型等其他产生词向量的方法。
然而,他们所产生的的词向量,都属于静态的词向量,这是由于这些方法产生的词向量表示方式,将会拿来直接作为输入层的输入,并且在后面的下游任务模型训练过程中,词向量不会再被调整, 所谓静态是指,一经产生,就不会再改变。
然而,对于一词多义的问题,这种静态的词向量并不能很好的表示一个单词的实际语义。例如,下面的两句话:
苹果好吃吗?
苹果好玩吗?
我们知道,“苹果”这个单词,在第一句话中,表示水果,而在第二句话中,表示手机品牌。然而使用静态词向量却无法很好的将二者语义区分开来,所以我们可以通过引入上下文信息建模更加复杂的神经网络,从而将静态词向量转换为动态词向量。
那么有哪些模型可以实现动态词向量呢?具体是如何得到的呢?
课程目录
我们将从这几个方面进行讲解。
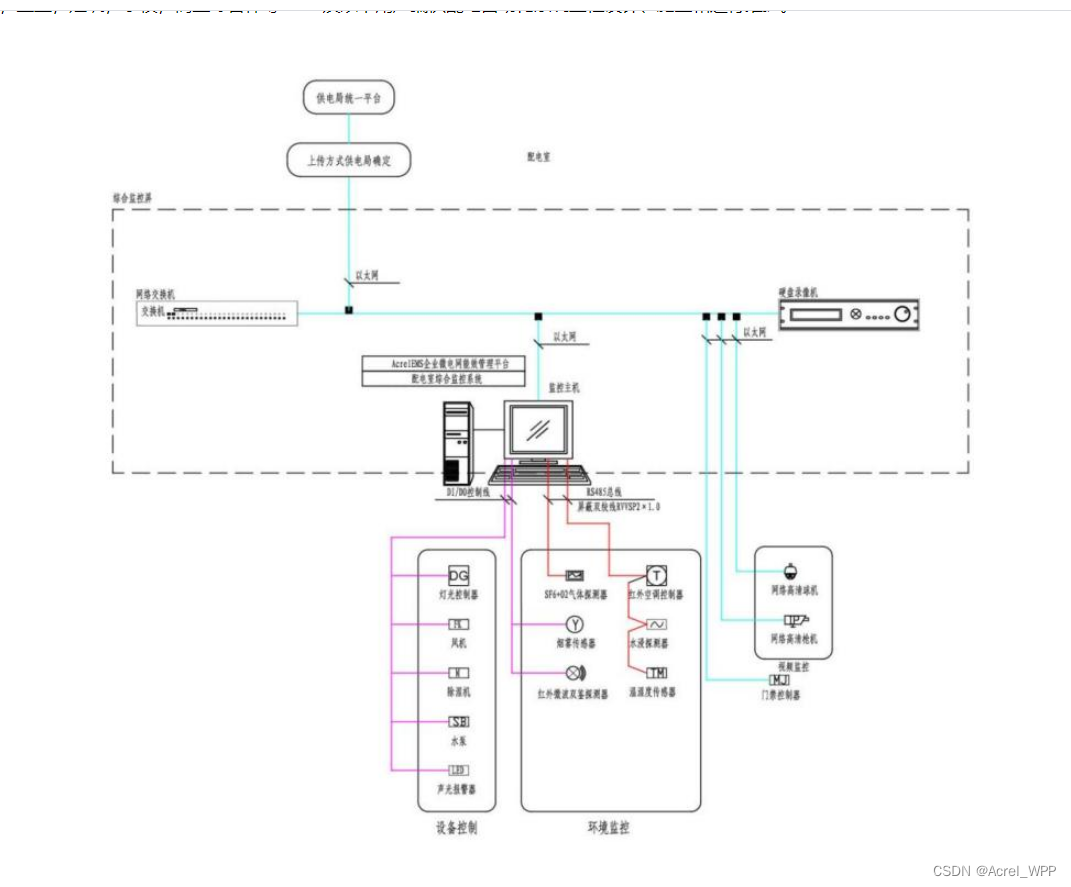
NLP发展史
Attention
Transformer
BERT
ERINE
NLP发展史

2013年Mikolov提出了word2vec语言模型,解决了训练词向量的方法。
2014年,循环神经网络及其变种LSTM/GRU开始被使用,并且Seq2Seq也被提出,
它是一种循环神经网络的变种,包括编码器 (Encoder) 和解码器 (Decoder) 两部分。
2015年,Attention注意力机制被引入到网络中,克服了“当输入序列非常长时,模型难以学到合理的向量表示”这一问题。
后面的发展中,我们发现,Attention注意力机制发挥了重要作用。例如,2017年提出的Transformer中,就强调了Attention的重要性。再往后,著名的语言模型BERT、ERNIE等,Attention都是其中的核心组件。
接下来,我们就依次对Attention、Transformer、BERT、ERNIE进行一个介绍。
Attention
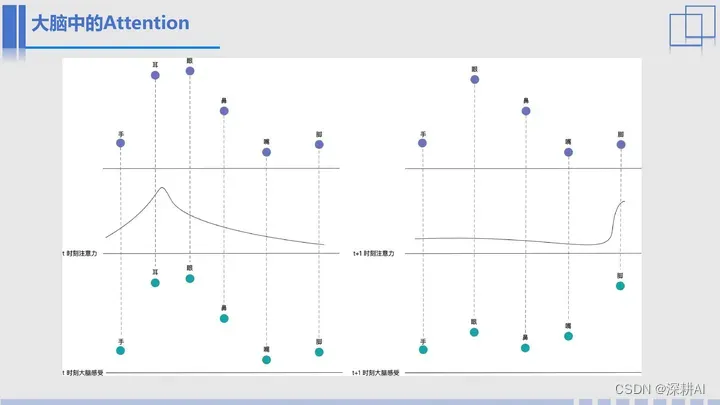
如图,是大脑中的注意力变化图。
举个例子,假如大家正在教室里认真的听老师讲课,那么此时,大家的注意力肯定是放在了耳朵和眼睛上,但是如果现在问大家一个问题,你能感受到你现在穿鞋了吗?其实大家肯定是穿了,但是问完这个问题以后,大家的注意力肯定会立马转移到脚上。那么左图就是t时刻,我们大家大脑的注意力分布图,右侧就是t+1时刻,注意力转移之后的分布图。

我们再以一个序列语句“He is eating an green apple”为例,再来看一下我们的注意力分布变化。
当我们在看第一个词He的时候,其实我们的注意力会更多的去看它后面两个单词是什么,也就是x2(is)和x3(eating)的注意力会高一些,就像图中的实线条所示;但是当我们读到第三个单词“eating”时,我们会更多的将注意力放在x1(He)和x5(apple)上,那么此时的注意力曲线就会变成虚线所示。
如果将每一个时刻的输入x看做是一个词向量,那么注意力大小就可以看做是一个权重。此时,在不同时刻,我们如果用整个句子中的每一个词的向量和权重去表示当前时刻的词向量,那么就可以使用如下 公式表示:
其中i表示某一时刻,yi表示该时刻的输出,xj表示每一个词向量,wij表示i时刻不同单词的权重。通过以上方式,我们其实就是在一句话中,重新表示了一个单词的向量。这也就是动态词向量的核心内容。
那刚才我们提到的权重,也就是注意力分布是怎么计算的呢?
在Attention机制中,我们通过相似度来计算权重。
注意力机制可以分为两步:
计算注意力分布
根据 来计算输入信息的加权平均
以文本序列为例,图中,q代表query,即要查询某个单词的词向量,x1,x2…xN,代表了一个序列,其中每一个xi表示不同时刻的输入单词(向量)。我们从下往上看这幅图,就是依次计算了q和x的相似度(通过矩阵相乘的方式),然后再通过softmax的方式进行归一化操作,此时计算的结果就是注意力分布 ,再然后,我们将x分别与之对应的 进行加权组合,得到最终的结果a,就是我们使用序列中所有单词向量动态表示q的结果。
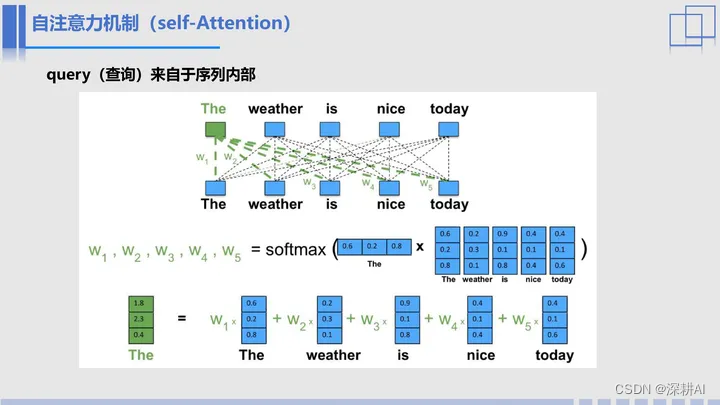
刚才我们一直提到的都是注意力机制,下面我们引入另一个单词,自注意力机制,也就是self-Attention,很明显,自注意力机制就是自己注意自己,也就是我们将前面的q换成序列中的单词,用该句中的所有单词去表示每一个单词。
以“The weather is nice today”这句话为例。
假如我们要使用这句话中所有单词去动态表示单词“The”,根据刚才的步骤,我们依次计算“the”的向量和句子中每个单词的相似度,再经过softmax函数,就得到了权重w1、w2、w3、w4、w5,最后我们用某个单词的权重与该单词的向量进行加权求和,就可以得到单词“The”在该句话中的动态表示。
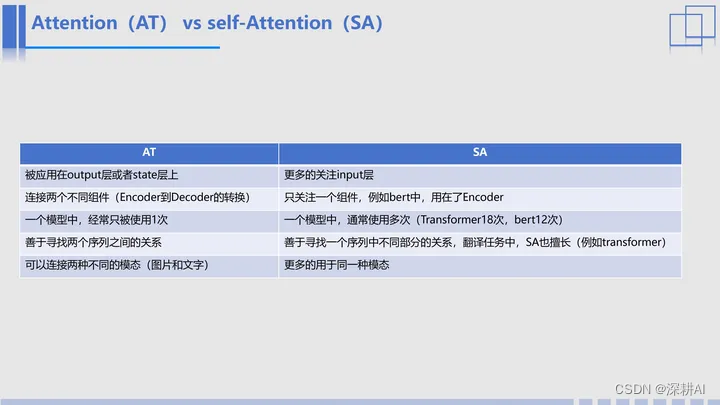
那刚才我们提到了attention和self-attention,他们两个有什么特点吗?这个表格就给出了一些经验。
Attention:通常被应用在output层或者state层上,用于连接两个不同组件(例如,从Encoder到Decoder的转换),善于寻找两个序列之间的关系;通常而言,一个模型中,只被使用1次;也可以连接两种不同的模态(图片和文字)。
Self-Attention:只关注一个组件,通常是关注input层,例如bert中,用在了Encoder;一个模型中,通常使用多次(Transformer18次,bert12次),善于寻找一个序列中不同部分的关系;更多的用于同一种模态。
Transformer

什么是transformer呢?
在不同的领域我们有不同的翻译,例如,在动漫里,我们将其翻译成“变形金刚”,在电力中,我们将其翻译成“变压器”,而我们所说的transformer,二者都不属于,而是一种神经网络。
曾经一段时间,有人把他翻译成变压器,这是由于该网络的最初应用是在语言翻译中,而语言翻译,就像变压器一样,是将一种语言翻译成另一种语言,所以将其翻译成变压器,也无可厚非,但是,随着transformer的应用越来越广泛,目前为止,已经远远超过“变压器”的含义。